AI 绘画StableDiffusionWebui图生图
介绍
stable-diffusion-webui AI绘画工具,本文介绍图生图,以一张图片做底图优化生成。
例如:上传一张真人照片,让AI把他改绘成动漫人物;上传画作线稿,让AI自动上色;上传一张黑白照,让AI把它修复成彩色相片。
https://github.com/AUTOMATIC1111/stable-diffusion-webui
这个功能位于「Img2img」的页签。
参数
-
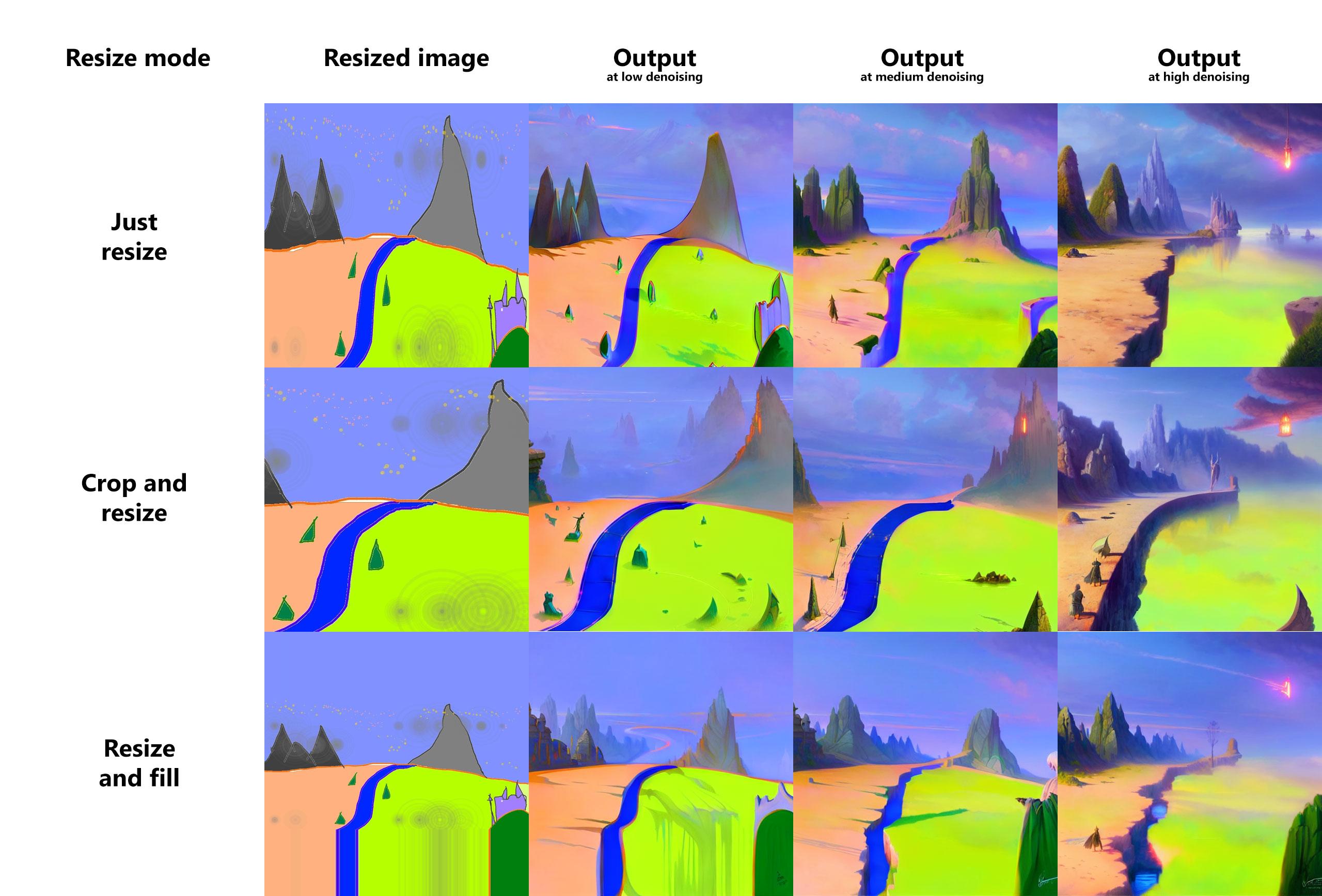
Resize mode:调整生成图片分辨率的模式,有原始分辨率、矩形、精确缩放等选项
- Just resize:紧调整大小,直接拉伸图像
- Crop and resize:裁剪然后调整大小,长宽比保持不变,但左右两侧会损失一点数据。
- Resize and fill:调整大小并填充,这会在你的图像周围填充新的噪点
- Just resize (latent upscale):和第一个选项相同,但使用的是潜在空间上采样技术。
-
Sampling method:采样方法,主要有Euler、Euler a、DPM++、DPM Fast等。
-
Sampling steps:采样步数,一般设为20-100,步数越多质量越高但速度更慢。
-
Refiner:选择是否使用重采样模型提升质量。
- Switch at 10 - 在第10步时切换到重采样模型。
- Switch at 0 - 表示一开始就使用重采样模型,不进行普通采样。
- Switch at -1 - 表示全部使用普通采样,不切换到重采样模型。
-
Resize to:直接设定生成图片的分辨率大小
-
Resize by:按比例缩放生成图片的分辨率。
