关于图像分类任务中划分数据集,并且生成分类类别的josn字典文件
发布时间:2024年01月06日
1. 前言
在做图像分类任务的时候,数据格式是文件夹格式,相同文件夹下存放同一类型的类别
不少网上的数据,没有划分数据集,虽然代码简单,每次重新编写还是颇为麻烦,这里记录一下
如下,有的数据集这样摆放:

可以看出这是个三分类任务,不过没有划分测试集、验证集
代码存放位置:和数据集dataset 同一路径

2. 完整代码
如下:
import random
import os
import shutil
from tqdm import tqdm
import json
def split_data(root, test_rate, flag=True):
# 待分类数据的当前目录
classes_directory = [i for i in os.listdir(root) if os.path.isdir(os.path.join(root, i))]
# 建立生成后的目录,方便拷贝
for i in classes_directory:
os.makedirs(os.path.join('./data/train', i)) # 训练集
os.makedirs(os.path.join('./data/test', i)) # 测试集
# 是否生成类别的 json 字典文件,默认生成
if flag:
class_indices = dict((k, v) for v, k in enumerate(classes_directory))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 遍历每个文件夹下的文件
for cla in classes_directory:
cla_path = os.path.join(root, cla) # 每个文件夹的路径
images_path = [os.path.join(root, cla, i) for i in os.listdir(cla_path)]
# 按比例随机采样测试集样本
test_split_path = random.sample(images_path, k=int(len(images_path) * test_rate))
# 划分数据
for i in tqdm(images_path, desc=cla):
if i in test_split_path:
shutil.copy(i, os.path.join('./data/test', cla))
else:
shutil.copy(i, os.path.join('./data/train', cla))
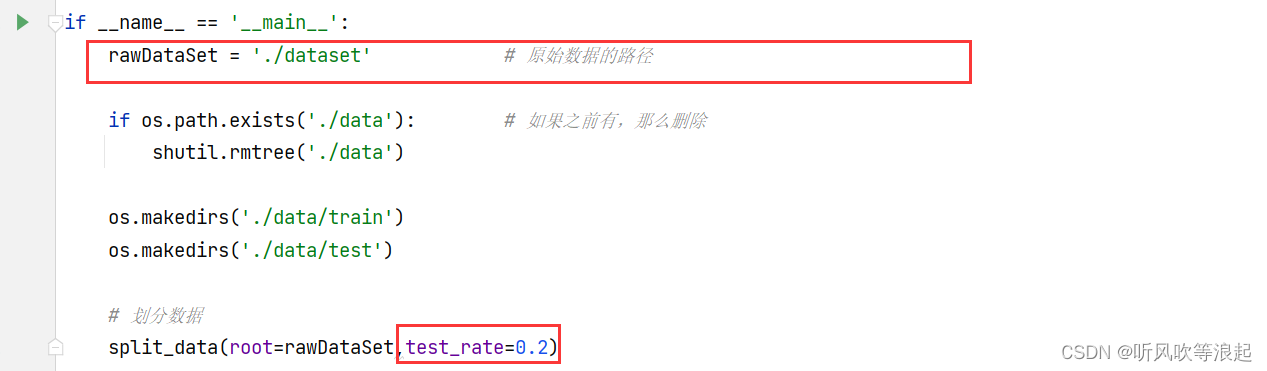
if __name__ == '__main__':
rawDataSet = './dataset' # 原始数据的路径
if os.path.exists('./data'): # 如果之前有,那么删除
shutil.rmtree('./data')
os.makedirs('./data/train')
os.makedirs('./data/test')
# 划分数据
split_data(root=rawDataSet, test_rate=0.2)运行代码过程:

运行结果:
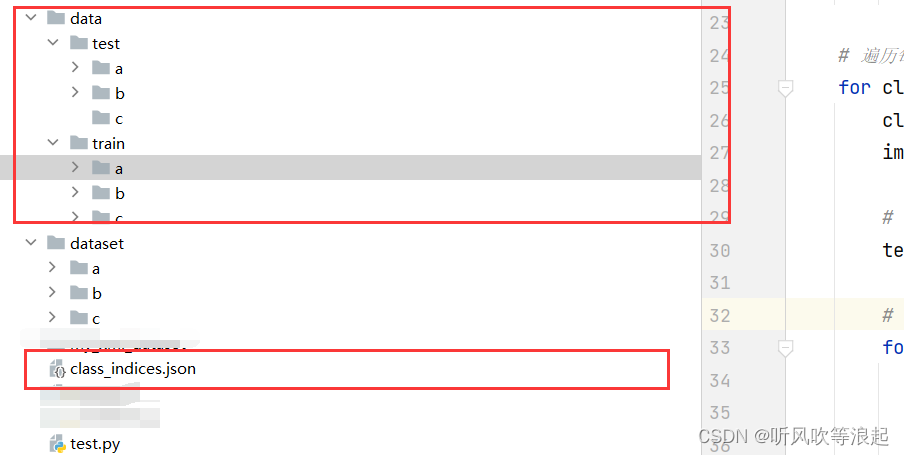
生成的json文件:

3. 代码介绍
首先,rawDataSet 传入的是待划分的数据集根目录,这里会将之前划分的删掉,这样每次生成的结果不一样。训练集和测试集的比例为0.2
这里按照本人平时的习惯,划分好的目录结构如下
--data-train- 不同类别的文件夹
--data-test- 不同类别的文件夹
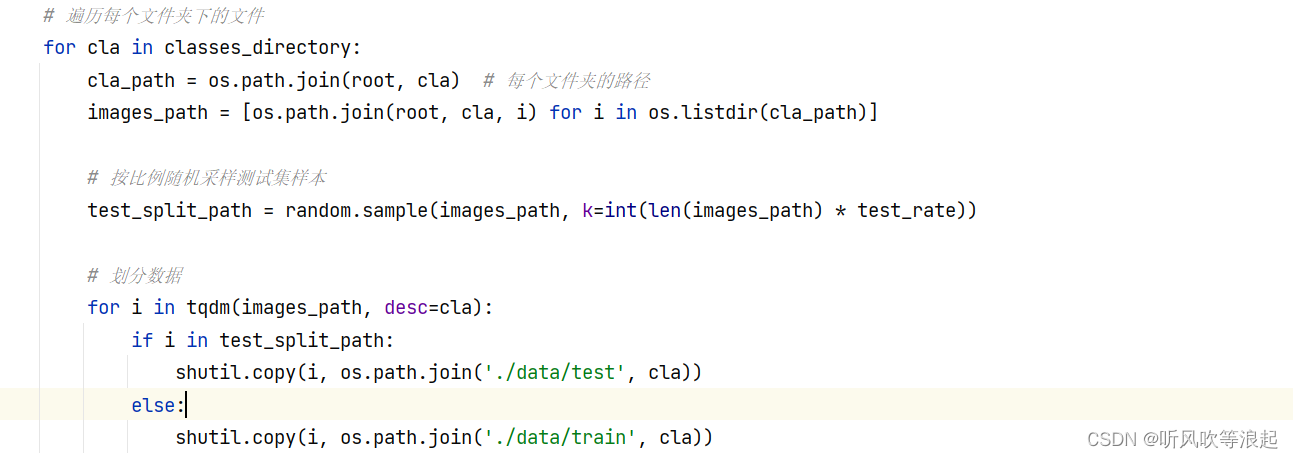
接下来这部分是读取每个子文件夹,或者说分类的classes(因为分类任务的文件夹就是class)
这里根据子文件夹名生成对应的json字典文件

划分数据,测试集会根据总数据的个数 * 划分比例 (test_rate)
遍历全部的数据,如果目标在测试集,那么就是测试集数据;否则为训练数据
如果是目标检测或者分割,数据和标签是分开的单独文件,划分的过程类似,后续会看着写写看
文章来源:https://blog.csdn.net/qq_44886601/article/details/135431820
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 毫秒格式化
- 78-C语言-完数的判断,以及输出其因子
- uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -个人中心页面搭建实现
- 外显和呼叫系统的关系
- 关于 Appium 各种版本的安装,都在这里
- mysql,dataGrip更改架构/schema does not support rename
- 【算法练习Day50】下一个更大元素II&&接雨水
- Java将富文本转化为word
- 算法复习笔记
- CrystalDiskInfo v9.2.2