python web
python web
python三大主流web框架
"""
django
特点:大而全 自带的功能特别特别特别的多 类似于航空母舰
不足之处:
有时候过于笨重
flask
特点:小而精 自带的功能特别少类似于游骑兵
第三方的模块特别特别特别的多,如果将flask第三方的模块加起来完全可以盖过django
并且也越来越像django
不足之处:
比较依赖于第三方的开发者
tornado
特点:异步非阻塞 支持高并发
牛逼到甚至可以开发游戏服务器
不足之处:
暂时你不会
"""
A:socket部分
B:路由与视图函数对应关系(路由匹配)
C:模版语法
django
A用的是别人的 wsgiref模块
B用的是自己的
C用的是自己的(没有jinja2好用 但是也很方便)
flask
A用的是别人的 werkzeug(内部还是wsgiref模块)
B自己写的
C用的别人的(jinja2)
tornado
A,B,C都是自己写的
Django 学习
基础环境配置
- python 版本 3.66
- Django 版本 1.11.11
下载 Django
pip install django==1.11.11
创建项目
命令行
# 一定要进入到指定的目录下 django-admin startproject project_name
pycharm
- new project --> django 即可
bug
bug 描述
TypeError: unsupported operand type(s) for /: ‘str‘ and ‘str‘,bug 解决
# setting.py TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', # 'DIRS': [BASE_DIR / 'templates'] # 将上面的修改成下面的 'DIRS': [str.format(BASE_DIR, '/templates')] # 下面也可以 # 'DIRS': [os.path.join(BASE_DIR, 'templates')]
命令行和 pycharm 的区别
- 命令行不会自动创建 templates 目录,需要手动创建
- 命令行 settings.py 文件中的
TEMPLATES字典中的'DIRS'对应的值为空列表需要自己手动填写为os.path.join(BASE_DIR, 'templates')
创建应用
- 一个应用就是一个功能,比如学校系统里的选课功能
python manage.py startapp app_name
# 在配置文件中注册应用
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01.apps.App01Config', # 全写
'app01', # 简写
]
启动 Django
# 命令行
python manage.py runserver
- pycharm 点击小绿点就可以了
主要文件介绍
mysite
|__ mysite
| |__ setting.py # 配置文件
| |__ urls.py # 路由与视图函数对应关系
| |__ wsgi.py # wsgiref 模块
|__ manage.py # django 的入口文件
|__ db.sqlite3 # 自带的数据库
|__ templates # 前端代码
|__ static
| |__ css
| |__ js
| |__ bootstarp # 前端框架
|__ app001
|__ admin.py # django 的后台管理
|__ apps.py # 注册使用
|__ migrations # 数据库迁移记录
|__ test.py # 测试文件
|__ views.py # 视图函数(视图层)
使用 Django 框架的步骤
- 当我们创建完应用后,就可以进行功能开发了,下面以登录功能为例:
-
在
urls.py中创建路由与视图函数的对应关系from app001 import views # 导入 views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^login/', views.login), # 添加该行 ] -
去相应的视图函数中创建函数
def login(request): return render(request, 'index.html') # return HttpResponse(b'hello world') -
根据视图函数返回值编写相应的前端页面
<!-- index.html --> ... -
运行项目查看结果即可
Django 框架的三板斧
# HttpResponse:返回字符串类型的数据
# render:返回html文件的
# redirect:重定向
from django.shortcuts import HttpResponse,render,redirect
# 视图函数必须要接受一个形参request
def ab_render(request):
return HttpResponse('str')
return render(request,'01 ab_render.html',locals())
return redirect(url)
静态文件配置
方法一:静态配置
<!-- html 文件这样写 -->
<head>
<script src="/static/bootstrap-3.4.1-dist/js/bootstrap.min.js"></script>
<link rel="stylesheet" href="/static/bootstrap-3.4.1-dist/css/bootstrap.min.css">
</head>
# settings.py 这样配
# 将 html 文件中的以 /static/ 开头的文件路径进行额外处理:
# 根据令牌在 STATICFILES_DIRS 中从上往下进行查询文件路径
STATIC_URL = '/static/' # 令牌
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static')
]
# 前端框架这样放
mysite
|__ static # 二级目录 (和 app 同级)
| |__ css
| |__ js
| |__ bootstarp # 前端框架
方法二:动态配置
<!-- html 文件这样写 -->
<head>
{% load static %}
<script src="{% static '/bootstrap-3.4.1-dist/js/bootstrap.min.js' %}"></script>
<link rel="stylesheet" href="{% static 'bootstrap-3.4.1-dist/css/bootstrap.min.css'%}">
</head>
# settings.py 这样配
STATIC_URL = '/static/' # 令牌
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static')
]
# 前端框架这样放
mysite
|__ static # 二级目录 (和 app 同级)
| |__ css
| |__ js
| |__ bootstarp # 前端框架
request 方法
request.method # 返回请求方式 并且是全大写的字符串形式 <class 'str'>
request.POST # 获取用户post请求提交的普通数据不包含文件
request.POST.get('key_name') # 只获取列表最后一个元素
request.POST.getlist('key_name') # 直接将列表取出
request.GET # 获取用户提交的get请求数据
request.GET.get('key_name') # 只获取列表最后一个元素
request.GET.getlist('key_name') # 直接将列表取出
登录界面
# views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
# Create your views here.
def login(request):
if request.method == 'POST':
result = request.POST.get('username')
return HttpResponse(f'{result} 欢迎回家!')
return render(request, 'index.html')
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
{% load static %}
<script src="{% static 'bootstrap-3.4.1-dist/js/bootstrap.min.js' %}"></script>
<link rel="stylesheet" href="{% static 'bootstrap-3.4.1-dist/css/bootstrap.min.css' %}">
{# <script src="/static/bootstrap-3.4.1-dist/js/bootstrap.min.js"></script>#}
{# <link rel="stylesheet" href="/static/bootstrap-3.4.1-dist/css/bootstrap.min.css">#}
</head>
<body>
<h1 class="text-center">登录</h1>
<form action="/login/" method="post">
username:<input type="text" name="username" class="form-control">
password:<input type="password" name="password" class="form-control">
<input type="submit" class="form-control info">
</form>
</body>
</html>
# settings.py
# 使用 post 请求现阶段需要注释下面一行
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
# urls.py
from django.conf.urls import url
from django.contrib import admin
from app001 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^login/', views.login),
]
Django 连接数据库
连接数据库
# settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'test', # 数据库名称
'USER': 'root',
'PASSWORD': '123',
'HOST': '192.168.222.5',
'PORT': 3306,
'CHARSET': 'utf8'
}
}
# 在 init.py 中添加这两行
import pymysql
pymysql.install_as_MySQLdb()
创建表
数据库和对象的对应关系:
类 表
对象 记录
对象属性 记录某个字段对应的值
## 所以创建一张表就是一个类
# models.py
class User(models.Model): # 必须要集成 models.Model
# id int primary_key auto_increment
id = models.AutoField(primary_key=True)
# username varchar(32)
username = models.CharField(max_length=32)
# password int
password = models.IntegerField()
初始化数据库
# 将类转移为数据库中的表
python .\manage.py makemigrations
python .\manage.py migrate
# 只要修改了models.py中跟数据库相关的代码 就必须重新执行上述的两条命令
bug
- 清除
Lib\site-packages\django\contrib\admin\migrations\和应用名下的migrations文件下的000*.py即可
创建关系表
publish = models.ForeignKey(to='Publish') # 默认就是与出版社表的主键字段做外键关联
authors = models.ManyToManyField(to='Author')
author_detail = models.OneToOneField(to='AuthorDetail')
# ForeignKey OneToOneField 会自动在字段后面加_id后缀
# 实例
from django.db import models
# 创建表关系 先将基表创建出来 然后再添加外键字段
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2)
# 总共八位 小数点后面占两位
"""
图书和出版社是一对多 并且书是多的一方 所以外键字段放在书表里面
"""
publish = models.ForeignKey(to='Publish') # 默认就是与出版社表的主键字段做外键关联
"""
如果字段对应的是ForeignKey 那么会orm会自动在字段的后面加_id
"""
"""
图书和作者是多对多的关系 外键字段建在任意一方均可 但是推荐你建在查询频率较高的一方
"""
authors = models.ManyToManyField(to='Author')
"""
authors是一个虚拟字段 主要是用来告诉orm 书籍表和作者表是多对多关系
让orm自动帮你创建第三张关系表
"""
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
"""
作者与作者详情是一对一的关系 外键字段建在任意一方都可以 但是推荐你建在查询频率较高的表中
"""
author_detail = models.OneToOneField(to='AuthorDetail')
"""
OneToOneField也会自动给字段加_id后缀
"""
class AuthorDetail(models.Model):
phone = models.BigIntegerField() # 或者直接字符类型
addr = models.CharField(max_length=32)
增删改查
表结构的增删改查
# 字段的增加
1.可以在终端内直接给出默认值
2.该字段可以为空
info = models.CharField(max_length=32,verbose_name='个人简介',null=True)
3.直接给字段设置默认值
hobby = models.CharField(max_length=32,verbose_name='兴趣爱好',default='study')
# 字段的修改
直接修改代码然后执行数据库迁移的两条命令即可!
# 字段的删
直接注释对应的字段然后执行数据库迁移的两条命令即可!
表内容增删改查
from app001 import models
# 查
# 返回值是列表套数据对象的格式
obj_list = models.User.objects.filter(username=username)
# 返回数据对象
user_obj = models.User.objects.filter(username=username).first()
# user_obj.字段名 可以获取对应的值
# filter括号内可以携带多个参数 参数与参数之间默认是and关系
# 增
user_obj = models.User.objects.create(username=username,password=password)
# 返回值就是当前被创建的对象本身
# 第二种增加
user_obj = models.User(username=username,password=password)
user_obj.save() # 保存数据
# 改
models.User.objects.filter.(id=user_id).update(username=username,password=password)
"""
将filter查询出来的列表中所有的对象全部更新,批量更新操作,只修改被修改的字段
"""
# 修改数据方式2
edit_obj.username = username
edit_obj.password= password
edit_obj.save()
"""
上述方法当字段特别多的时候效率会非常的低
从头到尾将数据的所有字段全部更新一边 无论该字段是否被修改
"""
# 删
models.User.objects.filter(id=user_id).delete() # 匹配批量删除
登录验证
from django.shortcuts import render
from django.shortcuts import HttpResponse
from app001 import models
# Create your views here.
def login(request):
if request.method == 'POST':
username = request.POST.get('username')
result = models.User.objects.filter(username=username).first()
if result:
password = request.POST.get('password')
if password == str(result.password):
return HttpResponse(f'{result.username} 欢迎回家!')
return HttpResponse('密码错误')
return HttpResponse('查无此人!')
return render(request, 'index.html')
# 错误示范
def edit_user(request):
user_id = request.GET.get('user_id')
if request.method == 'GET':
user = models.User.objects.filter(id=user_id).first()
return render(request, 'edit_user.html', locals())
user_id = request.GET.get('user_id')
username = request.POST.get('username')
password = request.POST.get('password')
print(username, password)
print(user_id)
result = models.User.objects.filter(id=user_id).update(username=username,
password=password)
print(result)
return redirect('/user_list/')
管理员修改用户信息
注意事项
- form 表单提交时,
action对应的值应该为空,如果对应的是跳转连接的话,后端无法获取?后面的内容- 思路:首先要有用户信息的的列表(这里新建页面
user_list)当我们点击编辑时,就要跳转到编辑页面edit_user(所以还得新建一个页面),在编辑页面更改完信息后提交到后端进行修改保存,然后再返回用户列表节目
#### user_list# views.py def user_list(request): user_query_set = models.User.objects.all() return render(request, 'user_list.html', locals())# user_list.html <body> <h1 class="text-center">用户列表</h1> <div class="container"> <div class="row"> <div class="col-md-8 col-md-offset-2"> <table class="table table-hover table-striped"> <thead> <tr> <th>ID</th> <th>username</th> <th>password</th> <th>action</th> </tr> </thead> <tbody> {% for user_obj in user_query_set %} <tr> <td>{{ user_obj.id }}</td> <td>{{ user_obj.username }}</td> <td>{{ user_obj.password }}</td> <td> <a href="/edit_user/?user_id={{ user_obj.id }}" class="btn btn-primary btn-xs">编辑</a> <a href="/delete_user/?user_id={{ user_obj.id }}" class="btn btn-danger btn-xs">删除</a> </td> </tr> {% endfor %} </tbody> </table> </div> </div> </div>
edit_list
# edit_list.py def edit_user(request): user_id = request.GET.get('user_id') if request.method == 'GET': user = models.User.objects.filter(id=user_id).first() return render(request, 'edit_user.html', locals()) user_id = request.GET.get('user_id') username = request.POST.get('username') password = request.POST.get('password') print(username, password) print(user_id) result = models.User.objects.filter(id=user_id).update(username=username, password=password) print(result) return redirect('/user_list/')# edit_user.html <body> <div class="container"> <div class="row"> <div class="col-md-8 col-md-offset-2"> <h1 class="text-center">登录</h1> <form action="" method="post"> username:<input type="text" name="username" class="form-control" value="{{ user.username }}"> password:<input type="password" name="password" class="form-control" value="{{ user.password }}"> <input type="submit" class="form-control danger"> </div> </div> </div>
删除用户
def delete_user(request):
user_id = request.GET.get('user_id')
models.User.objects.filter(id=user_id).delete()
return redirect('/user_list/')
django 生命周期

路由层
路由匹配
- 路由匹配支持正则表达式,如果不强制开头和结尾,url只要在
urlpatterns匹配到就算匹配成功。- 比如浏览器访问
/testssss/,urlpatterns中写url(r'/test/')也能匹配到
- 比如浏览器访问
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 首页
url(r'^$',views.home),
# 路由匹配
url(r'^test/$',views.test),
url(r'^testadd/$',views.testadd),
# 尾页(了解)
url(r'',views.error),
]
无名分组和有名分组
- 无名分组和有名分组不能混用,但是同一种分组可以使用多次
# 无名分组
"""
分组:就是给某一段正则表达式用小括号扩起来
"""
url(r'^test/(\d+)/',views.test)
def test(request,xx):
print(xx)
return HttpResponse('test')
# 无名分组就是将括号内正则表达式匹配到的内容当作位置参数传递给后面的视图函数
# 有名分组
"""
可以给正则表达式起一个别名
"""
url(r'^testadd/(?P<year>\d+)',views.testadd)
def testadd(request,year):
print(year)
return HttpResponse('testadd')
# 有名分组就是将括号内正则表达式匹配到的内容当作关键字参数传递给后面的视图函
反向解析
# 通过一些方法得到一个结果 该结果可以直接访问对应的url触发视图函数
# 先给路由与视图函数起一个别名
url(r'^func_kkk/',views.func,name='ooo')
# 反向解析
# 后端反向解析
from django.shortcuts import render,HttpResponse,redirect,reverse
reverse('ooo')
# 前端反向解析
<a href="{% url 'ooo' %}">111</a>
无名/有名分组反向解析
# 无名分组反向解析
url(r'^index/(\d+)/',views.index,name='xxx')
# 前端
{% url 'xxx' 123 %}
# 后端
reverse('xxx', args=(1,))
# 有名分组反向解析
url(r'^func/(?P<year>\d+)/',views.func,name='ooo')
# 前端
<a href="{% url 'ooo' 123 %}">222</a>
# 后端
reverse('ooo',args=(111,))
使用无名分组反向解析实现用户的编辑
def edit(request, user_id): # 需要传两个值
user_id = int(user_id)
if request.method == 'GET':
user = models.User.objects.filter(id=user_id).first()
return render(request, 'edit_user.html', locals())
username = request.POST.get('username')
password = request.POST.get('password')
models.User.objects.filter(id=user_id).update(username=username,
password=password)
return redirect('/user_list/')
<a href="{% url 'edit' user_obj.id %}" class="btn btn-primary btn-xs">编辑</a>
路由分发
# 总路由
from app01 import urls as app01_urls
from app02 import urls as app02_urls
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 1.路由分发
url(r'^app01/',include(app01_urls)), # 只要url前缀是app01开头 全部交给app01处理
url(r'^app02/',include(app02_urls)) # 只要url前缀是app02开头 全部交给app02处理
# 2.终极写法 推荐使用
url(r'^app01/',include('app01.urls')),
url(r'^app02/',include('app02.urls'))
# 注意事项:总路由里面的url千万不能加$结尾
]
# 子路由
# app01 urls.py
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^reg/',views.reg)
]
# app02 urls.py
from django.conf.urls import url
from app02 import views
urlpatterns = [
url(r'^reg/',views.reg)
]
django 个版本的区别
1.django1.X路由层使用的是url方法
而在django2.Xhe3.X版本中路由层使用的是path方法
url()第一个参数支持正则
path()第一个参数是不支持正则的 写什么就匹配什么
如果你习惯使用path那么也给你提供了另外一个方法
from django.urls import path, re_path
from django.conf.urls import url
re_path(r'^index/',index),
url(r'^login/',login)
2.X和3.X里面的re_path就等价于1.X里面的url
2.虽然path不支持正则 但是它的内部支持五种转换器
path('index/<int:id>/',index)
# 将第二个路由里面的内容先转成整型然后以关键字的形式传递给后面的视图函数
def index(request,id):
print(id,type(id))
return HttpResponse('index')
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
"""
3.模型层里面1.X外键默认都是级联更新删除的
但是到了2.X和3.X中需要你自己手动配置参数
models.ForeignKey(to='Publish')
models.ForeignKey(to='Publish',on_delete=models.CASCADE...)
"""
视图层
- 视图函数必须要返回一个HttpResponse对象
JsonResponse 对象
"""
json格式的数据有什么用?
