Python | Iter/genartor | 一文了解迭代器、生成器的含义\区别\优缺点
前提
一种技术的出现,需要考虑:
- 为了实现什么样的需求;
- 遇到了什么样的问题;
- 采用了什么样的方案;
- 最终接近或达到了预期的效果。
概念
提前理解几个概念:
-
迭代
我们经常听到产品迭代、技术迭代、功能迭代,这里的迭代的意思是在现有产品、技术、功能等基础上进行研发升级的过程,就可以理解为迭代。
从编程的角度讲,迭代是指重复执行一组操作的过程,通常是通过循环来实现。在编程中,迭代是遍历数据集合的一种
方式,允许逐个访问集合中的元素。 -
可迭代
可迭代是指能够被迭代的对象,即可以通过迭代遍历其元素的对象。Python中的可迭代对象可以是列表、元组、字典、字符串等。可迭代对象支持使用
for循环进行迭代。 -
可迭代对象
可迭代对象是实现了迭代协议的对象,即具有
__iter__()方法的对象。该方法返回一个迭代器对象。 -
迭代器
迭代器是一个具有
__iter__()和__next__()方法的对象,实现了迭代协议。__iter__()方法返回迭代器对象本身,而__next__()方法返回下一个元素。当没有元素可以迭代时,__next__()应该引发StopIteration异常。例如,可以使用内置的
iter()函数将可迭代对象转换为迭代器。当使用next()函数从迭代器中获取下一个元素时,如果没有元素可供迭代,将引发StopIteration异常。 -
生成器
生成器是一种特殊类型的迭代器,使用函数来生成值,而不是一次性构建并存储在内存中,所以极大减少内存使用。
生成器函数使用
yield语句产生值,而不是return。每次调用生成器的__next__()方法时,生成器函数会从上次yield语句的位置恢复执行,并继续执行直到遇到下一个yield语句或函数结束。这样可以有效地处理大量数据,因为它们允许逐个生成值,而不需要一次性生成整个序列。
普通实现
假设为了实现获取斐波那契数列的前多少位数据,一般采用的方式肯定是通过函数计算,将函数的计算值一次一次的返回并存储在一个如列表的容器中,然后再将容器数据遍历循环处理,代码示例如下:
def func(p_max):
def get_data(a, b):
return a + b
a, b, count = 0, 1, 0
p_lst = []
while count < p_max:
value = get_data(a, b)
a, b, count = b, value, count + 1
p_lst.append(value)
return p_lst
return_values = func(1000000000)
print(return_values)
for i in return_values:
# do something
pass
当p_max不大时,p_lst存储的数据不多,消耗的内存不大;一旦p_max比较大时,比如100,000,000时,p_lst存储内容就太多了,使用的内存也就会变得极大,甚至撑爆。
我们可以看一下当p_max设置为100,000,000时,30s内存就上限了。
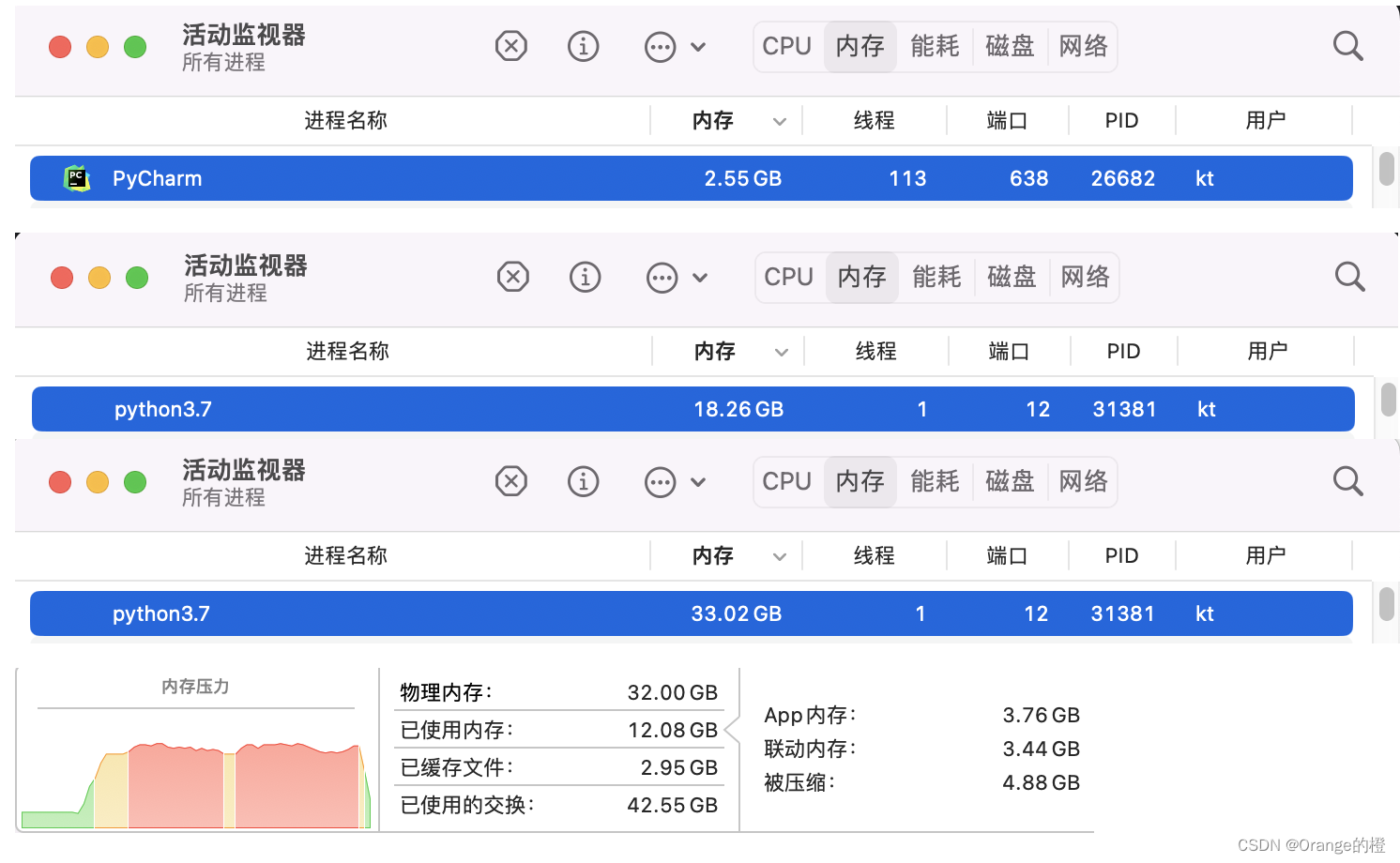
这只是一个方法的使用,在开发系统时,如果存在这样的操作,系统说不定在什么时候就因为内存问题被撑爆了,这是很可怕的。
进一步优化
为了避免这样的内存爆炸问题,最好的方式就是不存储所有结果,计算出一个就消费一个,方法每次只返回一个值,然后将其他变量覆盖重用循环往复,这样不就不会存在内存问题了。
def get_data(a, b):
return a + b