-
CFG Scale:控制生成图片质量和速度的折中参数,范围7-12。
-
Denoising strength:去噪强度,默认为0.75,数值越高去噪强度越大。
-
Seed:随机种子数,确保每次相同条件可以复现结果。
-
Script:选择定制脚本,实现不同效果。
-
Interrogate Deepboooru
上传图片后,用Danbooru图库数据判别图片并自动填入提示词。需要注意Deepbooru训练的图像数量有限,它顶多只能用来认图片的场景和人物tag,无法准确标出最新的动漫角色。 -
Interrogate CLIP
类似Deepbooru用途,不过较适合判别真人照片内容。
Refiner
Refiner 选项框内包含两个选项,一个是模型的选择框 “checkpoint”,另一个是决定何时开始使用 refiner 模型 “switch at”。当 “switch at”设定为0.5时即表示前一半的步骤使用 base 模型迭代,最后一半的步骤使用 refiner 模型迭代。设定为1则表示关闭此功能。
很有意思的是,refiner 的模型选项框内可以选择不止refiner 模型,还可以选择其他的普通模型(SDXL 和 SD1.5 都可以),因此就衍生出一种新的玩法,比如前面几步我使用真实模型,后面几步则使用动漫模型推理,生成更具特色的图片。

inpainting
https://github.com/AUTOMATIC1111/stable-diffusion-webui-feature-showcase#inpainting
当用户想要改进生成的图像中的某些部分时,可以使用修复功能来指定并编辑图像中的任何部分。

scripts (自定义脚本)
Loopback
