scrapy框架使用
1.Scrapy 数据的提取
response.xpath('//span/text').get()
response.css('span::text').get()
2.选择器使用

2.Scrapy 保存数据到文件
-
用Python原生方式保存
with open("movie.txt", 'wb') as f:
for n, c in zip(movie_name, movie_core):
str = n+":"+c+"\n"
f.write(str.encode())
-
使用Scrapy内置方式
scrapy 内置主要有四种:JSON,JSON lines,CSV,XML
最常用的导出结果格为JSON,命令如下:
scrapy crawl dmoz -o douban.json -t json-
-o 后面导出文件名
-
-t 后面导出的类型,可以省略,但要保存的文件名后缀,写清楚类型
-
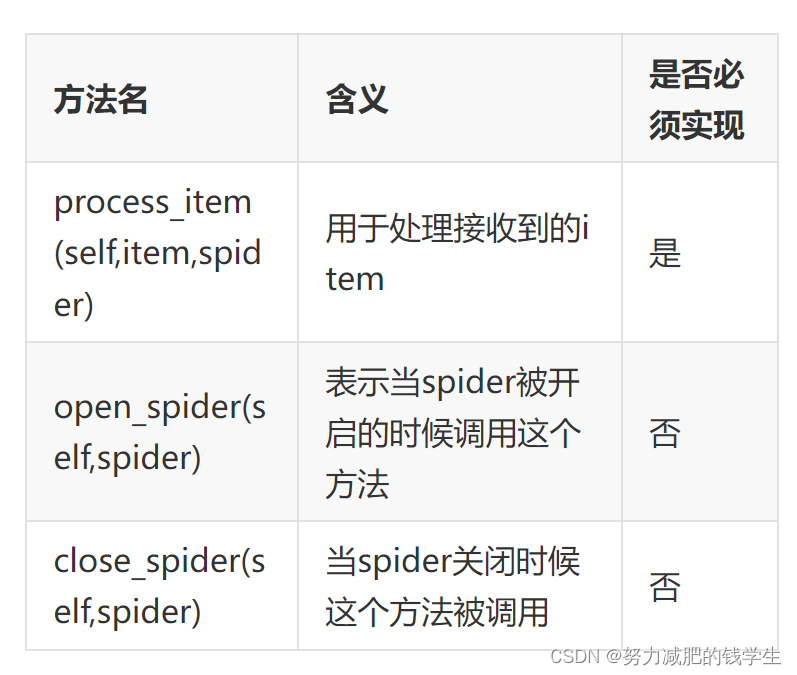
3.Item Pipeline的使用
from itemadapter import ItemAdapter
import re
class Project06Pipeline:
def process_item(self, item, spider):
return item
from scrapy.pipelines.images import ImagesPipeline
from scrapy.http.request import Request
class MyImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
return Request(item['image_url'])
def file_path(self, request, response=None, info=None, *, item=None):
name=item['name']
return f'{name}.jpg'4.Scrapy 使用ImagePipeline 保存图片
使用图片管道
scrapy.pipelines.images.ImagesPipeline
使用 ImagesPipeline ,典型的工作流程如下所示:
- 在一个爬虫中,把图片的URL放入?
image_urls?组内(image_urls是个列表) - URL从爬虫内返回,进入图片管道
- 当图片对象进入 ImagesPipeline,image_urls 组内的URLs将被Scrapy的调度器和下载器安排下载
- settings.py文件中配置保存图片路径参数
IMAGES_STORE - 开启管道
5.Scrapy 自定义ImagePipeline
import re
class Scrapy05Pipeline:
def process_item(self, item, spider):
return item
from scrapy.pipelines.images import ImagesPipeline
from scrapy.http.request import Request
class MyImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
return Request(item['image_url'])
def file_path(self, request, response=None, info=None, *, item=None):
# 处理文件名中的特殊字符
# name = item.get('name').strip().replace('\r\n\t\t','').replace('(','').replace(')','').replace('/','_')
name = re.sub('/','_',re.sub('[\s()]','',item.get('name')))
return f'{name}.jpg'
6.Scrapy 中settings配置 的使用
官网-参考配置
设置 — Scrapy 2.5.0 文档 (osgeo.cn)设置 — Scrapy 2.5.0 文档
配置文档
-
BOT_NAME
默认: 'scrapybot'
Scrapy项目实现的bot的名字。用来构造默认 User-Agent,同时也用来log。?当你使用 startproject 命令创建项目时其也被自动赋值。
-
CONCURRENT_ITEMS
默认: 100
Item Processor(即 Item Pipeline) 同时处理(每个response的)item的最大值
-
CONCURRENT_REQUESTS
默认: 16
Scrapy downloader 并发请求(concurrent requests)的最大值。
-
CONCURRENT_REQUESTS_PER_DOMAIN
默认: 8
对单个网站进行并发请求的最大值。
-
CONCURRENT_REQUESTS_PER_IP
默认: 0
对单个IP进行并发请求的最大值。如果非0,则忽略 CONCURRENT_REQUESTS_PER_DOMAIN 设定, 使用该设定。 也就是说,并发限制将针对IP,而不是网站。
该设定也影响 DOWNLOAD_DELAY: 如果 CONCURRENT_REQUESTS_PER_IP 非0,下载延迟应用在IP而不是网站上。
-
FEED_EXPORT_ENCODING ='utf-8'
设置导出时文件的编码
-
DOWNLOADER_MIDDLEWARES
默认:: {}
保存项目中启用的下载中间件及其顺序的字典
-
DOWNLOAD_DELAY
默认: 0
下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度, 减轻服务器压力。同时也支持小数
