第G2周:人脸图像生成(DCGAN)
发布时间:2023年12月29日
🍨 本文为[🔗365天深度学习训练营学习记录博客\n🍦 参考文章:365天深度学习训练营\n🍖 原作者:[K同学啊 | 接辅导、项目定制]\n🚀 文章来源:[K同学的学习圈子](https://www.yuque.com/mingtian-fkmxf/zxwb45)
一、设置超参数、导入数据?
import os
import random
import argparse
import numpy as np
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets as dset
import torchvision.utils as vutils
from torchvision.utils import save_image
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
manualSeed = 999 # 随机种子
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
torch.use_deterministic_algorithms(True) # Needed for reproducible results
# 超参数配置
dataroot = "D:/GAN-Data" # 数据路径
batch_size = 128 # 训练过程中的批次大小
n_epochs = 5 # 训练的总轮数
img_size = 64 # 图像的尺寸(宽度和高度)
nz = 100 # z潜在向量的大小(生成器输入的尺寸)
ngf = 64 # 生成器中的特征图大小
ndf = 64 # 判别器中的特征图大小
beta1 = 0.5 # Adam优化器的Beta1超参数
beta2 = 0.2 # Adam优化器的Beta1超参数
lr = 0.0002 # 学习率
# 创建数据集
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(img_size), # 调整图像大小
transforms.CenterCrop(img_size), # 中心裁剪图像
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5, 0.5, 0.5), # 标准化图像张量
(0.5, 0.5, 0.5)),]))
# 创建数据加载器
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size, # 批量大小
shuffle=True) # 是否打乱数据集
# 选择要在哪个设备上运行代码
device = torch.device("cuda:0" if (torch.cuda.is_available()) else "cpu")
print("使用的设备是:",device)
# 绘制一些训练图像
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:24],
padding=2,
normalize=True).cpu(),(1,2,0)))

二、定义模型、可视化?
# 自定义权重初始化函数,作用于netG和netD
def weights_init(m):
# 获取当前层的类名
classname = m.__class__.__name__
# 如果类名中包含'Conv',即当前层是卷积层
if classname.find('Conv') != -1:
# 使用正态分布初始化权重数据,均值为0,标准差为0.02
nn.init.normal_(m.weight.data, 0.0, 0.02)
# 如果类名中包含'BatchNorm',即当前层是批归一化层
elif classname.find('BatchNorm') != -1:
# 使用正态分布初始化权重数据,均值为1,标准差为0.02
nn.init.normal_(m.weight.data, 1.0, 0.02)
# 使用常数初始化偏置项数据,值为0
nn.init.constant_(m.bias.data, 0)
'''
定义生成器 Generator
'''
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
# 输入为Z,经过一个转置卷积层
nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8), # 批归一化层,用于加速收敛和稳定训练过程
nn.ReLU(True), # ReLU激活函数
# 输出尺寸:(ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 输出尺寸:(ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 输出尺寸:(ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 输出尺寸:(ngf) x 32 x 32
nn.ConvTranspose2d(ngf, 3, 4, 2, 1, bias=False),
nn.Tanh() # Tanh激活函数
# 输出尺寸:3 x 64 x 64
)
def forward(self, x):
return self.main(x)
# 创建生成器
netG = Generator().to(device)
# 使用 "weights_init" 函数对所有权重进行随机初始化,
# 平均值(mean)设置为0,标准差(stdev)设置为0.02。
netG.apply(weights_init)
# 打印生成器模型
print(netG)
'''
定义判别器 Discriminator
'''
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 定义判别器的主要结构,使用Sequential容器将多个层按顺序组合在一起
self.main = nn.Sequential(
# 输入大小为3 x 64 x 64
nn.Conv2d(3, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid())
def forward(self, x):
# 将输入通过判别器的主要结构进行前向传播
return self.main(x)
# 创建判别器对象
netD = Discriminator().to(device)
# 应用 "weights_init" 函数来随机初始化所有权重
# 使用 mean=0, stdev=0.2 的方式进行初始化
netD.apply(weights_init)
# 打印判别器模型
print(netD)
# 初始化“BCELoss”损失函数
criterion = nn.BCELoss()
# 创建用于可视化生成器进程的潜在向量批次
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
real_label = 1.
fake_label = 0.
