L40S解析,同是AD102核心为什么强于A800(A100)近2成性能
L40S解析,同是AD102核心为什么强于A800(A100)近2成性能 - 哔哩哔哩
一个朋友测试测试了4张4090和1张l40,性能。发现l40 性能训练大模型性价比超高。我就找了类似文章看看,分享一下。
一、L40S解析
一张硬件上比较平平无奇,但是性能与售价又惊为天人的显卡引起了我的注意。由于是未发售的企业级显卡因此只能用已有公开媒体数据做个推测。
L40S,一张OEM渠道拿货就近1w美刀的被动散热卡,无NVLINK,无PCIE5.0,无HBM3显存,只有一块和4090同样的AD102核心配上几乎没眼看的GDDR6(ECC)显存。显存带宽不到963G甚至落后4090 GDDR6X 1008G带宽10%以上。
就这个残血没黑科技的消费级B玩意儿,你要说强于A800(A100)我是不相信的,但是事实确实如此。

NV是怎么做到的呢?消费级核心卖1W刀抢钱,这是怎么会是呢?
![]()
也许没人了解AD102究竟有多强
4090使用的是残血阉割16384cuda内核的AD102-300核心,16MB L1 Cache,72MB L2 Cache。这已经吊打3090TI了。然而满血的AD102拥有18496CUDA内核,18MB L1,96MB L2这在缓存方面对比4090又提升接近20%。
这是为什么,没有外围堆料的的L40S几乎凭借一颗消费级核心达成性能之巅,打赢上一代AI旗舰卡。
现在的TENSORCORE对于L2的依赖已经远大于依赖传统显存带宽,预取L2数据的速度远远大于访问显存的速度。当然也要看缓存命中率的问题,就算这代N卡对于神经网络的分支预测准确度能够达到50%,那也是近乎于等同显存带宽翻倍。当然实际上的提升幅度可能不超过e^(0.5)-1这样。
之前AMPERE架构的A100 40MB L2几乎是给5120BIT的HBM显存做缓冲以减轻延迟与数据潮汐的影响(128bit对应1mb缓存再加点,正常AMPERE水平),AMPERE与AMPERE之前的显卡是个吞吐机,其实核心的计算能力已经完全足够,关键瓶颈是带宽,能不能及时喂进数据.但是在ADA架构后的显卡,并不能简单理解为吞吐机了,信息交换不太需要访问显存,通过自己自带的缓存部分高速复用数据,变成了发电机或者说吃草产奶的奶牛。DLSS3的帧生成就是明显的高速复用数据产出的典型应用。
如果单靠巨大的缓存显然不太行,有些数据能调用高速cache,有些不能,线程强制同步还要等慢的数据,这样瓶颈就到流水线上了。乱序执行,就是提高流水线每cycle效率的武器。


A100与H100的L2寄存调用区别

共享L2但分区索引
![]()
数据中心卡的P2P:
现在数据中心卡砍掉了NVLINK,但区别与游戏卡需要CPU DMA到内存再塞到另外一张卡的数据方式,提供了卡间的P2P交互。
P2P对于多卡训练还是有相当重要的意义,但是具体测试还是要多卡L40对比多卡4090,而且最好还是用同样的主板(非4代志强)至于4代志强的 DSA加速多卡和NV原生的P2P差距多大,还需要测试
L2 cache 所解决不了的问题
高BS高seq推理瓶颈:
高BS训练瓶颈:
L2 cache 本来就是片内sram就这么大,关键看命中率和速度,很显然在高BS高seq场景下脱靶惩罚更高,而且L40S是GDDR6显存不到900G的带宽,这点就更加明显,边际效应更重。

很显然BS和队列深度越大,AD102赶不上A100
对于游戏DLSS性能而言又是另外一回事了,帧生成是及时的,一帧1080分辨率的会由AI插帧生成另一帧。因此初始帧数非常重要,30帧补到60帧你可操作帧还是30就显得很不跟手,当然对于VR这样的低输入,双目高分辨率高刷新率的设备来说意义更为重大。
![]()
缓存瓶颈:GPU存储解构展望
HBM,片内缓存,可扩展存储,P2P。
HBM是未来,这是趋势,但是现在讲道理也太贵了,COWOS封装良率有一直上不去。现在看来GDDR能出到10,HBM都没法替代GDDR。
片内缓存是个好东西,也不知道英伟达出了什么黑科技,片内缓存暴涨,从每64bit分1MB缓存(3060 L2缓存也就3MB)一跃到4060给了24MB。当然最猛的L40S应该有96MB,可别忘了这是一颗消费级核心400mm^2多一点面积。
SRAM单元的面积,现在几乎不随制程推进而缩小,所以说这样提升50%CUDA单元数,且提升16倍L2的玩意是怎么来的?况且核心面积比上一代还缩了一点点。NV真的离谱。
可扩展存储:
当然是指DDR这样的硬件内存单元,随便叠可以叠到1T,但是对于神经网络性能呢有多少提升?还要分点芯片面积做低速内存的控制器。是不是有点费力不讨好??
看现在的大模型的参数量吧,A100 40G也能炼出GPT4啊。参数量现在看来并没有爆炸的趋势。反倒是神经网络没必要做太多层,参数传递太多次就不收敛了或者收敛到0也没有意义。想要参数多又想要推理运行快,这是违反缓存架构金字塔的。现在的大模型几乎都是N卡训练出的模型N卡自己微调,推理(自己甩出去的回旋镖自己接)出来的模型没人认为需要可扩展存储做辅助的当下,这个东西就是没必要的。
P2P:
多卡交互,无论是NVSwitch,NVlink,还是PCIE卡间交互都是P2P,速度快慢的不同罢了。支持P2P的PCIE卡,板子上有一个PCIE Switch芯片多卡交互走PCIE,L40/L40S是有的,4090以及其他游戏卡没有。这样的卡想多卡训练就只能把数据丢到内存里,通过CPU DMA到另一个卡里。
Transformer引擎
L40S有,那同为AD102核心的4090就没有吗?大胆猜测也是有的,只不过老黄给不给你开启使用罢了。其实AD102都是支持Transformer引擎那为什么只有L40S宣传了呢?因为L40S出的这会正好CUDA12.1的Transformer引擎软件适配工作正好做完了,4090其实也是可以跑Transformer加速的。
网页链接:It doesn't support the latest RTX 40-series card · Issue #15 · NVIDIA/TransformerEngine · GitHub

