AI绘画创作,训练Lora模型绘制你心中的童年爱豆漫画
1.整合包下载
首先是去秋叶大佬那里下载一键训练包,这样我们的训练就相当简单,解压包以后先更新,后启动。
秋叶大神百度网盘包:百度网盘 请输入提取码
提取码:p8uy
目录如下,我们就可以启动训练得软件啦!
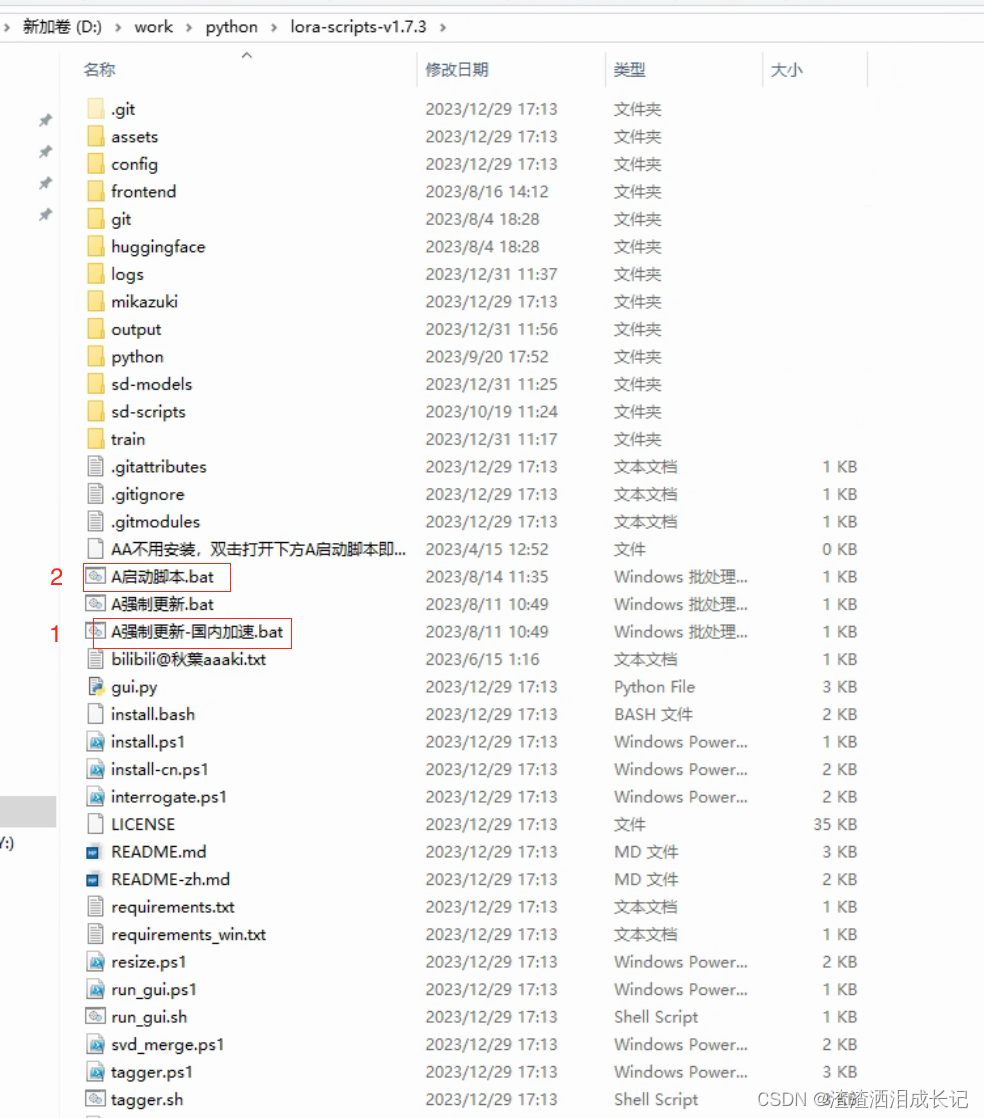
双击打开就是如下的界面?
