Pandas教程(五)—— 重塑及数据透视
1.数据重塑
重塑数据主要有两种方式,分别是 stack(堆叠)和 unstack(拆堆),他们两个是互逆的操作
| 函数 | 作用 | 参数 |
|---|---|---|
| data.stack( ) 堆叠 | 会“旋转”或将列中的数据透视到行 列 一一> 行 | 可以在括号里传入需要堆叠的轴向名称 |
| data.unstack( ) 拆堆 | 将行中的数据透视到列? 行 一一> 列 | 可以通过传入一个层级名称来拆分不同的层级 |
import pandas as pd
import numpy as np
data = pd.DataFrame(np.arange(12).reshape(6,2),
index = pd.MultiIndex.from_product([["Ohio","Colorado"],["one","two","three"]],names = ["state","number"]),
columns = pd.Index(["left","right"],name = "side"))
print(data)
print("-"*35)
# 拆堆 行透视为列
chai = data.unstack("state") # 传入要拆分的层级
print(chai)
print("-"*35)
# 堆叠 列透视为行
dui = chai.stack("side")
print(dui)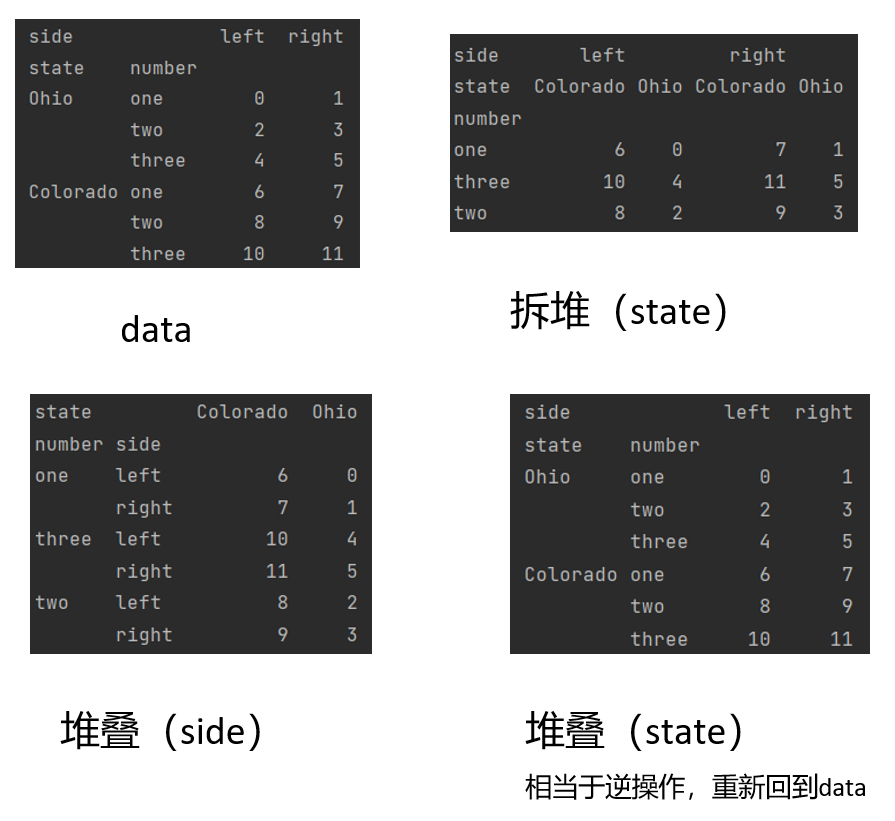
2.数据透视表
透视表是一种可以对数据动态排布并且分类汇总的表格格式
可以让我们从不同的角度去分析一个大数据库,有点类似于分类筛选的高阶版操作
?2.1 pivot_table?
? 该部分笔记参考了以下文章:
https://zhuanlan.zhihu.com/p/31952948![]() https://zhuanlan.zhihu.com/p/31952948
https://zhuanlan.zhihu.com/p/31952948
- 语法:? ? ?
? ? ? ? ?pivot_table ( data,? index = None,? values = None,??columns = None,? aggfunc = 'mean' )??
常用参数说明:?