前后端数据交互需要使用到json作为过渡 实现跨语言传输数据
前端序列化
JSON.stringify() json.dumps()
JSON.parse() json.loads()
"""
import json
from django.http import JsonResponse
## 不使用 JsonResponse
# 先转成json格式字符串
json_str = json.dumps(user_dict,ensure_ascii=False)
# 将该字符串返回
return HttpResponse(json_str)
# 使用 JsonResponse
return JsonResponse(user_dict,json_dumps_params={'ensure_ascii':False})
# 默认只能序列化字典 序列化其他需要加safe参数
return JsonResponse(l,safe=False)
form 表单接收文件
"""
form表单上传文件类型的数据
1.method必须指定成post
2.enctype必须换成formdata
"""
def ab_file(request):
if request.method == 'POST':
print(request.FILES) # 获取文件数据
# <MultiValueDict: {'file': [<InMemoryUploadedFile:u=1288812541,1979816195&fm=26&gp=0.jpg (image/jpeg)>]}>
file_obj = request.FILES.get('file') # 文件对象
with open(file_obj.name,'wb') as f:
for line in file_obj.chunks(): # 推荐加上chunks方法 其实跟不加是一样的都是一行行的读取
f.write(line)
return render(request,'form.html')
request 方法
request.method
request.POST
request.GET
request.FILES
request.body # 原生的浏览器发过来的二进制数据
request.path
request.path_info
request.get_full_path() # 能过获取完整的url及问号后面的参数
# 实例
print(request.path) # /app01/ab_file/
print(request.path_info) # /app01/ab_file/
print(request.get_full_path()) # /app01/ab_file/?username=jason
FBV 和 CBV
- 视图函数既可以是函数也可以是类
## FBV
def index(request):
return HttpResponse('index')
## CBV
# CBV路由:
"""
能够直接根据请求方式的不同直接匹配到对应的方法执行
"""
url(r'^login/',views.MyLogin.as_view())
# views.py
from django.views import View
class MyLogin(View):
def get(self,request):
return render(request,'form.html')
def post(self,request):
return HttpResponse('post方法')
CBV 如何添加装饰器
from django.utils.decorators import method_decorator
# 第一种
class MyCBV(View):
def get(self,request):
return HttpResponse()
@method_decorator(login_auth)
def post(self,request):
return HttpResponse()
# 第二种
@method_decorator(login_auth,name='post')
@method_decorator(index_de,name='get')
class MyCBV(View):
def get(self,request):
return HttpResponse()
def post(self,request):
return HttpResponse()
# 第三种
class MyCBV(View):
@method_decorator(login_auth)
def dispatch(self,request,*args,**kwargs):
super().dispatch(request,*args,**kwargs)
"""
看CBV源码可以得出 CBV里面所有的方法在执行之前都需要先经过
dispatch方法(该方法你可以看成是一个分发方法)
"""
def get(self,request):
return HttpResponse()
def post(self,request):
return HttpResponse()
模版语法
模版传值
{{}}变量{% %}逻辑判断
模版语法可以传递的后端 python 数据类型
- 整型、浮点型、字符串、列表、元组、字典、集合、函数等都可以
- 不过函数将函数名传过去会自动执行,并返回返回值,类也是如此
- 模版语法的取值:句点符
.,都是变量名.元素或索引或key
def login(request):
list001 = ['1', {'name': 'codeFun'}]
def func(): # 函数必须为无参函数
print('func is run...')
return '返回值'
class MyClass(object):
def __str__(self):
return self.__class__.__name__
def get_info(self):
print(self)
return render(request, 'index.html', locals())
<p>{{ list001.1.name }}</p> // codeFun
<p>{{ func }}</p> // 返回值
<p>{{ MyClass }}</p> // Myclass 执行的是 __str__
<p>{{ MyClass.get_info }}</p> // None 没有返回值
过滤器
- 基本语法:
{数据|过滤器名字:参数}
# 转义:
h_html = '<h1>hello world</h1>'
{{ h_html|safe }}
# 统计长度
{{ param_name|length }}
# 文件大小:将数字转换成带单位的数字比如 1024 会变成 1 KB
{{ file_size|filesizeformat }}
# 日期格式化: current_time 是时间对象
current_time = datetime.datetime.now()
{{ current_time|date:'Y-m-d H:i:s' }}
# 切片操作(支持步长)
{{ param_name|sice:'start_num:end_num:step' }}
# 切取字符(包含三个点)
info = '你好,这里是 codeFun 的博客,请友善言论,设计思路开始看'
{{ info|truncatechars:'21' }} # 你好,这里是 codeFun 的博客...
# 切取单词(不包含三个点,按照空格切)
info_en = "hello, this is codeFun's blog, please "
{{ info_en|truncatewords:'5' }} # hello, this is codeFun's blog, ...
# 移除特定字符
{{ str_name|cut:' ' }} # 清除空格
# 拼接(列表、元组、集合)
{{ iter_name|join:'$' }} # 使用 $ 将可迭代变量进行拼接
标签
for 循环
{% for foo in list001 %}
<p>{{ foo }}</p>
{% endfor %}
<!--
{% for 元素 in 可迭代变量(列表、元组、字典、集合等) %}
<p>{{ foo }}</p> 打印元素
{% endfor %}
-->
# forloop
# 可以使用 forloop.key_name 的形式去调用,比如 forloop.first 返回是否是第一个元素
{ 'parentloop': {},'counter0': 0, 'counter': 1, 'revcounter': 5, 'revcounter0': 4, 'first': True, 'last': False}
# {% empty %}
"""
当可迭代对象中没有元素时,执行它下面的代码块
"""
if 判断
{% if bool_object %}
{% elif bool_object001 %}
{% else %}
{% endif %}
with 起别名
{% with list001.0 as list001_first %}
<p>{{ list001_first }}</p>
{% endwith %}
自定义
-
自定义创建的三步骤:
-
在应用下创建一个名字必须叫
templatetags文件夹 -
在该文件内创建任意名称的 .py 文件
-
在 .py 文件中必须书写如下两句:
from django import template register = template.Library()
-
自定义过滤器
- 自定义过滤器中的函数最多有两个
# mytag.py
from django import template
register = template.Library()
@register.filter(name='sum_number')
def sum_number(num1, num2):
return num1 + num2
# 使用
{% load mytag %}
{{ num1|sum_number:10 }}
自定义标签
@register.simple_tag(name='date_format')
def date_format(year, month, day):
return f'{year}-{month}-{day}'
# 使用
# views.py
year = 2023
month = 5
day = 3
# index.html
{% load mytag %}
{% date_format year month day %}
自定义inclusion_tag
- 内部原理:
- 先定义一个方法,
- 在页面上调用该方法,方法返回的数据会传递给另一个 html 页面,
- 之后将渲染好的结果放到调用的位置
@register.inclusion_tag('inclusion.html')
def inclusion(num):
data = ['第{}项'.format(i) for i in range(num)]
return locals()
inclusion.html
<ul>
{% for datum in data %}
<li>{{ datum }}</li>
{% endfor %}
</ul>
# 使用
<p>{% inclusion 10 %}</p>
模版的继承
- 当多个页面的相同的内容较多时,可以使用模版的继承来减少代码的冗余
# 想要继承的子页面中写入如下代码
{% extends 'home.html' %}
# 被继承的页面中还可以划定需要修改的内容
{% block content %}
模版内容
{% endblock %}
# 通过上一步的操作就可以修改划定了的区域
{% block content %}
子页面内容
{% block.super %} # 可以将模版的内容全部拿过来
{% endblock %}
# 一般情况下模版页面上应该至少有三块可以被修改的区域
# 每一个子页面就都可以有自己独有的css代码 html代码 js代码
"""
1.css区域
{% block css %}
{% endblock %}
2.html区域
{% block content %}
{% endblock %}
3.js区域
{% block js %}
{% endblock %}
"""
模版的导入
- 如果有一部分的前端代码需要多次使用,这里为了减少代码的冗余,可以使用模版的导入
<!-- 在需要导入的地方直接导入即可,对于 wasai.html 没有额外要求 -->
{% include 'wasai.html' %}
模型层
创建测试环境
# 创建测试表
class Test_user(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
register_time = models.DateField() # 年月日
# register_time 可以接受时间格式、也可以是字符串
"""
关于 models.DateFiled 中的参数:
auto_now_add 记录创建时间
auto_now 记录创建时间和修改时间
"""
# 多表查询的环境
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2)
publish_date = models.DateField(auto_now_add=True)
# 书和出版社是多对多的关系
publish = models.ForeignKey(to='Publish')
# 书和作者是一对多的关系
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
email = models.EmailField()
def __str__(self):
return f'对象:{self.name}'
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 作者表和作者详情表是一对一
author_detail = models.OneToOneField(to='AuthorDetail')
class AuthorDetail(models.Model):
phone = models.BigIntegerField()
addr = models.CharField(max_length=64)
# 创建测试环境
# test.py
from django.test import TestCase
# 来自于 manage.py 的前四行代码
import os
import sys
# Create your tests here.
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "djangoStudy.settings")
################### 以上测试环境完成 ##############################
import models
models.Test_user.objects.all()
必知必会十三条
models.table_class.objects.x
# x 可以是下面的十三条
.all() # 查询所有数据
.filter() # 带有过滤条件的查询
.get() # 直接拿数据对象 但是条件不存在直接报错
.first() # 拿queryset里面第一个元素
first_obj = models.User.objects.all().first()
.last() # 拿 queryset 里面最后一个元素
last_obj = models.User.objects.all().last()
.values() # 可以指定获取的数据字段,类似 select name,age from ...
user_querySet001 = models.Test_user.objects.filter(pk=1).values('name')
print(user_querySet001[0]['name']) # codeFun 获取的是列表套字典
.values_list() # 列表套元祖
.distinct() 去重
.order_by()
query_set = models.Test_user.objects.order_by('-age') # 降序排列,不加减号顺序
print(query_set) # <QuerySet [<Test_user: jack-20>, <Test_user: codeFun-18>]>
# 10.reverse() 反转的前提是 数据已经排过序了 order_by()
# res = models.User.objects.all()
# res1 = models.User.objects.order_by('age').reverse()
# print(res,res1)
# 11.count() 统计当前数据的个数
# res = models.User.objects.count()
# print(res)
# 12.exclude() 排除在外
# res = models.User.objects.exclude(name='jason')
# print(res)
# 13.exists() 基本用不到因为数据本身就自带布尔值 返回的是布尔值
# res = models.User.objects.filter(pk=10).exists()
# print(res)
获取封装的 SQL 语句
# 方式1
res = models.User.objects.values_list('name','age') # <QuerySet [('jason', 18), ('egonPPP', 84)]>
print(res.query)
queryset对象才能够点击query查看内部的sql语句
# 方式2:所有的sql语句都能查看
# 去配置文件中配置一下即可,在打印返回值的时候打印打印出 SQL 语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
双下划线查询
# 形式:变量名__条件=值
models.User.objects.filter(age__gt=35) # 找出年龄大于 35 的数据
# 条件
__gt # 大于
__lt # 小于
__gte # 大于等于
__lte # 小于等于
__in
....filter(age__in=[18,30]) # 找出年龄在 18 和 30 岁
__range
....filter(age__in=[18,30]) # 找出年龄在 18 和 30 岁之间的(包含 18 和 30)
__contains # 包含字符串
....filter(name_contains='s') # 找出名字中包含字符 s 的
__icontains # 包含字符串,不区分大小写
__startswith # 以什么字符串开头
__endswith # 以什么字符串结尾
__month # 指定月份
__year # 指定年份
一对多外键增删改
# 增
# 通过 id 号增加
models.Book.objects.create(title='论语',price=33.33,publish_id=1)
# 通过添加对象增
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.create(title='道德经',price=43.33,publish=publish_obj)
# 删
models.Publish.objects.filter(pk=1).delete() # 级联删除
# 修改
models.Book.objects.filter(pk=1).update(publish_id=2)
publish_obj = models.Publish.objects.filter(pk=1).first()
models.Book.objects.filter(pk=1).update(publish=publish_obj)
多对多外键增删改
# 增加
# add() 括号内可以放多个数据
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.add(1)
author_obj = models.Author.objects.filter(pk=2).first()
book_obj.authors.add(author_obj)
# 结果
+----+---------+-----------+
| id | book_id | author_id |
+----+---------+-----------+
| 2 | 1 | 1 |
| 3 | 1 | 2 |
+----+---------+-----------+
# 删除 remove
# 修改 set([])
book_obj.authors.set([1,2]) | 2 | 1 | 2 |
# 清空 clear()
多表查询
- 正向和反向查询
- 比如外键字段在 A 表上,通过 A 表查询 B 表的数据,就是正向查询。通过 B 表查询 A 表则是反向查询。
- 正向查询按字段,反向查询按表名小写
# 1. 查询书籍主键为 1 的出版社的名字和地址
book_obj = models.Book.objects.filter(pk=1).first()
publish_obj = book_obj.publish
print(publish_obj.name,publish_obj.addr) # 蓝星出版社 earth
# 2. 查询书籍主键为 2 的作者
"""
当查询内容可能是多个时,需要加 .all()
"""
book_obj = models.Book.objects.filter(pk=2).first()
author_obj = book_obj.authors.all()
print(author_obj)
# 3. 查询作者 codeFun 的电话号码
author_obj = models.Author.objects.filter(name='codeFun').first()
author_detail_obj = author_obj.author_detail
print(author_detail_obj.phone)
# 4. 查询出版社是蓝星出版社出版的书
"""
当查询内容可能是多个时,需要加 _set.all()
"""
publish_obj = models.Publish.objects.filter(name='蓝星出版社').first()
book_objs = publish_obj.book_set.all()
print(book_objs.first().title) # 论语
# 5. 查询作者是 codeFun 的书
author_obj = models.Author.objects.filter(name='codeFun').first()
book_objs = author_obj.book_set.all()
print(book_objs.first().title) # 论语
基于双下划线的跨表查询
# 1. 查询 codeFun 的手机号和作者姓名和年龄
res_query_set = models.Author.objects.filter(name='codeFun').values('name', 'age', 'author_detail__phone')
print(res_query_set) # <QuerySet [{'name': 'codeFun', 'age': 18, 'author_detail__phone': 111}]>
# 反向
res_query_set = models.AuthorDetail.objects.filter(author__name='codeFun').values('author__name', 'phone', 'author__age')
print(res_query_set)
# 2. 查询书籍主键为 1 的出版社名称和书籍的名称
res_query_set = models.Book.objects.filter(pk=1).values('publish__name', 'title')
print(res_query_set) # <QuerySet [{'publish__name': '蓝星出版社', 'title': '论语'}]>
res_query_set = models.Publish.objects.filter(book__pk=1).values('book__title', 'name')
print(res_query_set)
# 3. 查询书籍主键为 1 的作者姓名
res_query_set = models.Book.objects.filter(pk=1).values('authors__name')
print(res_query_set) # QuerySet [{'authors__name': 'codeFun'}]>
# 4. 查询书籍主键是 1 的作者的手机号
res_query_set = models.Book.objects.filter(pk=1).values('authors__author_detail__phone')
print(res_query_set) # <QuerySet [{'authors__author_detail__phone': 111}]>
聚合函数的使用
from django.db.models import Max, Sum, Min, Count, Avg
"""
注意:使用 aggregate 方法
"""
# 1. 查询所有书的平均价格、最大价格、书的数量
res = models.Book.objects.aggregate(Avg('price'), Sum('price'), Count('pk'))
print(res) # {'price__avg': 51.696667, 'price__sum': Decimal('310.18'), 'pk__count': 6}
分组查询
- ?
models.Book.objects.annotate()按照图书进行分组(models 后面点什么,就按照什么分组) models.Book.objects.values('price').annotate()按照图书表中的价格进行分组
# 1. 统计每一本书的作者个数
res = models.Book.objects.annotate(author_num=Count('authors')).values('title', 'author_num')
print(res)
# 2. 统计每个出版社卖的最便宜的书的价格
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price', 'book__title')
print(res)
# 3. 统计不止一个作者的图书
# 先按照图书进行分组,求每一本图书对应的作者个数
# 过滤出不止一个作者的图书
res = models.Book.objects.annotate(author_num=Count('authors')).filter(author_num__gt=1).values('title',
'author_num')
print(res)
# 4. 查询每个作者的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price')
print(res)
F和Q查询
F 查询
- 直接获取表中某个字段对应的数据
from django.db.models import F
# 1. 查询出货量大于库存的书籍
res = models.Book.objects.filter(sold__gt=F('stock')).values('title')
print(res)
# 2. 将所有书籍的价格提高 100 块
models.Book.objects.update(price=F('price') + 100)
# 3. 在书名后面加上爆款两字
# F 不能直接做到字符串拼接
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.update(title=Concat(F('title'), Value('爆款')))
Q 查询
- 可以将
filter()函数默认的and关系改成or、not关系 - 可以将查询条件的左边变成字符串的形式
"""
Q() , Q() and
~ Q() , Q() not
Q() | Q() or
"""
# 1. 查询出价格大于 130 或小于 120 的图书名称
from django.db.models import Q
res = models.Book.objects.filter(Q(price__gt=130) | Q(price__lt=120)).values('title', 'price')
print(res)
# 1. 查询出价格大于 130 或小于 120 的图书名称
from django.db.models import Q
q = Q()
q.connector = 'or' # 默认 and
q.children.append(('price__gt', 130))
q.children.append(('price__lt', 120))
res = models.Book.objects.filter(q).values('title', 'price')
print(res)
Django 中开启事务
- 事务的四个特性(ACID)
- 原子性:不可分割的最小单位
- 一致性:跟原子性相辅相成
- 隔离性:事务之间互相不干扰
- 持久性:事务一旦确认永久生效
from django.db import transaction
try:
with transaction.atomic():
# sql1
# sql2
...
