C++入门(详细解读,建议收藏)
🚩C++是什么?🚩?🌟?🥦💬
????????C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机界提出了OOP(object oriented programming:面向对象)思想,支持面向对象的程序设计语言应运而生。
?????????1982年,Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,发明了一种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。因此:C++是基于C语言而产的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。
?C++的发展史
| 阶段 | 内容 |
|
C with
classes
|
类及派生类、公有和私有成员、类的构造和析构、友元、内联函数、赋值运算符、重载等
|
|
C++1.0
|
添加虚函数概念,函数和运算符重载,引用、常量等
|
|
C++2.0
|
更加完善支持面向对象,新增保护成员、多重继承、对象的初始化、抽象类、静态成员以及const
成员函数
|
|
C++3.0
|
进一步完善,引入模板,解决多重继承产生的二义性问题和相应构造和析构的处理
|
|
C++98
|
C++
标准第一个版本
,绝大多数编译器都支持,得到了国际标准化组织
(ISO)
和美国标准化协会认可,以模板方式重写
C++
标准库,引入了
STL(
标准模板库
)
|
|
C++03
|
C++
标准第二个版本,语言特性无大改变,主要:修订错误、减少多异性
|
|
C++05
|
C++
标准委员会发布了一份计数报告
(Technical Report
,
TR1)
,正式更名C++0x,即:计划在本世纪第一个
10
年的某个时间发布
|
|
C++11
|
增加了许多特性,使得
C++
更像一种新语言,比如:正则表达式、基于范围
for
循环、auto
关键字、新容器、列表初始化、标准线程库等
|
|
C++14
|
对
C++11
的扩展,主要是修复
C++11
中漏洞以及改进,比如:泛型的
lambda
表达式,auto
的返回值类型推导,二进制字面常量等
|
|
C++17
|
在
C++11
上做了一些小幅改进,增加了
19
个新特性,比如:
static_assert()
的文本信息可选,Fold
表达式用于可变的模板,
if
和
switch
语句中的初始化器等
|
|
C++20
|
自
C++11
以来最大的发行版
,引入了许多新的特性,比如:
模块
(Modules)
、协
程
(Coroutines)
、范围
(Ranges)
、概
(Constraints)
等重大特性,还有对已有特性的更新:比如Lambda
支持模板、范围
for
支持初始化等
|
|
C++23
|
制定
ing
|
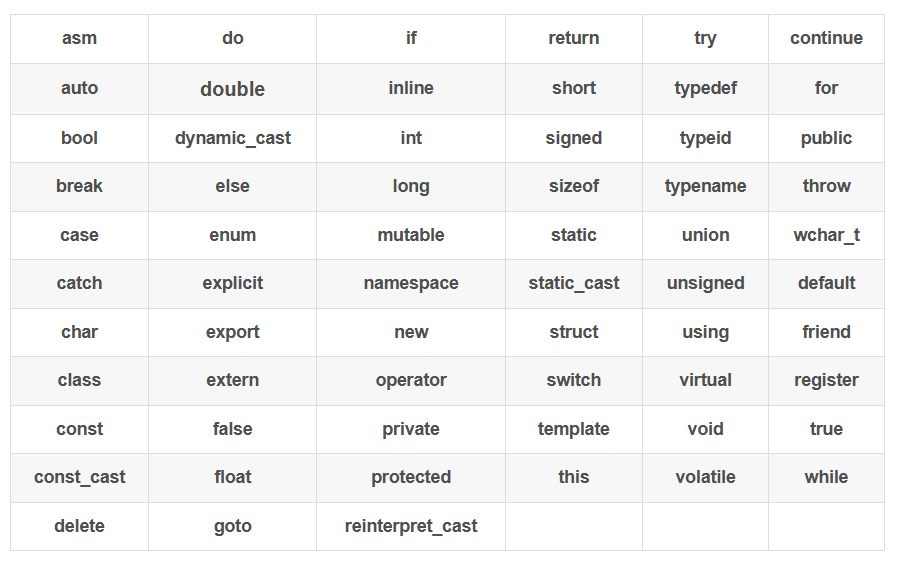
?C++关键字
C++总计63个关键字,C语言32个关键字,大家只要大概了解一下就好,后续学习过程会对这些关键字深入学习
🌟命名空间?
💬为什么会有命名空间
? ? ? ? 在编写程序时,我们定义了一个名为abc()的函数,在另一个可用库中也存在一个abc()函数,这时编译器就无法判断我们调用的是哪一个函数,因此引入了命名空间这个概念,专门用于解决上面的问题,他可以做为附加信息来区分不同库中相同名称的函数、类、变量等.
