2024/1/14周报
文章目录
摘要
本周阅读了一篇基于CEEMDAN-LSTM的金融时间序列预测模型的文章,文中提出了一种基于自适应噪声的完全集成经验模式分解(CEMDAN)和长短期记忆(LSTM)网络的金融时间序列预测模型,经过CEEMDAN分解、小波阈值去噪和重构,得到去噪后的信号。使用去噪信号代替原始信号作为LSTM网络的输入,可以获得更准确的最终预测结果,此外还对GRU的理论内容进行进一步的学习。
Abstract
This week, an article on the financial time series prediction model based on CEEMDAN-LSTM is readed. In this paper, a financial time series prediction model based on adaptive noise and fully integrated empirical mode decomposition (CEMDAN) and long-term and short-term memory (LSTM) networks is proposed. After CEEMDAN decomposition, wavelet threshold denoising and reconstruction, the denoised signal is obtained. Using the denoised signal instead of the original signal as the input of LSTM network can obtain more accurate final prediction results, and the theoretical content of GRU is studyed.
文献阅读
题目
Financial time series forecasting model based on CEEMDAN-LSTM
问题与创新
目前广泛使用的金融数据去噪方法是通过小波去噪等方法对整个序列进行去噪或平滑处理,然后将结果划分到两个不同的数据集中,通常被称为训练集和测试集。这实际上是在去噪过程中使用未来信息,可以提高历史数据的拟合度。然而使用未来的数据并不能真正提高预测能力。
本文提出了一种基于自适应噪声的完全集成经验模式分解(CEMDAN)和长短期记忆(LSTM)网络的金融时间序列预测模型。在实际应用中,未来的信息不能用于预测,因此引入滑动时间窗将原始序列分解为等长序列的簇。经过CEEMDAN分解、小波阈值去噪和重构,得到去噪后的信号。使用去噪信号代替原始信号作为LSTM网络的输入,将获得更准确的最终预测结果。以平安银行的股价数据为例,多种模型被用来预测其价格。结果表明,与标准LSTM模型和常用的结合经验模态分解的预测方法相比,所提出的CEEMDAN-LSTM模型具有更好的预测效果。在一段时间内使用滑动窗口对数据进行去噪更具有实际意义。
方法
A.CEMDAN方法