# 在with代码快内书写的所有orm操作都是属于同一个事务
except Exception as e:
print(e)
print('执行其他操作')
orm 中常用字段及参数
AutoField
主键字段 primary_key=True
CharFiled # varchar
verbose_name # 字段的注释
max_length # 长度
IntegerFiled # int
BingIntegerField # bigint
DecimalField
max_digits=8 # 数字允许最大位数
decimal_places=2 # 小数允许的最大位数
EmailFiled # varchar(254)
DateField # date
DateTimeField # datetime
auto_now # 每次修改数据的时候都会自动更新当前时间
auto_now_add # 只在创建数据的时候记录创建时间后续不会自动修改了
BooleanField(Field) # 布尔值类型,该字段传布尔值(False/True) 数据库里面存0/1
TextField(Field) # 文本类型
# 该字段可以用来存大段内容(文章、博客...) 没有字数限制
FileField(Field) # 字符类型
upload_to = "/data" # 给该字段传一个文件对象,会自动将文件保存到/data目录下然后将文件路径保存到数据库中
参考博客:https://www.cnblogs.com/Dominic-Ji/p/9203990.html
自定义字段
class MyCharField(models.Field):
def __init__(self,max_length,*args,**kwargs):
self.max_length = max_length
# 调用父类的init方法
super().__init__(max_length=max_length,*args,**kwargs) # 一定要是关键字的形式传入
def db_type(self, connection):
"""
返回真正的数据类型及各种约束条件
:param connection:
:return:
"""
return 'char(%s)'%self.max_length
# 自定义字段使用
myfield = MyCharField(max_length=16,null=True)
外键字段即参数
unique=True
ForeignKey(unique=True) === OneToOneField()
# 你在用前面字段创建一对一 orm会有一个提示信息 orm推荐你使用后者但是前者也能用
db_index
如果db_index=True 则代表着为此字段设置索引
to_field
设置要关联的表的字段 默认不写关联的就是另外一张的主键字段
on_delete
当删除关联表中的数据时,当前表与其关联的行的行为。
"""
django2.X及以上版本 需要你自己指定外键字段的级联更新级联删除
"""
数据库查询优化
- orm 语句的特点:
- 惰性查询:如果我们仅仅只是书写了 orm 语句,但是在后面没有用到该语句所查询出来的数据,那么 orm 会自动识别,并且不执行该语句
only 和 defer
- only 预先查询括号内的数据,defer 预先查找括号内以外的内容
res = models.Book.objects.only('title')
for i in res:
print(i.title) # 会预先就将 title 放到内存
print(i.price) # 会向数据库现查,然后返回数据
res = models.Book.objects.defer('title')
for i in res:
print(i.title) # 会向数据库现查,然后返回数据
print(i.price) # 会预先就将 title 放到内存
select_related 和 prefectch_related
- 和跨表操作有关
- select_related 会先将多张表连接成一张大表,然后一次性将大表里面的所有数据全部封装成对象返回
- select_related 只能 一对一 一对多 【多对多不行】
- prefectch_related 内部是子查询,将子查询查询出来的所有结果封装到对象返回
res = models.Book.objects.all()
for i in res:
print(i.publish.name) # 每循环一次就要走一次数据库查询
res = models.Book.objects.select_related('authors') # INNER JOIN
for i in res:
print(i.publish.name) # 每循环一次就要走一次数据库查询
res = models.Book.objects.prefetch_related('publish') # 子查询
for i in res:
print(i.publish.name)
choices 参数
"""
在设计表的时候 针对可以列举完全的可能性字段
一般都是用choices参数
"""
gender_choices = ((1,'male'),(2,'female'),(3,'others'))
gender = models.IntegerField()
# 针对具有choices参数的字段 存储数据的时候还是按照字段本身的数据类型存储没有其他的约束,但是如果存的字段在你列举的范围内 那么可以自动获取对应关系
user_obj.gender # 数字
user_obj.get_gender_display() # 固定格式 get_choices参数字段名_display()
"""有对应关系就拿对应关系,没有则还是数据本身不会报错"""
批量插入数据
def batch_insert(request):
# 创建空列表
user_list = []
for i in range(100):
# 创建相应的表对象
user_obj = models.MoreUser(username=f'用户 {i} 号')
# 将表对象添加至空列表
user_list.append(user_obj)
# 将装有表对象的列表放进 bulk_create 方法中即可批量插入数据
models.MoreUser.objects.bulk_create(user_list)
user_queryset = models.MoreUser.objects.all()
return render(request, 'batch_insert.html',locals())
多对多三种创建方式
# 全自动:利用orm自动帮我们创建第三张关系表
class Book(models.Model):
name = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author')
class Author(models.Model):
name = models.CharField(max_length=32)
"""
优点:代码不需要你写 非常的方便 还支持orm提供操作第三张关系表的方法...
不足之处:第三张关系表的扩展性极差(没有办法额外添加字段...)
"""
# 纯手动
class Book(models.Model):
name = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model):
book_id = models.ForeignKey(to='Book')
author_id = models.ForeignKey(to='Author')
'''
优点:第三张表完全取决于程序员进行额外的扩展
不足之处:需要写的代码较多,不能够再使用orm提供的简单的方法
'''
# 半自动
class Book(models.Model):
name = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author',
through='Book2Author',
through_fields=('book','author')
)
class Author(models.Model):
name = models.CharField(max_length=32)
# books = models.ManyToManyField(to='Book',
# through='Book2Author',
# through_fields=('author','book')
# )
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
"""
through_fields字段先后顺序
判断的本质:
通过第三张表查询对应的表 需要用到哪个字段就把哪个字段放前面
你也可以简化判断
当前表是谁 就把对应的关联字段放前面
半自动:可以使用orm的正反向查询 但是没法使用add,set,remove,clear这四个方法
"""
Ajax
Ajax 简介
- 功能:异步提交,局部刷新
- 能够向服务器发送 GET 和 POST 请求
- 定位:不是新的编程语言,而是一种使用现有标准的新方法(类似装饰器)
- 优点:在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容,给用户在不知不觉中完成请求和响应的感觉
- 使用前提:在使用 Ajax 的前,要导入 jQuery
整体框架
/*
注意:当前后端传输的数据不是字符串时,注意序列化和反序列化
*/
$('#submit').click(
function (){
$.ajax({
// 1. 指定朝哪个后端发送 Ajax 请求
url: '', // 朝当前地址提价
// 2. 请求方式
type: 'post', // 默认 get 请求
// 3. 数据 (前端数据)
data:{'a':$('#a').val(),'b':$('#b').val()},
// 4. 回调函数: 当后端给你返回结果的时候会自动触发,
success:function (args) { // args 接收后端的返回结果
$('#result').val(args)
}
})
}
)
小案例:实现普通的加法运算
- 输入两个数字,点击按钮,向后端发送 Ajax 请求,后端算出结果,再返回给前端动态展示的 input 框中
# 后端
def ajax(request):
if request.method == 'POST':
# print(request.POST) # <QueryDict: {'username': ['codeFun'], 'age': ['18']}>
a = request.POST.get('a')
b = request.POST.get('b')
result = int(a) + int(b)
return HttpResponse(result)
return render(request, 'ajax.html')
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>ajax</title>
{% load static %}
<script src="{% static 'bootstrap-3.4.1-dist/js/bootstrap.min.js' %}"></script>
<link rel="stylesheet" href="{% static 'bootstrap-3.4.1-dist/css/bootstrap.min.css' %}">
<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script>
</head>
<body>
<input type="text" name="a" id="a"> +
<input type="text" name="b" id="b"> =
<input type="text" name="result" id="result">
<button id="submit">提交</button>
<script>
$('#submit').click(
function (){
$.ajax({
// 1. 指定朝哪个后端发送 Ajax 请求
url: '', // 朝当前地址提价
// 2. 请求方式
type: 'post', // 默认 get 请求
// 3. 数据 (前端数据)
data:{'a':$('#a').val(),'b':$('#b').val()},
// 4. 回调函数: 当后端给你返回结果的时候会自动触发, args 接收后端的返回结果
success:function (args) {
{#alert(args)#}
$('#result').val(args)
}
})
}
)
</script>
</body>
</html>
前后端传输数据的编码格式
- 前后端传输数据可以通过 get 和 post 两种请求,而 get 请求的数据就是直接放在 URL 后面
url?name=codeFun&age=18 - 所以这里我们仅研究 post 请求,能够发送 post 请求目前之有两个 form 表单,Ajax 请求
- 前后端传输数据编码格式:
urlencoded、formdata、json
form 表单
- 默认的数据编码格式为
urlencoded, 数据格式为name=codeFun&age=18- django 后端针对符合
urlencoded都会自动解析封装到request.POST中
- django 后端针对符合
- 如果将格式改成
formdata【<form action="" method="post" enctype="multipart/form-data">】,对于普通的键值对还是request.POST, 对于文件会解析到request.FILES - form 表单无法发送JSON格式的数据
Ajax
- 默认的数据编码格式为
urlencoded - ajax 发送 json 格式数据
- 前后端传输的数据一定确保编码格式跟数据真正的格式是一致的
$('#btn').click(function(){
$.ajax({
url: '',
type: 'post',
// 设置传送数据格式为 json
contentType: 'application/json',
// 将数据转为 json 格式并发送
data: JSON.stringify({'username':'codeFun', 'age':18}),
success:function(){
}
})
}
)
def ajax(request):
if request.method == 'POST':
# 判断是否是 ajax 请求
if request.is_ajax():
# 获取前端的 json 对象
json_byte = request.body
print(request.body) # b'{"username":"codeFun","age":18}'
python_dict = json.loads(json_byte) # 将 json字典 转换为 python 字典
print(json_dict['username']) # 取字典中的值
return render(request, 'ajax.html')
通过 ajax 向后端发送文件
- ajax 发送文件需要借助于 js 内置对象 FormData
<body>
<input type="text" name="username" id="username">
<input type="file" name="file" id="d3">
<button id="d1">提交</button>
<script>
$('#d1').on('click',function () {
let formDataObj = new FormData()
formDataObj.append('username',$('#username').val())
formDataObj.append('myfile',$('#d3')[0].files[0])
$.ajax({
url: '',
type: 'post',
data: formDataObj,
contentType: false,
processData: false,
success: function (args) {
}
})
})
</script>
</body>
def ajax_file(request):
if request.method == 'POST':
print(request.POST)
print(request.FILES)
file_obj = request.FILES.get('myfile')
with open(file_obj.name,'wb') as f:
for line in file_obj.chunks():
f.write(line)
return render(request, 'ajax_file.html')
后端向前端传送 json 数据
$.ajax({
// 自动将后端传来的 json 数据进行解码
dataType:'JSON',
})
dict001 = {'name':'codeFun', 'age': 18}
json.dump()
ajax 和 sweetalert 实现二次确认
- sweetalert 官网:https://lipis.github.io/bootstrap-sweetalert/
def ajax_list(request):
user_queryset = models.User.objects.all()
return render(request, 'ajax_list.html', locals())
def ajax_list001(request):
if request.is_ajax():
if request.method == 'POST':
# 状态字典,返回给前端,前端根据状态码来进行相应的操作
request_dict = {'code': 1000, 'msg': '您的这个文件彻底删除了'}
del_id = request.POST.get('del_id')
result = models.User.objects.filter(pk=del_id).delete()
return JsonResponse(request_dict)
<body>
<div class="container-fluid">
<h1 class="text-center">数据展示</h1>
<div class="row">
<div class="col-md-8 col-md-offset-2">
<table class="table-striped table-hover table">
<thead>
<tr>
<th>ID</th>
<th>username</th>
<th>password</th>
</tr>
</thead>
<tbody>
{% for user_obj in user_queryset %}
<tr>
<td>{{ user_obj.pk }}</td>
<td>{{ user_obj.username }}</td>
<td>{{ user_obj.password }}</td>
<td>
<button class="btn btn-primary btn-xs edit">编辑</button>
<!-- 将 id 值赋值给 del_id -->
<button class="btn btn-danger btn-xs del" del_id="{{ user_obj.pk }}">删除</button>
</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
</div>
<script>
$('.del').on('click',function () {
// 获取 del_id 对应的值
//alert($(this).attr('del_id'))
let currentBtn = $(this)
// 二次确认框
swal({
title: "你确定要删除吗?",
text: "你将无法在回收站找到他们!",
type: "warning",
showCancelButton: true,
confirmButtonClass: "btn-danger",
confirmButtonText: "是的,删除它!",
cancelButtonText: "不,取消!",
closeOnConfirm: false,
closeOnCancel: false
},
function(isConfirm) {
if (isConfirm) {
$.ajax({
url: '/ajax_list001/',
type: 'post',
data: {'del_id':currentBtn.attr('del_id')},
success: function (args) {
// 获取后端的信息
if (args.code === 1000){
swal("删除了!", args.msg, "success");
// 直接刷新当前页面
// window.location.reload()
// 利用 DOM 操作,动态刷新
currentBtn.parent().parent().remove()
}else {
swal("删除了!", "未知错误", "info");
}
}
})
} else {
swal("取消了", "你的这个文件现在安全了)", "error");
}
});
})
</script>
</body>
自定义分页器
# 自定义的模块要放到 utils 下
from utils.mypage import Pagination
def batch_insert(request):
# 获取列取对象的 queryset
user_queryset = models.MoreUser.objects.all()
# 确认当前页是第几页
current_page = request.GET.get('page', 1)
# 获取列取对象的数量
all_count = user_queryset.count()
# 创建分页器对象,还可以 per_page_num=10, pager_count=11 指定每页多少个,每页放多少个页码按钮
page_obj = Pagination(current_page=current_page, all_count=all_count)
# 将列取对象进行切片,获取
page_queryset = user_queryset[page_obj.start:page_obj.end]
return render(request, 'batch_insert.html', locals())
<body>
<ul>
遍历切片好的列取对象
{% for user_obj in pag_queryset %}
<li>{{ user_obj.username }}</li>
{% endfor %}
获取后端生成好的 html 页面
{{ page_obj.page_html|safe }}
</ul>
</body>
# 分页器代码
class Pagination(object):
def __init__(self, current_page, all_count, per_page_num=10, pager_count=11):
"""
封装分页相关数据
:param current_page: 当前页
:param all_count: 数据库中的数据总条数
:param per_page_num: 每页显示的数据条数
:param pager_count: 最多显示的页码个数
"""
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
if current_page < 1:
current_page = 1
self.current_page = current_page
self.all_count = all_count
self.per_page_num = per_page_num
# 总页码
all_pager, tmp = divmod(all_count, per_page_num)
if tmp:
all_pager += 1
self.all_pager = all_pager
self.pager_count = pager_count
self.pager_count_half = int((pager_count - 1) / 2)
@property
def start(self):
return (self.current_page - 1) * self.per_page_num
@property
def end(self):
return self.current_page * self.per_page_num
def page_html(self):
# 如果总页码 < 11个:
if self.all_pager <= self.pager_count:
pager_start = 1
pager_end = self.all_pager + 1
# 总页码 > 11
else:
# 当前页如果<=页面上最多显示11/2个页码
if self.current_page <= self.pager_count_half:
pager_start = 1
pager_end = self.pager_count + 1
# 当前页大于5
else:
# 页码翻到最后
if (self.current_page + self.pager_count_half) > self.all_pager:
pager_end = self.all_pager + 1
pager_start = self.all_pager - self.pager_count + 1
else:
pager_start = self.current_page - self.pager_count_half
pager_end = self.current_page + self.pager_count_half + 1
page_html_list = []
# 添加前面的nav和ul标签
page_html_list.append('''
<nav aria-label='Page navigation>'
<ul class='pagination'>
''')
first_page = '<li><a href="?page=%s">首页</a></li>' % (1)
page_html_list.append(first_page)
if self.current_page <= 1:
prev_page = '<li class="disabled"><a href="#">上一页</a></li>'
else:
prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)
page_html_list.append(prev_page)
for i in range(pager_start, pager_end):
if i == self.current_page:
temp = '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i,)
else:
temp = '<li><a href="?page=%s">%s</a></li>' % (i, i,)
page_html_list.append(temp)
if self.current_page >= self.all_pager:
next_page = '<li class="disabled"><a href="#">下一页</a></li>'
else:
next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)
page_html_list.append(next_page)
last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)
page_html_list.append(last_page)
