Apache Seatunnel本地源码构建编译运行调试
Apache Seatunnel本地源码构建编译运行调试
1. 环境准备
??本文使用的是windows10-64位专业版的电脑,需要安装环境如下
1.1 Java环境
??jdk>=1.8 - 64 位的jdk、
1.2 Maven
??使用的是idea自带的maven,最好是安装一个方便源码编译构建,使用idea自带的maven无法执行mvnw,但是可以复制mvnw后面的在idea的maven中的run maven中的new goal里面执行即可。
1.3 IDEA
??代码编辑调试运行器
1.4 Docker环境
??mysql8.0.28的安装是使用docker安装部署
1.5 Mysql8.0.28
https://mp.weixin.qq.com/s/5PC_VXtNc8689ag8b8cYLA
??以上那几个步骤省略
1.6 其它环境准备
??还需要如下的如下环境:
https://mp.weixin.qq.com/s/qHHcbl6AMmdEbZLKnhz_tA
https://mp.weixin.qq.com/s/BaXK0dMu4whOrnKQbb6G-A
Windows10之wsl-Linux子系统安装JDK、Maven环境
https://mp.weixin.qq.com/s/Lq30469wZgikM72s8tv1ZA
在阅读本文需要对Apache SeaTunne有一点了解
https://mp.weixin.qq.com/s/uHZ-29OF-NawOL4oZW6z2A
2. 源码包下载
https://seatunnel.apache.org/download
https://github.com/apache/seatunnel
https://github.com/apache/seatunnel-web
??seatunnel可以在官方的download下载源码包或者在github上下载tag2.3.3包,不要下载2.3.3-release,不要下载xxx-release的分支,就拿2.3.3-release分支来说,里面的项目版本有2.3.3、又有2.3.4的版本,项目模块之前的版本不统一,就会导致编译版本冲突,下载tag中的2.3.3或者是download源码Source