2.训练前的准备
2.1 图片集
看我们训练的是什么就要去选择相关的训练集,人物还是画风,要是人物的画背景单调些,不要复杂,图片要高清不要糊。
我要训练的是我小时候看的动画片,百变小樱魔术卡,之前搜c站都没有所以想自己训练一个这样的人物,
选择图片也是很有讲究地如果是训练人物的化,需要尽可能以脸部特写为主(多角度、多表情),再放几张全身像(不同姿势、不同服装)。
- 不少于 15 张的高质量图片,一般可以准备 20-50 张图
- 减少重复或相似度高的图片
- 图片主体内容清晰可辨、特征明显,图片构图简单,避免其它杂乱元素
- 脸部有遮挡的不要(比如麦克风、手指、杂物等)
- 背景太复杂的不要(比如一堆字的广告板,或夜市太乱的背景)
- 分辨率太低的不要
- 光影比较特殊的不要(比如暗光,背光等)
- 不像本人特征的不要(比如大部分训练集都是长发,那么短发显脸大的不要,大笑毁形象的不要)
- 化妆太浓重的、美颜太严重的不要

?2.2 图片集处理
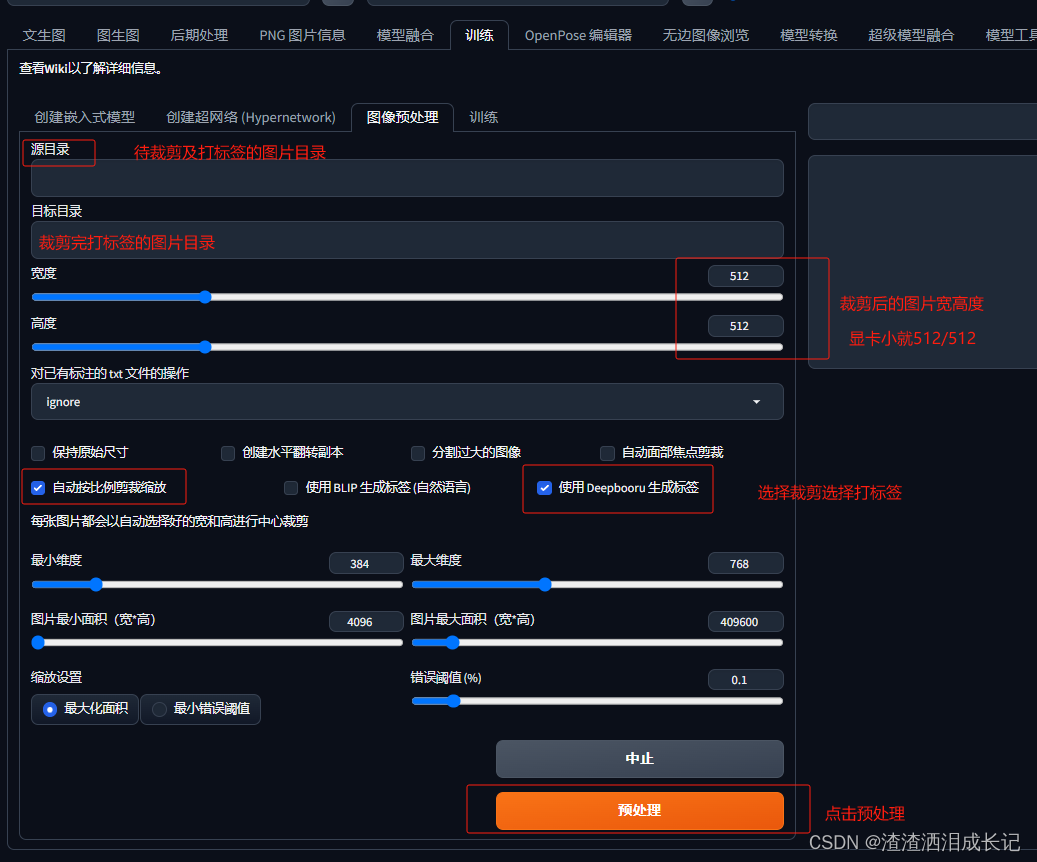
人物挑选好了,就需要进行裁剪图片到统一的尺寸以及给图片打标签(标签呢就是图片的内容好喂给ai这个是什么),我们可以选择SD进行裁剪打标签操作。
此时需要打开SD的web界面,点击训练一栏,如果显卡小就512/512的,最好将照片名字改为英文,否则训练过程失败,按如下的图片操作进行图片处理。(注:处理完图片就需要关闭掉SD,否则吃显存)
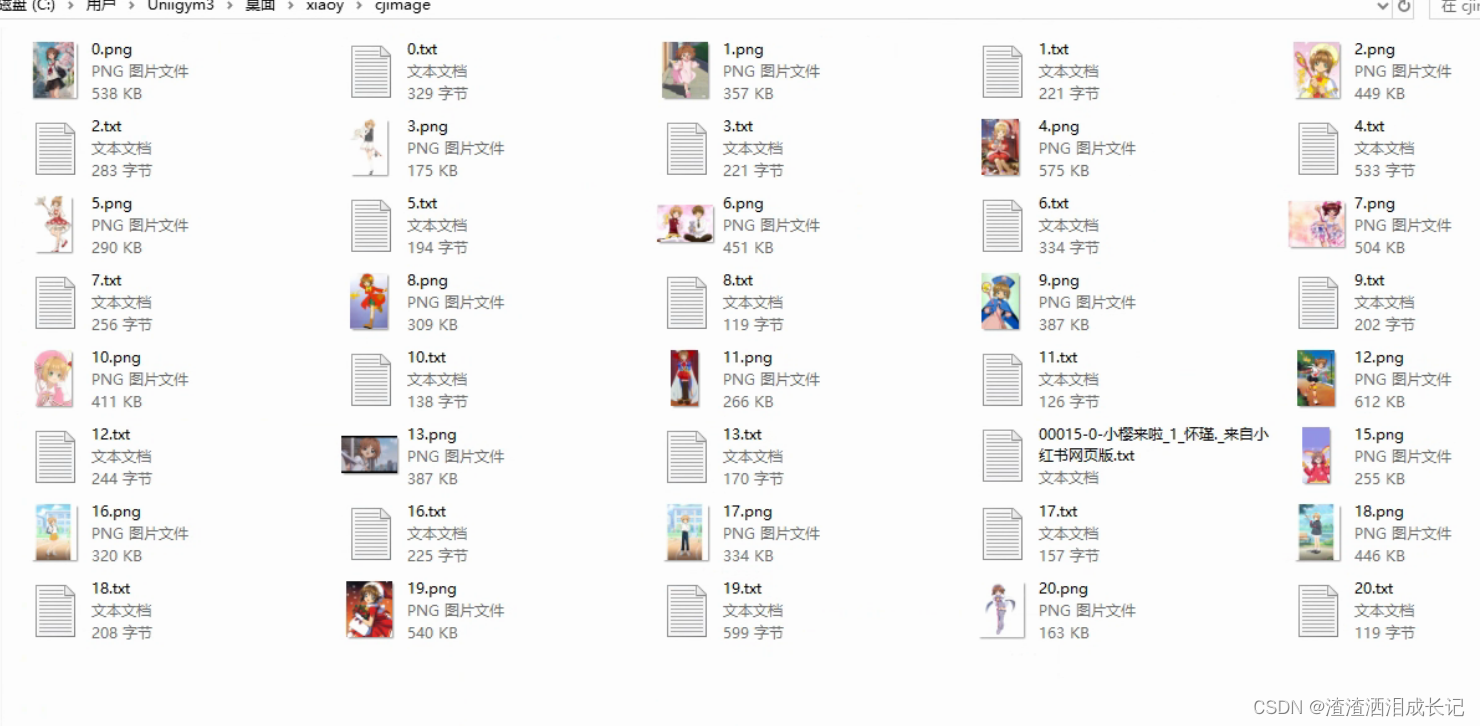
图片处理完就会有裁剪后的图片以及图片后与图片名称相同的txt文本,这个就是打的标签,大家可以进来更改对应的标签,是保留或者删除等等。