# 尾部添加标签
page_html_list.append('''
</nav>
</ul>
''')
return ''.join(page_html_list)
组件和模块
forms 组件
不使用 forms 组件
- 不使用 forms 组件实现向 form 表单中输入错误信息并提示。
- 通过占位符的形式,先在 input 框左边放上没有内容的 span 在没有错误时,用户是看不见内容的,当用户输入了错误的内容再将错误信息填入 span 框,实现向 form 表单中输入错误信息并提示。
def ab_form(request):
# 先在 span 中放入空内容
username_error = ''
password_error = ''
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
email = request.POST.get('email')
if len(username) < 3:
# 根据错误原因将错误信息填入
username_error = '用户名小于三位数'
if len(password) < 3:
password_error = '用户名小于三位数'
return render(request, 'ab_form.html', locals())
<form action="" method="post">
<p>用户名:<input type="text" name="username">
<!-- 获取错误信息 -->
<span style="color: red" id="d1">{{ username_error }}</span>
</p>
<p>密码:<input type="text" name="password">
<span style="color: red" id="d2">{{ password_error }}</span>
</p>
<p>邮箱:<input type="text" name="email">
<span style="color: red" id="d3"></span>
</p>
<p><input type="submit" id="d4"></p>
</form>
forms 组件的使用流程
通过 forms 组件的使用实现上上述问题。
-
创建并实例化 form 类
from django import forms # forms 类的创建和数据库差不多 class MyForm(forms.Form): username = forms.CharField(min_length=3, max_length=8) password = forms.CharField(min_length=6) email = forms.EmailField() def ab_forms(request): # 产生空对象 forms_obj = MyForms() if request.method == 'POST': # 获取用户数据 forms_obj = MyForms(request.POST) # 校验数据 if forms_obj.is_valid(): # 如果数据合法,就应该将数据保存到数据库 pass # 如果是 get 请求就传入空对象,如果是 post 请求就传入校验后的对象 return render(request,'ab_forms.html',locals()) -
前端代码的编写
<!-- novaildata 禁用前端校验 --> <form action="" method="post" novalidate> {% for form_obj in forms_obj %} <!-- form_obj.label 默认为变量名首字母大写 form_obj 默认为 input-text 框 form_obj.errors.0 为默认生成的错误信息 --> <p>{{ form_obj.label }}:{{ form_obj }} <span>{{ form_obj.errors.0 }}</span></p> {% endfor %} <input type="submit"> </form>
校验数据细则
- 校验数据会进行一一对应的原则,当传入的数据多于校验的字段时,多传的字段直接忽略
- 而若少传数据时,就可能触发
required错误
- 而若少传数据时,就可能触发
# 1 将带校验的数据组织成字典的形式传入即可
form_obj = views.MyForm({'username':'jason','password':'123','email':'123'})
# 2 判断数据是否合法,全部合法返回True
form_obj.is_valid() # False
# 3 查看所有校验通过的数据
form_obj.cleaned_data # {'username': 'jason', 'password': '123'}
# 4 查看所有不符合校验规则以及不符合的原因
form_obj.errors # { 'email': ['Enter a valid email address.']}
# 5 校验数据只校验类中出现的字段 多传不影响 多传的字段直接忽略
form_obj = views.MyForm({'username':'jason','password':'123','email':'123@qq.com','hobby':'study'})
form_obj.is_valid() # True
# 6 校验数据 默认情况下 类里面所有的字段都必须传值
form_obj = views.MyForm({'username':'jason','password':'123'})
form_obj.is_valid()
False
"""
也就意味着校验数据的时候 默认情况下数据可以多传但是绝不可能少传
"""
前端渲染细则
<!--
forms组件只会自动帮你渲染获取用户输入的标签(input select radio checkbox)
不能帮你渲染提交按钮
<!-- -->
<!-- 第一种渲染方式:代码书写极少,封装程度太高 不便于后续的扩展 一般情况下只在本地测试使用 -->
{{ form_obj.as_p }}
{{ form_obj.as_ul }}
{{ form_obj.as_table }}
<!-- 第二种渲染方式:可扩展性很强 但是需要书写的代码太多 一般情况下不用 -->
<p>{{ form_obj.username.label }}:{{ form_obj.username }}</p>
<p>{{ form_obj.password.label }}:{{ form_obj.password }}</p>
<p>{{ form_obj.email.label }}:{{ form_obj.email }}</p>
<!-- 第三种渲染方式(推荐使用):代码书写简单 并且扩展性也高 -->
{% for form in form_obj %}
<p>{{ form.label }}:{{ form }}</p>
{% endfor %}
xxField() 函数内的参数
label # 字段名
error_messages # 自定义报错信息
initial # 默认值
required # 是否必填
# 添加标签属性
# 注意:多个属性之直接用逗号隔开即可
widget=forms.widgets.PasswordInput(attrs={'class':'form-control c1 c2'})
# 第一道关卡里面还支持正则校验
validators=[
RegexValidator(r'^[0-9]+$', '请输入数字'),
RegexValidator(r'^159[0-9]+$', '数字必须以159开头')
]
示例:
username = forms.CharField(
min_length=3,max_length=8,label='用户名',
error_messages={
'min_length':'用户名最少3位',
'max_length':'用户名最大8位',
'required':"用户名不能为空"
}
email = forms.EmailField(
label='邮箱',
error_messages={
'invalid':'邮箱格式不正确',
'required': "邮箱不能为空"
}
)
其他类型的渲染
# radio
gender = forms.ChoiceField(
choices=((1, "男"), (2, "女"), (3, "保密")),
label="性别",
initial=3,
widget=forms.widgets.RadioSelect()
)
# select
hobby = forms.ChoiceField(
choices=((1, "篮球"), (2, "足球"), (3, "双色球"),),
label="爱好",
initial=3,
widget=forms.widgets.Select()
)
# 多选
hobby1 = forms.MultipleChoiceField(
choices=((1, "篮球"), (2, "足球"), (3, "双色球"),),
label="爱好",
initial=[1, 3],
widget=forms.widgets.SelectMultiple()
)
# 单选checkbox
keep = forms.ChoiceField(
label="是否记住密码",
initial="checked",
widget=forms.widgets.CheckboxInput()
)
# 多选checkbox
hobby2 = forms.MultipleChoiceField(
choices=((1, "篮球"), (2, "足球"), (3, "双色球"),),
label="爱好",
initial=[1, 3],
widget=forms.widgets.CheckboxSelectMultiple()
)
钩子函数
-
钩子函数:在特定的节点自动触发完成响应操作
-
在 forms 组件中类似第二道关卡,能够让我们自定义校验规则
- 第一道关卡:xxFiled() 函数的参数限制
- 分类:
- 局部钩子:单个字段校验规则的时候使用
- 全局钩子:多个字段校验规则的时候使用
-
实际案例
# 局部钩子:校验用户名中不能含有 666
def clean_username(self):
# 获取到用户名
username = self.cleaned_data.get('username')
if '666' in username:
# 提示前端展示错误信息
self.add_error('username','光喊666是不行滴~')
# 将钩子函数钩去出来数据再放回去
return username
# 全局钩子:校验密码和确认密码是否一致
def clean(self):
password = self.cleaned_data.get('password')
confirm_password = self.cleaned_data.get('confirm_password')
if not confirm_password == password:
self.add_error('confirm_password','两次密码不一致')
# 将钩子函数钩出来数据再放回去
return self.cleaned_data
auth 模块
- auth 模块可以操作 auth_user 表,而且还配套了很多方法,如查看用户名和密码是否一致,判断当前用户是否登录等
- 我们可以使用 auth 模块来实现用户的登录和注册
auth 创建超级管理员
python manage.py createsuperuser
auth 模块常用的方法
# 1.比对用户名和密码是否正确
from django.contrib import auth
user_obj = auth.authenticate(request,username=username,password=password)
# 括号内必须同时传入用户名和密码
print(user_obj) # 用户对象 jason 数据不符合则返回None
print(user_obj.username) # jason
print(user_obj.password) # 密文
# 2.保存用户状态
# 主要执行了该方法 你就可以在任何地方通过request.user获取到当前登陆的用户对象
auth.login(request,user_obj) # 类似于request.session[key] = user_obj
# 3.判断当前用户是否登陆
request.user.is_authenticated()
# 4.获取当前登陆用户
request.user
request.user.username # 获取当前对象的名字
# 5.校验用户是否登陆装饰器
from django.contrib.auth.decorators import login_required
# 局部配置(优先匹配)
@login_required(login_url='/login/')
# 全局配置
LOGIN_URL = '/login/'
# 6.比对原密码
request.user.check_password(old_password)
# 7.修改密码
request.user.set_password(new_password) # 仅仅是在修改对象的属性
request.user.save() # 这一步才是真正的操作数据库
# 8.注销
auth.logout(request)
# 9.注册
# 操作auth_user表写入数据
User.objects.create(username=username,password=password) # 写入数据 不能用create 密码没有加密处理
# 创建普通用户
User.objects.create_user(username=username,password=password)
# 创建超级用户(了解):使用代码创建超级用户 邮箱是必填的 而用命令创建则可以不填
User.objects.create_superuser(username=username,email='123@qq.com',password=password)
使用 auth 模块实现登录和注册功能
from django.contrib import auth
# 登录验证
def auth_login(request):
next_url = request.GET.get('next')
print(next_url)
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
user_obj = auth.authenticate(request, username=username, password=password)
if user_obj:
auth.login(request, user_obj)
if next_url:
return redirect(next_url)
return HttpResponse('欢迎回家~')
return render(request, 'auth_login.html')
# 注册
from django.contrib.auth.models import User
def auth_register(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
confirm_password = request.POST.get('confirm_password')
if password == confirm_password:
User.objects.create_user(username=username, password=password)
return redirect('/auth_login/')
return HttpResponse('两次密码不一致')
return render(request, 'auth_register.html')
# 登录校验
# 别忘了在登录界面保存用户状态
from django.contrib.auth.decorators import login_required
@login_required(login_url='/auth_login/')
def auth_home(request):
print('hello home')
return HttpResponse('欢迎回家~')
# 退出登录
@login_required(login_url='/auth_login/')
def auth_logout(request):
auth.logout(request)
return redirect('/auth_login/')
# 修改密码
@login_required(login_url='/auth_login/')
def change_pass(request):
if request.method == 'POST':
old_password = request.POST.get('old_password')
new_password = request.POST.get('new_password')
confirm_password = request.POST.get('confirm_password')
is_right = request.user.check_password(old_password)
if is_right:
if new_password == confirm_password:
request.user.set_password(new_password)
request.user.save()
return redirect('/auth_login/')
return render(request, 'change_pass.html', locals())
扩展 auth_user 表
- 没有执行数据库迁移命令,即要确保 auth_user 表还没有创建
- 若已经创建,可以替换数据库
- 在 models.py 中编写类继承 AbstractUser
- 继承的类中不能覆盖 AbstractUser 中的字段名
- 在配置文件中编写
AUTH_USER_MODEL = '应用名.表名'告诉你需要用该表名替代 auth_user - 扩展后的表拥有 auth_user 的所有字段以及我们自己扩展的字段
session 和 cookie
定义
- session 和 cookie 主要作用是保存用户信息或状态信息
- cookie:服务端保存在客户端浏览器上的信息都可以称之为 cookie
- 表现形式:key value 键值对(可以有多个)
- session:(用户)数据保存在服务端
- 表现形式:key value 键值对(可以有多个)
- token:将服务端保存的用户信息进行加密,然后返回给客户端进行保存
cookie 操作
# 如果想操作 cookie views.py 中函数的返回值应该是这种形式
obj = render()
# 操作 cookie
return obj
"""
也就是需要先获取“三板斧”的对象后才能操作 cookie
"""
操作 cookie
# 设置 cookie
obj.set_cookie(key,value)
# 在设置 cookie 的时候还可以设置超时时间,
# 以秒为单位
obj.set_cookie('username', 'jason666',max_age=3,expires=3)
# max_age 其他浏览器 expires IE 浏览器
# 获取 cookie
request.COOKIES.get(key)
登录认证
- 用户只能在登录界面登录(获取 cookie ),然后才能进入其他页面,如果没有 cookie 则跳转到登录界面
- 用户输入在没登陆前,就前往其他页面A,跳转到登录界面登录后,跳转到其他页面A
def cookie(request):
next_url = request.GET.get('next')
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
if username == 'codeFun' and password == '123':
obj = redirect(next_url)
# 设置 cookie
obj.set_cookie('username', 'codeFun')
return obj
return render(request, 'cookie.html')
def cookie_auth(func):
def wrapper(request, *args, **kwargs):
# 获取目标地址
target_url = request.get_full_path()
# 获取 cookie 并判断值是否相同
if request.COOKIES.get('username') == 'codeFun':
return func(request,*args, **kwargs)
# 如果不相同就跳转到登录界面,并且携带用户原本想要进入的界面
return redirect(f'/cookie/?next={target_url}')
return wrapper
@cookie_auth
def read(request):
# cookie_value = request.COOKIES.get('username')
# if cookie_value == 'codeFun':
# return HttpResponse('登录成功~')
return HttpResponse('登录成功~')
@cookie_auth
def watch(request):
return HttpResponse('watch ~~')
session 操作
- 在默认情况下操作 session 需要 Django 中默认的一张 django_session 表
- django 默认session 的过期时间是 14 天
- session 的保存位置:MySQL、文件、redis、memcache 等
- django_session 表中的数据条数:同一台计算机上同一个浏览器只会有一条数据生效。
- 创建 session 的过程:
- django 产生随机字符串,然后将对应的数据存储到 django_session 表中
- 先在内存中产生操作数据的缓存,在响应结果 django 中间件的时候才能真正的操作数据
- 将产生的随机字符串返回给客户端浏览器进行保存
- django 产生随机字符串,然后将对应的数据存储到 django_session 表中
- 获取 session 的过程:
- 自动从浏览器请求中获取 session_id 对应的随机字符串,然后根据随机字符串去 django 表中比对
- 比对成功以字典的形式封装到 request.session 中,比对不上 request.session.get() 返回 None
# 设置 session
request.session['key'] = value
# 获取session
request.session.get('key')
# 设置过期时间
request.session.set_expiry()
"""
括号内可以放四种类型的参数
1.整数 多少秒
2.日期对象 到指定日期就失效
3.0 一旦当前浏览器窗口关闭立刻失效
4.不写 失效时间就取决于django内部全局session默认的失效时间
"""
# 清除session
request.session.delete() # 只删服务端的 客户端的不删
request.session.flush() # 浏览器和服务端都清空(推荐使用)
中间件
-
django 中间件是 django 的门户,请求来的时候需要先经过中间件才能到达真正的 django 后端,相应走的时候也需要经过中间件才能发送出去
-
django 中自带七个中间件
# settings.py MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] -
django 中支持我们五个自定义的方法
- process_request、process_response 必须掌握
- process_view process_template_response process_exception 了解即可
-
process_request
- .请求来的时候需要经过每一个中间件里面的process_request方法,结果的顺序是按照配置文件中注册的中间件从上往下的顺序依次执行,如果中间件里面没有定义该方法,那么直接跳过执行下一个中间件。
- 如果该方法返回了HttpResponse对象,那么请求将不再继续往后执行,而是直接原路返回(校验失败不允许访问…)
- process_request方法就是用来做全局相关的所有限制功能
-
process_response
- 响应走的时候需要经过每一个中间件里面的process_response方法
- 该方法有两个额外的参数request,response
- 该方法必须返回一个HttpResponse对象
- 默认返回的就是形参response
- 你也可以自己返回自己的
- 默认返回的就是形参response
- 顺序是按照配置文件中注册了的中间件从下往上依次经过
- 如果你没有定义的话 直接跳过执行下一个
- 注意:如果在第一个process_request方法就已经返回了HttpResponse对象,那么响应走的就是会直接走同级别的 process_reponse 返回
-
process_view
- 路由匹配成功之后执行视图函数之前,会自动执行中间件里面的该放法
- 顺序是按照配置文件中注册的中间件从上往下的顺序依次执行
-
process_template_response
- 返回的HttpResponse对象有render属性的时候才会触发
- 顺序是按照配置文件中注册了的中间件从下往上依次经过
-
process_exception
- 当视图函数中出现异常的情况下触发
- 顺序是按照配置文件中注册了的中间件从下往上依次经过
自定义中间件
- 在项目名或者应用名下面创建任意名称的文件夹
- 在该文件夹下面创建任意名称的 py 文件
- 在该文件内中书写类(必须继承
MiddlewareMinxin)- 在该类中就可以书写自定以的五个方法了
- 然后将类的路径以字符串的形式注册到配置文件(settings.py)中
# mydd.py
from django.utils.deprecation import MiddlewareMixin
class MyMiddleware(MiddlewareMixin):
# process_request 必须携带 request
def process_request(self, request):
print('hello world')
# process_response 必须携带 request 和 response
def process_response(self,request,response):
pass
# 必须返回 response
return response
# settings.py
MIDDLEWARE = [
...
'app001.myMiddleware.mydd.MyMiddleware'
]
csrf 相关装饰器
前端校验
<form action="" method="post">
{% csrf_token %}
</form>
# ajax 校验
function getCookie(name) {
var cookieValue = null;
if (document.cookie && document.cookie !== '') {
var cookies = document.cookie.split(';');
for (var i = 0; i < cookies.length; i++) {
var cookie = jQuery.trim(cookies[i]);
// Does this cookie string begin with the name we want?