p_max = 1000000000
a, b, count = 0, 1, 0
while count < p_max:
value = get_data(a,b)
# do something use value
print(value)

经过等待,发现内存并没有多少变化,说明确实有效果。
但从上面看出,这里的循环使用while进行判断操作,和我们通常使用的遍历方法用法不同,那么是否可以将上述方法采用遍历的形式计算产生并消费呢?迭代器
迭代器
首先我们自行创建一个类,实现__iter__()和__next__()方法:
class MyFb:
def __init__(self, a, b, compute_time):
# 斐波那契左数
self.a = a
# 斐波那契右数
self.b = b
# 计算多少次几次斐波那契值
self.compute_time = compute_time
# 初始化计次器
self.current_time = 0
def __iter__(self):
return self
def __next__(self):
# 当计次器值 小于 总计算次数时,计算斐波那契数列值并将a、b向后推移
if self.current_time < self.compute_time:
value = self.a + self.b
self.a = self.b
self.b = value
self.current_time += 1
#print("%s/%s - %s" % (self.current_time,self.compute_time,value))
return value
else:
raise StopIteration
# 斐波那契起始值0、1,共计次10次
myfb = MyFb(0, 1, 1000000000)
for i in myfb:
# do something
print(i)
# while myfb:
# try:
# next(myfb)
# except StopIteration as e:
# print('End!')
# break
# 斐波那契起始值0、1,共计次10次
我们已经可以对通过MyFB类创建的myfb迭代器对象进行逐一遍历获取、访问、处理;
但是,为了能使对象被遍历,需要创建一个类并手动进行内置函数__iter__()和__next__()的定制,不仅徒增了代码量,也降低了代码的可读性。
有没有什么简单的方法就能实现迭代器的功能,还能保持代码易操作、易读的方式? 生成器
生成器
生成器(Generator)实际上是迭代器的一种特殊类型。(生成器只是一种便捷实现迭代器的方式而已)
通过使用函数和 yield 语句创建迭代器(每次执行完后会将global(), local() 环境变量缓存起来,下次执行时从yield处开始并恢复global(), local() 环境变量),每次遍历时,执行到yield时就将 yield后的结果返回回来,生成器函数并不使用return。
生成器具有迭代器的所有特性,并且还有一些额外的优势。
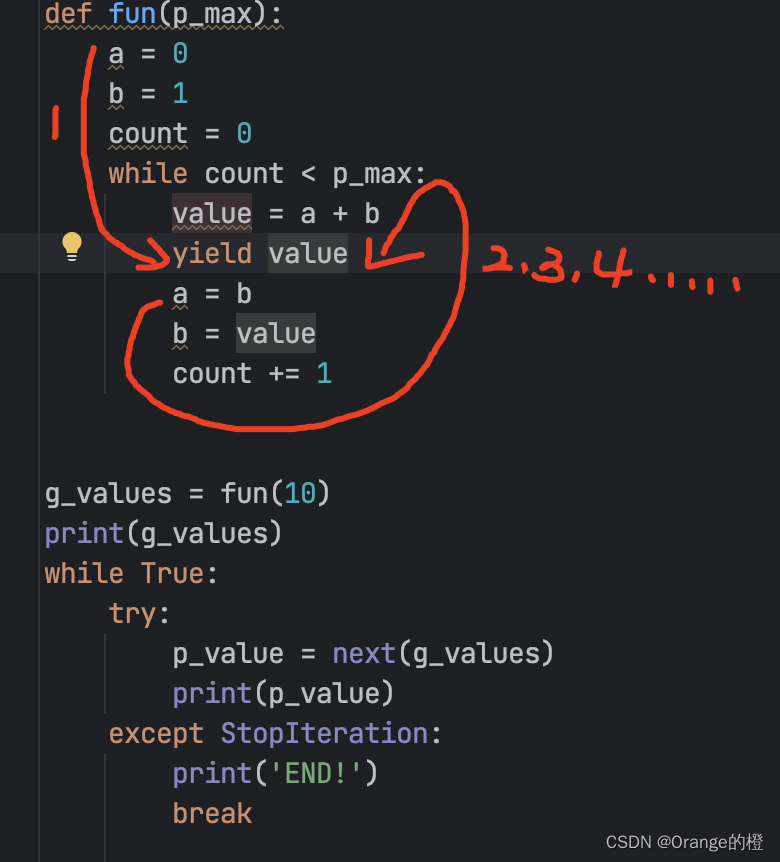
为了明显的说明其原理,我们写一个比较简单理解但是并不美观的代码:
def fun(p_max):
a = 0
b = 1
count = 0
while count < p_max:
value = a + b
yield value
a = b
b = value
count += 1
g_values = fun(100000000)
print(g_values)
while True:
try:
p_value = next(g_values)
print(p_value)
except StopIteration:
print('END!')
break
因为for兼容了迭代器的异常处理,所以我们可以直接使用:
def fun(p_max):
a = 0
b = 1
count = 0
while count < p_max:
value = a + b
yield value
a = b
b = value
count += 1
g_values = fun(10000000000)
print(g_values)
for i in g_values:
print(i)
继续简化代码可以写为:
def fun(p_max):
a,b,count = 0,1,0
while count < p_max:
yield a+b
a,b,count = b,a+b,count+1
for i in fun(10000000000):
print(i)
所以,迭代器是一种访问数据的方式,生成器是一种更加便捷实现的形式,而它们最主要的优点就是延迟数据生成,减少内存消耗,不要将其想的太复杂,只是一种措施、一种手段而已。
优缺点
生成器原本即为迭代器的特殊模式,所以可以看一下对于迭代器而言的优缺点都有哪些。
优点
- 内存效率: 迭代器按需生成元素,一次只产生一个元素,因此在处理大规模数据集时,迭代器能够更好地节省内存。这对于在有限内存环境中处理大型数据集或流式数据非常有利。
- 惰性计算: 迭代器支持惰性计算,只在需要时生成元素。这使得它们适用于处理无限序列或大规模数据,因为不需要一次性生成整个序列。
- 适用于多次迭代: 一旦迭代器耗尽了所有元素,可以通过重新调用
__iter__()方法将其重新初始化,使得可以再次从头开始迭代。这使得迭代器适用于需要多次迭代相同数据集的情况。 - 支持
for循环: 迭代器实现了迭代协议,因此可以直接用于for循环中。这样的代码更加简洁和易读。 - 支持无限序列: 由于迭代器是按需生成元素的,它们可以用于表示无限序列。这在模拟无限数据流等场景中非常有用。
- 支持并发操作: 由于迭代器是逐个产生元素的,它们可以在多线程或多进程环境中更容易地被共享和处理,而不需要担心整个数据集的同步问题。
缺点
- 不支持随机访问: 迭代器一次只能产生一个元素,无法通过索引直接访问元素。如果需要通过索引或其他方式随机访问数据集的元素,迭代器可能不是最佳选择。
- 代码繁琐: 相对于直接使用列表等数据结构,实现迭代器可能需要编写更多的代码,包括实现
__iter__()和__next__()方法。这可能在某些情况下增加了代码的复杂性。 - 不适用于所有场景: 尽管迭代器在许多情况下非常有用,但并不是所有问题都适合使用迭代器。在某些场景下,传统的数据结构和方法可能更加直观和简单。
- 一次性消耗: 大多数迭代器是一次性的,即一旦迭代器耗尽了所有元素,就不能重新开始。这与一些需要多次迭代相同的场景不匹配。
- 不易调试: 由于迭代器是按需生成元素的,当程序发生错误时,调试可能变得更加困难。在某些情况下,你可能无法直接查看整个数据集,而需要通过逐步迭代来定位问题。
- 不支持修改: 大多数迭代器是只读的,不支持在迭代过程中修改数据集。如果需要修改数据集,可能需要使用其他数据结构。
🎉如果对你有所帮助,可以点赞、关注、收藏起来,不然下次就找不到了🎉
【点赞】??????????
【关注】??????????
【收藏】??????????
Thanks for watching.
–Kenny
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!