?2.3 图片复制到训练集目录
我们在.\lora-scripts-v1.7.3\train目录下创建个训练集,我的是小樱就叫sakura,这个名字叫什么都行,大家按自己的起名字,然后将处理完的图片和标签全选复制到 .\lora-scripts-v1.7.3\train\sakura目录里。
2.4 底层模型准备
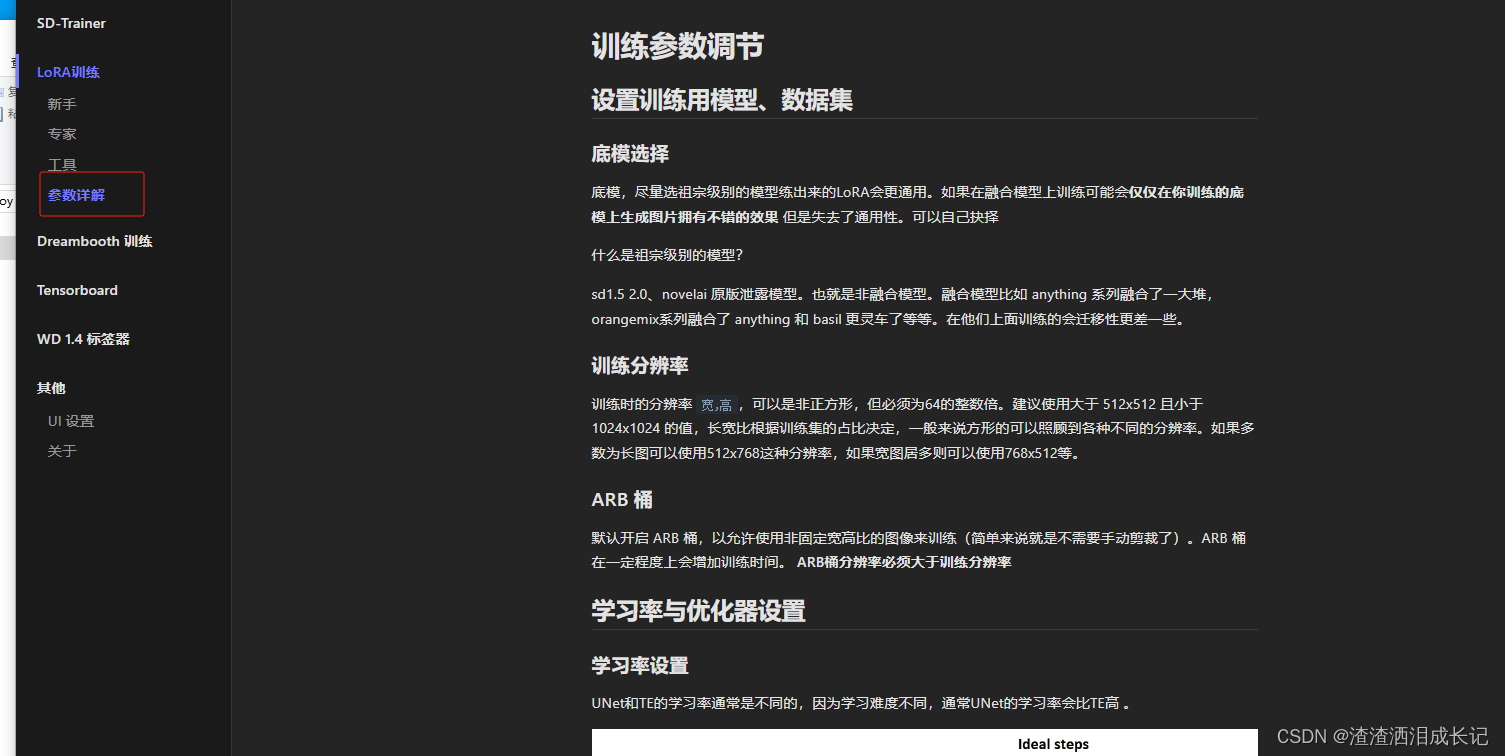
准备训练用的Stable Diffusion的底层模型,尽量选祖宗级别的模型: 例如用?SD 1.5、?SD 2.1、?NovelAI 原版泄露模型训练出来的 LoRA 会更通用,也可以用anything这种融合的模型,可能在此模型使用上比较好,切换到其他大模型就失去了通用性,具体选择看个人,我这里有anything-v5-PrtRE.safetensors模型,就用这个训练试试。
