K近邻算法(K-Nearest Neighbors,KNN)
发布时间:2024年01月08日
K近邻算法(K-Nearest Neighbors,KNN)是一种基本的监督学习算法,常用于分类和回归任务。KNN的基本思想是通过测量不同样本点之间的距离,将新样本的类别标签赋予其K个最近邻居中出现最频繁的类别。
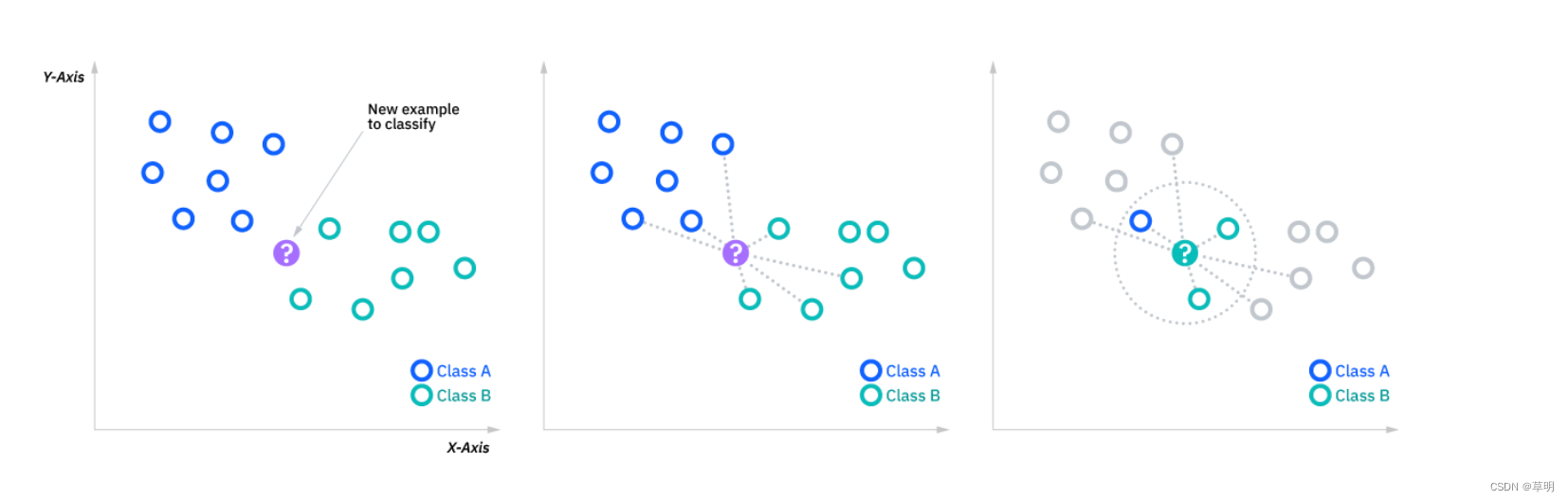
以下是KNN的基本原理和使用方法:
基本原理
- 距离度量: KNN通常使用欧氏距离(Euclidean distance)或其他距离度量来衡量样本点之间的相似性。
- 邻居选择: 对于一个新样本,找到离它最近的K个训练样本。
- 多数投票: 对于分类问题,将K个最近邻居的类别标签进行投票,选择得票最多的类别作为新样本的预测类别。对于回归问题,可以取K个最近邻居的平均值作为预测值。
优点
- 简单而有效: KNN是一种非参数化方法,模型不需要训练过程,易于理解和实现。
- 适用于多类别问题: KNN可用于处理多类别分类问题。
使用方法
KNN的使用通常包括以下步骤:
- 数据准备: 收集并准备好带标签的训练数据集。
- 选择K值: 选择K值,即决定考虑多少个最近邻居。
- 距离度量: 选择合适的距离度量方法。
- 训练模型: 对于KNN来说,训练过程仅仅是将训练数据存储起来。
- 预测: 对于新样本,计算它与训练数据中每个样本的距离,选取距离最近的K个样本,通过多数投票确定预测类别。
代码示例(使用Python和scikit-learn)
以下是一个简单的KNN分类的示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建KNN模型
model = KNeighborsClassifier(n_neighbors=3) # 设置K值为3
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Classification Report:\n{report}')
在这个示例中,n_neighbors参数设置了K值,你可以根据需要调整K值以及其他参数。详细的参数说明可以在官方文档中找到。
文章来源:https://blog.csdn.net/galoiszhou/article/details/135445869
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++笔记(二)
- 通过WebUART分享并远程控制设备
- 【无标题】
- 【蓝桥杯选拔赛真题53】python兑换券换玩偶 第十四届青少年组蓝桥杯python 选拔赛比赛真题解析
- 猫粮推荐:猫咖老板自用五大品牌主食冻干推荐!
- 力扣416. 分割等和子集(java 动态规划)
- uniapp|微信小程序:隐私保护指引说明
- Kubernetes 学习总结(44)—— Kubernetes 1.29 中的删除、弃用和主要更改
- Redis:原理+项目实战——Redis实战3(Redis缓存最佳实践(问题解析+高级实现))
- 【数据结构】串,数组,广义表 | 笔记整理 | C/C++实现