-
DOWNLOAD_TIMEOUT
默认: 180
下载器超时时间(单位: 秒)
-
ITEM_PIPELINES
默认: {}
保存项目中启用的pipeline及其顺序的字典。该字典默认为空,值(value)任意。 不过值(value)习惯设定在0-1000范围内
-
DEPTH_LIMIT
默认:
0类:
scrapy.spidermiddlewares.depth.DepthMiddleware允许为任何站点爬行的最大深度。如果为零,则不会施加任何限制。
-
LOG_ENABLED
默认: True
是否启用logging
-
LOG_ENCODING
默认: 'utf-8'
logging使用的编码。
-
LOG_FILE
默认: None
logging输出的文件名。如果为None,则使用标准错误输出(standard error)。
-
LOG_FORMAT
默认: '%(asctime)s [%(name)s] %(levelname)s: %(message)s'
日志的数据格式
-
LOG_DATEFORMAT
默认: '%Y-%m-%d %H:%M:%S'
日志的日期格式
-
LOG_LEVEL
默认: 'DEBUG'
log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG
-
LOG_STDOUT
默认: False
如果为 True ,进程所有的标准输出(及错误)将会被重定向到log中
-
ROBOTSTXT_OBEY
默认: True
是否遵循robots协议
-
USER_AGENT
默认: "Scrapy/VERSION (+http://scrapy.org)"
爬取的默认User-Agent,除非被覆盖
7.Scrapy 保存数据案例-小说保存
1.
scrapy startproject myfrist(project_name)
2.
scrapy genspider 爬虫名 爬虫的地址
3.spider
import scrapy
class XiaoshuoSpiderSpider(scrapy.Spider):
name = 'xiaoshuo_spider'
allowed_domains = ['zy200.com']
url = 'http://www.zy200.com/5/5943/'
start_urls = [url + '11667352.html']
def parse(self, response):
info = response.xpath("/html/body/div[@id='content']/text()").extract()
href = response.xpath("//div[@class='zfootbar']/a[3]/@href").extract_first()
yield {'content':info}
if href != 'index.html':
new_url = self.url + href
yield scrapy.Request(new_url, callback=self.parse)
4.pipline
class XiaoshuoPipeline(object):
def __init__(self):
self.filename = open("dp1.txt", "w", encoding="utf-8")
def process_item(self, item, spider):
content = item["title"] + item["content"] + '\n'
self.filename.write(content)
self.filename.flush()
return item
def close_spider(self, spider):
self.filename.close()
8.Scrapy 中 Request 的使用
爬虫中请求与响应是最常见的操作,Request对象在爬虫程序中生成并传递到下载器中,后者执行请求并返回一个Response对象

class scrapy.http.Request(url[, callback, method='GET', headers, body, cookies, meta, encoding='utf-8', priority=0, dont_filter=False, errback])
一个Request对象表示一个HTTP请求,它通常是在爬虫生成,并由下载执行,从而生成Response
-
参数
-
url(string) - 此请求的网址
-
callback(callable) - 将使用此请求的响应(一旦下载)作为其第一个参数调用的函数。有关更多信息,请参阅下面的将附加数据传递给回调函数。如果请求没有指定回调,parse()将使用spider的 方法。请注意,如果在处理期间引发异常,则会调用errback。
-
method(string) - 此请求的HTTP方法。默认为'GET'。可设置为"GET", "POST", "PUT"等,且保证字符串大写
-
meta(dict) - 属性的初始值Request.meta,在不同的请求之间传递数据使用
-
body(str或unicode) - 请求体。如果unicode传递了,那么它被编码为 str使用传递的编码(默认为utf-8)。如果 body没有给出,则存储一个空字符串。不管这个参数的类型,存储的最终值将是一个str(不会是unicode或None)。
-
headers(dict) - 这个请求的头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。如果 None作为值传递,则不会发送HTTP头.一般不需要
-
encoding: 使用默认的 'utf-8' 就行
-
dont_filter:是否过滤重复的URL地址,默认为?