# 为生成器(G)和判别器(D)设置Adam优化器
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, beta2))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, beta2))
img_list = [] # 用于存储生成的图像列表
G_losses = [] # 用于存储生成器的损失列表
D_losses = [] # 用于存储判别器的损失列表
iters = 0 # 迭代次数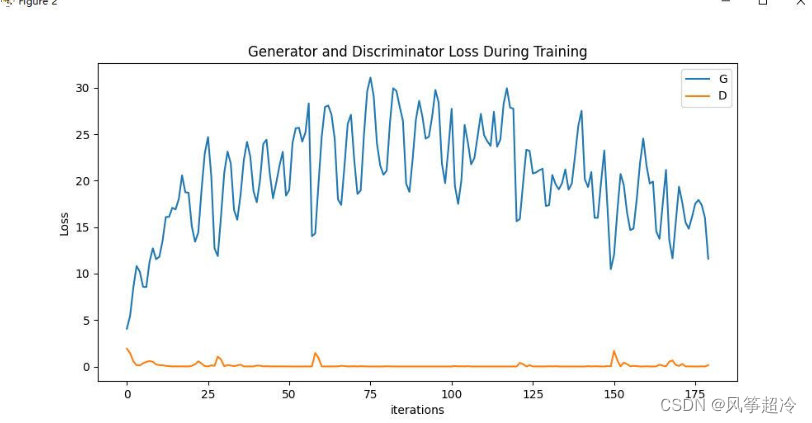
三、训练模型?
print("Starting Training Loop...") # 输出训练开始的提示信息
# 进行多个epoch的训练
for epoch in range(n_epochs):
# 对于dataloader中的每个batch
for i, data in enumerate(dataloader, 0):
############################
# (1) 更新判别器网络:最大化 log(D(x)) + log(1 - D(G(z)))
############################
## 使用真实图像样本训练
netD.zero_grad() # 清除判别器网络的梯度
# 准备真实图像的数据
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device) # 创建一个全是真实标签的张量
# 将真实图像样本输入判别器,进行前向传播
output = netD(real_cpu).view(-1)
# 计算真实图像样本的损失
errD_real = criterion(output, label)
# 通过反向传播计算判别器的梯度
errD_real.backward()
D_x = output.mean().item() # 计算判别器对真实图像样本的输出的平均值
## 使用生成图像样本训练
# 生成一批潜在向量
noise = torch.randn(b_size, nz, 1, 1, device=device)
# 使用生成器生成一批假图像样本
fake = netG(noise)
label.fill_(fake_label) # 创建一个全是假标签的张量
# 将所有生成的图像样本输入判别器,进行前向传播
output = netD(fake.detach()).view(-1)
# 计算判别器对生成图像样本的损失
errD_fake = criterion(output, label)
# 通过反向传播计算判别器的梯度
errD_fake.backward()
D_G_z1 = output.mean().item() # 计算判别器对生成图像样本的输出的平均值
# 计算判别器的总损失,包括真实图像样本和生成图像样本的损失之和
errD = errD_real + errD_fake
# 更新判别器的参数
optimizerD.step()
############################
# (2) 更新生成器网络:最大化 log(D(G(z)))
############################
netG.zero_grad() # 清除生成器网络的梯度
label.fill_(real_label) # 对于生成器成本而言,将假标签视为真实标签
# 由于刚刚更新了判别器,再次将所有生成的图像样本输入判别器,进行前向传播
output = netD(fake).view(-1)
# 根据判别器的输出计算生成器的损失
errG = criterion(output, label)
# 通过反向传播计算生成器的梯度
errG.backward()
D_G_z2 = output.mean().item() # 计算判别器对生成器输出的平均值
# 更新生成器的参数
optimizerG.step()
# 输出训练统计信息
if i % 400 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, n_epochs, i, len(dataloader), errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# 保存损失值以便后续绘图
G_losses.append(errG.item())
D_losses.append(errD.item())
# 通过保存生成器在固定噪声上的输出来检查生成器的性能
if (iters % 500 == 0) or ((epoch == n_epochs - 1) and (i == len(dataloader) - 1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
# 可视化
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 创建一个大小为8x8的图形对象
fig = plt.figure(figsize=(8, 8))
# 不显示坐标轴
plt.axis("off")
# 将图像列表img_list中的图像转置并创建一个包含每个图像的单个列表ims
ims = [[plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)] for i in img_list]
# 使用图形对象、图像列表ims以及其他参数创建一个动画对象ani
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
# 将动画以HTML形式呈现
HTML(ani.to_jshtml())