2.5 底层模型复制到训练目录
将准备好的模型复制到.\lora-scripts-v1.7.3\sd-models里。
3.?训练参数设置
?我们简单训练下Lora由于是新手以及显卡问题所以我们进入新手模式。
打开训练页面,地址:http://127.0.0.1:28000/lora/basic.html
训练参数设置:
- 底模文件路径:刚才我们说的准备下基础底层模型,这里我就用这个路径./sd-models/anything-v5-PrtRE.safetensors
- 训练集路径:裁剪过的打标签的图片数据集路径, 我的路径为./train/sakura
- 训练图片分辨率,显卡低用512/512
- 模型保存名称:最后生成的模型名称,我的就叫sakura
- 模型保存文件夹:默认即可,默认就是output
- 每 N epoch(轮)自动保存一次模型:每一次模型需要训练的轮数,这里设置为2,代表美2轮保存下模型,默认即可
- 最大训练轮数:这里选了默认10次,根据你的训练集以及显卡大小去定。选了10次最后迭代10次训练过程,每两轮保存一次,就会保存5个模型。
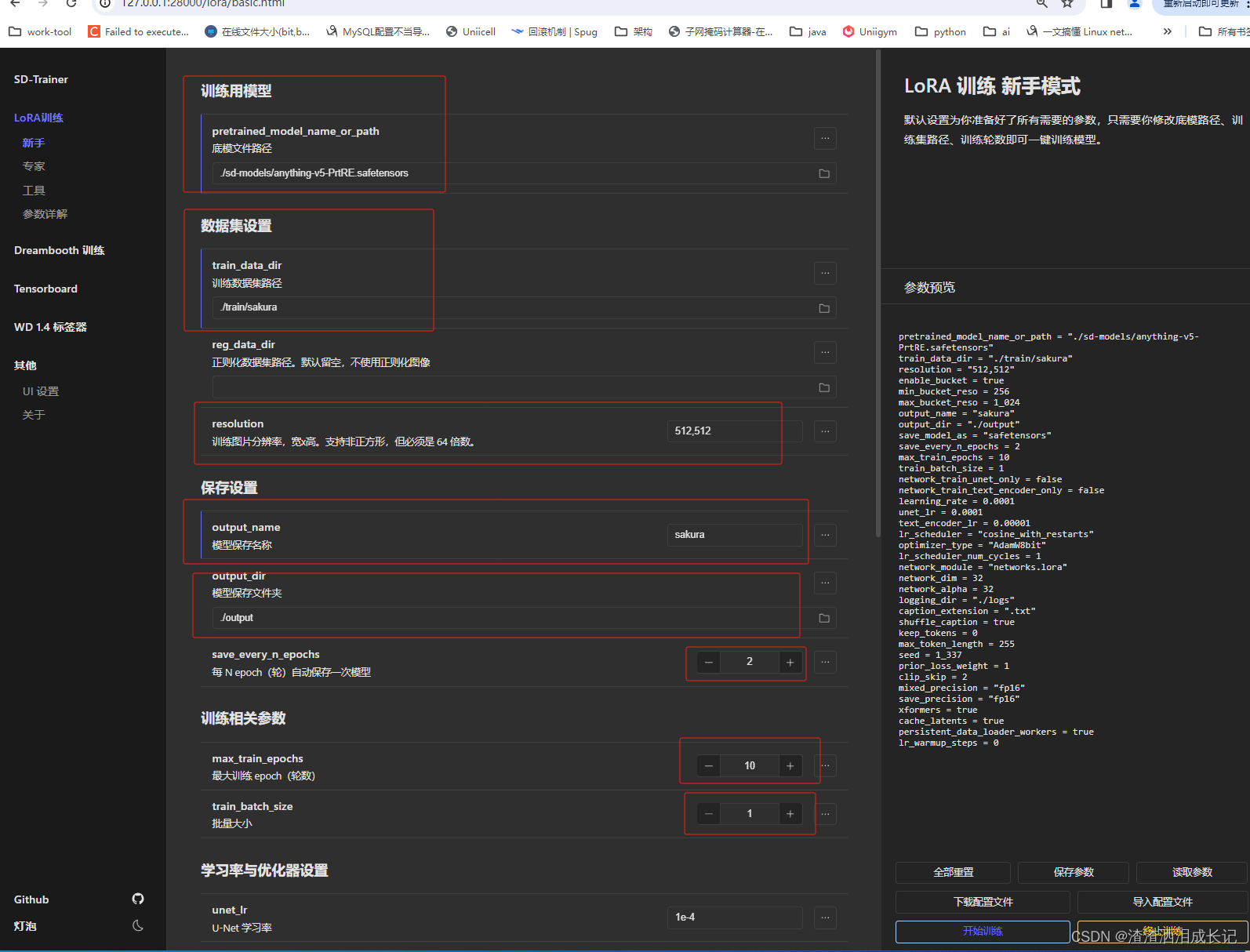
- 学习率:大家可以直接默认,这里注意网络维度,不是越大越好,还是和显存有关,这里默认是32,我的显卡低就选这个,大家高点的也可选择64
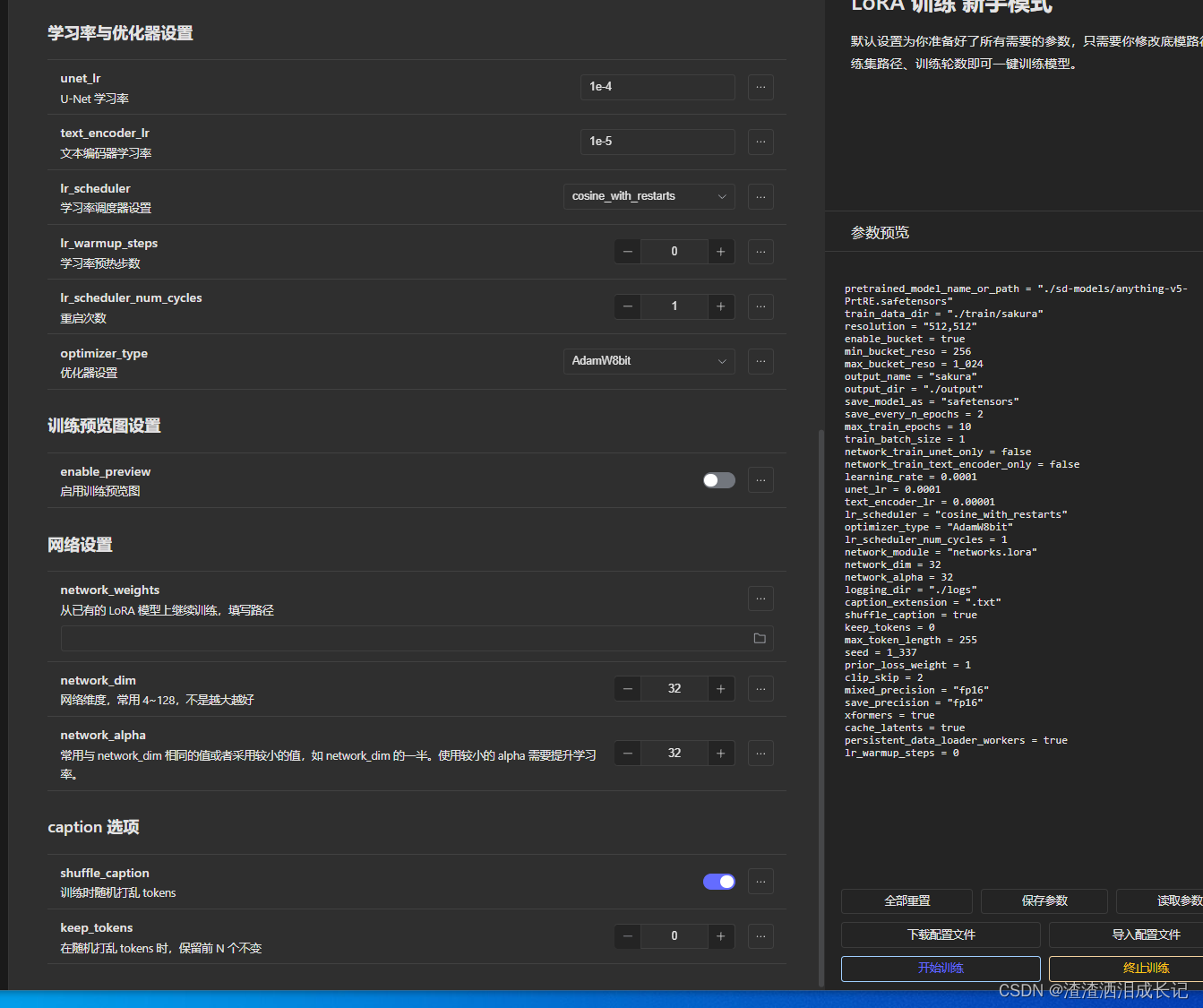
?大家也可以去看下参数说明那一栏。
4.开始训练
都设置完毕建议点击保存参数,下次进来页面时则会加载参数,防止丢失,然后就点击右下角的开始训练,就会弹出训练任务已提交,等待训练。