? ? ? ? 比如一个目录可以存在多个文件夹,每个文件夹中不能有相同的文件名,但不同的文件夹中的文件可以重名
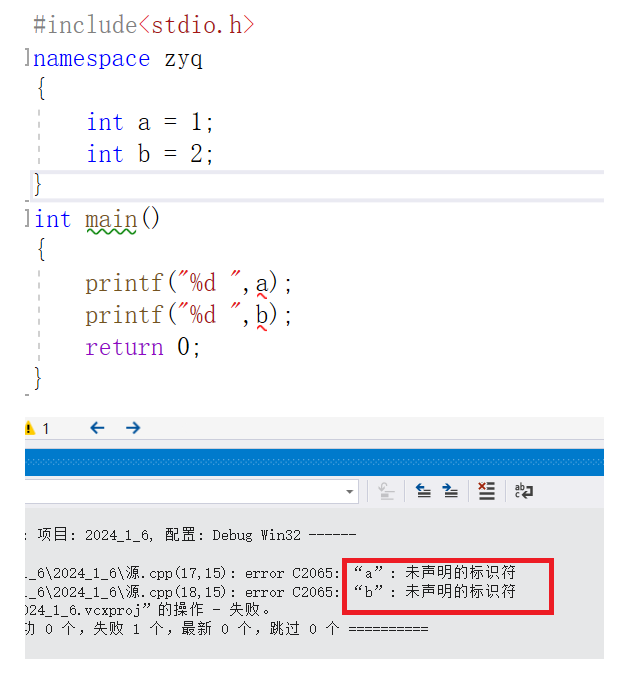
例如: 当全局变量和库里的函数名相同时
#include<stdio.h> #include<stdlib.h> int rand = 1; int main() { printf("%d ", rand); return 0; }运行会显示编译报错: error C2365: “rand”: 重定义;以前的定义是“函数”
C语言没办法解决这样的命名冲突,所以提出了namespace来解决这一问题
💬命名空间定义
定义方法:
????????定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
1.正常的命名空间定义
// 命名空间中可以定义变量/函数/类型
namespace zyq
{
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}2.命名空间还可以嵌套定义
namespace zyq1
{
int a;
int b;
int Add(int left, int right)
{
? ? return left + right;
}
namespace zyq2
{
? ? int c;
? ? int d;
? ? int Sub(int left, int right)
? ? {
? ? ? ? return left - right;
? ? }
}
}3.同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
例如,在test.h中定义了一个namespace zyq,在test.c中也定义了一个namespace zyq,即使两个命名空间内的内容不同,只要名字相同,编译器会把两个命名空间合并为一个
使用方法:
在命名空间中定义的成员,就相当于他们被一堵围墙围起来了,没有门是无法使用他们的
可以看出不能直接使用命名空间中的成员,接下来介绍三种可以使用命名空间成员的方法:
1.加命名空间名称及作用域限定符
#include<stdio.h>
namespace zyq
{
int a = 1;
int b = 2;
}
int main()
{
//'::'符号位作用域限定符,通过"命名空间名::成员"就可使用空间中的成员
printf("%d ",zyq::a);
printf("%d ",zyq::b);
return 0;
}2.使用using将命名空间中某个成员引入
#include<stdio.h>
namespace zyq
{
int a = 1;
int b = 2;
}
using zyq::a;
using zyq::b;
int main()
{
printf("%d ",a);
printf("%d ",b);
return 0;
}3.使用using namespace 命名空间名称 引入
#include<stdio.h>
namespace zyq
{
int a = 1;
int b = 2;
}
using namespace zyq;
int main()
{
printf("%d ",a);
printf("%d ",b);
return 0;
}这种方法有个缺点,会把命名空间中的所有成员暴露出来,当存在多个命名空间时,可能会造成命名污染
🥦C++输入&输出
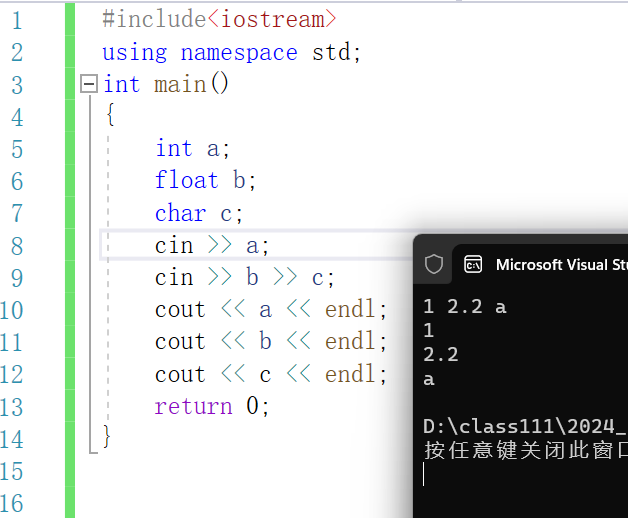
打印helloworld一定是程序员的第一个程序,那么C++是如何实现的呢?