if (cookie.substring(0, name.length + 1) === (name + '=')) {
cookieValue = decodeURIComponent(cookie.substring(name.length + 1));
break;
}
}
}
return cookieValue;
}
var csrftoken = getCookie('csrftoken');
function csrfSafeMethod(method) {
// these HTTP methods do not require CSRF protection
return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method));
}
$.ajaxSetup({
beforeSend: function (xhr, settings) {
if (!csrfSafeMethod(settings.type) && !this.crossDomain) {
xhr.setRequestHeader("X-CSRFToken", csrftoken);
}
}
});
- 网站整体都不校验,就几个视图函数需要做校验
# settings.py
MIDDLEWARE = [
# 'django.middleware.csrf.CsrfViewMiddleware',
]
# views.py
from django.views import View
# 方法一
@method_decorator(csrf_protect,name='post') """"""
class MyCsrfToken(View):
def post(self,request):
return HttpResponse('post')
def post(self,request):
return HttpResponse('post')
# 方法二
class MyCsrfToken(View):
@method_decorator(csrf_protect) """"""
def dispatch(self, request, *args, **kwargs):
return super(MyCsrfToken, self).dispatch(request,*args,**kwargs)
def post(self,request):
return HttpResponse('post')
# 方法三
class MyCsrfToken(View):
@method_decorator(csrf_protect) """"""
def post(self,request):
return HttpResponse('post')
- 网站整体都做校验,就单单几个视图函数不校验
# settings.py
MIDDLEWARE = [
'django.middleware.csrf.CsrfViewMiddleware',
]
# views.py
# 方法一
class MyCsrfToken(View):
@method_decorator(csrf_exempt) """"""
def dispatch(self, request, *args, **kwargs):
return super(MyCsrfToken, self).dispatch(request,*args,**kwargs)
def get(self,request):
return HttpResponse('get')
# 方法二
@method_decorator(csrf_exempt,name='dispatch')
class MyCsrfToken(View):
def get(self,request):
return HttpResponse('get')
django 式编程思想
文件目录
functions
|
|____ ___init__.py
|____ qq.py
|____ wechat.py
|____ email.py
|
settings.py
|
start.py
# __init__.py
import settings
import importlib
def send_all(content):
for path_str in settings.FUNCTIONS_LIST:
module_path, class_name_str = path_str.rsplit('.', maxsplit=1)
# 利用字符串导入模块
module = importlib.import_module(module_path)
# 利用反射获取类名
class_name = getattr(module,class_name_str)
# 利用鸭子类型
obj = class_name()
obj.say(content)
# QQ.py
class QQ:
def __init__(self):
pass
def say(self,content):
print(f'QQ:{content}')
# email.py 和 WeChat.py 差不多改个名而已
# settings.py
FUNCTIONS_LIST = [
'functions.email.Email',
# 'functions.qq.QQ',
'functions.wechat.Wechat',
]
# start.py
from functions import send_all
send_all('hello world')
# 运行结果
Email:hello world
wechat:hello world
BBS 项目
修改密码
- 需求:点击修改密码,然后弹出修改密码的弹窗,在弹窗中修改密码
# 点击“修改密码”弹出下面的框
<a href="#" data-toggle="modal" data-target=".bs-example-modal-lg">修改密码</a>
# 弹出此框
<div class="modal fade bs-example-modal-lg" tabindex="-1" role="dialog"
aria-labelledby="myLargeModalLabel">
<div class="modal-dialog modal-lg" role="document">
<div class="modal-content">
<h1 class="text-center">修改密码</h1>、
<div class="row">
<div class="col-md-8 col-md-offset-2">
<div class="form-group">
<label for="">用户名</label>
<input type="text" disabled value="{{ request.user.username }}"
class="form-control">
</div>
<div class="form-group">
<label for="">原密码</label>
<input type="password" id="id_old_password" class="form-control">
</div>
<div class="form-group">
<label for="">新密码</label>
<input type="password" id="id_new_password" class="form-control">
</div>
<div class="form-group">
<label for="">确认密码</label>
<input type="password" id="id_confirm_password" class="form-control">
</div>
<div class="modal-footer">
<button type="button" class="btn btn-default" data-dismiss="modal">
取消</button>
<button class="btn btn-primary" id="id_edit">修改</button>
# 错误信息在此显示
<span style="color: red" id="password_error"></span>
</div>
<br>
<br>
</div>
</div>
</div>
</div>
</div>
数据的录入
-
首先创建超级管理员,并登录
-
将 models 中的数据库导入 admin.py
from django.contrib import admin from app001 import models # Register your models here. admin.site.register(models.UserInfo) admin.site.register(models.Blog) admin.site.register(models.Category) admin.site.register(models.Tag) admin.site.register(models.Article) admin.site.register(models.Article2Tag) admin.site.register(models.UpAndDown) admin.site.register(models.Comment) -
前端显示表名优化
# models.py class UserInfo(AbstractUser): ... # 添加以下内容就可以显示中文表名了 class Meta: verbose_name_plural = '用户表' -
输入内容,先向文章表内输入,通过文章表将博客站点表和分类表填入相应的内容
- 小知识点:
blank=True:admin 后台管理该字段可以为空,所以经常和null=True一块使用
- 小知识点:
-
将用户表中的用户和其他表中的字段绑定关系,比如 codeFun 和 Blog 站点中的 codeFun 绑定关系
-
标签表、文章2标签 绑定关系
处理用户上传的头像
media 配置
- 该配置可以让用户上传的所有文件都固定存放在某一个指定的文件夹下
- 配置完之后用户上传的文件都会放到 media 下,会自动创建多级目录,例如上传的文件字段如下
avatar = models.FileField(upload_to='avatar/',那么真实的存储路径就是/media/avatar/xxx
- 配置完之后用户上传的文件都会放到 media 下,会自动创建多级目录,例如上传的文件字段如下
# settings.py
MEDIA_ROOT = os.path.join(BASE_DIR,'media') # 名字随意
暴露后端指定文件
# urls.py
from django.views.static import serve
from BBS import settings
# 固定写法
url(r'^media/(?P<path>.*)',serve,{'document_root':settings.MEDIA_ROOT})
用户名跳转功能
- 在 home 页面点击文章下面的用户名跳转用户主页
- 研究博客园发现,点击之后直接跳转以用户名为根目录的链接
https://www.cnblogs.com/fkxxgis/
- 研究博客园发现,点击之后直接跳转以用户名为根目录的链接
# 达到上面的效果只需要在 urls 上使用正则匹配即可
url(r'^(?P<username>\w+)/$', views.site),
# home.html 的 src 应该这样写,直接使用用户名作为目录
<span><a href="/{{ article_obj.blog.userinfo.username }}">...</a>
# 之后在 views.py 中调出相应用户的数据即可
按照日期归档
from django.db.models.functions import TruncMonth
date_list = models.Article.objects.filter(blog=blog).annotate(month=TruncMonth('create_time')).values('month').annotate(count_num=Count('pk')).values_list('month','count_num')
分类链接的跳转
-
个人主页面侧边栏的跳转功能
-
跳转路径如下
https://www.cnblogs.com/codeFun/tag/1/ 标签 https://www.cnblogs.com/codeFun/category/1 分类 https://www.cnblogs.com/codeFun/archive/2020-11/ 日期 -
所以 urls 可以这样写
url(r'^(?P<username>\w+)/(?P<condition>category|tag|archive)/(?P<param>.*)/', views.site),
-
# 后端还是使用的个人主页的代码,只是加了一个判断,用于判断是否是侧边栏跳转
def site(request, username, **kwargs):
user_obj = models.UserInfo.objects.filter(username=username).first()
if not user_obj:
return HttpResponse('查无此人~')
blog = user_obj.blog
article_list = models.Article.objects.filter(blog=blog)
# 如果 kwargs 没有接受数据那就是主页面
if kwargs:
condition = kwargs.get('condition')
param = kwargs.get('param')
if condition == 'category':
article_list = article_list.filter(category__pk=param)
elif condition == 'tag':
article_list = article_list.filter(tags__pk=param)
else:
year, month = param.split('-')
article_list = article_list.filter(create_time__year=year, create_time__month=month)
# 查询用户所有的分类以及分类下的文章数
category_list = models.Category.objects.filter(blog=blog).annotate(count_num=Count('article__pk')).values_list(
'name', 'count_num', 'pk')
tag_list = models.Tag.objects.filter(blog=blog).annotate(count_num=Count('article__pk')).values_list('name',
'count_num',
'pk')
date_list = models.Article.objects.filter(blog=blog).annotate(month=TruncMonth('create_time')).values(
'month').annotate(count_num=Count('pk')).values_list('month', 'count_num')
return render(request, 'site.html', locals())
# 前端 url 的书写
<p><a href="/{{ username }}/archive/{{ date.0|date:'Y-m' }}">{{ date.0|date:'Y年m月' }}({{ date.1 }})</a></p>
<p><a href="/{{ username }}/category/{{ category.2 }}/">{{ category.0 }}({{ category.1 }})</a></p>
<p><a href="/{{ username }}/tag/{{ tag.2 }}/">{{ tag.0 }}({{ tag.1 }})</a></p>
文章详情页
-
文章详情页的地址:
http://127.0.0.1:8000/codeFun/article/2/ -
根据地址则 urls
url(r'^(?P<username>\w+)/article/(?P<article_id>\d+)/',views.article_detail) -
将侧边栏代码使用 inclusion_tag 整合
-
在 app001 目录下创建 templatetags 目录
-
在目录中创创建 left_data.py,并编写如下:
from django import template from django.db.models import Count from django.db.models.functions import TruncMonth from app001 import models register = template.Library() @register.inclusion_tag('left.html') def left(username): user_obj = models.UserInfo.objects.filter(username=username).first() blog = user_obj.blog article_list = models.Article.objects.filter(blog=blog) # 查询用户所有的分类以及分类下的文章数 category_list = models.Category.objects.filter(blog=blog).annotate(count_num=Count('article__pk')).values_list( 'name', 'count_num', 'pk') tag_list = models.Tag.objects.filter(blog=blog).annotate(count_num=Count('article__pk')).values_list('name', 'count_num', 'pk') date_list = models.Article.objects.filter(blog=blog).annotate(month=TruncMonth('create_time')).values( 'month').annotate(count_num=Count('pk')).values_list('month', 'count_num') return locals() -
编写相应的前段代码
# left.html <div class="panel panel-primary"> <div class="panel-heading"> <h3 class="panel-title">文章分类</h3> </div> <div class="panel-body"> {% for category in category_list %} <p><a href="/{{ username }}/category/{{ category.2 }}/">{{ category.0 }}({{ category.1 }})</a></p> {% endfor %} </div> </div> <div class="panel panel-danger"> <div class="panel-heading"> <h3 class="panel-title">标签分类</h3> </div> <div class="panel-body"> {% for tag in tag_list %} <p><a href="/{{ username }}/tag/{{ tag.2 }}/">{{ tag.0 }}({{ tag.1 }})</a></p> {% endfor %} </div> </div> <div class="panel panel-info"> <div class="panel-heading"> <h3 class="panel-title">日期归档</h3> </div> <div class="panel-body"> {% for date in date_list %} <p><a href="/{{ username }}/archive/{{ date.0|date:'Y-m' }}">{{ date.0|date:'Y年m月' }}({{ date.1 }})</a></p> {% endfor %} </div> </div> -
在相应的位置进行导入
<div class="col-md-3"> {% load left_data %} {% left username %} </div>
-
DRF
基础知识储备
web 的开发模式
- 前后端混合开发(即前后端不分离)
- 返回的是 html 内容,需要写模版
- 前后端分离
- 后端开发者只关注于写后端接口,返回 json xml 格式
动静态页面的区别
- 动态页面需要查询数据库,而静态页面不用
api 接口
- 定义:通过网络,规定了前后端交互规则的 url 连接,也就是前后端信息交互的媒介
- 例如百度地图的 api 接口 :https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=%E4%B8%8A%E6%B5%B7&query=%E8%82%AF%E5%BE%B7%E5%9F%BA&output=json
软件 postman 的使用
- 是一款模拟返送 http 请求的工具

restful 规范
- REST 的全称是 Representational State Transfer,中文的意思是表述性状态转移
- RESTful 是一种定义 web api 接口的设计风格,用于前后端分离的应用模式中。
- 理念:后端开发的任务就是提供数据,对外提供的数据资源的访问接口,所以在定义接口时,客户端访问的url路径就是表示要操作这种数据资源
-
数据的安全保障
- 采用 https 协议进行数据传输
-
接口特征表现:一看这个 url 就是 api 接口
- 用 api 关键字标识接口 url:
- 例如:
https://api.baidu.com、https://www.baidu.com/api
- 例如:
- 用 api 关键字标识接口 url:
-
多数据版本共存
- 在 url 链接中标识数据版本
- 例如:
https://api.baidu.com/v1、https://api.baidu.com/v2
- 例如:
- 在 url 链接中标识数据版本
-
数据即资源,均使用名词(可复数)
- 接口一般都是完成前后端数据的交互,交互的数据我们称为资源
- 这个资源里面有着数据的所有操作
- 例如:
api.baidu.com/users
- 特殊的接口中允许出现动词,因为这些接口没有明确的资源,或是动词就是接口的核心含义
- 例如:
baidu.com/place/search、baidu.com/login
- 例如:
- 接口一般都是完成前后端数据的交互,交互的数据我们称为资源
-
资源操作由请求方式决定
# 查 https://api.baidu.com/books # get请求:获取所有书 https://api.baidu.com/books/1 # get请求:获取主键为1的书 # 增 https://api.baidu.com/books # post请求:新增一本书书 # 改 https://api.baidu.com/books/1 # put请求:整体修改主键为1的书 https://api.baidu.com/books/1 # patch请求:局部修改主键为1的书 # 删 https://api.baidu.com/books/1 # delete请求:删除主键为1的书 -
过滤,通过 url 上传参的形式传递搜索条件
/v1/zoos?limit=10 # 指定返回记录的数量 /v1/zoos?offset=10 # 指定返回记录的开始位置 /v1/zoos?page=2&per_page=100 # 指定第几页,以及每页的记录数 /v1/zoos?sortby=name&order=asc # 指定返回结果按照哪个属性排序,以及排序顺序 /v1/zoos?animal_type_id=1 # 指定筛选条件 -
响应状态码
- 2xx 正常状态码
- 3xx 重定向响应
- 4xx 客户端异常
- 5xx 服务端异常
-
错误处理,应返回错误信息 error 当做 key
{"error": "msg"} -
返回结果,针对不同的操作,服务器向用户返回的结果应该符合一下规范
GET /collection:返回资源对象的列表(数组)GET /collection/resource:返回单个对象POST /collection:返回新生成对象PUT/collection/resource:返回完整的资源对象PATCH /collection/resource:返回完整的资源对象DELETE /collection/resource:返回一个空文档
-
需要 url 请求的资源需要访问资源的请求连接
- Hypermedia API,RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么
DRF 的简单使用
Django 和 djangorestframework 的使用版本
- django 2.0.6
- djangorestframework 3.10.0
使用流程
-
在 settings.py 中的app中注册
INSTALLED_APPS = [ 'rest_framework' ] -
连接数据库
-
在 models.py 中写表模型并做数据迁移
class Book(models.Model): name=models.CharField(max_length=32) price=models.DecimalField(max_digits=5,decimal_places=2) author=models.CharField(max_length=32) -
新建一个序列化类,需要在 app001 中新建 ser.py
from rest_framework.serializers import ModelSerializer from app01.models import Book class BookModelSerializer(ModelSerializer): class Meta: model = Book fields = "__all__" -
在视图函数中写视图类
from rest_framework.viewsets import ModelViewSet from .models import Book from .ser import BookModelSerializer class BooksViewSet(ModelViewSet): queryset = Book.objects.all() serializer_class = BookModelSerializer -
编写路由关系
from app01 import views from rest_framework.routers import DefaultRouter router = DefaultRouter() # 可以处理视图的路由器 router.register('book', views.BooksViewSet) # 向路由器中注册视图集 # 将路由器中的所以路由信息追到到django的路由列表中 urlpatterns = [ path('admin/', admin.site.urls), ] # router.urls 列表 # 两个列表相加 urlpatterns += router.urls -
在 postman 中进行测试即可
序列化和反序列化
基本步骤(序列化组件查看单个数据)
- 写一个类继承
Serializer- 在类中写要序列化的字段,没必要将
models中的全写
- 在类中写要序列化的字段,没必要将
- 在视图函数中生成序列化对象
- 生成的序列化对象要传入被序列化的对象
- 序列化的数据使用
序列化对象.data得到,类型是一个字典 - 将字典返回,返回使用
Response或者JsonResponse
from rest_framework import serializers
class StudentSerializer(serializers.Serializer):
id = serializers.CharField()
name = serializers.CharField()
age = serializers.CharField()
clazz = serializers.CharField()
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Student
class StudentView(APIView):
def get(self,request,pk):
student_obj = Student.objects.filter(pk=pk).filter()
student_ser = StudentSerializer(student_obj,many=True)
return Response(student_ser.data)
class Student(models.Model):
id = models.AutoField(primary_key=True,auto_created=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
clazz = models.CharField(max_length=32)
序列化类的字段的类型和属性
| 字段类型 | 字段构造方式 |
|---|---|
| BooleanField | BooleanFieldO |
| CharField | Charfield(max_length= None, min_length=None, allow_blank=false, trim_whitespace=True) |
| EmailField | Emailfield(max_length=None, min_ length= None, allow_blank=False) |
| RegexField | Regexfield(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SIugField(max_length=50, min_length=None, allow_blank=False) 正则字段,验i证正则模式[a-zA-20-9-1+ |
| URLField | URLField(max length=200, min_length=None, allow_blank=False) |
| IPAddressField | IPAddressField(protocol=‘both’, unpack_ipv4=False, **options) |
| IntegerField | integerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalFiel d | DecimalField(max _digits, decimal_places, coerce_to_string=None, max_value=None, min _value=None) max_digits. 最多位 decimal_palces: 小数点位置 |
| DateTimeField | DateTimefield(format=api_settings,DATETIME_ FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings,DATE_FORMAT, input_ formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
选项参数
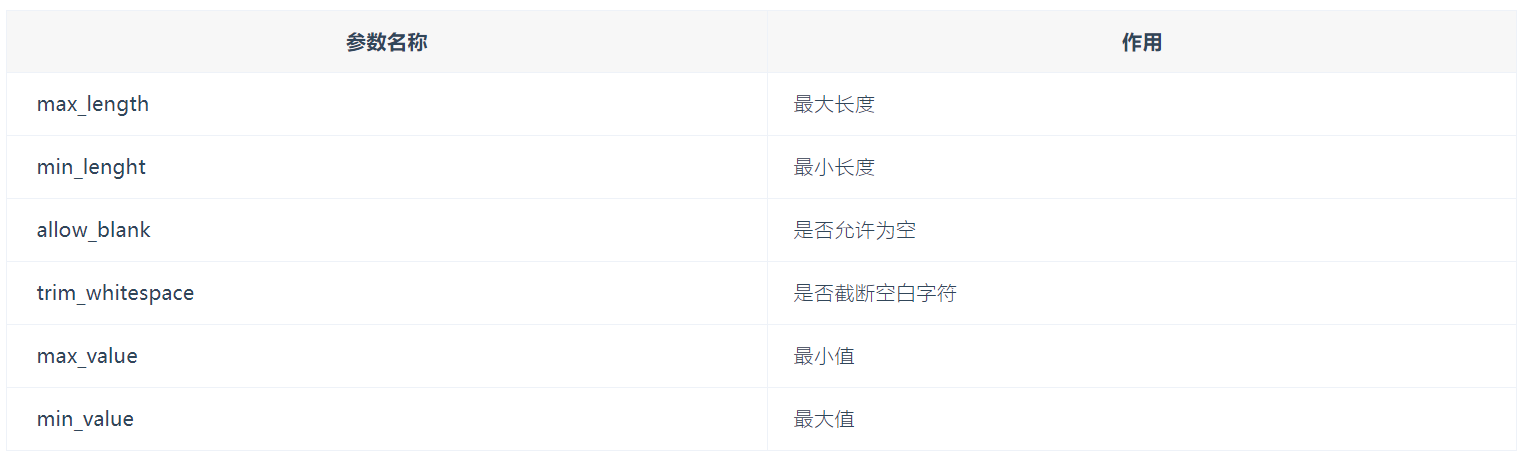
通用参数
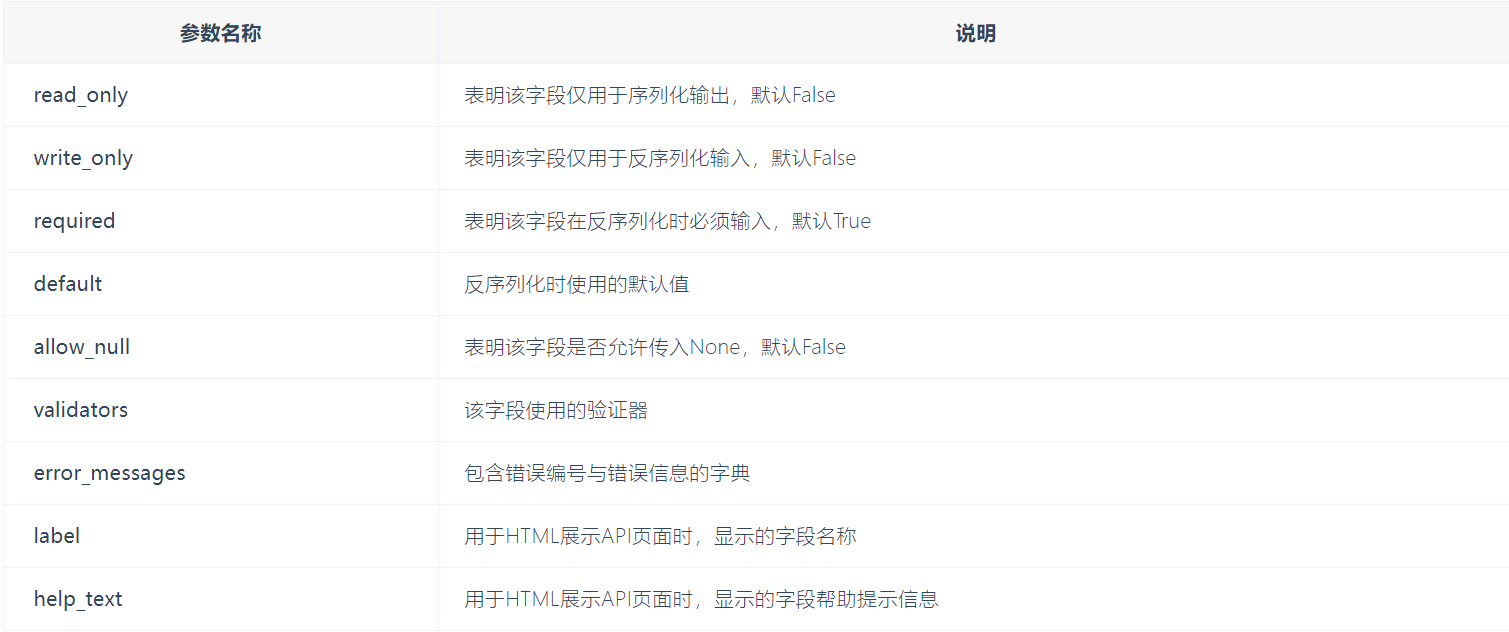
序列化组件修改数据
-
在原有的序列化类中添加
update()方法,在方法中编写需要反序列化的字段,然后保存并返回反序列化后的数据class StudentSerializer(serializers.Serializer): ... def update(self, instance, validated_data): instance.id = validated_data.get('id') instance.name = validated_data.get('name') instance.age = validated_data.get('age') instance.clazzz = validated_data.get('clazz') instance.save() return instance -
在视图文件中的视图类中创建
put函数,在函数内得到序列化对象(需要将要修改的对象和数据传入),然后判断数据校验是否通过,若通过,保存序列化对象,不通过,将错误返回class StudentView(APIView): def put(self,request,pk): response_dic = {'status':100, 'msg':'成功','data':''} student_obj = Student.objects.filter(pk=pk).first() # 实例化序列化对象 student_ser = StudentSerializer(instance=student_obj,data=request.data) if student_ser.is_valid(): student_ser.save() response_dic['data'] = student_ser.data else: response_dic['status'] = 101 response_dic['msg'] = student_ser.error_messages response_dic['data'] = student_ser.errors return Response(response_dic)
限制数据传入
- 可以通过字段参数进行限制,如
CharField(max_length=6,min_length=2) - 如果上述限制不够还可以添加全局钩子和局部钩子,具体如何编写如下
# 局部钩子
# 如果岁数小于 18 岁校验不通过
def validate_age(self,data):
if int(data) < 18:
raise ValidationError('年龄太小')
else:
return data
# 全局钩子
# 班级名不能和姓名一样
def validate(self, validate_data):
name = validate_data.get('name')
clazz = validate_data.get('clazz')
if name == clazz:
raise ValidationError('班级名和姓名一致了!')