Code包,本文使用的tag2.3.3的包来本地编译构建运行的,使用2.3.3-release分支版本不统一导致冲突,我怀疑这个2.3.3-release分支估计是他们的开发分支,所以这里是需要注意的,不然很难在本地搞起来,seatunnel-web项目拉取的是1.0.0-release分支的代码。
3. idea项目配置
3.1 项目导入
??seatunnel解压路径如下:
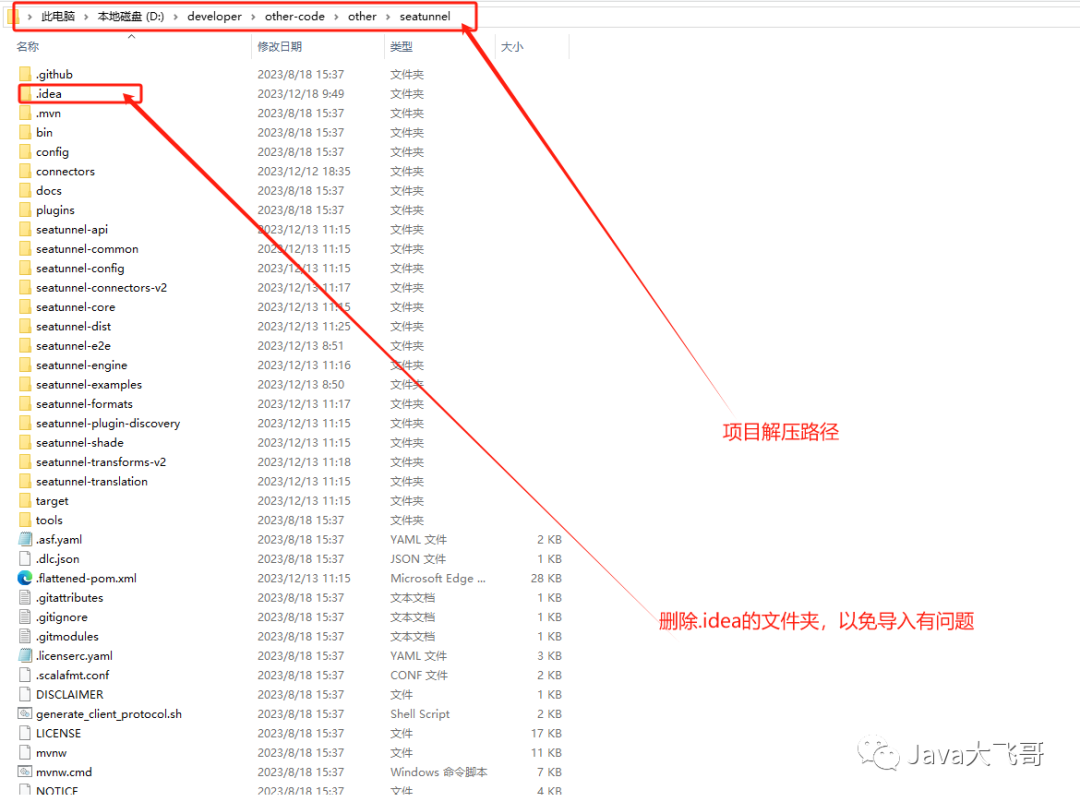
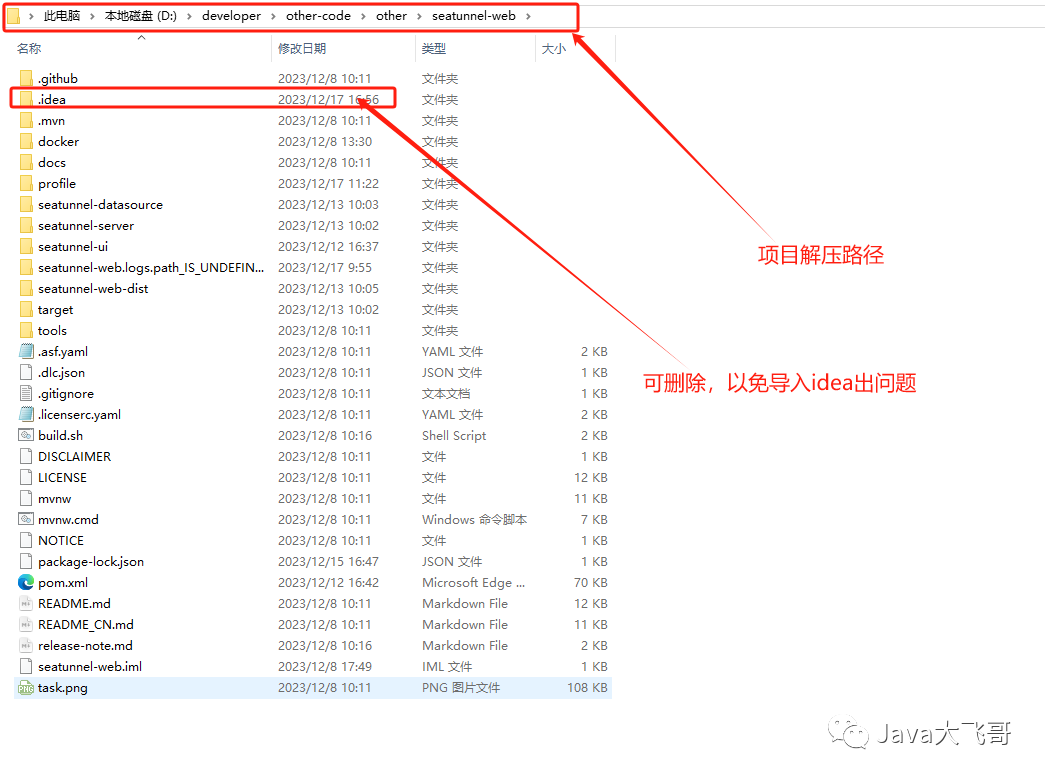
??seatunnel-web路径如下:
git clone https://github.com/apache/seatunnel-web.git
git checkout 1.0.0-release
或者使用git拉取,git环境可要可不要
3.2 maven配置
??setting.xml配置
??配置成阿里的maven仓库方便编译构建是下载拉取项目所需的依赖包
<localRepository>D:\developer\repository</localRepository> <!--改为自己的本地maven仓库的路径即可-->
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
<mirror>
<id>aliyunmaven2</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库2</name>
<url>https://maven.aliyun.com/repository/apache-snapshots</url>
</mirror>
<mirror>
<id>aliyunmaven3</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库3</name>
<url>https://maven.aliyun.com/repository/central</url>
</mirror>
</mirrors>
??idaea的maven配置