#include<iostream>
// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
using namespace std;
int main()
{
cout << "hello world!\n" << endl;
return 0;
}注意:
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件以及按命名空间使用方法使用std。
- 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。
C++的输入输出可以自动识别变量类型。 - <<是流插入运算符,>>是流提取运算符。
- endl是特殊的C++符号,表示换行输出
- cin和scanf输入时类似,遇到空格、换行、tab等都会停止读入
?缺省参数
?缺省参数的概念
????????缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
例如:
#include<iostream>
using namespace std;
void func(int a = 1)
{
cout << a << endl;
}
int main()
{
//没有传入参数,a默认为1
func();
//a的值为6
func(6);
return 0;
}??缺省参数分类
全缺省参数
void Func(int a = 10, int b = 20, int c = 30)
{
? ? cout<<"a = "<<a<<endl;
? ? cout<<"b = "<<b<<endl;
? ? cout<<"c = "<<c<<endl;
}半缺省参数
void Func(int a, int b = 10, int c = 20)
{
? ? cout<<"a = "<<a<<endl;
? ? cout<<"b = "<<b<<endl;
? ? cout<<"c = "<<c<<endl;
}注意:
1.半缺省参数必须从右往左依次来给出,不能间隔着给
void Func(int a=10, int b , int c = 20)
{
? ? cout<<"a = "<<a<<endl;
? ? cout<<"b = "<<b<<endl;
? ? cout<<"c = "<<c<<endl;
}这样写,传参时就会发生问题,例如调用:Func(5),那5应该赋值给谁呢?
2.缺省参数不能在函数声明和定义中同时出现
//a.h
?void Func(int a = 10);
?
?// a.cpp
?void Func(int a = 20)
{}如果声明与定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该用那个缺省值。
3.缺省值必须是常量或者全局变量
🚩函数的重载
函数重载的概念
????????函数重载是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
ps:若仅返回值不同,则不构成重构
int Add(int a, int b)
{
cout << "int Add(int a, int b)" << endl;
return a + b;
}
double Add(double a, double b)
{
cout << "double Add(double a, double b)" << endl;
return a + b;
}
int main()
{
//调用第一个函数
Add(1,2);
//调用第二个函数
Add(1.1,2.2);
return 0;
}🥦引用
概念
????????引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。例如,每个人都有大名,也会有小名,两个名字都指的是我们,引用就相当于起别名。
?使用方法: 类型& 引用变量名(对象名) = 引用实体
#include<iostream>
using namespace std;
int main()
{
int a = 0;
//给a起一个小名b
int& b = a;
//b++就相当于a++
b++;
//打印结果为1
cout << a << endl;
return 0;
}引用的特点
- 引用在定义时必须初始化
- ?一个变量可以有多个引用(每个人可以有多个小名)
- 引用一旦引用一个实体,再不能引用其他实体(每个小名只能是一个人)
- 引用类型必须和引用实体是同种类型的
常引用
在使用引用时,不单单要看引用类型和引用实体是否为同种类型的,还要看修改权限的问题
#include<iostream>
using namespace std;
int main()
{
//a用const修饰,a就不能修改了
const int a = 0;
//b是int类型的,b可以修改,但是b修改也会影响a,这样写会报错
int& b = a;
cout << a << endl;
return 0;
}a是无法修改的,b是可修改的,而a和b都是同一个元素,所以肯定是不行的,要想引用a,b之前也得加一个const
还有一种情况可以用上述知识解释,看如下代码:
#include<iostream>
using namespace std;
int main()
{
//报错
int a = 0;
double& b = a;
//不报错
int c = 0;
double d = c;
return 0;
}int到double会发生隐式转化,而在转化时,并不是直接将int类型转化为double类型的,编译器会自己生成一个空间,借助这个空间完成转化,所以当前代码b引用的其实是这个空间,而这个空间是具有常性的,所以在double 前加一个const就不会报错了
使用场景
1.做参数
此时a和b都为实参的别名,操作ab就相当于操作实参
void swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}2.做返回值
可以理解为返回的是一个n的别名
int& Count()
{
? static int n = 0;
? n++;
? // ...
? return n;
}引用的优点
????????以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
如下代码可以证明:
#include<iostream>
#include <time.h>
using namespace std;
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
void TestReturnByRefOrValue()
{
// 以值作为函数的返回值类型
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// 以引用作为函数的返回值类型
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// 计算两个函数运算完成之后的时间
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
TestRefAndValue();
TestReturnByRefOrValue();
return 0;
}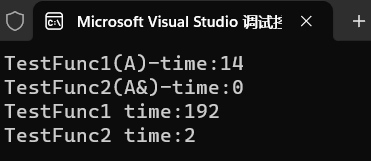
可见使用引用作为参数或者返回值时效率会比传值效率更高
引用和指针的区别
1.在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。

?2.引用在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
#include<iostream>
#include <time.h>
using namespace std;
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}可以通过比较两者汇编语言的实现证明:?