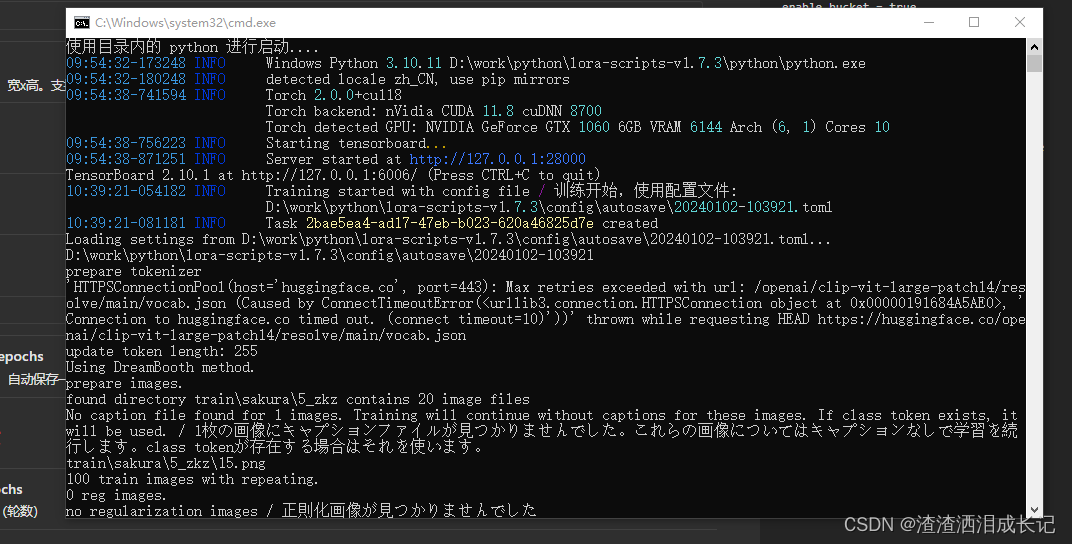
4.1??tensorboard
训练过程中可以看下训练曲线图,在tensorboard一栏。
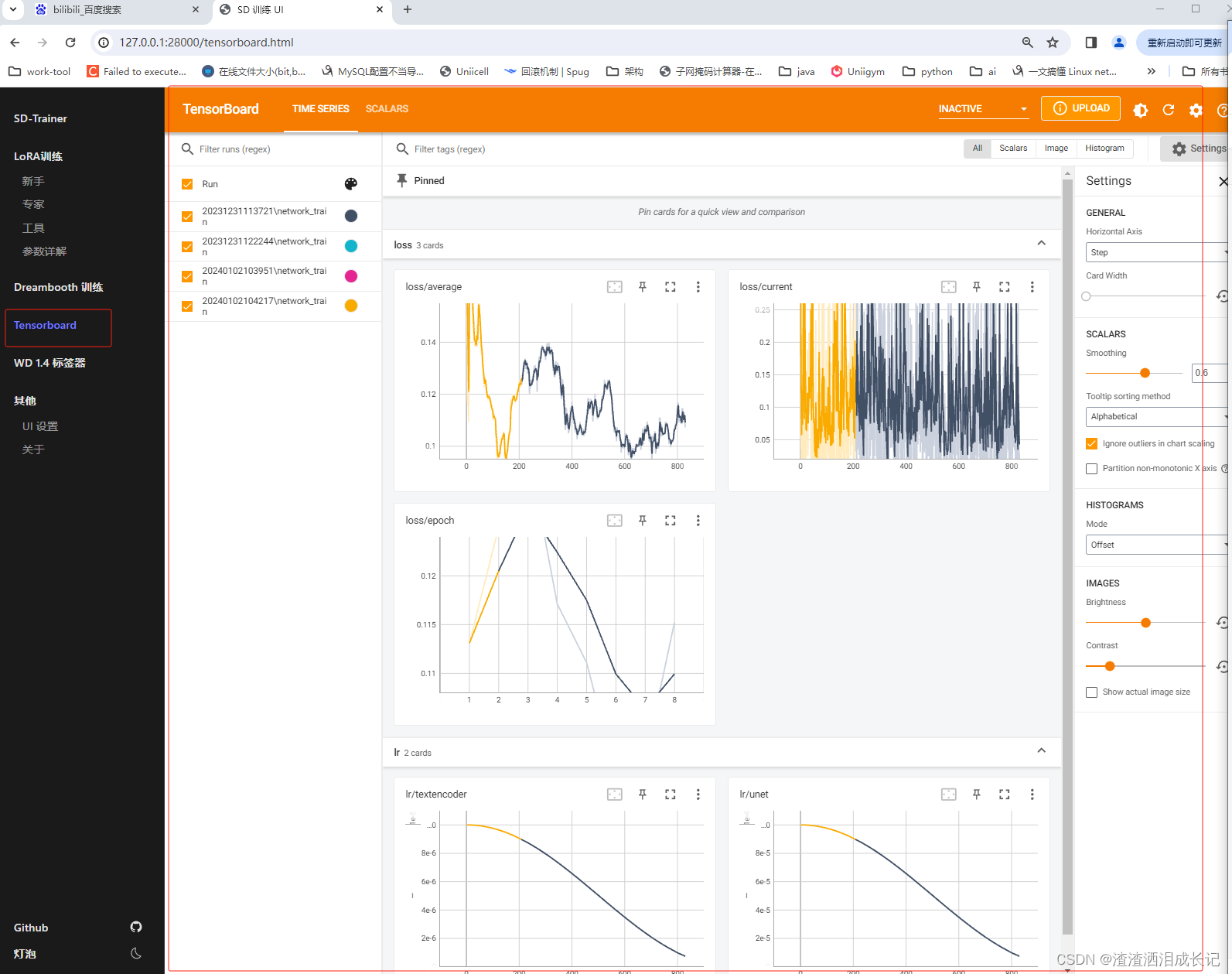
我们设置的参数是10,所以此次训练迭代10次结束,现在已经训练第三个了,而到了第二个就会进行模型保存一次,我们看下是否保存了模型结果。?
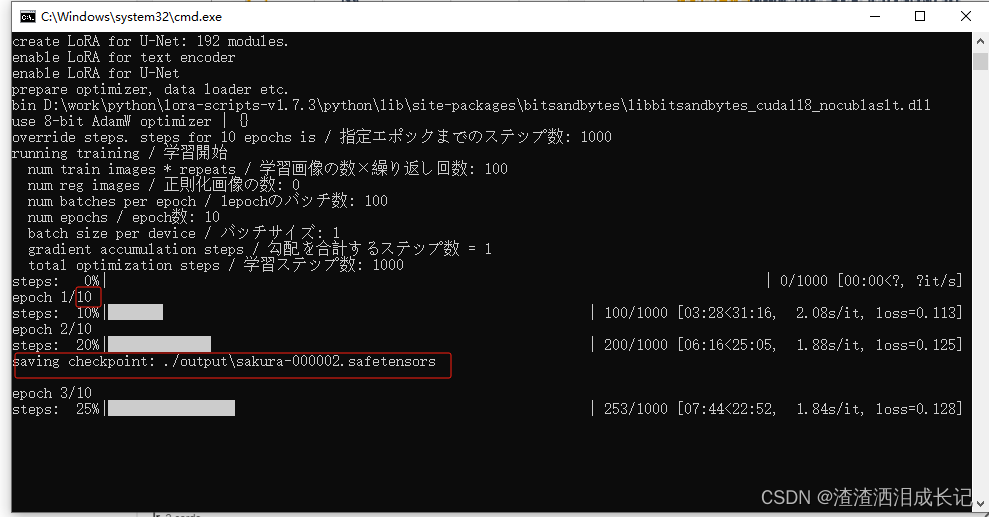
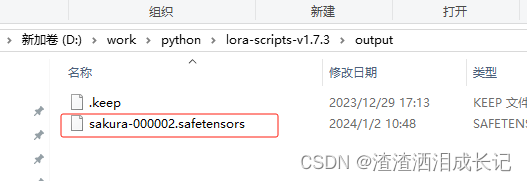
?已经有了一个了。
?
?5.训练完成
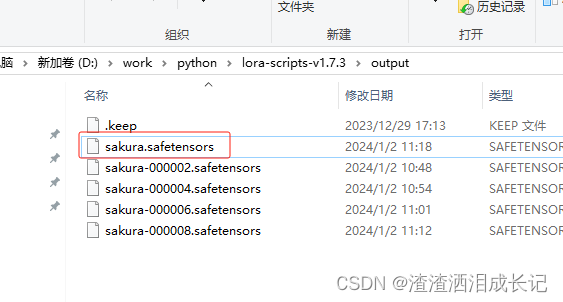
等待一段时间,可以看下10个迭代已经全部完成。

?最后保存的是这个模型。
?