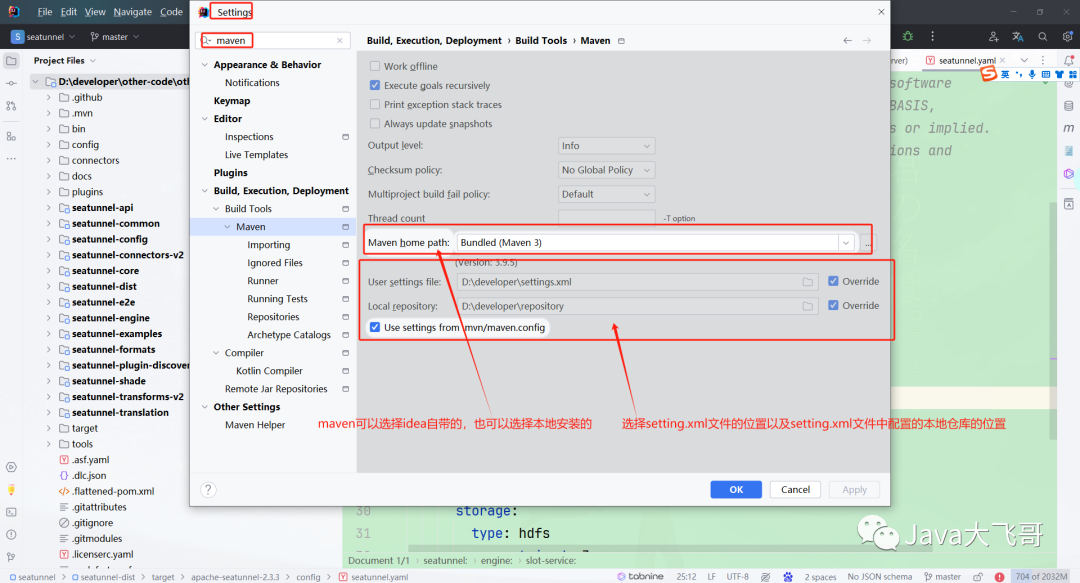
??两个项目都是这种配置,这里选择一个演示即可。
3.3 项目JDK配置

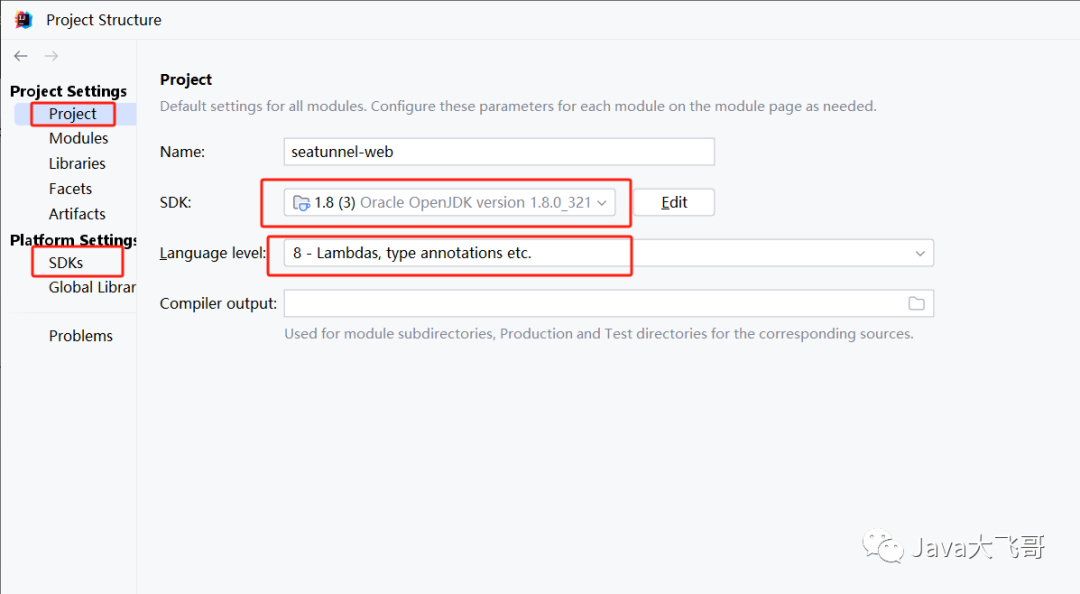
??在project和SDKs选项中选择配置下jdk,两个项目都是这种配置,这里选择一个演示即可。
3.4 项目启动参数配置
3.4.1 seatunnel项目启动参数配置
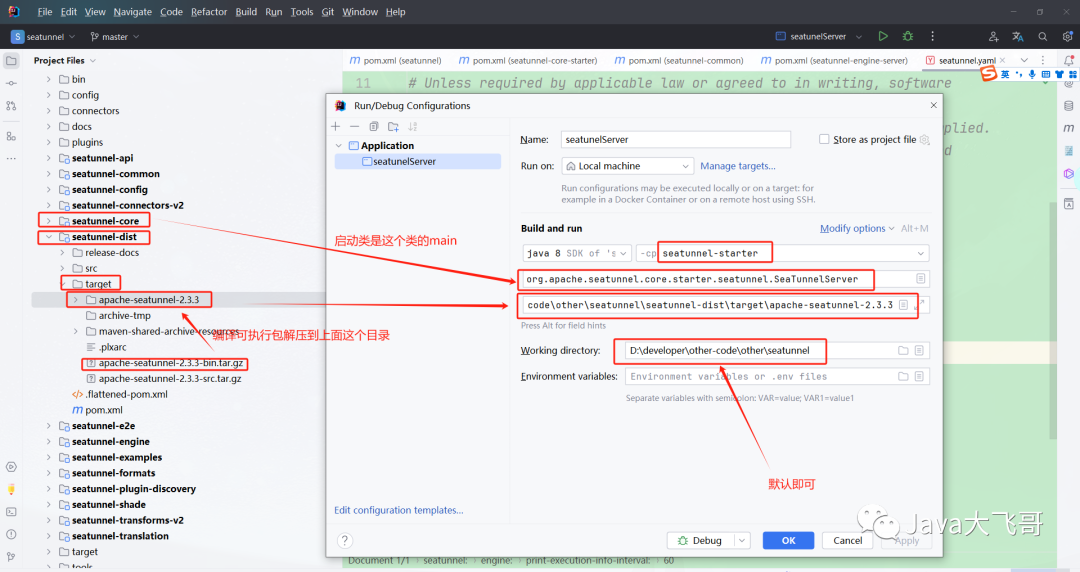
??jvm参数如下:编译的压缩包的解压路径
-DSEATUNNEL_HOME=D:\developer\other-code\other\seatunnel\seatunnel-dist\target\apache-seatunnel-2.3.3
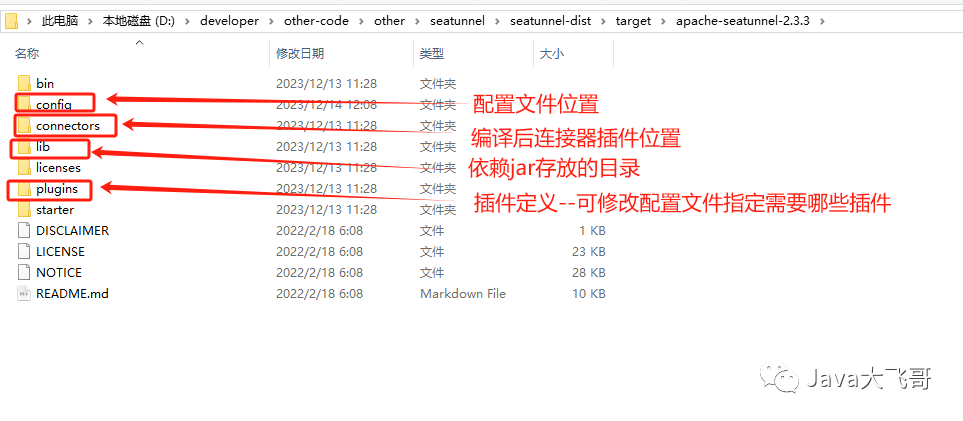
??项目编译后会输出到seatunnel-dist的target下
3.4.2 seatunnel-web项目启动参数配置


??jvm参数和环境变量如下:
jvm参数
-DSEATUNNEL_HOME=D:\developer\other-code\other\seatunnel\seatunnel-dist\target\apache-sea
环境变量
ST_WEB_BASEDIR_PATH=D:\developer\other-code\other\seatunnel-web\seatunnel-web-dist\target\apache-seatunnel-web-1.0.1-SNAPSHOT\apache-seatunnel-web-1.0.1-SNAPSHOT
??项目编译后会输出到seatunnel-web-dist的target下
4. 源码编译运行
4.1 sql脚本执行
??脚本如下,复制出来执行即可:
??数据库执行如下:
4.2 编译构建
4.2.1 seatunnel编译构建
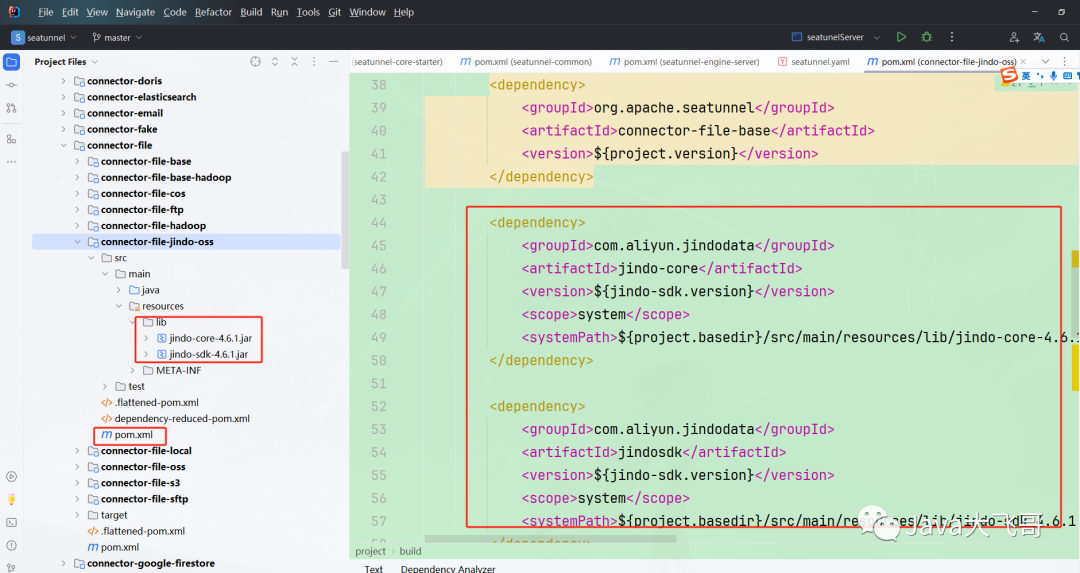
??jindodata先关的jar需要自行下载导入,在seatunnel-connectors-v2–>connector-file–>connector-file-jindo-oss的pom文件修改依赖如下:
<dependency>
<groupId>com.aliyun.jindodata</groupId>
<artifactId>jindo-core</artifactId>
<version>${jindo-sdk.version}</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/lib/jindo-core-4.6.1.jar</systemPath>
</dependency>
<dependency>
<groupId>com.aliyun.jindodata</groupId>
<artifactId>jindosdk</artifactId>
<version>${jindo-sdk.version}</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/lib/jindo-sdk-4.6.1.jar</systemPath>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.4.2</version>
<configuration>
<includeSystemScope>true</includeSystemScope>
</configuration>
</plugin>
</plugins>
</build>
??引入jindodata相关的本地依赖和打包插件,jindodata相关包会在文末分享给大家
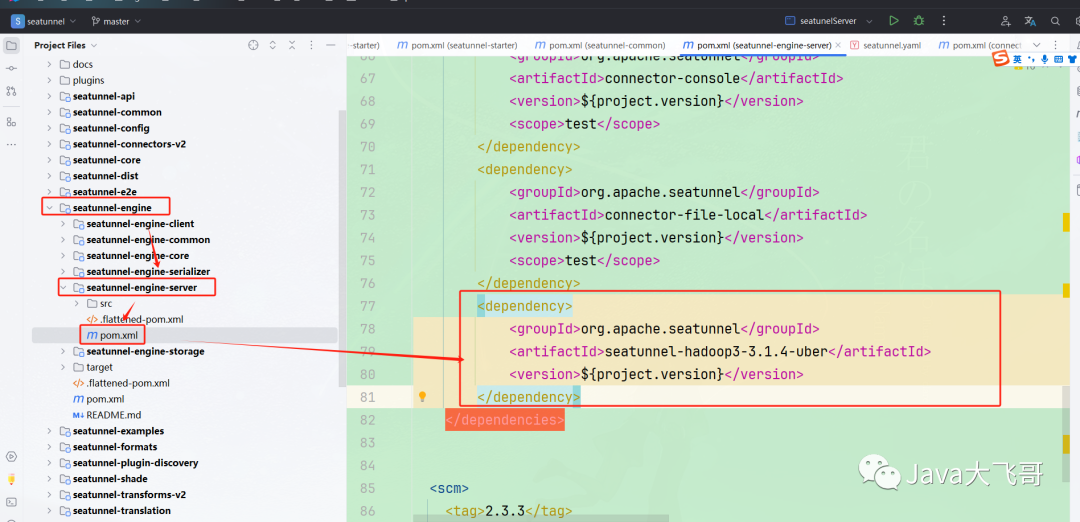
??修改seatunnel-hadoop3-3.1.4-uber的maven如下:
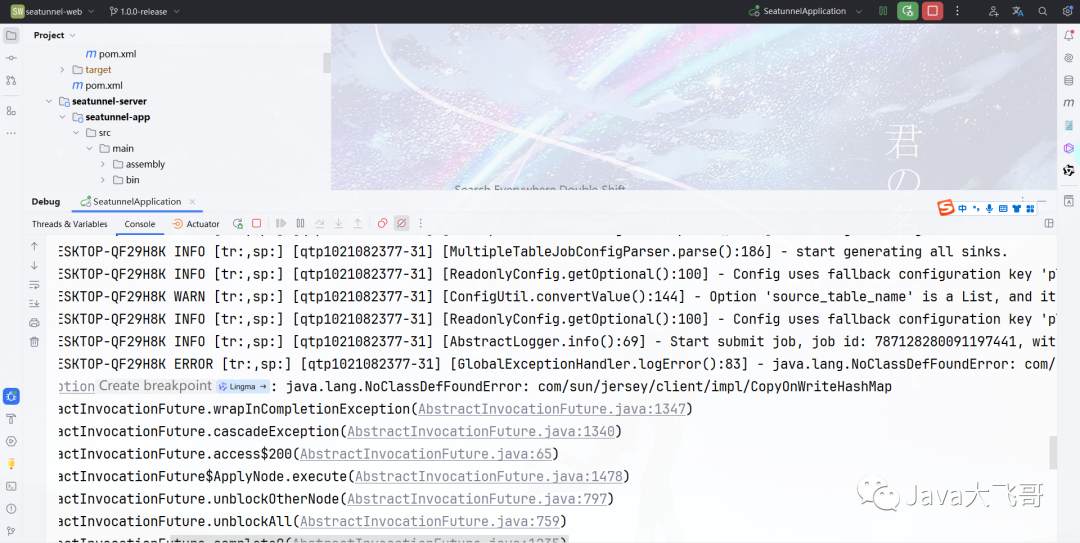
??该包如果不修改直接引入会导致下面的类死活依赖不到,后面将改包放入到taget的解压路径下的lib里面不生效导致报错如下:
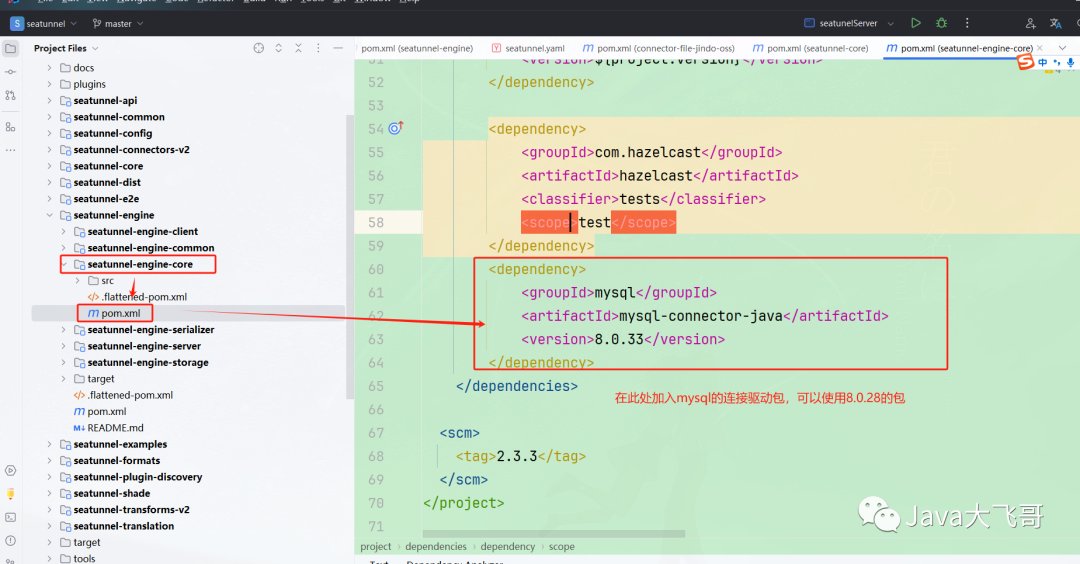