# 从数据加载器中获取一批真实图像
real_batch = next(iter(dataloader))
# 绘制真实图像
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# 绘制上一个时期生成的假图像
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()?训练结果:
[Epoch 0/50][Batch 0/36][D loss: 1.446340][G loss: 5.497820][D : 0.496465][G : 0.006384]
[Epoch 1/50][Batch 0/36][D loss: 0.198702][G loss: 32.366798][D : 0.000000][G : 0.000000]
[Epoch 2/50][Batch 0/36][D loss: 0.007939][G loss: 39.840797][D : 0.000000][G : 0.000000]
[Epoch 3/50][Batch 0/36][D loss: 0.008718][G loss: 39.420380][D : 0.000000][G : 0.000000]
[Epoch 4/50][Batch 0/36][D loss: 0.000432][G loss: 39.375351][D : 0.000000][G : 0.000000]
[Epoch 5/50][Batch 0/36][D loss: 0.000377][G loss: 39.141502][D : 0.000000][G : 0.000000]
[Epoch 6/50][Batch 0/36][D loss: 0.000066][G loss: 38.554665][D : 0.000000][G : 0.000000]
[Epoch 7/50][Batch 0/36][D loss: 0.000161][G loss: 37.076347][D : 0.000000][G : 0.000000]
[Epoch 8/50][Batch 0/36][D loss: 0.236551][G loss: 5.515038][D : 0.126019][G : 0.009809]
[Epoch 9/50][Batch 0/36][D loss: 0.774763][G loss: 4.037993][D : 0.041982][G : 0.032798]
[Epoch 10/50][Batch 0/36][D loss: 1.355027][G loss: 7.484296][D : 0.627779][G : 0.001169]
[Epoch 11/50][Batch 0/36][D loss: 1.026440][G loss: 3.390290][D : 0.480961][G : 0.066138]
[Epoch 12/50][Batch 0/36][D loss: 0.698196][G loss: 2.289851][D : 0.117281][G : 0.149754]
[Epoch 13/50][Batch 0/36][D loss: 0.407120][G loss: 3.295501][D : 0.169919][G : 0.056703]
[Epoch 14/50][Batch 0/36][D loss: 0.858621][G loss: 4.627818][D : 0.297173][G : 0.028583]
[Epoch 15/50][Batch 0/36][D loss: 1.068889][G loss: 4.085044][D : 0.314014][G : 0.029605]
[Epoch 16/50][Batch 0/36][D loss: 0.761256][G loss: 1.878336][D : 0.122635][G : 0.189217]
[Epoch 17/50][Batch 0/36][D loss: 0.946410][G loss: 5.986092][D : 0.486197][G : 0.005545]
[Epoch 18/50][Batch 0/36][D loss: 0.607918][G loss: 8.022884][D : 0.355339][G : 0.000997]
[Epoch 19/50][Batch 0/36][D loss: 0.387959][G loss: 5.217168][D : 0.148431][G : 0.012128]
[Epoch 20/50][Batch 0/36][D loss: 0.502083][G loss: 3.828265][D : 0.124887][G : 0.032919]
[Epoch 21/50][Batch 0/36][D loss: 0.341051][G loss: 5.217510][D : 0.129790][G : 0.010647]
[Epoch 22/50][Batch 0/36][D loss: 0.305131][G loss: 3.878963][D : 0.118515][G : 0.034831]
[Epoch 23/50][Batch 0/36][D loss: 0.326738][G loss: 3.092067][D : 0.048084][G : 0.073658]
[Epoch 24/50][Batch 0/36][D loss: 1.001996][G loss: 7.870810][D : 0.531534][G : 0.001848]
[Epoch 25/50][Batch 0/36][D loss: 0.646764][G loss: 5.994369][D : 0.328600][G : 0.005999]