?6.使用自己训练的模型
模型训练完了,剩下就是我们自己使用模型了,需要打开SD绘画,我们先把模型复制到SD里,然后打开SD界面,刷新下就有了我们的Lora模型。
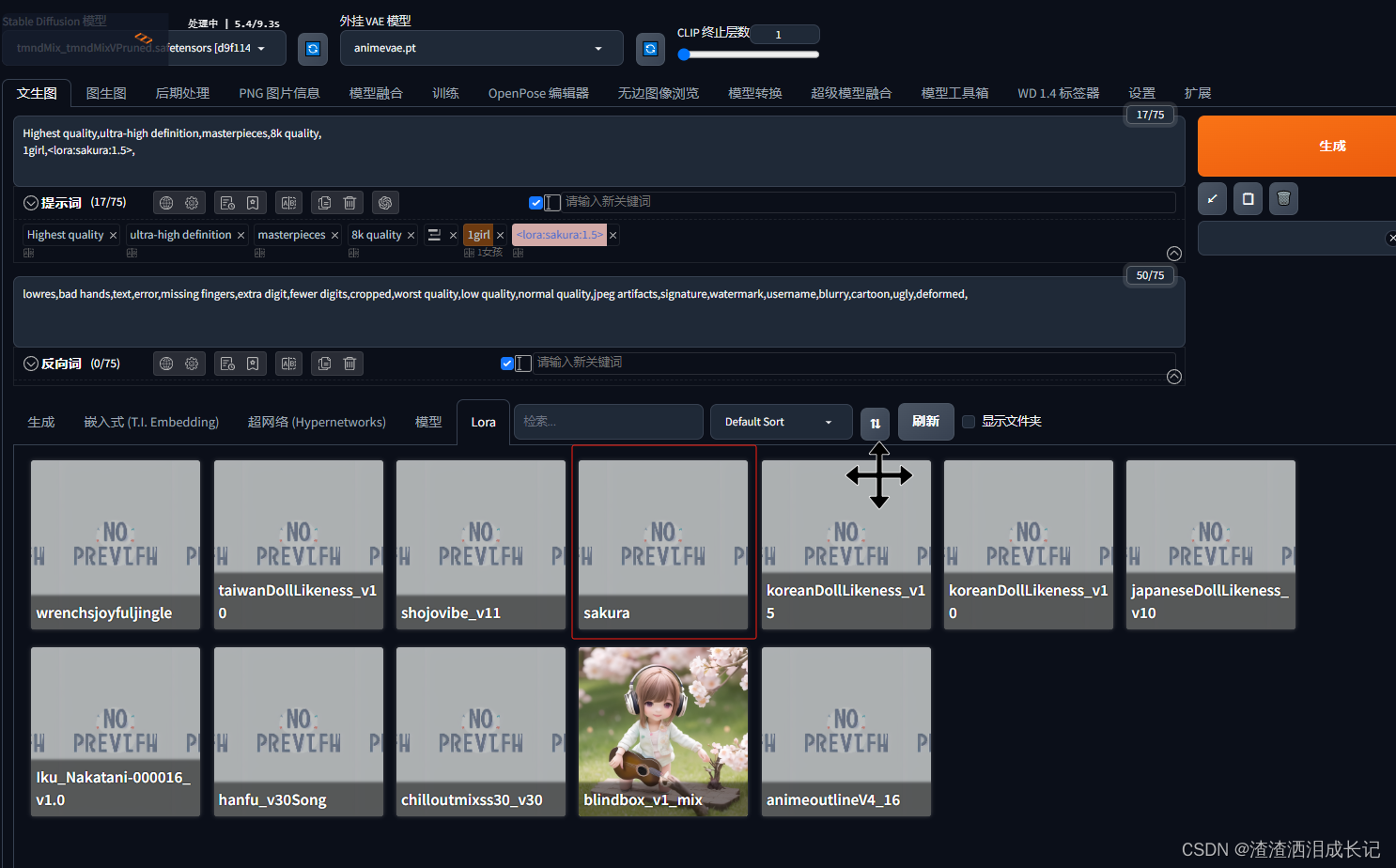
这样我们就可以使用了。
如果不用这个Lora模型的化,就是这样的,用基础模型就是这样的。

使用Lora模型的化,用的大模型anything-v5-PrtRE,Lora1.3的比例就很像了


我特喜欢这个,这个巨像,

我们不是有好几个模型吗,可以挨个放入进来看看哪种的会更好一些 ,然后还有比例问题,看看在哪个会更好一点,比如1不像你这个人物就往上调1.1,1.2等等这样试试,取自己最中意的那个
使用这个大模型出来的效果也不错,tmndMix_tmndMixVPruned
简直就是小樱本人Lora1.5

?Lora1.3


其实画风也是有点微变的哈哈?

也可以生成长头发的小樱,不同穿着的小樱。

1.2就不是那么像了,哈哈?

当然不是每个模型都比较好,Q图就比较糊,也不算好看,所以上面介绍尽量用祖宗级别的模型,不要用融合后的模型,不兼容通用。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 0122-1-JavaScript高级程序设计11-27章
- Mysql 索引优化
- 代码随想录算法训练营第五十三天| 1143.最长公共子序列、1035.不相交的线、53.最大子序和动态规划
- 2023最新版JavaSE教程——第12天:集合框架
- docker搭建镜像仓库并设置账密登录
- C语言——联合和枚举
- vp与vs联合开发-Ini配置文件
- 文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《含规模氢能综合利用的高比例风光多能源系统低碳灵活调度》
- 绿色环保之选:探索智慧公厕公司厂家的可持续发展策略
- Feign目标方法代理流程