else:
return validate_data
序列化组件查看所有数据
-
新增路由
path('students/', views.StudentsView.as_view()), -
创建视图函数
class StudentsView(APIView):
def get(self,request):
response_dic = {'status': 100, 'msg': '成功'}
student_queryset = Student.objects.all()
# 注意:many = True
student_ser = StudentSerializer(book_queryset,many=True)
response_dic['data'] =student_ser.data
return Response(response_dic)
序列化组件新增数据
# 在查看所有数据的路由基础进行添加代码即可
class StudentsView(APIView):
def post(self,reqeust):
response_dic = {'status':100, 'msg': '成功'}
# 新增数据时,只需传入 data 即可,无需传入 instance
stuendt_ser = StudentSerializer(data=reqeust.data)
if stuendt_ser.is_valid():
stuendt_ser.save()
response_dic['data'] = stuendt_ser.data
else:
response_dic['status'] = 102
response_dic['msg'] = '保存失败'
response_dic['data'] = stuendt_ser.errors
return Response(response_dic)
序列化组件删除数据
# 根据 pk 值直接删除就好,不用借用序列化组件
class StudentView(APIView):
def delete(self,request,pk):
del_obj = Student.objects.filter(pk=pk).delete()
return Response({'status': 100, 'msg': '删除成功','data':del_obj})
模型类序列化器
- 使用模型序列化器不用重写 create 和 update 方法
# CBV 需要继承 ModelSerializer
class BookModelSerializer(serializers.ModelSerializer):
# 类名必须是 Meta
class Meta:
model=Book # 对应上models.py中的模型
# 序列化所有字段
fields='__all__'
# 序列化指定字段
# fields=('name','price','id','author')
# 排除指定字段
# exclude=('name',) #跟fields不能都写,写谁,就表示排除谁
# 添加字段属性
extra_kwargs = { # 类似于这种形式name=serializers.CharField(max_length=16,min_length=4)
'price': {'write_only': True},
}
source 字段属性
-
可以改字段名称
title_new = serializers.CharField(source='title')
-
可以进行跨表查询数据
publish=serializers.CharField(source='publish.email')
-
可以执行表模型中的方法
pub_date=serializers.CharField(source='test')
-
当表关系是一对多时,这是就要输出一个列表,可以使用
SerializerMethodField方法进行输出# 它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西 authors=serializers.SerializerMethodField() #它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西 def get_authors(self,instance): # book对象 authors=instance.authors.all() # 取出所有作者 ll=[] for author in authors: ll.append({'name':author.name,'age':author.age}) return ll
请求和响应
请求
from rest_framework.request import Request
# 使用 Request 必须传入 request
rest_request = Request(request=request)
rest_request.data # 前端以三种编码方式传入的数据,都可以取出来
rest_request.query_params # 等同于 django 标准的 request.GET
响应
from rest_framework.response import Response
return Response(data=None, status=None,
template_name=None, headers=None,
exception=False, content_type=None)
# data:你要返回的数据,字典
#status:返回的状态码,默认是200,
"""
from rest_framework import status在这个路径下,它把所有使用到的状态码都定义成了常量
"""
# template_name 渲染的模板名字(自定制模板),不需要了解
# headers:响应头,可以往响应头放东西,就是一个字典
# content_type:响应的编码格式,application/json和text/html;
视图
- 两个视图基类:APIView GenericAPIView
基于 APIView 写接口
- 当写的接口类过多时,会发现有很多重复的代码
# # views.py
from rest_framework.generics import GenericAPIView
from app01.models import Book
from app01.ser import BookSerializer
# 基于APIView写的
class BookView(APIView):
def get(self,request):
book_list=Book.objects.all()
book_ser=BookSerializer(book_list,many=True)
return Response(book_ser.data)
def post(self,request):
book_ser = BookSerializer(data=request.data)
if book_ser.is_valid():
book_ser.save()
return Response(book_ser.data)
else:
return Response({'status':101,'msg':'校验失败'})
class BookDetailView(APIView):
def get(self, request,pk):
book = Book.objects.all().filter(pk=pk).first()
book_ser = BookSerializer(book)
return Response(book_ser.data)
def put(self, request,pk):
book = Book.objects.all().filter(pk=pk).first()
book_ser = BookSerializer(instance=book,data=request.data)
if book_ser.is_valid():
book_ser.save()
return Response(book_ser.data)
else:
return Response({'status': 101, 'msg': '校验失败'})
def delete(self,request,pk):
ret=Book.objects.filter(pk=pk).delete()
return Response({'status': 100, 'msg': '删除成功'})
# models.py
class Book(models.Model):
name=models.CharField(max_length=32)
price=models.DecimalField(max_digits=5,decimal_places=2)
publish=models.CharField(max_length=32)
# ser.py
class BookSerializer(serializers.ModelSerializer):
class Meta:
model=Book
fields='__all__'
# urls.py
path('books/', views.BookView.as_view()),
re_path('books/(?P<pk>\d+)', views.BookDetailView.as_view()),
基于 GenericAPIView 写接口
# views.py
class Book2View(GenericAPIView):
#queryset要传queryset对象,查询了所有的图书
# serializer_class使用哪个序列化类来序列化这堆数据
queryset=Book.objects
# queryset=Book.objects.all()
serializer_class = BookSerializer
def get(self,request):
book_list=self.get_queryset()
book_ser=self.get_serializer(book_list,many=True)
return Response(book_ser.data)
def post(self,request):
book_ser = self.get_serializer(data=request.data)
if book_ser.is_valid():
book_ser.save()
return Response(book_ser.data)
else:
return Response({'status':101,'msg':'校验失败'})
class Book2DetailView(GenericAPIView):
queryset = Book.objects
serializer_class = BookSerializer
def get(self, request,pk):
book = self.get_object()
book_ser = self.get_serializer(book)
return Response(book_ser.data)
def put(self, request,pk):
book = self.get_object()
book_ser = self.get_serializer(instance=book,data=request.data)
if book_ser.is_valid():
book_ser.save()
return Response(book_ser.data)
else:
return Response({'status': 101, 'msg': '校验失败'})
def delete(self,request,pk):
ret=self.get_object().delete()
return Response({'status': 100, 'msg': '删除成功'})
path('books2/', views.Book2View.as_view()),
re_path('books2/(?P<pk>\d+)', views.Book2DetailView.as_view()),
基于五个拓展类
- ListModelMixin:
- 列表视图扩展类,提供
list(request, *args, **kwargs)方法快速实现列表视图,返回200状态码。 - 该Mixin的list方法会对数据进行过滤和分页。
- 列表视图扩展类,提供
- CreateModelMixin:
- 创建视图扩展类,提供
create(request, *args, **kwargs)方法快速实现创建资源的视图。 - 成功返回201状态码。如果序列化器对前端发送的数据验证失败,返回400错误。
- 创建视图扩展类,提供
- RetrieveModelMixin
- 详情视图扩展类,提供
retrieve(request, *args, **kwargs)方法,可以快速实现返回一个存在的数据对象。 - 如果存在,返回200, 否则返回404。
- 详情视图扩展类,提供
- UpdateModelMixin
- 更新视图扩展类,提供
update(request, *args, **kwargs)方法,可以快速实现更新一个存在的数据对象。 - 同时也提供
partial_update(request, *args, **kwargs)方法,可以实现局部更新。 - 成功返回200,序列化器校验数据失败时,返回400错误。
- 更新视图扩展类,提供
- DestroyModelMixin
- 删除视图扩展类,提供
destroy(request, *args, **kwargs)方法,可以快速实现删除一个存在的数据对象。成功返回204,不存在返回404。
- 删除视图扩展类,提供
from rest_framework.mixins import ListModelMixin,CreateModelMixin,UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin
# views.py
class Book3View(GenericAPIView,ListModelMixin,CreateModelMixin):
queryset=Book.objects
serializer_class = BookSerializer
def get(self,request):
return self.list(request)
def post(self,request):
return self.create(request)
class Book3DetailView(GenericAPIView,RetrieveModelMixin,DestroyModelMixin,UpdateModelMixin):
queryset = Book.objects
serializer_class = BookSerializer
def get(self, request,pk):
return self.retrieve(request,pk)
def put(self, request,pk):
return self.update(request,pk)
def delete(self,request,pk):
return self.destroy(request,pk)
path('books3/', views.Book3View.as_view()),
re_path('books3/(?P<pk>\d+)', views.Book3DetailView.as_view()),
常用子类视图
- CreateAPIView
- 提供 post 方法
- 继承自: GenericAPIView、CreateModelMixin
- ListAPIView
- 提供 get 方法
- 继承自:GenericAPIView、ListModelMixin
- RetireveAPIView
- 提供 get 方法
- 继承自: GenericAPIView、RetrieveModelMixin
- DestoryAPIView
- 提供 delete 方法
- 继承自:GenericAPIView、DestoryModelMixin
- UpdateAPIView
- 提供 put 和 patch 方法
- 继承自:GenericAPIView、UpdateModelMixin
- RetrieveUpdateAPIView
- 提供 get、put、patch方法
- 继承自: GenericAPIView、RetrieveModelMixin、UpdateModelMixin
- RetrieveUpdateDestoryAPIView
- 提供 get、put、patch、delete方法
- 继承自:GenericAPIView、RetrieveModelMixin、UpdateModelMixin、DestoryModelMixin
使用ModelViewSet编写5个接口
from rest_framework.viewsets import ModelViewSet
class Book5View(ModelViewSet): #5个接口都有,但是路由有点问题
queryset = Book.objects
serializer_class = BookSerializer
path('books5/',
views.Book5View.as_view(
actions={
'get':'list',
'post':'create'})), #当路径匹配,又是get请求,会执行Book5View的list方法
re_path('books5/(?P<pk>\d+)',
views.Book5View.as_view(
actions={'get':'retrieve',
'put':'update',
'delete':'destroy'})),
继承ViewSetMixin的视图类
- 可以拓展方法
from rest_framework.viewsets import ViewSetMixin
class Book6View(ViewSetMixin,APIView): #一定要放在APIVIew前
def get_all_book(self,request):
print("xxxx")
book_list = Book.objects.all()
book_ser = BookSerializer(book_list, many=True)
return Response(book_ser.data)
path('books6/', views.Book6View.as_view(actions={'get': 'get_all_book'})),
路由层
最简模式
path('books4/', views.Book4View.as_view()),
re_path('books4/(?P<pk>\d+)', views.Book4DetailView.as_view()),
如果视图继承了ViewSetMixin
path('books5/',
views.Book5View.as_view(actions={
'get':'list',
'post':'create'})), #当路径匹配,又是get请求,会执行Book5View的list方法
re_path('books5/(?P<pk>\d+)',
views.Book5View.as_view(
actions={
'get':'retrieve',
'put':'update','delete':'destroy'})),
继承自视图类,ModelViewSet的路由写法(自动生成路由)
# 第一步:导入routers模块
from rest_framework import routers
# 第二步:有两个类,实例化得到对象
# routers.DefaultRouter 生成的路由更多
router = routers.SimpleRouter()
# router=routers.DefaultRouter()
# 第三步:注册
router.register('前缀','继承自ModelViewSet视图类','别名')
router.register('books',views.BookViewSet) # 不要加斜杠了
# 第四步
# router.urls # 自动生成的路由,加入到原路由中
urlpatterns+=router.urls
action 的使用
- 为了给继承自ModelViewSet的视图类中定义的函数也添加路由
class BookViewSet(ModelViewSet):
queryset =Book.objects.all()
serializer_class = BookSerializer
# methods第一个参数,传一个列表,列表中放请求方式,
# ^books/get_1/$ [name='book-get-1'] 当向这个地址发送get请求,会执行下面的函数
# detail:布尔类型 如果是True
#^books/(?P<pk>[^/.]+)/get_1/$ [name='book-get-1']
@action(methods=['GET','POST'],detail=True)
def get_2(self,request,pk):
print(pk)
book=self.get_queryset()[:2] # 从0开始截取一条
ser=self.get_serializer(book,many=True)
return Response(ser.data)
"""
装饰器,放在被装饰的函数上方,method:请求方式,detail:是否带pk
"""
自定义认证、权限、过滤、频率、异常处理
自定义认证
编写自定义认证类
from app001 import models
class MyAuth(BaseAuthentication):
def authenticate(self, request):
token = request.GET.get('token')
if token:
user_token = models.UserToken.objects.filter(token=token).first()
if user_token:
return user_token,token
else:
raise AuthenticationFailed('认证失败')
else:
raise AuthenticationFailed('您没有携带 token')
编写登录视图
class Login(APIView):
def post(self,request):
username = request.data.get('username')
password = request.data.get('password')
user_obj = models.UserInfo.objects.filter(username=username,password=password).first()
if user_obj:
token = uuid.uuid4()
models.UserToken.objects.update_or_create(defaults={'token':token},username=user_obj)
return Response({'status': 100, 'msg': '登陆成功', 'token': token})
else:
return Response({'status': 101, 'msg': '用户名或密码错误'})
在需要认证的视图上添加自定义认证类
class StudentsView(APIView):
authentication_classes = [MyAuth]
全局认证的配置
# 可以有多个认证,从左到右依次执行
# 全局使用,在setting.py中配置
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.app_auth.MyAuthentication",]
}
# 局部使用,在视图类上写
authentication_classes=[MyAuthentication]
# 局部禁用
authentication_classes=[]
自定义权限
- 写一个类,继承BasePermission,
- 重写has_permission
- 如果权限通过,就返回True,不通过就返回False
from rest_framework.permissions import BasePermission
class UserPermission(BasePermission):
def has_permission(self, request, view):
# 不是超级用户,不能访问
# 由于认证已经过了,request内就有user对象了,当前登录用户
user=request.user # 当前登录用户
# 如果该字段用了choice,通过get_字段名_display()就能取出choice后面的中文
print(user.get_user_type_display())
if user.user_type==1:
return True
else:
return False
全局使用和局部禁用
# 全局使用
REST_FRAMEWORK={
# 权限的使用伴随着认证的使用
"DEFAULT_AUTHENTICATION_CLASSES":["app01.app_auth.MyAuthentication",],
# 禁用的字段
'DEFAULT_PERMISSION_CLASSES': [
'app01.app_auth.UserPermission',
],
}
# 局部禁用
class TestView(APIView):
permission_classes = []
局部使用
class TestView(APIView):
permission_classes = [app_auth.UserPermission]
内置频率的使用
- 限制登录用户或未登录用户的访问频次
限制未登录用户的登录频次
# 全局使用、局部禁用
# 全局使用 限制未登录用户1分钟访问5次
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_CLASSES': (
'rest_framework.throttling.AnonRateThrottle',
),
'DEFAULT_THROTTLE_RATES': {
'anon': '3/m', # 限制在每分钟三次
}
}
# views.py
class TestView4(APIView):
uthentication_classes=[]
permission_classes = []
throttle_classes = []
# 局部使用
# 局部使用下,全局使用的频次得保留
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_RATES': {
'anon': '3/m', # 限制在每分钟三次
}
}
class TestView5(APIView):
authentication_classes=[]
permission_classes = []
throttle_classes = [AnonRateThrottle]
def get(self,request,*args,**kwargs):
return Response('我是未登录用户,TestView5')
限制登录用户的访问频次
# 全局使用 settings.py
'DEFAULT_THROTTLE_CLASSES': (
# 未登录用户和登录用户可以同时限制
'rest_framework.throttling.AnonRateThrottle',
'rest_framework.throttling.UserRateThrottle' # 限制登录用户
),
'DEFAULT_THROTTLE_RATES': {
'user': '10/m', # 限制登录用户每分钟访问十次
'anon': '5/m',
}
限制手机号验证码次数
# throttlings.py
from rest_framework.throttling import SimpleRateThrottle
class SMSThrotting(SimpleRateThrottle):
scope = 'sms'
def get_cache_key(self, request, view):
telephone = request.query_params.get('telephone')
#'throttle_%(scope)s_%(ident)s'%{}
return self.cache_format%{'scope':self.scope,'ident':telephone}
# 配置在视图类上
from .throttlings import SMSThrotting
class SendSmSView(ViewSet):
throttle_classes = [SMSThrotting,]
# 早setting中配置
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_RATES':{
'sms':'1/m' # key要跟类中的scop对应
}
}
内置过滤
- 安装
pip install django-filter - 注册在 app 中注册
# 全局配置
REST_FRAMEWORK = {
'DEFAULT_FILTER_BACKENDS':
('django_filters.rest_framework.DjangoFilterBackend',)
}
# views.py
class BookView(ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_fields = ('name',) #配置可以按照哪个字段来过滤
过滤总结
# 当视图函数继承了 (GenericViewSet, ListModelMixin) 时可可以使用入下:
'''
排序:
按id正序倒叙排序,按price正序倒叙排列
使用:http://127.0.0.1:8000/course/free/?ordering=-id
配置类:
filter_backends=[OrderingFilter]
配置字段:
ordering_fields=['id','price']
内置过滤:
使用:http://127.0.0.1:8000/course/free/?search=39
按照price过滤(表自有的字段直接过滤)
配置类:
filter_backends=[SearchFilter]
配置字段:
search_fields=['price']
扩展:django-filter
安装:pip install django-filter 还需要在 app 中进行注册