[Epoch 26/50][Batch 0/36][D loss: 1.305306][G loss: 3.512106][D : 0.027197][G : 0.060318]
[Epoch 27/50][Batch 0/36][D loss: 0.230971][G loss: 6.018190][D : 0.160877][G : 0.005384]
[Epoch 28/50][Batch 0/36][D loss: 0.479868][G loss: 2.851458][D : 0.012263][G : 0.132684]
[Epoch 29/50][Batch 0/36][D loss: 1.190969][G loss: 6.840727][D : 0.560059][G : 0.003298]
[Epoch 30/50][Batch 0/36][D loss: 1.005036][G loss: 6.322803][D : 0.486148][G : 0.005413]
[Epoch 31/50][Batch 0/36][D loss: 0.407194][G loss: 5.357150][D : 0.025872][G : 0.012775]
[Epoch 32/50][Batch 0/36][D loss: 0.715868][G loss: 4.764071][D : 0.410440][G : 0.018443]
[Epoch 33/50][Batch 0/36][D loss: 0.525104][G loss: 4.291232][D : 0.187566][G : 0.026254]
[Epoch 34/50][Batch 0/36][D loss: 0.363458][G loss: 4.643357][D : 0.184744][G : 0.021312]
[Epoch 35/50][Batch 0/36][D loss: 0.550998][G loss: 3.245662][D : 0.190560][G : 0.078518]
[Epoch 36/50][Batch 0/36][D loss: 0.686132][G loss: 5.602957][D : 0.362706][G : 0.007369]
[Epoch 37/50][Batch 0/36][D loss: 0.556991][G loss: 3.656791][D : 0.147552][G : 0.046845]
[Epoch 38/50][Batch 0/36][D loss: 0.459933][G loss: 4.163424][D : 0.245844][G : 0.033957]
[Epoch 39/50][Batch 0/36][D loss: 0.232279][G loss: 4.535916][D : 0.114630][G : 0.016447]
[Epoch 40/50][Batch 0/36][D loss: 0.479002][G loss: 5.497972][D : 0.263936][G : 0.012047]
[Epoch 41/50][Batch 0/36][D loss: 0.720815][G loss: 3.263973][D : 0.259178][G : 0.061856]
[Epoch 42/50][Batch 0/36][D loss: 0.703234][G loss: 6.425527][D : 0.400735][G : 0.003400]
[Epoch 43/50][Batch 0/36][D loss: 0.741217][G loss: 2.052215][D : 0.048953][G : 0.209300]
[Epoch 44/50][Batch 0/36][D loss: 0.658782][G loss: 3.800625][D : 0.272119][G : 0.040041]
[Epoch 45/50][Batch 0/36][D loss: 0.402264][G loss: 5.260798][D : 0.185568][G : 0.009509]
[Epoch 46/50][Batch 0/36][D loss: 0.753039][G loss: 4.797507][D : 0.406285][G : 0.022727]
[Epoch 47/50][Batch 0/36][D loss: 0.301918][G loss: 4.467443][D : 0.173592][G : 0.022788]
[Epoch 48/50][Batch 0/36][D loss: 0.638086][G loss: 1.768839][D : 0.072733][G : 0.227529]
[Epoch 49/50][Batch 0/36][D loss: 0.576230][G loss: 2.268032][D : 0.082981][G : 0.151779] ?
?
?
文章来源:https://blog.csdn.net/qq_60245590/article/details/135297676
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Python 基础】-- 在 mac OS 中安装 多个 python 版本
- 移动图书盘点系统需求说明书
- OpenFeign远程调用
- 预调酒市场调研:2025年市场将达到565亿美元
- 数据库历史分区表分析性能调查
- 非空断言,不能将类型“number | undefined”分配给类型“number”
- 新手抖店入门教程,从开店到起店,小白一看就懂!
- 2.4k+start简单好用的个人图书管理系统搭建教程
- 书生·浦语 第三章:基于 InternLM 和 LangChain 搭建你的知识库
- python_selenium&零基础爬虫学习案例_知网文献信息