这个功能允许用户多次将输出图像反馈到img2img中,使用相同的提示生成更多图像。
SD Upscale
用于提高低分辨率、小尺寸图像的大小和质量,通过使用算法如Lanczos和Real ESRGAN/ESRGAN来放大多个图像,并将这些图像叠加生成单一放大图像。
- Lanczos 是一种标准的图像缩放算法,虽然面部更干净一些,但它通常更忠实于原始图像。
- Real ESRGAN 2x Plus的色调稍偏暖,头发、衣服上的皱纹等细节有些模糊,给人一种柔和的印象。
- 无论Real ESRGAN 4x Anime 6B是否是专门用于动画的算法,给人的印象是整体绘制均匀,并且经过校正,使颜色清晰分离而不是渐变。另外,修饰后的脸部也有一丝动漫人物的气息。
- Real ESRGAN 4x 具有柔软而模糊的触感,尤其是当您观察女孩的皮肤触感时。
Outpainting mk2
图像的外延绘制功能,即在图像的边缘添加新的内容。
Poor man’s outpainting
更基础的外延绘制方法。
Prompts from file or textbox
用于从文件中读取提示,并用于图像生成
Prompt matrix
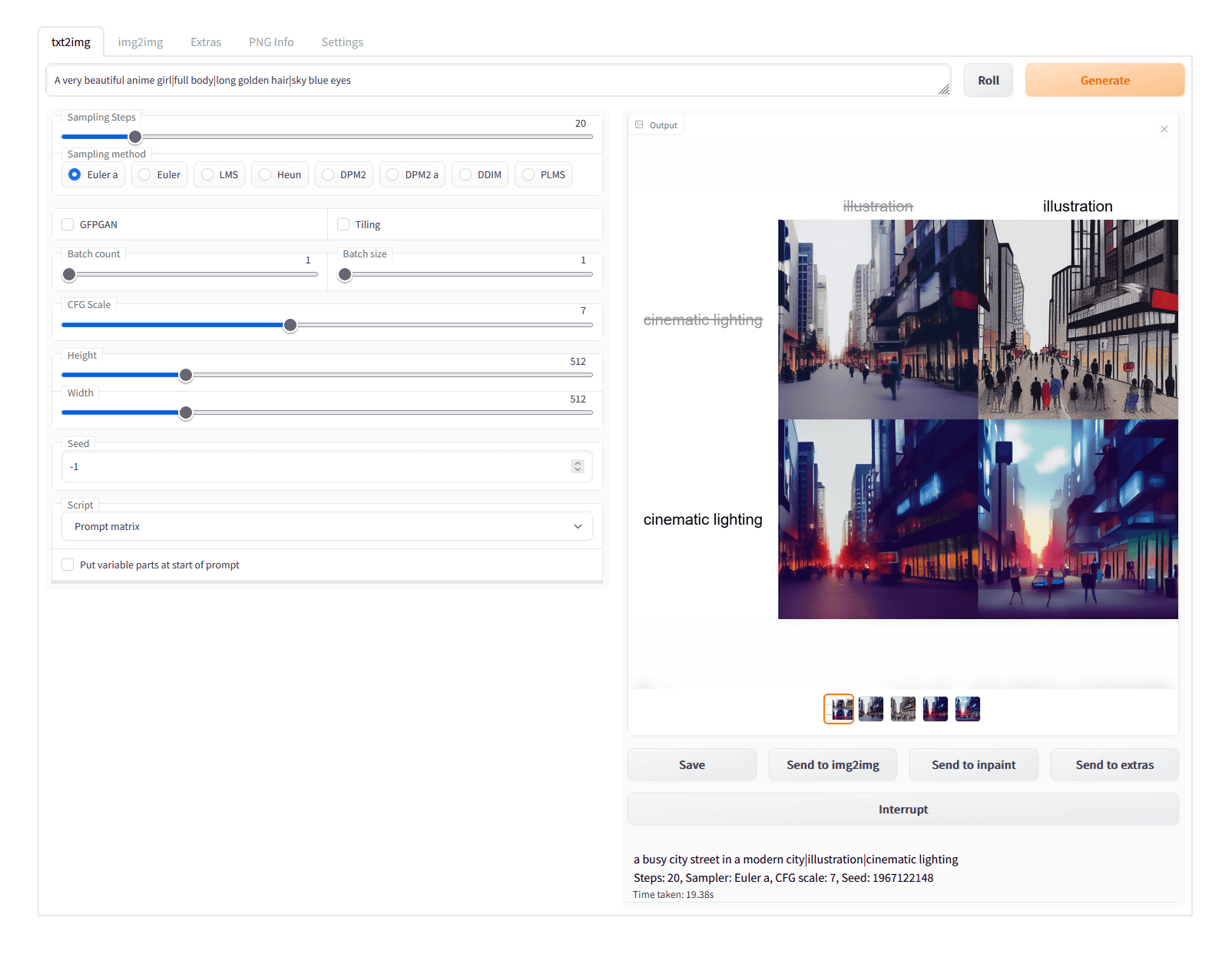
这个功能允许用户通过组合输入的字符串(提示)来生成图像。通常,关键词是用逗号分隔的,但在Prompt matrix中,它们是用竖线(‘|’)分隔的。例如,输入提示“繁忙的现代城市街道 | 插画 | 电影式灯光”,系统将生成结合了“繁忙的现代城市街道”、“插画”和“电影式灯光”的图像。这个功能可以输出多种组合的图像,让用户看到不同元素组合的效果。
controlnet m2m
加载视频,,并照常配置 controlnet 的其余部分,但不加载图片