支持自由字段的过滤还支持外键字段的过滤
http://127.0.0.1:8000/course/free/?course_category=1 # 过滤分类为1 (python的所有课程)
配置类:
filter_backends=[DjangoFilterBackend]
配置字段:
filter_fields=['course_category']
'''
内置排序
# 局部使用和全局使用
# 局部使用
from rest_framework.generics import ListAPIView
from rest_framework.filters import OrderingFilter
from app01.models import Book
from app01.ser import BookSerializer
class Book2View(ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
filter_backends = [OrderingFilter] # 添加排序模块
ordering_fields = ('id', 'price') # 排序字段
# 使用:
http://127.0.0.1:8000/books2/?ordering=-price # 按照 price 降序
http://127.0.0.1:8000/books2/?ordering=price # 按照 price 升序
http://127.0.0.1:8000/books2/?ordering=-id
配置日志
# settings.py
#日志的配置
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'verbose': {
'format': '%(levelname)s %(asctime)s %(module)s %(lineno)d %(message)s'
},
'simple': {
'format': '%(levelname)s %(module)s %(lineno)d %(message)s'
},
},
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
'handlers': {
'console': {
# 实际开发建议使用WARNING
'level': 'DEBUG',
'filters': ['require_debug_true'],
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
'file': {
# 实际开发建议使用ERROR
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler',
"""
日志位置,日志文件名,日志保存目录必须手动创建,注:这里的文件路径要注意BASE_DIR代表的是小luffyapi
"""
'filename': os.path.join(os.path.dirname(BASE_DIR), "logs", "luffy.log"),
# 日志文件的最大值,这里我们设置300M
'maxBytes': 300 * 1024 * 1024,
# 日志文件的数量,设置最大日志数量为10
'backupCount': 100,
# 日志格式:详细格式
'formatter': 'verbose',
# 文件内容编码
'encoding': 'utf-8'
},
},
# 日志对象
'loggers': {
'django': {
'handlers': ['console', 'file'],
'propagate': True, # 是否让日志信息继续冒泡给其他的日志处理系统
},
}
}
# utils.logger.py
import logging
# log=logging.getLogger('名字') # 跟配置文件中loggers日志对象下的名字对应
log = logging.getLogger('django')
# 如何使用:放在自定义的异常返回中
log.error(f'error class is {context["view"].__class__.__name__}, Error massage is [{str(exc)}]')
自定义异常返回
#统一接口返回
# 自定义异常方法,替换掉全局
# 写一个方法
# 自定义异常处理的方法
from rest_framework.views import exception_handler
from rest_framework.response import Response
from rest_framework import status
def my_exception_handler(exc, context):
log.error(f'error class is {context["view"].__class__.__name__}, Error massage is [{str(exc)}]')
response=exception_handler(exc, context)
# 两种情况,一个是None,drf没有处理
#response对象,django处理了,但是处理的不符合咱们的要求
# print(type(exc))
if not response:
if isinstance(exc, ZeroDivisionError):
return Response(data={'status': 777, 'msg': "除以0的错误" + str(exc)}, status=status.HTTP_400_BAD_REQUEST)
return Response(data={'status':999,'msg':str(exc)},status=status.HTTP_400_BAD_REQUEST)
else:
# return response
return Response(data={'status':888,'msg':response.data.get('detail')},status=status.HTTP_400_BAD_REQUEST)
# 全局配置setting.py
'EXCEPTION_HANDLER': 'app01.app_auth.my_exception_handler',
封装 Response 对象
# 以后都用自己封装的
class APIResponse(Response):
def __init__(self,code=100,msg='成功',data=None,status=None,headers=None,**kwargs):
dic = {'code': code, 'msg': msg}
if data:
dic = {'code': code, 'msg': msg,'data':data}
dic.update(kwargs)
super().__init__(data=dic, status=status,headers=headers)
# 使用
return APIResponse(data={"name":'lqz'},token='dsafsdfa',aa='dsafdsafasfdee')
return APIResponse(data={"name":'lqz'})
return APIResponse(code='101',msg='错误',data={"name":'lqz'},token='dsafsdfa',aa='dsafdsafasfdee',header={})
图书案例(分页器)
- 关联表的字段如何返回给前端
建表
-
on_delete 和 db_db_constraint
- on_delete:
- CASCADE:级联删除
- PROTECT:保护模式,删除的时候,会抛出ProtectedError错误
- SET_NULL: 置空模式,删除的时候,外键字段被设置为空,前提就是blank=True,null=True,定义该字段的时候,允许为空。
- SET_DEFAULT::置默认值,删除的时候,外键字段设置为默认值,所以定义外键的时候注意加上一个默认值。
- SET(): 自定义一个值,该值当然只能是对应的实体了
- db_constraint
- 如果使用两个表之间存在关联,首先db_constraint=False 把关联切断,但保留连表查询的功能,其次要设置null=True, blank=True,on_delete=DO_NOTHING这样删了不会影响其他关联的表
- on_delete:
-
表断关联
-
表之间没有外键关联,但是有外键逻辑关联(有充当外键的字段)
-
断关联后不会影响数据库查询效率,但是会极大提高数据库增删改效率(不影响增删改查操作)
-
断关联一定要通过逻辑保证表之间数据的安全,不要出现脏数据(使用代码控制)
-
级联关系
- 作者没了,详情也没:
on_delete=models.CASCADE - 出版社没了,书还是那个出版社出版:
on_delete=models.DO_NOTHING - 部门没了,员工没有部门(空不能):
null=True, on_delete=models.SET_NULL - 部门没了,员工进入默认部门(默认值):
default=0, on_delete=models.SET_DEFAULT
- 作者没了,详情也没:
-
虚拟表的创建
class Meta: abstract = True
from django.db import models
# Create your models here.
class BaseModel(models.Model):
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
last_time = models.DateTimeField(auto_now=True, verbose_name='修改时间')
is_delete = models.BooleanField(default=True, verbose_name='是否删除')
class Meta:
abstract = True
class Book(BaseModel):
name = models.CharField(max_length=32, verbose_name='书名')
price = models.DecimalField(decimal_places=2, max_digits=4, verbose_name='价格')
publish = models.ForeignKey(to='Publish', on_delete=models.DO_NOTHING, db_constraint=False, verbose_name='出版社')
# 不能写 on_delete
authors = models.ManyToManyField(to='Author', db_constraint=False, verbose_name='作者')
def __str__(self):
return self.name
@property
def publish_name(self):
return self.publish.name
def author_list(self):
author_list = []
authors = self.authors.all()
for author in authors:
author_list.append({'name':author.name,'sex':author.get_sex_display()})
return author_list
class Publish(BaseModel):
name = models.CharField(max_length=32, verbose_name='出版社')
address = models.CharField(max_length=32, verbose_name='位置')
def __str__(self):
return self.name
class Author(BaseModel):
name = models.CharField(max_length=32, verbose_name='作者姓名')
sex = models.IntegerField(choices=((1, '男'), (2, '女')), verbose_name='性别')
author_detail = models.OneToOneField(to='AuthorDetail', verbose_name='作者详情', on_delete=models.CASCADE,
db_constraint=False)
def __str__(self):
return self.name
class AuthorDetail(BaseModel):
phone = models.CharField(max_length=11)
address = models.CharField(max_length=32, verbose_name='地址')
获取所有和获取单个
# ser.py
from rest_framework import serializers
from .models import Book
class BooKModelSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = ('name', 'price', 'authors', 'publish', 'publish_name', 'author_list')
# 若想要获取 publish_name 和 author_list,就必须在 models.Book 中写如下方法:
# @property
# def publish_name(self):
# return self.publish.name
#
# def author_list(self):
# author_list = []
# authors = self.authors.all()
# for author in authors:
# author_list.append({'name': author.name, 'sex': author.get_sex_display()})
# return author_list
extra_kwargs = {
'publish': {'write_only': True},
'publish_name': {'read_only': True},
'authors': {'write_only': True},
'author_list': {'read_only': True},
}
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework.viewsets import ModelViewSet
from app001 import models
from .ser import BooKModelSerializer
class BooksView(APIView):
# 将获取单个和获取所有集成在一个 get 方法
@staticmethod
def get(request, *args, **kwargs):
if kwargs:
pk = kwargs.get('pk')
book_obj = models.Book.objects.filter(pk=pk).first()
book_ser = BooKModelSerializer(instance=book_obj)
else:
book_queryset = models.Book.objects.filter(is_delete=True).all()
book_ser = BooKModelSerializer(instance=book_queryset, many=True)
return Response(book_ser.data)
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', views.BooksView.as_view()),
re_path('books/(?P<pk>\d+)/', views.BooksView.as_view()),
]
批量增加和单个增加
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework.viewsets import ModelViewSet
from app001 import models
from .ser import BooKModelSerializer
class BooksView(APIView):
@staticmethod
def post(request, *args, **kwargs):
if isinstance(request.data, dict):
book_ser = BooKModelSerializer(data=request.data)
book_ser.is_valid(raise_exception=True)
book_ser.save()
return Response(data=book_ser.data)
elif isinstance(request.data, list):
book_ser = BooKModelSerializer(data=request.data, many=True)
book_ser.is_valid(raise_exception=True)
book_ser.save()
return Response(data=book_ser.data)
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', views.BooksView.as_view()),
re_path('books/(?P<pk>\d+)/', views.BooksView.as_view()),
]
批量修改和单个修改、局部修改
# 对于局部修改 patch ,添加 partial=True 即可,其他的不用看
book_ser = BookModelSerializer(instance=book,data=request.data,partial=True)
-
批量修改的数据格式:
[{ "id": 8, "name": "实施经理2", "price": "21.34", "authors": [ 2,1 ], "publish": 1 }, { "id": 9, "name": "监考老师2", "price": "21.34", "authors": [ 2 ], "publish": 1 }] -
获取 id 号来获取图书对象,然后将 id 号去掉就是修改对象。
# views.py
from rest_framework.response import Response
from rest_framework.views import APIView
from rest_framework.viewsets import ModelViewSet
from app001 import models
from .ser import BooKModelSerializer
# Create your views here.
class BooksView(APIView):
def put(self, request, *args, **kwargs):
# 表示获取不到就是 kwargs.get('pk', False) = False
if kwargs.get('pk', False):
pk = kwargs.get('pk')
book_obj = models.Book.objects.filter(pk=pk).first()
book_ser = BooKModelSerializer(instance=book_obj, data=request.data, partial=True)
book_ser.is_valid(raise_exception=True)
book_ser.save()
return Response(data=book_ser.data)
else:
book_list = []
modify_data = []
for item in request.data:
pk = item.pop('id')
book_obj = models.Book.objects.get(pk=pk)
print(book_obj)
book_list.append(book_obj)
modify_data.append(item)
book_ser = BooKModelSerializer(instance=book_list, data=modify_data, many=True)
book_ser.is_valid(raise_exception=True)
book_ser.save()
return Response(book_ser.data)
class BookListSerializer(serializers.ListSerializer):
def update(self, instance, validated_data):
book_list = []
print(instance)
print(validated_data)
# 其实还是调用了添加单个的 update 方法
for i, ser_data in enumerate(validated_data):
result = self.child.update(instance[i], ser_data)
book_list.append(result)
return book_list
class BooKModelSerializer(serializers.ModelSerializer):
class Meta:
# 指定数据类型是列表类型的序列化类
list_serializer_class = BookListSerializer
批量删除和单个删除
class BooksView(APIView):
@staticmethod
def delete(request, *args, **kwargs):
pk_list = []
if kwargs.get('pk', False):
pk_list.append(kwargs.get('pk'))
else:
pk_list = request.data
delete_msg = models.Book.objects.filter(pk__in=pk_list, is_delete=True).delete()
return Response({'msg': delete_msg})
分页器
from rest_framework.viewsets import ModelViewSet
from rest_framework.generics import ListAPIView
from rest_framework.pagination import PageNumberPagination
from rest_framework.pagination import LimitOffsetPagination
from rest_framework.pagination import CursorPagination
class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = BooKModelSerializer
# 设置分页器类型
pagination_class = PageNumberPagination
class BookModelViewSet(ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = BooKModelSerializer
pagination_class = PageNumberPagination
# settings.py
REST_FRAMEWORK = {
# 全局设置分页时,一页放多少个数据
'PAGE_SIZE': 2,
}
自定义分页器
class MyPageNumberPagination(PageNumberPagination):
#http://127.0.0.1:8000/api/books2/?aaa=1&size=6
page_size=3 #每页条数
page_query_param='aaa' #查询第几页的key
page_size_query_param='size' # 每一页显示的条数
max_page_size=5 # 每页最大显示条数
class MyCursorPagination(CursorPagination):
cursor_query_param = 'cursor' # 每一页查询的key
page_size = 2 #每页显示的条数
ordering = '-id' #排序字段
class BookView(ListAPIView):
# queryset = models.Book.objects.all().filter(is_delete=False)
queryset = models.Book.objects.all()
serializer_class = BookModelSerializer
#配置分页
pagination_class = MyCursorPagination
**继承 APIView 进行分页 **
class BookView(APIView):
# throttle_classes = [MyThrottle,]
def get(self,request,*args,**kwargs):
book_list=models.Book.objects.all()
# 实例化得到一个分页器对象
page_cursor=MyPageNumberPagination()
book_list=page_cursor.paginate_queryset(book_list,request,view=self)
# 下一页的连接
next_url =page_cursor.get_next_link()
# 前一页的连接
pr_url=page_cursor.get_previous_link()
# print(next_url)
# print(pr_url)
book_ser=BookModelSerializer(book_list,many=True)
return Response(data=book_ser.data)
限制 ip 访问
# 写一个类,继承SimpleRateThrottle,只需要重写get_cache_key
from rest_framework.throttling import ScopedRateThrottle,SimpleRateThrottle
#继承SimpleRateThrottle
class MyThrottle(SimpleRateThrottle):
scope='luffy'
def get_cache_key(self, request, view):
return request.META.get('REMOTE_ADDR') # 返回
# 局部使用,全局使用
REST_FRAMEWORK={
'DEFAULT_THROTTLE_CLASSES': (
'utils.throttling.MyThrottle',
),
'DEFAULT_THROTTLE_RATES': {
'luffy': '3/m' # key要跟类中的scop对应
},
}
注册功能
- 使用了默认的 auth 表,并上传了头像,
- 两次密码的确认,但是不可能在数据库中创建 re_password 字段,那么在序列化时怎么办
- 密码加密
- 上传头像
# settings.py
# 配置外部访问媒体路径
MEDIA_URL = '/media/'
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
# 指定使用的 auth 表是自己定义的
AUTH_USER_MODEL = 'app001.user' # 格式:app 名.表名
# models.py
from django.db import models
from django.contrib.auth.models import AbstractUser
class User(AbstractUser):
mobile = models.CharField(max_length=32, unique=True)
icon = models.ImageField(upload_to='icon', default='icon/default.png')
# ser.py
from rest_framework import serializers
from rest_framework.exceptions import ValidationError
from app001 import models
class LoginModelSerializer(serializers.ModelSerializer):
re_password = serializers.CharField(write_only=True, required=True)
class Meta:
model = models.User
fields = ['username', 'password', 'mobile', 're_password']
@staticmethod
def validate_mobile(mobile):
if len(mobile) == 11:
return mobile
raise ValidationError('电话号码位数不对')
def validate(self, validate_date):
password = validate_date.get('password')
re_password = validate_date.get('re_password')
if password == re_password:
validate_date.pop('re_password')
return validate_date
raise ValidationError('两次密码不一致')
def create(self, validated_data):
# 原来的是 return models.User.objects.create(**validated_data) 密码不加密
return models.User.objects.create_user(**validated_data)
# 上传头像时用到的序列化类,仅仅上传头像所以只需要序列化 icon 字段即可
class UpdateModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.User
fields = ['icon']