??加入mysql8.x的连接驱动包,这里不加的话,可以在解压的target目录下的lib中把这个jar包放进去,因为本文要进行的是mysql-jdbc—>mysql-jdbc的单表数据同步,所以需要这个jar包
??seatunnel.yaml配置,这个基本默认即可
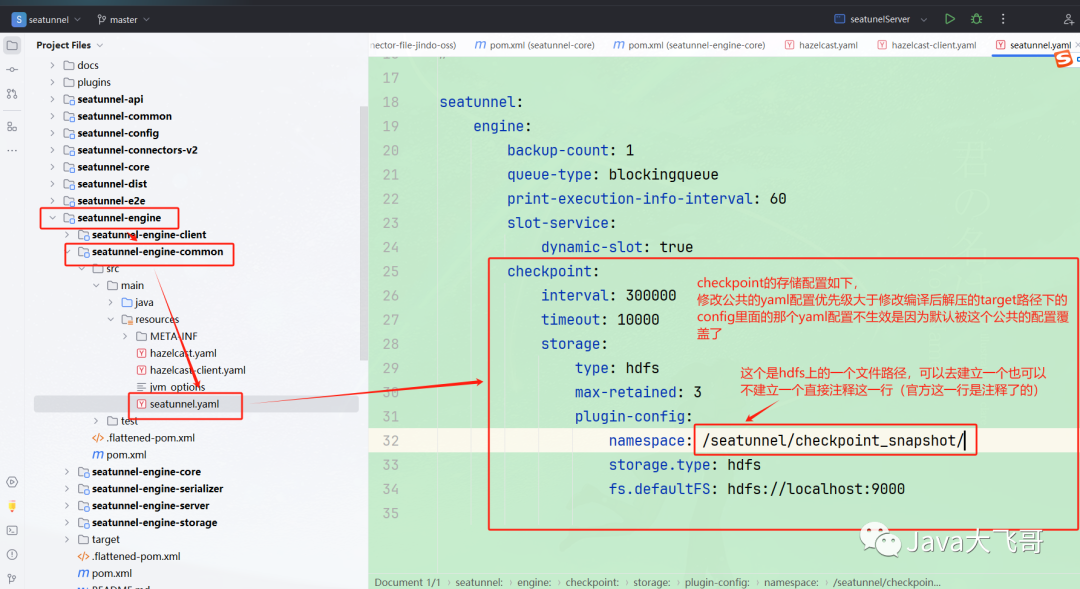
??如果下载的是release支付的包或代码,需要在整个项目的pom中加入如下的配置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-gpg-plugin</artifactId>
<version>3.0.1</version>
<executions>
<execution>
<id>sign-artifacts</id>
<phase>verify</phase>
<goals>
<goal>sign</goal>
</goals>
</execution>
</executions>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
??该插件配置是或略打包时候的gpg签名校验,不然会编译不通过,好多开源正规的项目都有这种签名校验的,所以需要加入这个插件才可以编译通过
4.2.3 seatunnel-web编译构建
??seatunnel-server–>seatunnel-app–>pom加入mysql8.x的连接驱动包,可以使用8.0.28的包
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
??修改seatunnel-app下的application.yml
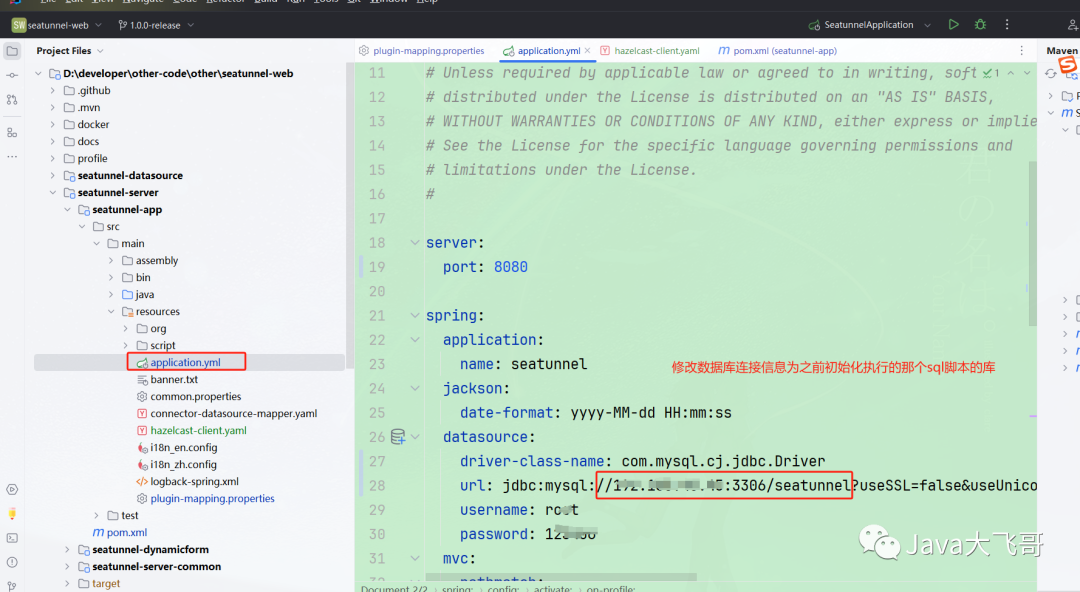
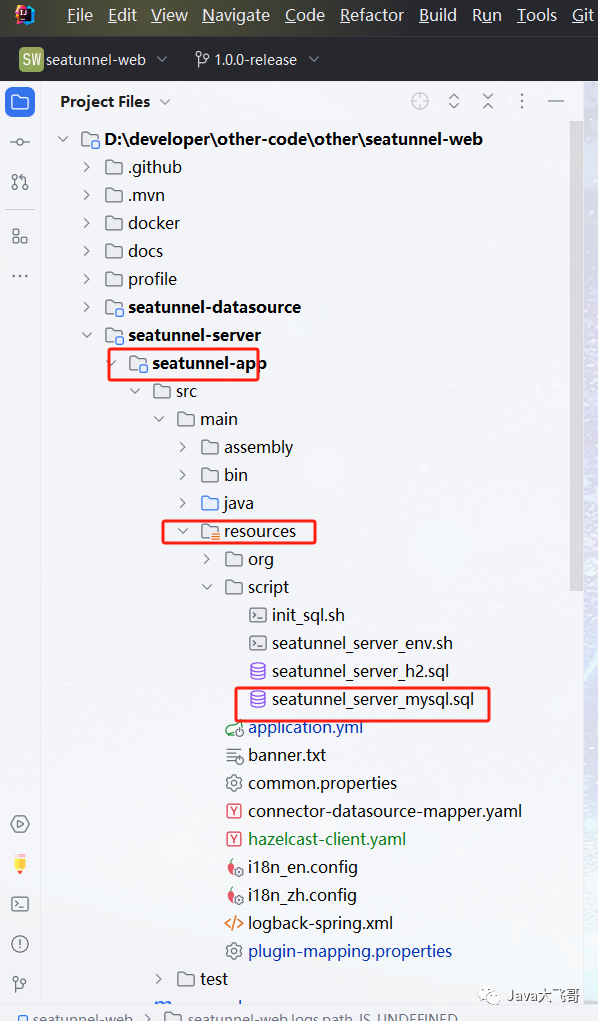
??将seatunnel项目里面编译到seatunnel-dist下target里面的解压文件里面的的hazelcast-client.yaml文件和connectors文件下的plugin-mapping.properties(这个文件已经包含了,可以修改,注释里面的一些插件,放入自己需要的插件即可)文件拷贝到seatunnel-app的rusources里面,如上图所示.