二、l40与4张4090性能
实测4块4090训练效率,远不及一块L40,更不如一块A100,无论是速度还是价格。测试llama-factory 大模型训练工具。
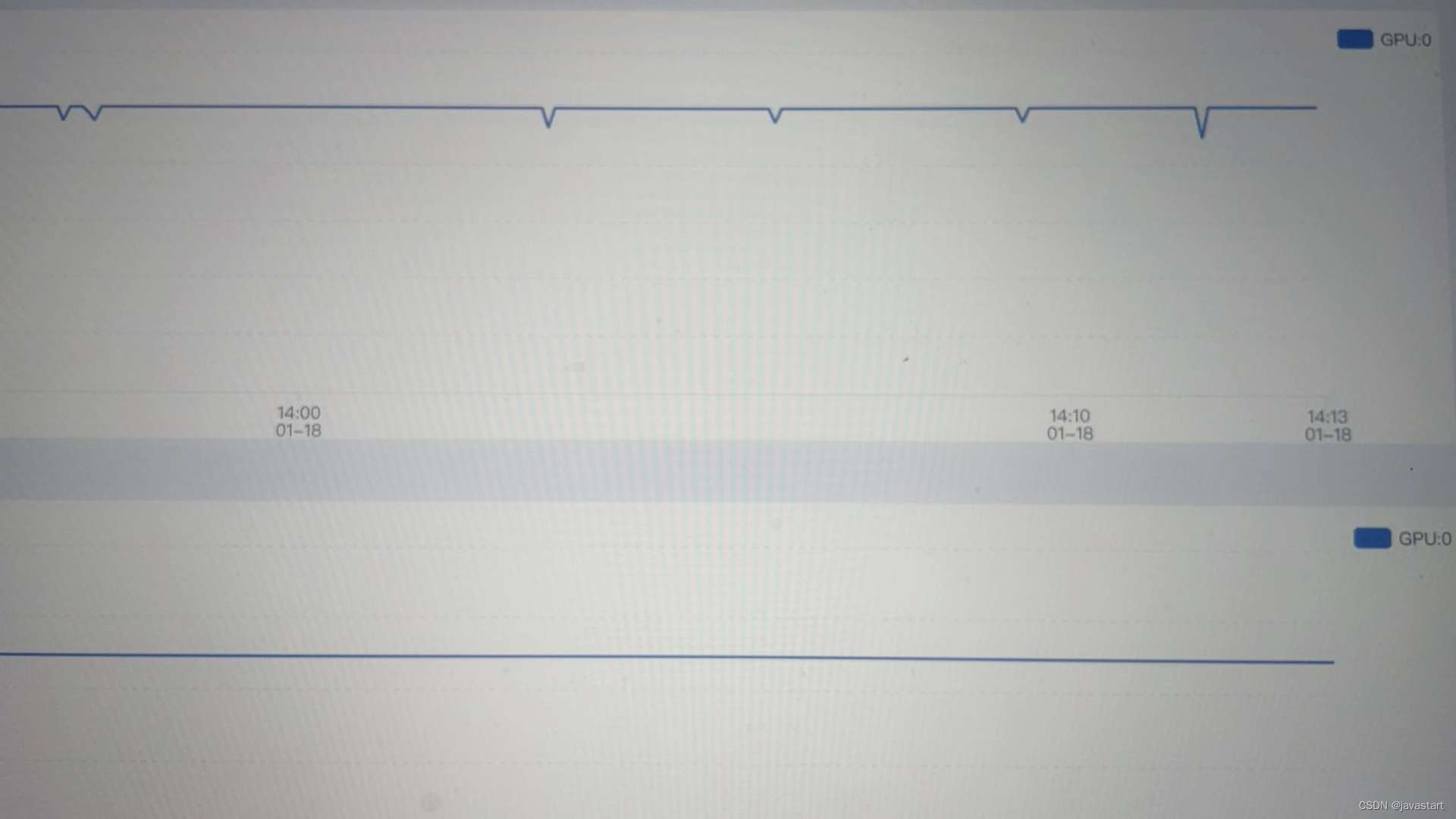
1张L40
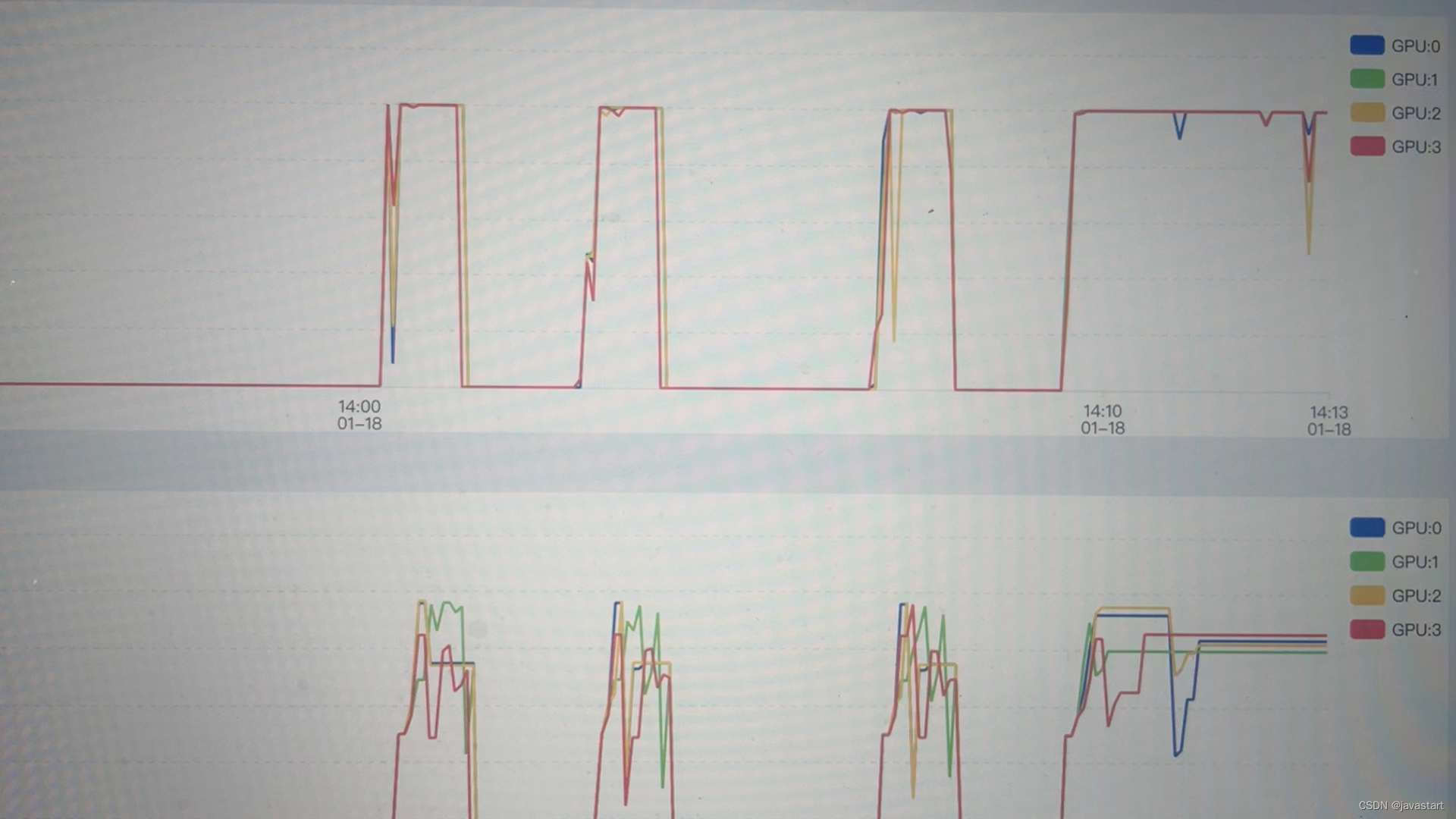
4张4090
本来是不想上传的,有可能影响卡价,但是现在连4090卡都没了,就发出来吧,哈哈哈哈哈。
全文完
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 健康手表数据洞察台
- MATLAB 点云SVD分解计算平面法向量 (41)
- 新手必看!STM32通用定时器-输入捕获!
- 半监督学习 - 联合训练(Co-Training)
- 大数据导论(4)---大数据应用
- 如何基于企业需求,又便宜又快地定制开发一套CRM客户管理系统?
- VSCode添加Python解释器并安装Python库
- springboot项目禁用dataSource数据源功能,只需修改yml文件,关闭数据库连接功能
- MySQL插入、更新和删除
- 直流负载的基础知识