False过滤 -
cookie(dict或list) - 请求cookie。这些可以以两种形式发送。
- 使用dict或者列表
-
9.Scrapy中下载中间件
下载中间件是Scrapy请求/响应处理的钩子框架。这是一个轻、低层次的应用。
通过可下载中间件,可以处理请求之前和请求之后的数据。
每个中间件组件都是一个Python类,它定义了一个或多个以下方法,我们可能需要使用方法如下:
-
process_request()
-
process_response()
process_request(self, request, spider)
当每个request通过下载中间件时,该方法被调用
必须返回以下其中之一
-
返回 None
- Scrapy 将继续处理该 request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该 request 被执行(其 response 被下载)
-
返回一个 Response 对象
- Scrapy 将不会调用 任何 其他的 process_request()或 process_exception()方法,或相应地下载函数; 其将返回该 response。已安装的中间件的 process_response()方法则会在每个 response 返回时被调用
-
返回一个 Request 对象
- Scrapy 则停止调用 process_request 方法并重新调度返回的 request。当新返回的 request 被执行后, 相应地中间件链将会根据下载的 response 被调用
-
raise IgnoreRequest
- 如果抛出 一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则 request 的 errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)
参数:
- request (Request 对象) – 处理的request
- spider (Spider 对象) – 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
process_response()应该是:返回一个?Response对象,则返回一个?Request?对象或引发?IgnoreRequest例外情况。
-
如果它返回?
Response(可能是相同的给定响应,也可能是全新的响应),该响应将继续使用?process_response()?链中的下一个中间件 -
如果它返回一个?
Request?对象时,中间件链将暂停,返回的请求将重新计划为将来下载。这与从返回请求的行为相同?process_request() -
如果它引发了?
IgnoreRequest异常,请求的errback函数 (Request.errback?)。如果没有代码处理引发的异常,则忽略该异常,不记录该异常(与其他异常不同)。 -
参数
- request?(is a?
Request?object) -- 发起响应的请求 - response?(
Responseobject) -- 正在处理的响应 - spider?(
Spider?object) -- 此响应所针对的蜘蛛
- request?(is a?
10.Scrapy 中 Downloader 设置代理

class MyProxyDownloaderMiddleware:
def process_request(self, request, spider):
# request.meta['proxy'] ='http://ip:port'
# request.meta['proxy'] ='http://name:pwd@ip:port'
request.meta['proxy'] ='http://139.224.211.212:8080'
11.下载中间件实战-Scrapy与Selenium结合

spider
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super(BaiduSpider, cls).from_crawler(crawler, *args, **kwargs)
spider.chrome = webdriver.Chrome(executable_path='../tools/chromedriver.exe')
crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed)
# connect里的参数
# 1. 处罚事件后用哪个函数处理
# 2. 捕捉哪个事件
return spider
def spider_closed(self, spider):
spider.chrome.close()
middleware
def process_request(self, request, spider):
spider.chrome.get(request.url)
html = spider.chrome.page_source
return HtmlResponse(url = request.url,body = html,request = request,encoding='utf-8')
middleware2
# 用来创建selenium中间件
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.service import Service
from scrapy.http import HtmlResponse
class SeleniumMiddleware:
# def __init__(self):
# # 创建一个Chrome浏览器驱动
# s = Service(executable_path='scrapy07/chromedriver.exe')
# # 创建浏览器
# self.chrome = Chrome(service=s)
def process_request(self, request, spider):
# 发送请求
spider.chrome.get(request.url)
# 将数据返回到Spider中
return HtmlResponse(
url=request.url,
body=spider.chrome.page_source,
encoding='utf-8',
request=request
)
selenium
import scrapy
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.service import Service
from scrapy import signals
class SeleniumSpider(scrapy.Spider):
name = "selenium"
allowed_domains =['httpbin.org']
start_urls=['http://httpbin.org/get']
# def start_requests(self):
# #创建一个chrome浏览器驱动
# s=Service(executable_path='D:/PYthon study/auto/save-data/project08/chromedriver.exe')
# #建立浏览器
# chrome = Chrome(service=s)
# #发送请求
# chrome.get('http://httpbin.org/get')
# #获取响应
# print(chrome.page_source)
# #关闭浏览器
# chrome.quit()
# def parse(self, response):
# print(response.text)
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = super(SeleniumSpider, cls).from_crawler(crawler, *args, **kwargs)
#创建一个chrome浏览器驱动
s=Service(executable_path='project08\chromedriver.exe')
#建立浏览器
spider.chrome = Chrome(service=s)
crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed)
return spider
def spider_closed(self, spider):
#关闭浏览器
spider.chrome.quit()
def parse(self, response):
print(response.text)本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- juniper EX系列交换机COS配置
- Cell子刊|四医大研究团队发现线粒体多肽缓解非酒精性脂肪肝的直接互作靶点
- return、break、continue用法和区别(C/C++)
- QT第一天
- WeNet语音识别调用通义千问
- Transformer and Pretrain Language Models3-4
- python爬虫,验证码识别,携带cookies请求
- 使用强化学习进行神经网络结构搜索的代码以及修改
- 在排序数组中查找元素的第一个和最后一个位置
- 学习Vue的插槽总结