??plugin-mapping.properties配置文件修改只包含如下两个插件:
seatunnel.source.Jdbc = connector-jdbc
seatunnel.sink.Jdbc = connector-jdbc
4.3 编译打包命令
seatunnel项目运行这个:
mvn clean package -pl seatunnel-dist -am -Dmaven.test.skip=true
seatunnel打包插件命令实例如下:
mvn clean package -pl seatunnel-connectors-v2/connector-jdbc -am -DskipTests -T 1C
seatunnel-web项目运行这个:
mvn clean package -pl seatunnel-web-dist -am -Dmaven.test.skip=true
或者可以直接点击右侧maven的package打包即可
??关于这个编译构建的官方也有讲,下面两个连接打开就有,需要仔细的阅读
https://seatunnel.apache.org/docs/2.3.3/contribution/setup
https://github.com/apache/seatunnel-web
4.4 启动运行
??在启动前需要先启动本地的mysql8.x、hadoop3.1.3
??在启动之前将如下的jar包放入到seatunnel和seatunnel-web编译构建的target的lib目录下,以免启动由于缺少jar依赖而报错

??或者是把项目中编译好的插件或数据源jar复制到这个两个项目的target的lib目录下也是可以的,上面的是我去阿里云maven仓库下载的
??然后先启动seatunnel在启动seatunnel-web
??前端ui编译启动
??ui源码构建发布前需要修改访问后端的端口号:
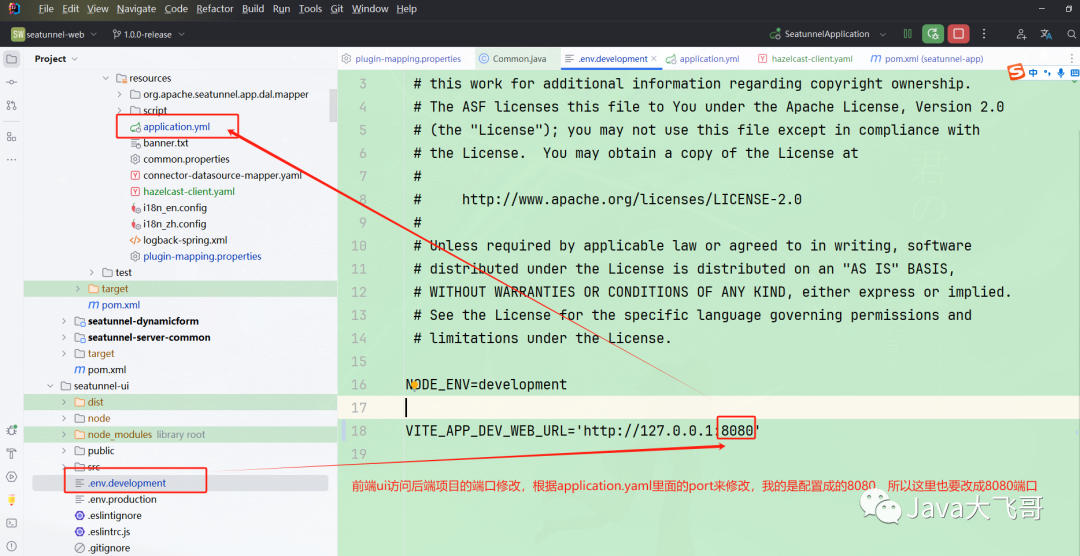
??cmd进入到seatunnel-web—>seatunnel-ui
??路径执行如下命令:
npm install
npm run dev
4.5 访问首页
??访问地址:
http://localhost:5173/
用户名/密码都是admin

5. mysql-jdbc 到mysql-jdbc的单表数据同步
5.1 添加数据源
??如果创建不可以选择说明是对应的lib下面没有放入对应的数据源的插件jar包

5.2 同步任务定义
??这里我们添加的是两个mysql-jdbc的数据源,这里采用任务类型是“数据集成”,mysql的单表同步到mysql的单表
??将seatunnel库中的表role表同步到seatunnel_copy数据库中的role表中,seatunnel_copy数据库中的role表的结构和seatunnel库中的表role表结构一模一样
??任务的source和sink的数据源如果不可以选,说明是lib下没有数据源相关的jar,需要放入指定的jar重启项目才可以选数据源
??source配置如下:

??sink配置如下:

5.3 同步任务执行
??保存选择任务的类型使用的流式任务:(保存可以选择流式任务也可以选择批任务)
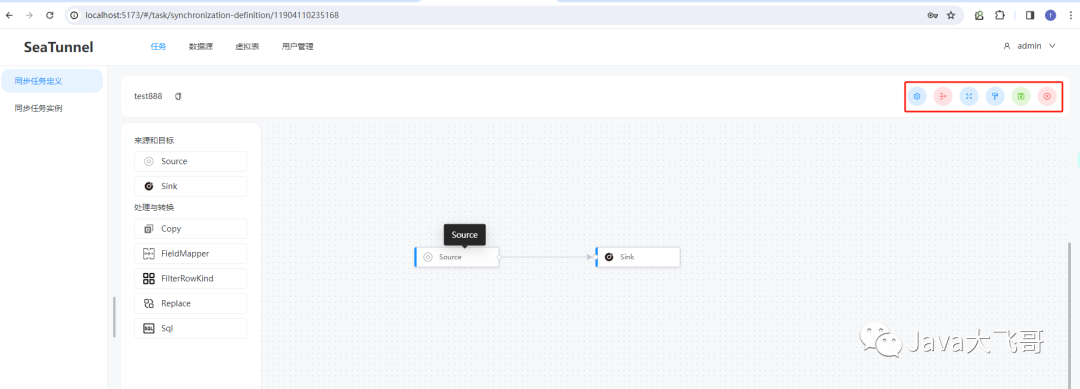
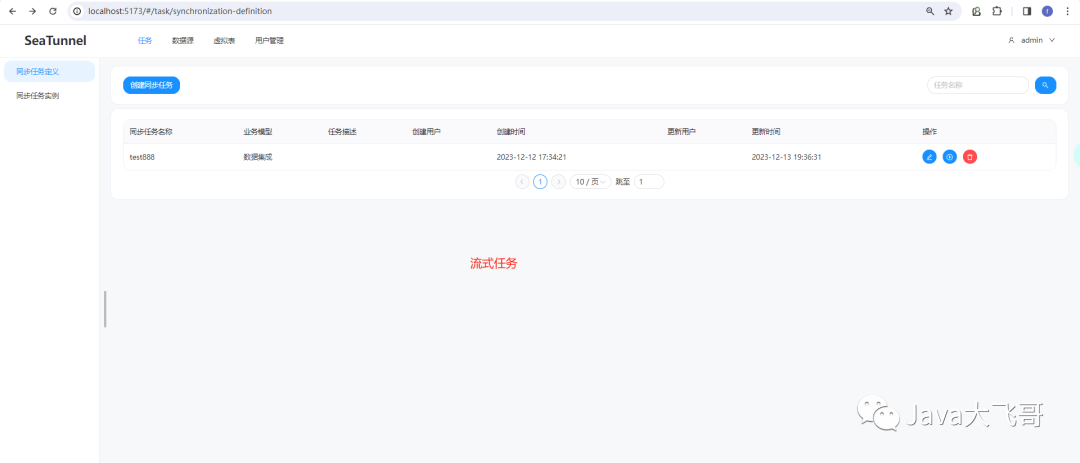
??配置好任务之后,就可以点击运行按钮,执行完之后在“同步任务实例”列表中就可以看到之前的任务,状态是已完成
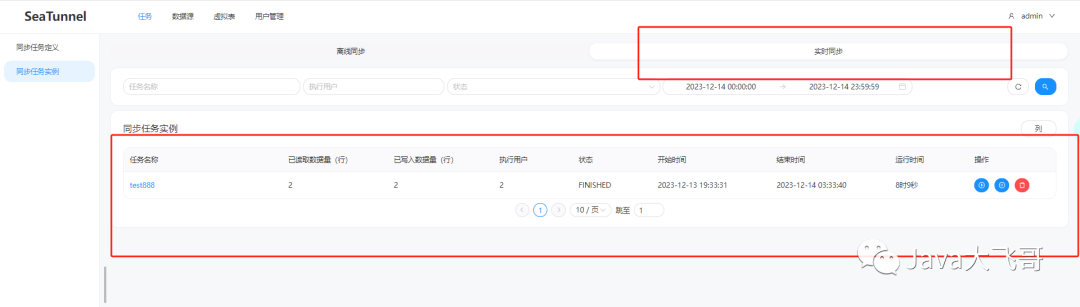
5.4 同步任务执行遇到的问题
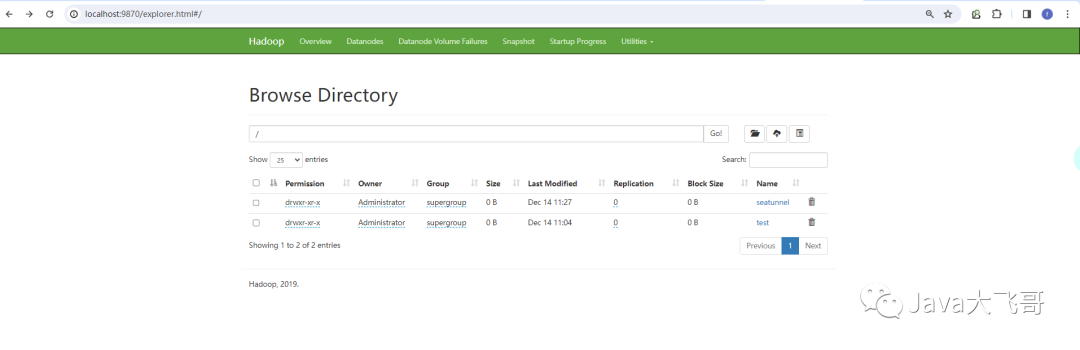
??如果状态执行不是已完成就会是一个以失败的状态,原因可能是缺少jar包或者是本地缺少hadoop3.1.3的环境,hadoop的环境官方的大佬说不是必须的,但是我在本地做这个案例的时候没有hadoop会执行报错的,所以上面seatunnel引擎的公共模块中的seatunnel.yaml配置里面配置了hdfs相关存储的信息,所以还需要去hdfs上新建一个目录如下:

??这个目录不建立没有试过会不会报错,反正是有总比没有好,本地没有hapood会报如下错误:
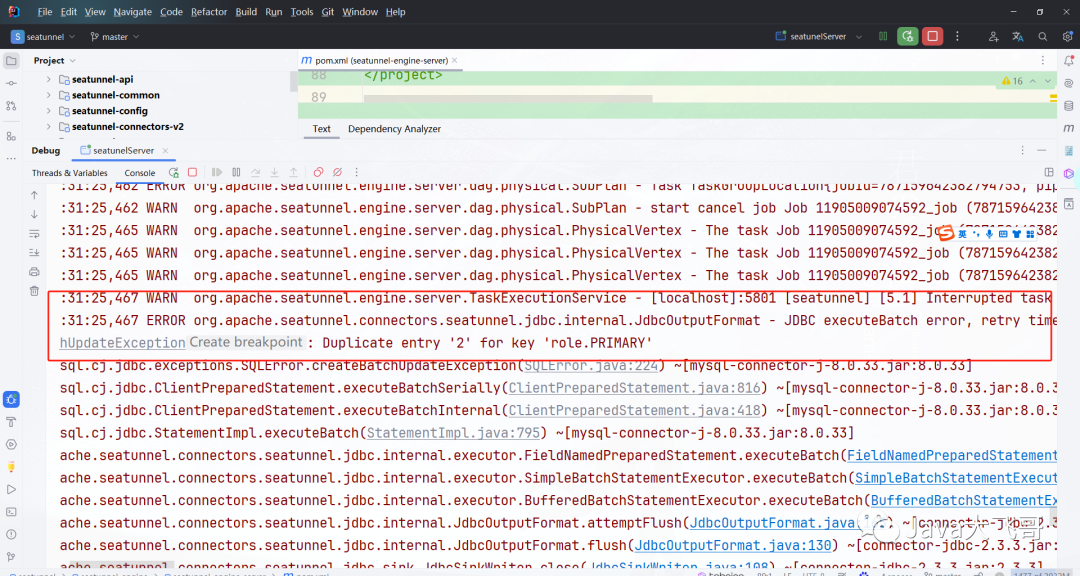
??大致上是任务在执行的时候需要做一些任务的检查点或保存点的数据状态的存储,上面那个报错感觉是执行了两次或者是多个线程执行过导致数据本来第一次是已经同步过去了,后面有搞了一次就主键冲突导致任务状态变成失败了,有了hdfs就不会有这个报错的,也是很神奇。
5.5 同步任务执行的结果
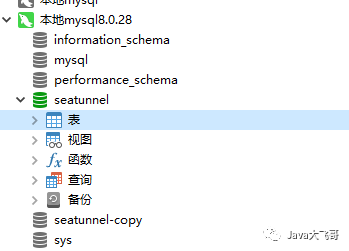
??可以看到seatunnel库中role表数据同步到seatunnel_copy数据库中的role表中了
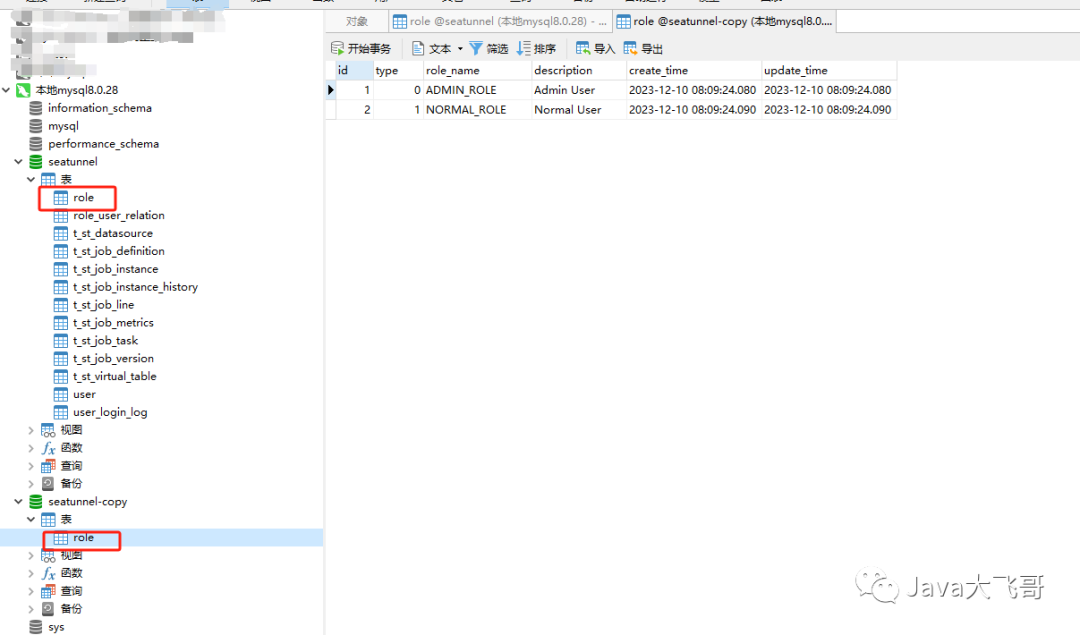
6. 总结
??本地源码编译运行已经分享完了,这样做是为了更好的理解这个项目,你可以跑起来在idea中本地两边的项目打上断点,使用debug调试跟踪源码,可以开发一个插件或者是为这个项目贡献源码,或者是用于学习,通过欣赏项目的源码来学习项目中的一些好的设计思路,我个人觉得这个项目的亮点有一下几点:
??第一:使用hazelcast(底层基于netty和socket)实现了内核集群,同时也可以使用hazelcast的代client向hazelcast引擎服务提交一个任务,然后该任务由web端或者是linux的控制台提交到引擎服务上(提交的任务是一个json的文件,里面定义好了input、transform和sink这三个阶段的信息),引擎服务又有master和work,主节点负责管理work节点的状态和任务调度(任务需要下发到那个work节点上执行,利用多机分布式来跑任务),并且会对任务做保存点or检查点(有点像fink的保存点和检查点的概念)。
??第二是插件机制:一个插件就是一个jar包,把公共的流程步骤高度抽象封装到上层的api中,差异化的实现各种场景下的数据同步需求,数据源和插件是很丰富的
