菜鸟导入导出assetbundle
因为菜鸟不会用unity c#什么的,所以最后参考贴吧的方法用的是UABE(Unity Assets Bundle Extractor)和UABEA(Unity Assets Bundle Extractor Avalonia)
可以去github上下载
对于txt、xml什么的可以直接改,但是byte文件里还是会有一些类似乱码的东西,所以这种的还不太清楚怎么改比较好
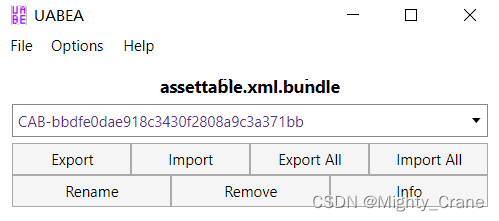
用UABEA open要编辑的bundle,如果太大会提示保存到memory,总之是有个CAB数据在内存里,贴吧的教程是export出来,但我实践后感觉并不需要,直接点击info
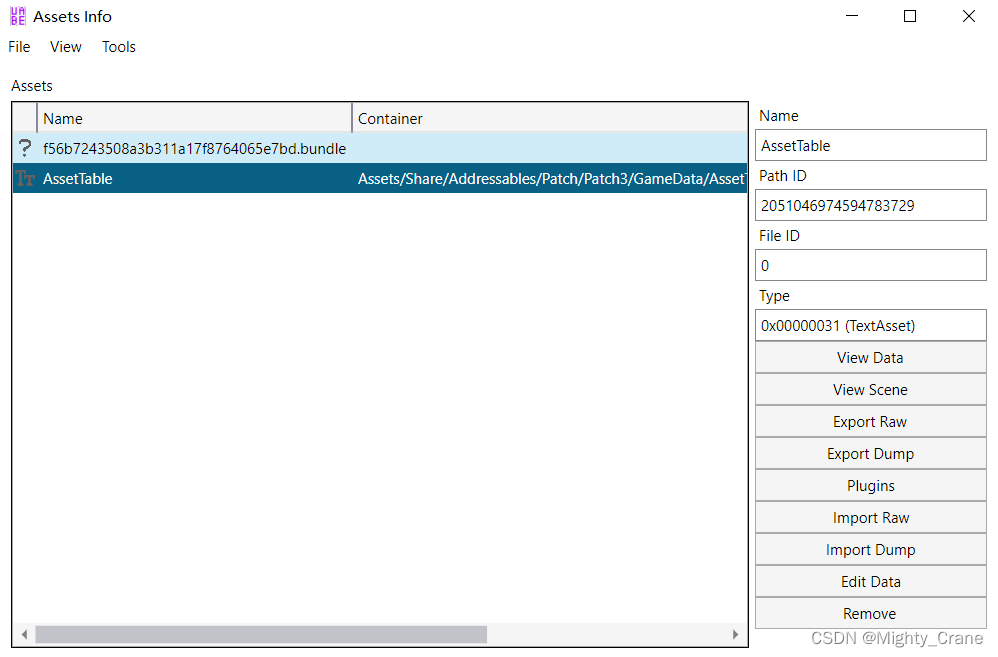
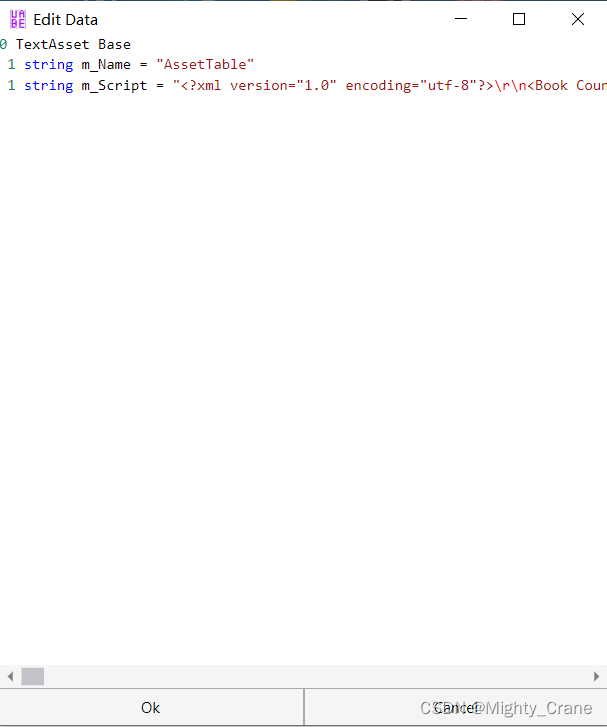
在弹窗选择对应文件后,其实可以直接edit,但是一般这种内容被整合在一个字符串""里面,无论看还是写都十分麻烦,所以我一般是export dump出来txt再编辑
当然这里的txt还是把字符串挤在一起的,所以为了清楚要改哪里,我还是用了UABE来导出一个更结构化的txt
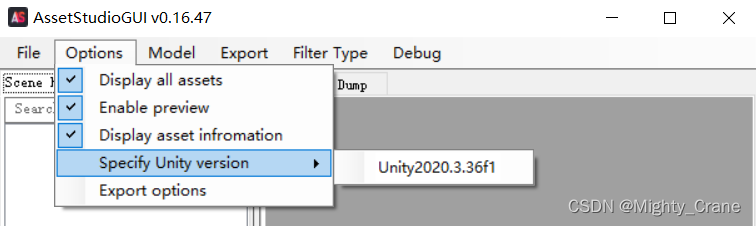
记得用UABE读取bundle之前先要填入一个unity版本,不然会报错。每次打开都要填,还挺麻烦的
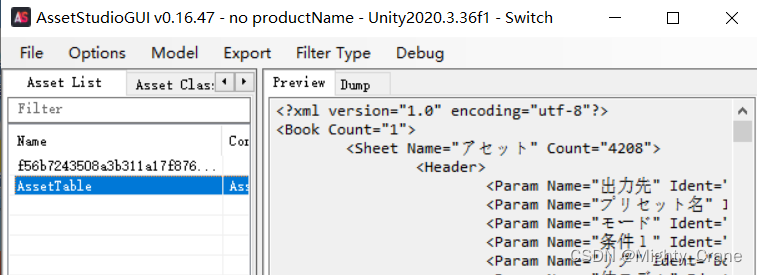
load file之后在左侧栏asset list可以找到打开对应文件,可以看到是比较结构化的

也可以这样export dump出来txt,不过这个txt是不能用来导入的,修改之后还是要做成一行字符串,换行都要用\n或者\r\n等
我是想把两个mod合并,所以就是要把两个bundle里的相应项拼在一起。不过有的几千条,一个一个搞太难受了,所以写了下面的python代码
# -*- coding: utf-8 -*-
import re
def merge_and_save_to_txt(str1, str2, output_file):
import re
# 使用正则表达式分割字符串
list1 = re.split(r'\s{4,}', str1)
list2 = re.split(r'\s{4,}', str2)
# 合并两个列表并去重
merged_list = list(set(list1 + list2))
missing_in_merged = [item for item in list1 if item not in list2]
print(len(list2),len(list1),len(missing_in_merged),len(merged_list))
# 对合并后的列表进行排序
merged_list.sort()
# 逐行保存到文本文件
with open(output_file, 'w', encoding='utf-8') as file:
for item in merged_list:
# 将 \n 和 \r 替换为原始形式
item = item.replace('\n', '\\n').replace('\r', '\\r')
#file.write(f"{item}\\r\\n\t\t\t")
file.write(f"{item}\n")
with open(output_file.replace(".txt","_rest.txt"), 'w', encoding='utf-8') as file:
for item in missing_in_merged:
# 将 \n 和 \r 替换为原始形式
item = item.replace('\n', '\\n').replace('\r', '\\r')
file.write(f"{item}\\r\\n\t\t\t")
#file.write(f"{item}\n")
def find_special_characters(text):
special_characters = set()
for char in text:
if not char.isalnum() and char not in [' ', '\t', '\n', '\r']:
special_characters.add(char)
return special_characters
# 因为懒得再让他读txt找对应项在哪,所以直接把相应部分复制上来
string1 = '''
'''
string2 = '''
'''
special_chars = find_special_characters(string1)
print("Special Characters found:")
for char in special_chars:
print(repr(char))
special_chars = find_special_characters(string2)
print("Special Characters found:")
for char in special_chars:
print(repr(char))
# 保存结果到文本文件
output_file_path = "merged_result4.txt"
merge_and_save_to_txt(string1, string2, output_file_path)
print(f"Results saved to {output_file_path}")
但是保存过程中可以看到有些编码问题,原本的txt中有些字符是非gbk或utf-8编码的,这里只能统一编码,所以可能会伤到原本的设置。所以如果害怕的话还是最好手动比较?反正还没发现更好的办法(甚至直接把txt用pycharm打开的话能够看到一些在记事本里没问题的地方,也会加塞一些乱码字符)
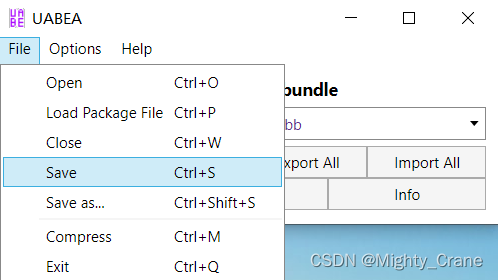
总之把这个神秘的txt改好后再通过UABEA import dump上去后,按照贴吧的教程是txt import给CAB,然后CAB再import给bundle,然后再compress。实践后感觉其实没那么复杂,就是一个save完事,除非另存为点save as
总之这样这个bundle就改好了
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CnosDB容灾方案概述
- 【C语言编程之旅 1】刷题篇-初识c语言
- 【Android逆向】记录一次某某虚拟机的逆向
- 文件夹加密软件哪个更安全?文件夹加密软件盘点
- Supervised Knowledge Makes Large Language Models Better In-context Learners
- 如何使用C++max函数(c语言max函数的使用方法)
- Asp .Net Core 系列: 集成 Consul 实现 服务注册与健康检查
- Hive之set参数大全-6
- 新手怎么入行SEM
- 【习题】 从网络获取数据