经验模态分解具有自适应性,克服了小波分解需要设置基函数的问题。EMD本质上是一个稳定化过程,它通过一个固定的模态将序列从不同尺度的平稳波动项和一个残差趋势项中分离出来,每个波动项称为固有模态函数(IMF)。原始信号S(t)可以用分解项的求和形式来描述。有以下等式:
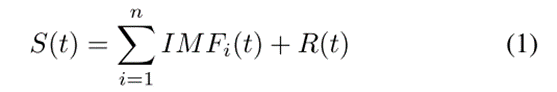
IMFi(t)和R(t)分别表示第i个IMF,即残差函数。n表示IMF分量的总和。
CEEMDAN在EMD分解后加入带有辅助噪声的IMF分量,而不是直接将高斯白色噪声信号加入到原始信号中。 CEEMDAN分解中,在获得一阶IMF分量后进行整体平均计算,然后对剩余部分重复上述操作,有效地解决了白色噪声从高频向低频传递的问题。CEEMDAN算法可以描述如下:
(1) 将高斯白色噪声添加到原始信号
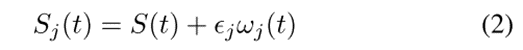
j ∈ [1,.,J],ωj(t)表示第j个具有正态分布的噪声信号,ω j为噪声系数。
(2) 对每个Sj(t)进行EMD分解,得到第一个IMF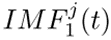 ,然后提取CEEMDAN的第一个IMF
,然后提取CEEMDAN的第一个IMF
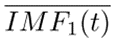
(3) 计算去除第一模态分量后的残差R1(t):
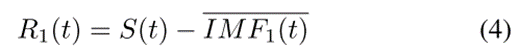
(4) 重复(1)至(3),直至残留信号符合要求。原始信号可以表示为
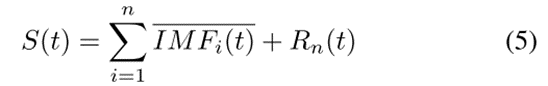
信号经过CEEMDAN分解后,不能直接丢弃高频分量。可以对高频信号部分进行滤波去噪,然后利用去噪后的信号进行重构,既可以避免信息的大量损失,又可以滤除部分噪声。
常用的去噪方法是小波阈值去噪法:
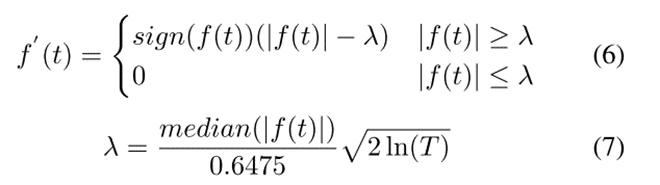
f ′(t)表示滤波后的函数,符号表示符号函数。在(7)中,median返回中位数。
B.LSTM网络
控制单元状态信息增加或减少的结构称为门。在LSTM块中有三个这样的门,即遗忘门,输入门和输出门。通过这些门结构,LSTM可以记忆、更新、遗忘一些信息。
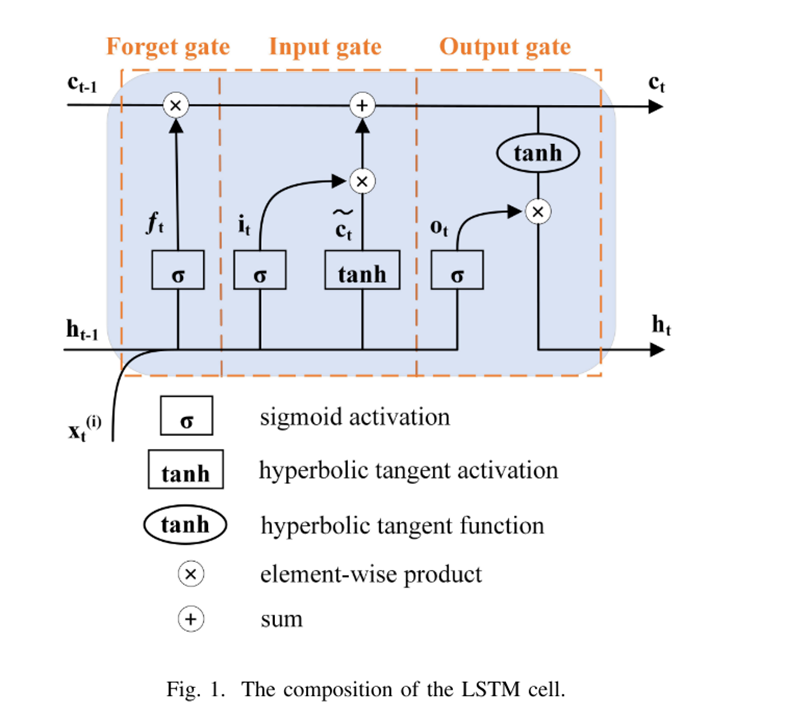
以遗忘门举例说明:
遗忘门通过将先前状态ht-1的输出和当前状态输入信息xt输入到sigmoid函数中,生成0和1之间的值,并将其与单元状态相乘,结果0表示遗忘,1表示完全记住。
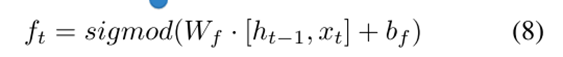
C. CEEMDAN-LSTM模型
现实中,股票市场金融时间序列受短期噪声影响较大,因此以损失少量信息为代价,在进行预测前对序列进行去噪处理,有助于提高预测的准确性和可靠性。
本文提出的模型流程图如图2所示:

- 原始信号处理:获取的股市数据包括多个维度,每个维度的数据需要单独提取和处理。
- 信号分解-去噪-重构:对分解后的IMF信号不进行去噪处理,而是只对噪声能量高的IMF分量进行去噪处理。
- 数据预测:去噪后,重建的信号通过LSTM网络得到最终的预测值。虽然神经网络只有4层,但去噪后的信号具有更明显的特征,通过网络仍然可以得到更好的预测结果。
