Multimodal Multitask Learning with a Unified Transformer
发布时间:2024年01月18日

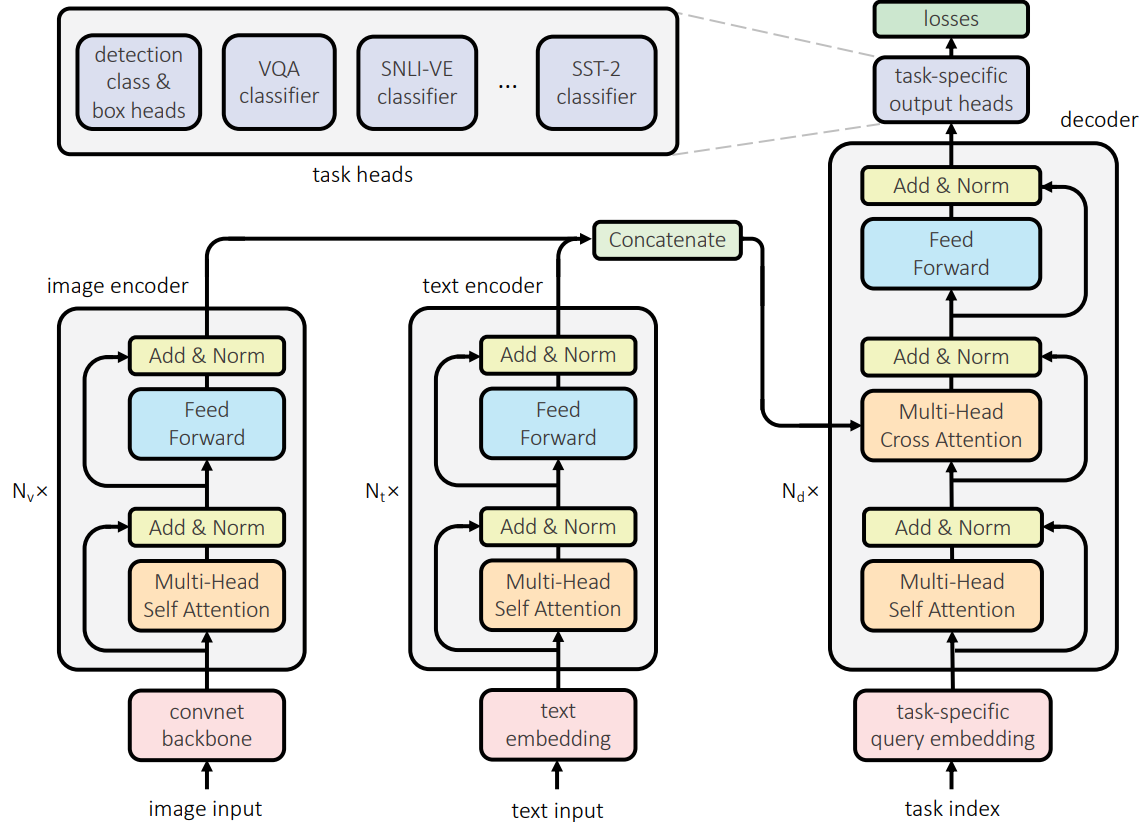
SNLI-VE dataset,natural language understanding tasks:MNLI,QNLI,QQP,SST-2

截止到发文时间的issue数,多吓人呐,不建议复现
文章来源:https://blog.csdn.net/qq_46221910/article/details/135682183
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 十三、Ansible Role 详解
- springboot通过servlet拦截器对请求防重处理
- 提高工作效率:在文件夹重命名时添加上级目录名称的技巧
- 神经辐射场(NeRF)概述
- 排障启示录-无线漫游效果差
- 力扣5. 最长回文子串
- 如何在小米路由器4A千兆版刷入OpenWRT并通过内网穿透工具实现公网远程访问
- crontab命令格式详细说明与常用各种写法总结
- 身份证阅读器Qt动态调用方法donsee32.dll实现读取身份证信息、社保卡信息、IC卡、银行卡等信息
- VUE--组件通信(父子)