ES分词器
Analysis:文本分析是把全文本转换一系列单词的过程,也叫分词。Analysis是通过Analyzer(分词器)来实现的。
1.Analyzer组成
-
注意:在ES中默认使用标准分词器:StandardAnalyzer。特点是:中文是单字分词,英文是单词分词。
举例:我是中国人 how are you
"我" "是" "中" "国" "人" "how" "are" "you"?
分词器由三种构件组成:character filters,tokenizers,token filters。
-
character filters:字符过滤器,先对文本进行预处理,过滤掉那些html标签。
-
tokenizers:分词器,一般英文可以根据空格来分开,而中文比较复杂,可以采用机器学习算法来分词。
-
token filters:token过滤器,将切分后的单词进行加工,大写转换小写、同义转换等等。

2.ES提供的分词器——内置分词器
-
standard Analyzer—默认分词器,英文按单词切分,并小写处理、过滤符号,中文按单字分词。
-
simple Analyzer—英文按照单词切分、过滤符号、小写处理,中文按照空格分词。
-
stop Analyzer—中文英文一切按照空格切分,英文小写处理,停用词过滤(基本不会当搜索条件的无意义的词a、this、is等等),会过滤其中的标点符号。
-
whitespace Analyzer—中文或英文一切按照空格切分,英文不会转小写。
-
keyword Analyzer—不进行分词,这一段话整体作为一个词。
?测试语法: 
举例:stop Analyzer
 ?
?
3.设置内置分词器
在我们创建索引指定映射的时候,可以在设置字段类型的时并指定其要使用的分词器。

4.适合中文的分词器——IK
4.1IK分词器的安装
Release v7.14.0 · medcl/elasticsearch-analysis-ik · GitHub
 ?
?
下载到本地,解压之后通过xftp上传到云服务器中。
? 停止es和kibana的容器,我们通过数据卷的方式挂载:
docker run -d --name es ?
-p 9200:9200 -p 9300:9300 ? ?
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" ?
-e "discovery.type=single-node"?
-v ?/opt/ik-7.14.0/:/usr/share/elasticsearch/plugins/ik-7.14.0 ?
?elasticsearch:7.14.0
4.2使用
IK有两种颗粒度的拆分:
-
ik_smart:会做最粗粒度的拆分。

- ik_max_word:会做文本最细粒度的拆分。 ?
 ?
?
4.3IK中的扩展词和停用词配置
-
扩展词典就是有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入到扩展词典。
-
停用词典就是有些词是关键词,但是出于业务场景不想使用这些关键词被检索到,可已将这些词典放入停用词典中。
举例:
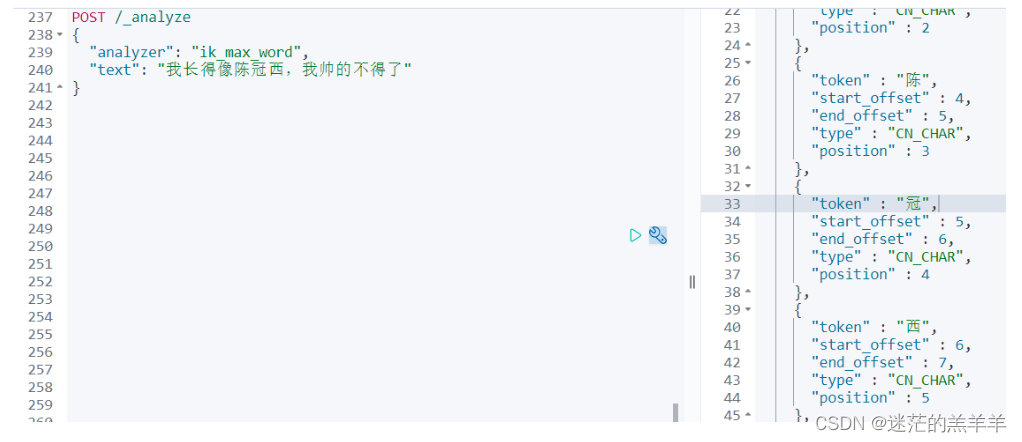
????????分词后可以看到陈冠西本来是个人名,但是并没有将陈冠西分为一个词,而是分为了"陈","冠","西"。所以我们可以自定义的将"陈冠西"加入到扩展词典中,后续就可以通过"陈冠西"关键词搜索到完整的数据。
????????停用词典反之即可,就是此词虽然被切分成了关键词,但是并不想通过此词搜索到这条完整数据,那就将这个词加入到停用词典中。
1.进入到ik分词器的config目录,找到IKAnalyzer.cfg.xml文件

2.vim进入这个文件

自定义文件名:

????????我们在这里可以配置文件,在config下创建相应的文件后,将自定义的词加入文件即可,但是切记一行只能放一个词。
????????但是ES其实也给我们给了一些它认为比较重要的词,如下两个文件中:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年第四届电气、电子与信息工程国际会议(ISEEIE 2024) | Ei&Scopus双检索
- 指标体系构建-04-非交易型数据指标体系
- 【Python基础篇】【18.模块和包】(附案例,源码)
- 重生奇迹mu翅膀教程攻略
- 金蝶云星空 x 钉钉考勤|集简云助力集成电路上市企业考勤数据自动同步,让效率翻倍!
- 置顶> 个人学习记录一览
- STM32——电容触摸按键充电时间测量实验
- 【算法系列 | 10】深入解析查找算法之—线性查找
- 鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Text文本组件
- SSH连接docker容器