浅谈测试自动化selenium之POM模式
基于本人也是一个初学者,在运用POM模式的时候记录一下自己的学习笔记。
如果你是大神,那么可以略过,如果你是初学者,希望对你有帮助。
本文阐述了以下几个问题:
????????什么叫POM模式
????????为什么要用POM模式
????????POM模式的思想
? ? ? ? POM模式的运用
在刚学习selenium自动化测试的时候,一般都是:
????????1.打开网页
????????2.定位元素,进行操作
????????3.关闭网页
以百度为例:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get("https://www.baidu.com/")
text_input=driver.find_element(By.XPATH,'//*[@id="kw"]')
text_input.send_keys("京东")
submit_button=driver.find_element(By.XPATH,'//*[@id="su"]')
submit_button.click()
time.sleep(8)
driver.quit()以上是一个简单的访问百度网页,搜索京东的例子。
因为只有一个页面,所以相对来说使用这种模式的弊端没有显露出来。
当被测对象有很多页面的时候,问题开始显现出来了。
假设在5个测试用例中都使用到了元素X,那么,当前端对元素X做了更新处理的时候。我们就需要找到这5个引用到了元素X的地方,对元素X进行更改。
所以,引入POM模式。
什么叫POM模式
POM模式:Page Object Model,即页面对象模型。
通俗讲,就是把页面的元素、操作、数据等分离开来,再通过用例调用。
本质上就是一种封装的思想,让代码逻辑更清晰,容易维护。这样的话,就能减少重复大量的定位元素和维护的时间成本。
为什么要用POM模式
通过这种模式,我们把页面的元素定位和业务操作分离开。
????????1.多个测试人员可同时编写和维护脚本
????????2.代码逻辑更清晰,更易维护
POM模式的思想
将页面分为3层:操作层、页面层、用例层
操作层:就是对一些元素的公共操作。比如:点击,输入,拖拽。
页面层:页面元素的定位,及属于该页面独有的操作也可封装在这里。
用例层:在页面中操作元素。也就是测试用例。
关系如下图,网络找的,侵删。
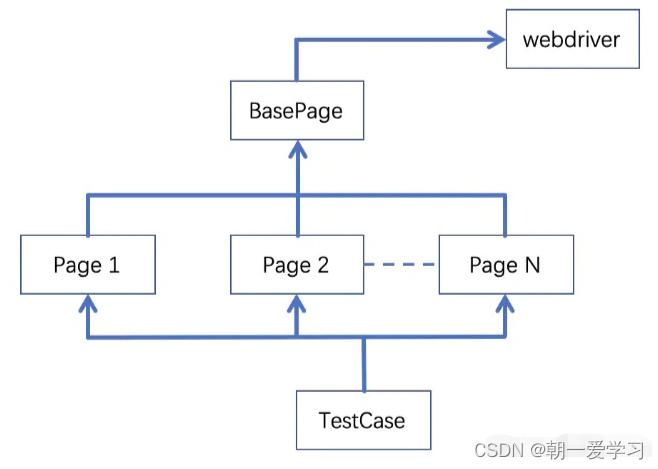
操作层:BasePage,点击,输入,拖拽等公共的操作。
页面层:Page,继承BasePage,实现元素定位以及一些该页面独有的功能。
用例层:TestCase,测试用例。
POM模式的运用
根据POM模式的思想:
1.首先封装公共操作到base_page
2.然后定位页面元素至page
3.最后在test_case写测试用例
base_page.py:
定义了打开网页,定位元素,点击,输入,关闭网页的方法。
可被其他页面继承。
from selenium import webdriver
import logging
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class BasePage:
def __init__(self):
self.driver=webdriver.Chrome()
def open_url(self,url):
self.driver.get(url)
self.driver.maximize_window()
def find_element(self,locator,timeout=10):
try:
element=WebDriverWait(self.driver,timeout).until(EC.presence_of_element_located(locator))
return element
except:
logging("{locator}元素没有找到")
raise
def click(self,locator):
element=self.driver.find_element(*locator)
element.click()
def send_keys(self,locator,text):
element=self.driver.find_element(*locator)
element.send_keys(text)
def quit(self):
self.driver.quit()
index_page.py:
具体的页面元素定位,以及一些该页面元素独有的方法。
继承了BasePage。
from selenium.webdriver.common.by import By
from base_page import BasePage
class IndexPage(BasePage):
text_input = (By.XPATH, '//*[@id="kw"]')
submit_button = (By.XPATH, '//*[@id="su"]')
def input_text(self,text):
self.send_keys(self.text_input,text)
def submit(self):
self.click(self.submit_button)
testcase.py:
前置操作,初始化driver,打开网页。
执行测试用例。
后置操作,关闭浏览器。
import time
import unittest
from index_page import IndexPage
class TestCaseSearch(unittest.TestCase):
def setUp(self)->None:
self.driver=IndexPage()
self.driver.open_url("https://www.baidu.com/")
def tearDown(self)->None:
self.driver.quit()
def testSearch(self):
self.driver.input_text(text="京东")
self.driver.submit()
time.sleep(8)
if __name__ =="__main__":
unittest.main()本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何使用ActiveMQ
- 电脑pdf如何转换成word格式?用它实现pdf文件一键转换
- Qlib从入门到精通
- 基于python的leetcode算法介绍之递归
- 某工业控制安全厂商安全研究员面试与笔试
- 【前端】NodeJS 部署到 Window 并以 EXE 文件运行
- 自动化生产线-采用工业机器人比人工有哪些优势?
- 计算机服务器中了lockbit3.0勒索病毒如何处理,勒索病毒解密数据恢复
- 【算法系列 | 9】深入解析查找算法之—哈希表查找
- ECharts配置个性化图表:圆环、立体柱状图