引用和指针的不同点:
- ?引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
💬内联函数
引例
两数相乘的宏:
#define mul(x,y) x*y
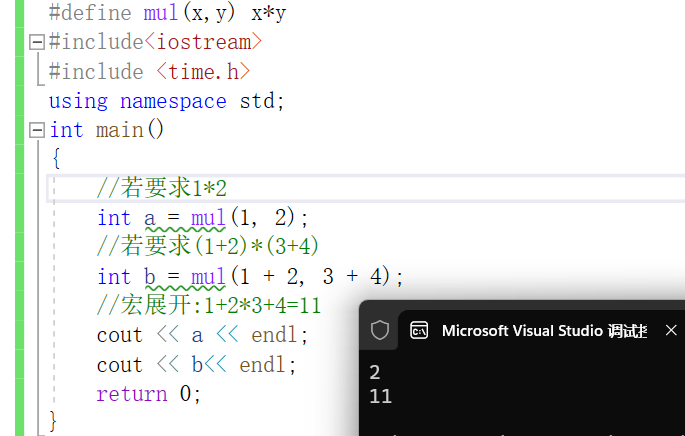
可以看出,想要实现出完美的宏功能,需要加许多括号,避免运算顺序发生改变,这样是很麻烦的,
此外宏还有许多缺点:
1.不方便调试宏。(因为预编译阶段进行了替换)
?2.导致代码可读性差,可维护性差,容易误用。
?3.没有类型安全的检查 。
而内联函数就解决了宏的所有缺点
内联函数概念
????????以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
调用普通函数时会建立栈帧

如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。

?特点
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
- 建议将函数体不是很长,并且不是递归和经常调用的函数定义为内联函数
- ?inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
// Func.h
#include <iostream>
using namespace std;
inline void f(int i);
// Func.cpp
#include "F.h"
void f(int i)
{
cout << i << endl;
}
// main.cpp
#include "Func.h"
int main()
{
f(10);
return 0;
}
// 链接错误:main.obj : error LNK2019: 无法解析的外部符号 "void __cdecl
f(int)" (?f@@YAXH@Z),该符号在函数 _main 中被引用?auto关键字(C++11)
简介
????????C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得,auto可以在变量初始化时自动识别变量是什么类型的.
????????使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
auto的使用
1.自动识别类型
#include<iostream>
#include <time.h>
using namespace std;
int main()
{
int a = 8;
auto b = a;
auto c = b;
auto d = &a;
//typeid可以识别变量的类型,这里用于检验auto的作用
cout << typeid(b).name() << endl; //结果为int
cout << typeid(c).name() << endl; //结果为int
cout << typeid(d).name() << endl; //结果为int*
return 0;
}2.使用auto声明引用类型时要加&,否则就不是起别名了,而是创建了另一个变量
#include<iostream>
#include <time.h>
using namespace std;
int main()
{
int a = 8;
//相当于创建了b变量,b的值时a的拷贝
auto b = a;
//给a起了一个别名,两者共用一个空间
auto& c = a;
return 0;
}3.当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
void TestAuto()
{
? ?auto a = 1, b = 2;
? ?auto c = 3, d = 4.0; ?// 该行代码会编译失败,因为c和d的初始化表达式类型不同}auto不能推导的场景
1. auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void func(auto a)
{}2. auto不能直接用来声明数组
void func()
{
? ?int a[] = {1,2,3};
? ?auto b[] = {4,5,6};
}🚩基于范围的for循环(C++11)
范围for的语法
在c语言中,若我们要遍历一个数组,一般会这样写:
void show()
{
int a[] = { 1,2,3,4,5,6 };
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
printf("%d ", a[i]);
}对于一个有范围的集合而言,C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围,简单来说就是:?变量:数组名
void show()
{
int a[] = { 1,2,3,4,5,6 };
for (auto i :a)
cout<<i<<endl;
}注意:与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
for循环迭代的范围必须是确定的
????????对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
注意:以下代码就有问题,因为for的范围不确定
void TestFor(int array[])
{
? ?for(auto& e : array)
? ? ? ?cout<< e <<endl;
}🌟指针空值nullptr(C++11)
在c语言中,我们一般定义一个空指针是这样写的:
int *p = NULL;NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL ??0
#else
#define NULL ??((void *)0)
#endif
#endif
?可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,比如:
void f(int)
{
cout<<"f(int)"<<endl;
}
void f(int*)
{
cout<<"f(int*)"<<endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
return 0;
}????????程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。
????????在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0。
注意:
1. 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
2. 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。3. 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
3. 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!