??第三是类加载器:实现了自己的类加载器,项目启动就通过自己实现的类加载器加载指定路径下的插件jar包,就是通过这种插件的加载机制来完成按需加载,插件的机制就是上一个插件的输出作为下一个插件的输入,数据在一个插件链条上滚动传递,有点像设计模式中的责任链模式。
??第四是三套引擎:默认使用的是自研的SeaTunnelEngine,还支持flink和spark两大引擎。
??上面只是我个人看到的一些优点,也没有细细的看,就随便看了下,或许还有我不晓得的新东西,上面的hazelcast可以研究学下下,插件机制和自定义类加载机制是可以应用于我们平时的业务代码开发中。
??有优点同样也存在缺点,她是一个闪亮的星星还处于发展阶段,相对来说还不是那么成熟,所以选型得慎重考虑,官方的文档虽然是比较全的,但是基本是英文的并且篇幅比较短,字少事多,赶脚写的不是那么详细,有的影藏的细节的东西,需要查看官方的公众号的文章或者是看源码中才能找到答案的,在遇到问题的时候最好的方法是找官方,寻求官方的帮助,加入官方的群聊,可以直接和大佬沟通,或者是你自己改源码解决,感觉不太靠谱还是不要使用以免背锅,本地构建编译如果你实在是编译运行不起来的话,多花一点时间是可以搞出来的,这个玩意我搞了有一个星期了吧,实在是有点蛋疼遇到各种奇葩的问题,在搞不出来,都有点想不搞了,放弃吧,但是一想在试一试结果还是被我搞出来了,坚持向下凿水源距离你可能就差一步之遥了,其实也是可以不编译构建,欣赏下源码也是不错的选择,然后不用把时间浪费在这个构建编译上,其实是为了打断点好调试一点,光看代码的话,也是只能浏览下看个大概,在学习研究这种开源的项目,也在只能是看他的官方文档和其他的一些博客资料,边搞边猜,边猜边搞,慢慢的也基本上能搞通,需要参看好多的文章或信息,然后从中实践出真知,所以我就写了这篇文章总结了下,下一篇文章分享在centOs上的安装部署实践mysql-jdbc==>mysql-jdbc同步例子中遇到的坑,敬请期待下一篇文章,希望我的分享对你有所帮助,请一键三连,么么么哒!
7.资料分享
链接:https://pan.baidu.com/s/1DWKpX2j5nyvDT3UucVc1Sg
提取码:ip7p
??seatunnel-2.3.3.zip是tag的源码包, apache-seatunnel-2.3.3-src.tar.gz这个是官网的download下载的sourceCode包。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 推荐一款可以自动创建视频的前端Ract框架
- 2020年财政收支
- 学习笔记-李沐动手学深度学习(三)(10-11,隐藏层、多层感知机、激活函数、模型超参数选择、欠过拟合)
- JAVA开发中几个常用的lambda表达式!记得收藏起来哦~
- pytorch 通用训练代码讲解(very good)
- 护眼台灯哪个牌子好?2024年专业护眼台灯品牌排行榜!
- 代码随想录算法训练营第十四天 | 二叉树理论基础、递归遍历 、迭代遍历、统一迭代
- 开发代码基础
- 你在为其他知识付费平台做流量吗?
- Windows操作系统:共享文件夹,防火墙的设置