? ? ? ? ? ? ? ? ? ?index:? 设置行分层字段,将选中的列设为行索引? ?👇
? ? ? ? ? ? ? ? ? ?values:输入一个含列名的列表,筛选我们需要保留的列
? ? ? ? ? ? ? ? ? ?columns:类似Index设置列分层字段,将选中的列设为列索引? ?👉
? ? ? ? ? ? ? ? ? ?aggfunc:设置我们对数据聚合时进行的函数操作,默认为 mean
? ? ? ? ? ? ? ? ? ?fill_value:替换缺失值
? ? ? ? ? ? ? ? ? ?drop_na:是否去除所有条目均为NA的列(默认False,不去除)
? ? ? ? ? ? ? ? ? ?margins:是否添加行 / 列计数 及 总计数(默认False,不添加)
- 参数使用说明
? ? ? ?下面我们以詹姆斯某赛季的数据为例,来对pivot_table函数进行讲解
? step1? 首先导入数据,并展示前五场:
import pandas as pd
import numpy as np
road = "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件028-029\Lebron_James.csv"
data = pd.read_table(road,sep=",")
print(data.head(5))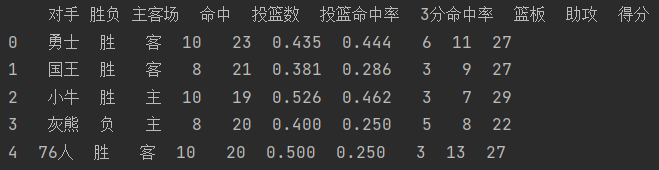
?step2??需要james在主客场和不同胜负情况(index)下的得分、篮板与助攻(values)三项数据
data1 = pd.pivot_table(data, index=['对手', '主客场'],values=['得分','助攻','篮板'])
print(data1.head(5))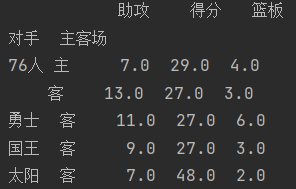
? ?step3??我们还想获得james在主客场和不同胜负情况下的总得分、总篮板、总助攻(aggfunc)
? ? ? ? ? ? ? 此时应该向aggfunc中输入sum函数,按层次求和
# 这里要注意mean不是内置函数,它是numpy中的一个函数
data2 = pd.pivot_table(data, index=['对手', '主客场'],values=['得分','助攻','篮板'],
aggfunc=[sum,np.mean])
print(data2.head(5))
??step4??我们也可以通过columns再设置一个列索引,并且通过margin来汇总
# fill_value填充空值,margins=True进行汇总
data3 =pd.pivot_table(data,index=['主客场'],columns=['对手'],values=['得分'],aggfunc=[np.sum],fill_value=0,margins=1)
print(data3)
?2.2?实现excel的vlookup功能
- 要求:一个excel表中有两个sheet,要求将 sheet1 中的某列,插入到 sheet2 的指定位置?
- step:
- ?切片要合并的列?
- 将它和sheet2合并
- 再在合并的数据中提取出该列,并在合并数据中删除该列
- 将提取出的该列插入指定位置
import pandas as pd
road = "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件028-029\Vlookup.xlsx"
data1 = pd.read_excel(road,sheet_name="花名册")
data2 = pd.read_excel(road,sheet_name="成绩单")
# 将 花名册 与 成绩单中的总分、学号 合并
hebing = pd.merge(data1,data2.loc[:,["学号","总分"]],how = "left",on = "学号")
print(hebing)
print("-" * 40)
# 将总分放到第二列的位置
score = hebing.总分 # 提取出 总分 列
hebing = hebing.drop("总分",axis = 1) # 在原数据中删除该列
hebing.insert(1,"总分",score) # 在原数据第二列插入新列
print(hebing)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 奇迹服务端问题解答
- git apt wget 全局设置代理
- 记录一个Python鼠标自动模块用法和selenium加载网页插件的设置
- 【LangChain学习之旅】—(9) 用SequencialChain链接不同的组件
- DC-DC升压/降压芯片 模块5V 12v 24V 36V 隔离电源解决方案PCB和原理图
- XDOJ562.两个分数的加法和减法
- 李宏毅LLM——ChatGPT原理剖析
- Android---Kotlin 学习011
- flume:Ncat: Connection refused.
- NVME SSD FDP功能有什么作用?