# views.py
from rest_framework.viewsets import GenericViewSet
from rest_framework.mixins import CreateModelMixin,UpdateModelMixin
from app001 import models
from app001 import ser
# Create your views here.
class RegisterIView(GenericViewSet, CreateModelMixin,UpdateModelMixin):
queryset = models.User.objects.all()
serializer_class = ser.LoginModelSerializer
# 根据不同的请求选择不同的序列化类
def get_serializer_class(self):
if self.action == 'update':
return ser.UpdateModelSerializer
else:
return ser.LoginModelSerializer
# urls.py
from django.contrib import admin
from django.urls import path
from django.urls import re_path
from rest_framework import routers
from app001 import views
from django.views.static import serve
from django.conf import settings
route = routers.SimpleRouter()
route.register(prefix='register', viewset=views.RegisterIView)
urlpatterns = [
# 将 media 文件夹开放供外部访问
# '^media/(?P<path>.*)/' 这样是错误的
re_path('^media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT}),
]
urlpatterns += route.urls
JWT
- jwt:json web token
- jwt 分为三段式:头部(head)、身体(payload)、签名(sgin)
- 头和体是可逆加密,让服务器可以反解出 user 对象,签名是不可逆的,保证整个 token 的安全性
- 头、体、签名都是采用 json 格式的字符串进行加密,可逆加密一般采用 base64 算法,不可逆加密一般采用 hash(md5) 算法
- 头中的内容是基本信息:如公司信息、项目信息,token 采用的加密方式信息
- 体中的内容是关键信息:用户主键、用户名、签发时客户端信息(设备号、地址)、过期时间
- 签名中的内容是安全信息:头的加密结果 + 体的加密结果 + 服务器不外公开的安全码 进行 md5 加密
- 校验:
- 将 token 按
.拆分成三段字符串,第一段头加密字符串,一般不需要做任何处理 - 第二段体加密字符串,要反解出用户主键,通过主键从 Uuser 表中就能得到登录用户,过期时间和设备信息等安全信息,确保 token 没过期,并且是同一设备
- 再将前两段和服务器安全码进行 md5 加密,与第三段签名字符串进行碰撞校验,通过后才能代表第二段校验得到的 user 对象是合法的
- 将 token 按
- drf 项目的 jwt 认证开发流程
- 用账号密码访问登录接口,登录接口逻辑中调用签发 token 算法,得到 token 返回给客户端,客户端保存到自己的 cookie 中
- 校验 token 的算法应该写在认证类中(在认证类中调用),全局配置给认证组件,所有视图类的请求,都会进行认证校验,所以请求带了token,就会反解出user对象,在视图类中用 request.user 就能访问登录的用户
- 注意:登录接口需要做 认证 + 权限 局部禁用
简单使用
- 用户表使用 django 自带的 auth 表
# urls.py
from rest_framework_jwt.views import obtain_jwt_token
urlpatterns = [
path('login/',obtain_jwt_token)
]
-
限制登录用户必须携带 jwt
- 没有登录认证 jwt 是失效的
from rest_framework_jwt.authentication import JSONWebTokenAuthentication from rest_framework.permissions import IsAuthenticated # 设置为登录的用户才能访问的接口 class TemView(APIView): # 携带 jwt 认证 authentication_classes = [JSONWebTokenAuthentication, ] # 注意不是 permission_class # 登录认证 permission_classes = [IsAuthenticated, ] @staticmethod def get(request): return Response("用户已经登录") -
访问 TemView 时,需要在 headers 中添加如下:
- key:Authorization
- value: JWT eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6InJvb3QiLCJleHAiOjE2ODcyMjc5NjksImVtYWlsIjoiIn0.QWcQaYxV0mF4HKM93EIEYBYuhQVlLm_QmP4nR9ydDEY
- value 的格式是由内置的 JWT 决定的
自定义登录返回
# utils.py
def my_jwt_response_payload_handler(token, user=None, request=None):
return {
'token': token,
'msg': '登录成功',
'status': 100,
'username': user.username
}
# settings.py
# JWT 的全局配置
JWT_AUTH = {
'JWT_RESPONSE_PAYLOAD_HANDLER': 'app001.utils.my_jwt_response_payload_handler',
# 过期时间
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=7), # 过期时间,手动配置
}
自定义 jwt
# utils.py
from rest_framework.authentication import BaseAuthentication
from rest_framework_jwt.authentication import jwt_decode_handler
from rest_framework.exceptions import AuthenticationFailed
import jwt
from app001 import models
# 自定义 JWT 用户认证
class MyAuthentication(BaseAuthentication):
def authenticate(self, request):
# 获取 token 信息
jwt_value = request.META.get('HTTP_AUTHORIZATION')
if jwt_value:
try:
payload = jwt_decode_handler(jwt_value)
except jwt.ExpiredSignature:
raise AuthenticationFailed('签名过期')
except jwt.InvalidTokenError:
raise AuthenticationFailed('用户非法')
except Exception as e:
raise AuthenticationFailed(str(e))
print(payload) # {'user_id': 1, 'username': 'root', 'exp': 1687244675, 'email': ''}
user = models.User(id=payload.get('user_id'), username=payload.get('username'))
print(user)
return user, jwt_value
raise AuthenticationFailed('您未携带认证信息')
# views.py
# 自定义 JWT 认证
from app001 import utils
class JWTView(APIView):
authentication_classes = [utils.MyAuthentication, ]
@staticmethod
def get(request, *args, **kwargs):
return Response("用户已经登录")
用户多途径登录
- 比如用户可以使用用户名、邮箱或手机号登录
# views.py
from rest_framework.viewsets import ViewSet
class LoginView(ViewSet):
@staticmethod
def login(request, *args, **kwargs):
# context 是 ser 和 view 其他数据交互的桥梁,view 可以通过如下方式将 request 传过去
# 我们也可以使用 login_ser.context 获取 ser 的数据
login_ser = ser.Login2ModelSerializer(data=request.data, context={'request': request})
login_ser.is_valid(raise_exception=True) # 会自动调用 ser 中的 validate 方法进行校验
token = login_ser.context.get('token')
username = login_ser.context.get('username')
return Response({'status': 100, 'msg': '登陆成功', 'token': token, 'username': username})
# ser.py
from rest_framework import serializers
import re
from rest_framework_jwt.utils import jwt_encode_handler
from rest_framework_jwt.utils import jwt_payload_handler
from rest_framework.exceptions import ValidationError
from app001 import models
class Login2ModelSerializer(serializers.ModelSerializer):
username = serializers.CharField()
class Meta:
model = models.User
fields = ['username', 'password']
def validate(self, attrs):
username = attrs.get('username')
password = attrs.get('password')
if re.match('^1[3-9][0-9]{9}$', username):
user_obj = models.User.objects.filter(mobile=username).first()
elif re.match('^.+@.+$', username):
user_obj = models.User.objects.filter(email=username).first()
else:
user_obj = models.User.objects.filter(username=username).first()
if user_obj:
if user_obj.check_password(password):
# 签发 token
payload = jwt_payload_handler(user_obj) # 将 user_obj 传入得到 payload
token = jwt_encode_handler(payload) # 将 payload 传入得到 token
self.context['token'] = token
self.context['username'] = username
return attrs
else:
raise ValidationError("密码错误")
else:
raise ValidationError('用户不存在')
# urls.py
path('login2/', views.LoginView.as_view({'post': 'login'})),
cache 缓存
# 前端混合开发缓存的使用
-缓存的位置,通过配置文件来操作(以文件为例)
-缓存的粒度:
-全站缓存
中间件
MIDDLEWARE = [
'django.middleware.cache.UpdateCacheMiddleware',
。。。。
'django.middleware.cache.FetchFromCacheMiddleware',
]
CACHE_MIDDLEWARE_SECONDS=10 # 全站缓存时间
-单页面缓存
在视图函数上加装饰器
from django.views.decorators.cache import cache_page
@cache_page(5) # 缓存5s钟
def test_cache(request):
import time
ctime=time.time()
return render(request,'index.html',context={'ctime':ctime})
-页面局部缓存
{% load cache %}
{% cache 5 'name' %} # 5表示5s钟,name是唯一key值
{{ ctime }}
{% endcache %}
# 前后端分离缓存的使用
- 如何使用
from django.core.cache import cache
cache.set('key',value可以是任意数据类型)
cache.get('key')
-应用场景:
-第一次查询所有图书,你通过多表联查序列化之后的数据,直接缓存起来
-后续,直接先去缓存查,如果有直接返回,没有,再去连表查,返回之前再缓存
路飞学城项目
虚拟环境搭建
pip 换源
# 在 C:\Users\13475\AppData\Roaming\pip\pip.ini 下添加如下
[global]
index-url = http://pypi.douban.com/simple
[install]
use-mirrors =true
mirrors =http://pypi.douban.com/simple/
trusted-host =pypi.douban.com
- 在命令行自增加也行:
pip3 install pymysql -i 地址
下载虚拟环境
pip install virtualenv
pip install virtaulenvwrapper-win
# 将如下变量添加至环境变量
key: WORKON_HOME value: E:\development\pythonvirenv\Virtualenvs
创建虚拟环境
mkvirtualenv -p python3 luffy
workon luffy
# 在虚拟环境 luffy 中安装 django
pip install django==2.2.2
workon # 列出所有的虚拟环境
workon luffy # 使用 luffy 虚拟环境
mkvirtualenv -p python3 luffy # 使用 python3 创建虚拟环境
rmvirtualenv luffy # 删除虚拟环境 luffy
后台创建配置修改
目录结构
luffyapi
|__ logs/ # 项目运行时/开发时日志目录 - 包
|___ manage.py # 脚本文件
|___luffyapi/ # 项目主应用,开发时的代码保存 - 包
| |___ apps/ # 开发者的代码保存目录,以模块[子应用]为目录保存 - 包
| |___libs/ # 第三方类库的保存目录[第三方组件、模块] - 包
| |___settings/ # 配置目录 - 包
| | |___dev.py # 项目开发时的本地配置
| | |___ prod.py # 项目上线时的运行配置
| |___urls.py # 总路由
| |___wsgi.py
| |___utils/ # 多个模块[子应用]的公共函数类库[自己开发的组件]
|___scripts # 保存项目运营时的脚本文件 - 文件夹
配置开发环境
- 将 settings.py 中的所有内容 copy 到 dev.py 中,然后修改如下:
# dev.py
# 下面为添加
sys.path.insert(0,BASE_DIR)
sys.path.insert(1,os.path.join(BASE_DIR,'apps'))
# 下面为修改
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
USE_TZ = False
# 需要删掉一行,因为前后端分离,所以可以将 templates 文件夹删除
# 所以相应的配置也应该删除
# 'DIRS': [BASE_DIR / 'templates']
# manage.py
def main():
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'luffapi.settings.dev')
注意:当项目上线时,走的不是manage.py—》uwsgi.py,需要修改
os.environ.setdefault(‘DJANGO_SETTINGS_MODULE’, ‘luffyapi.settings.dev’)
- 注册 app
python ../manage.py startapp app_name # 在当前目录下创建 app
# dev.py
INSTALLED_APPS = [
'user',
'home',
]
连接数据库
# 修改源码
# query = query.decode(errors='replace')
query = query.encode(errors='replace')
创建用户表
- 扩展自带的 auth 表
- 由于需要外界访问头像,所以还需要暴露内部的一个文件夹
# models.py
from django.db import models
from django.contrib.auth.models import AbstractUser
class User(AbstractUser):
mobile = models.CharField(max_length=11, unique=True)
icon = models.ImageField(upload_to='icon', default='icon/default.png')
# dev.py
# 配置外部访问媒体路径
MEDIA_URL = '/media/'
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
# 指定使用的 auth 表是自己定义的
AUTH_USER_MODEL = 'user.user' # 格式:app 名.表名
# from django.contrib import admin
from django.contrib import admin
from django.urls import path
from django.urls import re_path
from django.urls import include
from django.views.static import serve
from django.conf import settings
urlpatterns = [
path('admin/', admin.site.urls),
# 设置路由分发
path('home/', include('luffyapi.apps.home.urls')),
path('user/', include('luffyapi.apps.user.urls')),
# 暴露内部文件给外部
re_path('media/(?P<path>.*)', serve, {'document_root': settings.MEDIA_ROOT})
]
跨域问题
- 同源策略:请求的的 url 地址,必须和浏览器上的地址处于同一区域上
- 同域:域名、端口、协议三者都相同
- CORS:跨域资源共享,允许不同的域向服务器请求数据
- 简单请求:必须同时满足下面的两个要求
- 请求方法仅限于 HEAD GET POST
- HTTP 的头信息仅限于 Accept、Accept-Language、Content-Language、Last-Event-ID
- Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
- 非简单请求
- 简单请求:必须同时满足下面的两个要求
- 开启跨域资源共享
- 下载中间件
pip install django-cors-headers
- 下载中间件
# 以下内容均在 dev.py 中添加
# 2. 注册 app
INSTALLED_APPS = [
'corsheaders',
]
# 3. 配置中间件
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
]
# 4. 配置必要配置
# 解决跨域问题
CORS_ORIGIN_ALLOW_ALL = True
CORS_ALLOW_METHODS = (
'DELETE',
'GET',
'OPTIONS',
'PATCH',
'POST',
'PUT',
'VIEW',
)
CORS_ALLOW_HEADERS = (
'authorization',
'content-type',
)
前后端打通
-
前后端的数据交互使用
axios-
安装
cnpm install axios -
在 main.js 中配置
import axios from 'axios' //导入安装的axios //相当于把axios这个对象放到了vue对象中,以后用 vue对象.$axios Vue.prototype.$axios = axios;
-
-
axios 的使用
// 使用(某个函数中)
// 向某个地址发送get请求
this.$axios.get('http://127.0.0.1:8000/home/home/').
// 如果请求成功,返回的数据在 response 中
then(function (response) {
console.log(response)
}).
// 捕获 error
catch(function (error) {
console.log(error)
})
// 上面的函数也可以使用 箭头函数
// function (response) { console.log(response)} 可以简写成下面的形式
response=>{ console.log(response)}
- 小案例
<!-- component.Test.vue -->
<template>
<div>
<!-- 马斯泰语法获取 -->
<p>{{ test_data }}</p>
</div>
</template>
<script>
export default {
name: "Test",
data(){
return {
test_data: String
}
},
created() {
<!-- 获取后端的数据 -->
this.$axios.get(this.$settings.base_url + '/home/test/').then(
response => {
this.test_data = response.data
}
).catch(
error => {
console.log(error)
}
)
}
}
</script>
<style scoped>
</style>
<!--views.home.vue -->
<template>
<div class="home">
<!--3. 在 template 中直接使用即可 -->
<Test/>
</div>
</template>
<script>
// 1. 导入头部组件
import Test from "@/components/Test.vue";
export default {
name: 'Home',
components: {
// 2. 在 components 中进行注册
Test,
}
}
</script>
xadmin 的使用
-
安装
https://codeload.github.com/sshwsfc/xadmin/zip/django2 -
在 dev.py 中进行 app 注册
INSTALLED_APPS = [ # xadmin主体模块 'xadmin', # 渲染表格模块 'crispy_forms', # 为模型通过版本控制,可以回滚数据 'reversion', ] -
主路由替换掉 admin
# xadmin的依赖 import xadmin xadmin.autodiscover() # xversion模块自动注册需要版本控制的 Model from xadmin.plugins import xversion xversion.register_models() urlpatterns = [ # ... path(r'xadmin/', xadmin.site.urls), ] -
原来的 admin.py 更改入下
import xadmin from luffyapi.apps.home import models xadmin.sites.register(models.Banner)
协同开发 git
#1 协同开发,版本管理
#2 svn(集中式管理),git(分布式管理)
#3 git装完,既有客户端,又有服务的
#4 git工作流程
-工作区,暂存区,版本库
#5 远程仓库:github,码云,公司内部(gitlab)
# 6 安装:一路下一步
# 7 右键--git bash here
# 8 git 命令
-初始化:git init 文件夹名
-初始化:git init #当前路径全被管理
-git status
-git add a.txt # 把a提交到暂存区
-git add .
-git commit -m '注释,我新增了a' # 把暂存区的所有都提交到版本库
-需要增加作者信息
git config --global user.email "lqz@qq.com"
git config --global user.name "lqz"
git config user.email "egon@qq.com"
git config user.name "egon"
-把a的新增提交到版本管理
-新建b,在a中新增一行
-git checkout . # 回复到提交版本的位置,a是空的,b没有被git管理,所有,是什么样,还是什么样
-git log # 查看版本管理的日志
-git reflog # 查看日志,条数更多,内容更少
-git reset --hard 版本号
# 红色表示未被管理
# 绿色表示提交到暂存区了
# 忽略文件
-空文件夹不被管理
-指定某些文件或者文件夹不被git管理
-在项目根路径,跟.git文件夹一个路径,新建.gitignore.,在里面配置
- 语法:
# 号是注释,没有用
文件夹名字,表示文件夹忽略,不被管理
/dist 表示根路径下的dist文件夹,不被管理
*.py 表示后缀名为py的文件,都被忽略
*.log*
# 分支操作
-查看分支 git branch 查看所有分支,分支是绿的,表示在当前分支上
-创建分支 git branch dev
-创建并切换到 git checkout -b dev
-删除分支 git branch -d dev
-切换分支 git checkout dev
-合并分支 git merge 分支名 # 把dev分支合并到master分支:切换到master分支,执行合并dev分支的命令
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!