Controlnet 将从视频中获取图片并创建视频。
https://www.reddit.com/media?url=https%3A%2F%2Fpreview.redd.it%2Fio1uce6d6zka1.gif%3Fformat%3Dmp4%26s%3Deae8ab720eeaa71a0197a3999ae53d7d88057317
X/Y Plot
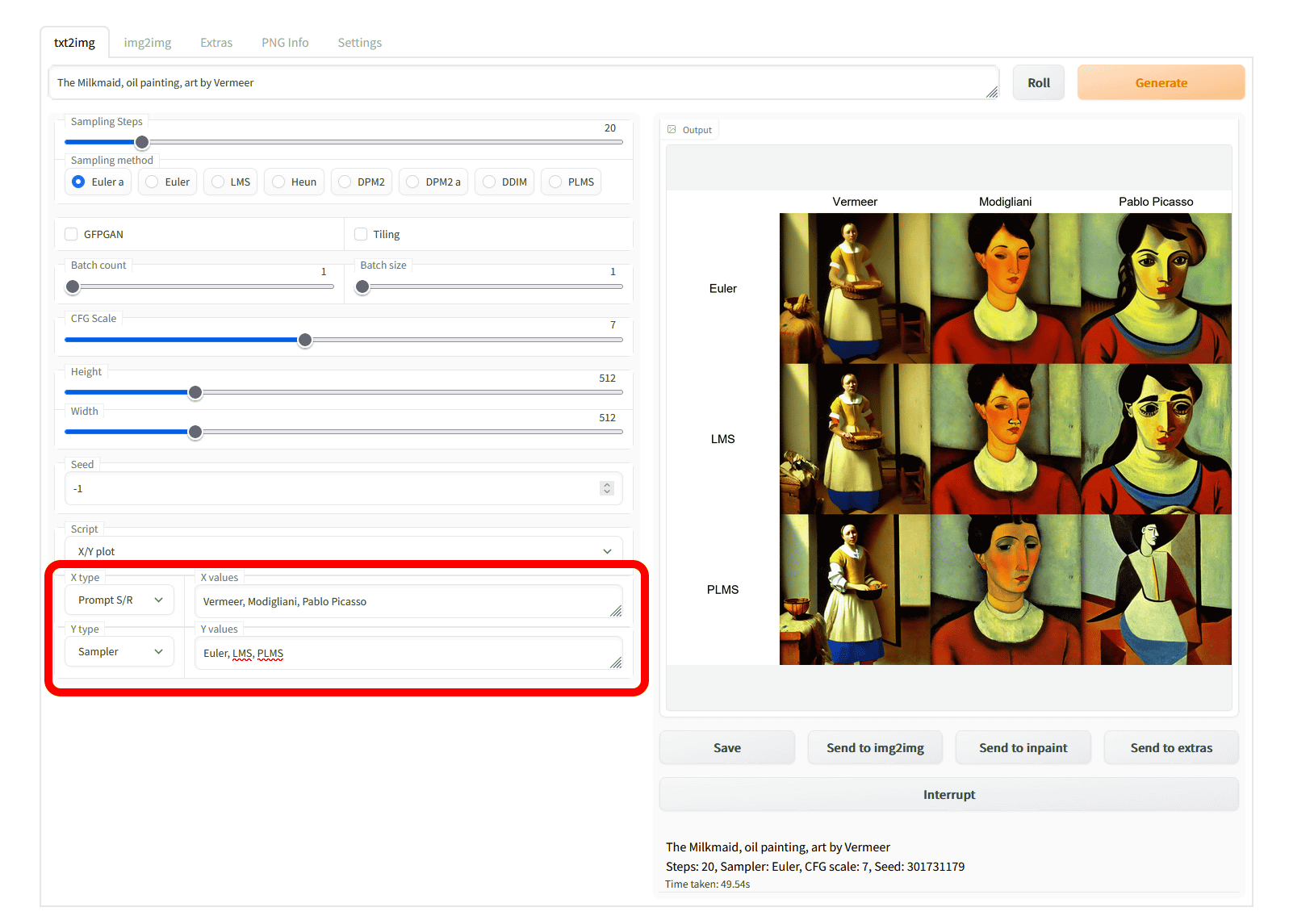
这个功能提供了两种选择项“X Type”和“Y Type”,用户可以选择不同的变量,如“Seed”(种子)、“Steps”(步骤)、“CFG Scale”(CFG比例,越高的值使图像更接近提示)、“Prompt S/R”(结束提示)和“Sampler”(采样器)。用户可以通过这些选项来生成不同风格和特征的图像。例如,选择不同的画家风格和采样器类型,可以看到每位画家风格的差异以及不同采样器带来的效果。
示例
https://civitai.com/models/34185/test002
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TypeScript 极速梳理
- java数据结构之赫夫曼树
- yolov5 7.0中文注释版train.py和detect.py
- ChatGPT助力Excel数据分析:让你的工作事半功倍!
- 精致旅游网ROXANDREA 网页设计 html模板
- 【随笔】程序员必备的面试技巧,如何成为那个令HR们心动的程序猿!
- Android布局字体大小不根据用户设置字体大小变化而变化
- 项目一为啥把输出结果保存到excle中,excle中没结果
- Binary Tree Right Side View
- 嵌出式学习小结