实验过程
数据集与数据预处理
选取平安银行2010年1月至2021年12月的九项特征数据作为原始数据。每天的数据形成一个九维向量,具有九个特征:最高价、最低价、开盘价、收盘价、换手率、昨日收盘价、成交量、涨跌、成交金额。2010年1月至2018年12月的数据作为训练集,2019年1月至2021年12月的数据作为测试集。
为了克服特征序列之间维数不同的影响,提高模型精度,提高迭代求解的收敛速度,首先对数据进行归一化处理:
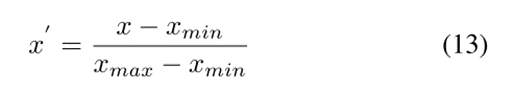
得到网络输出后,需要通过逆归一化得到最终结果。
参数设置
将滑动时间窗口设置为120,并使用最近的10个历史数据来预测下一个值。通过滑动窗口,可以获得长度为120的多个序列。每个序列去噪后,最后10个结果作为LSTM的输入,网络的输出是预测值。
评价指标和参数
该模型的效果一般通过以下四个评价指标来衡量:
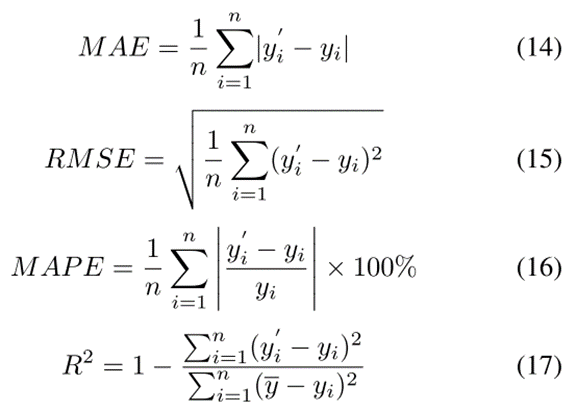
实验结果
下图表示使用相同数据集的三个不同模型的预测误差:
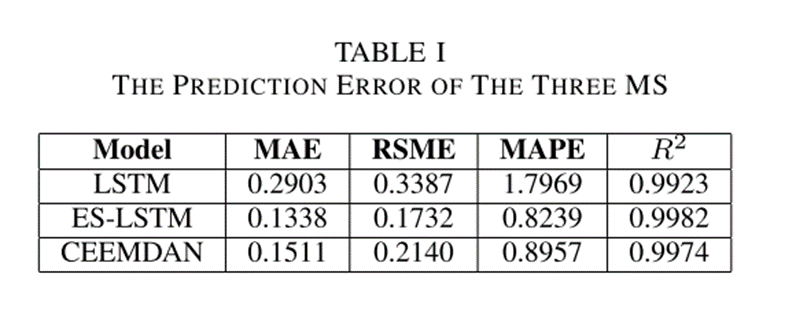
在三个指标上,ES-LSTM和CEEMDAN-LSTM模型的预测性能相近,且明显优于原始模型LSTM。与ES-LSTM模型相比,CEEMDAN-LSTM模型性能非常接近,并且可以反映更详细的变化,在金融时间序列特别是股票价格序列中更加实用。
深度学习
GRU
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:
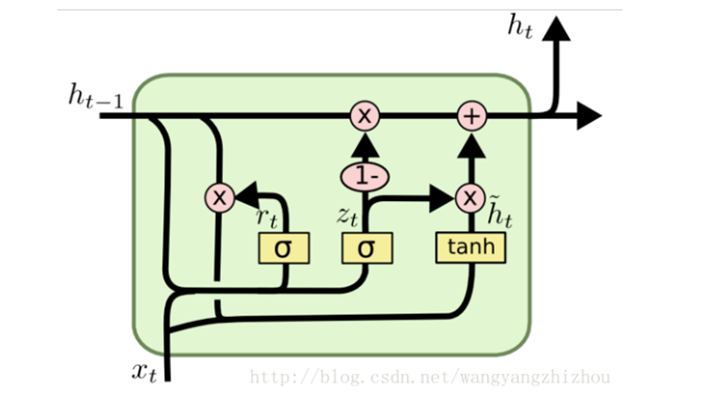
图中的zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 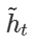 上,重置门越小,前一状态的信息被写入的越少。
上,重置门越小,前一状态的信息被写入的越少。
GRU前向传播
根据上面的GRU的模型图,推导出GRU网络的前向传播公式:

GRU的训练过程
从前向传播过程中的公式可以看出要学习的参数有Wr、Wz、Wh、Wo。其中前三个参数都是拼接的(因为后先的向量也是拼接的),所以在训练的过程中需要将它们分割出来:
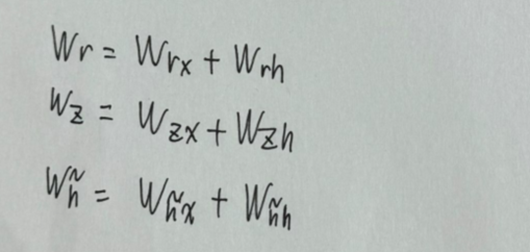
输出层的输入:
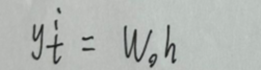
输出层的输出:
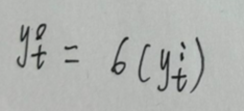
在得到最终的输出后,就可以写出网络传递的损失,单个样本某时刻的损失为:
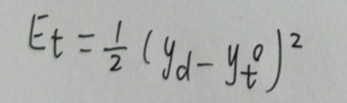
则单个样本的在所有时刻的损失为:
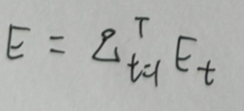
采用后向误差传播算法来学习网络,所以先得求损失函数对各参数的偏导(总共有7个):

其中各中间参数为:
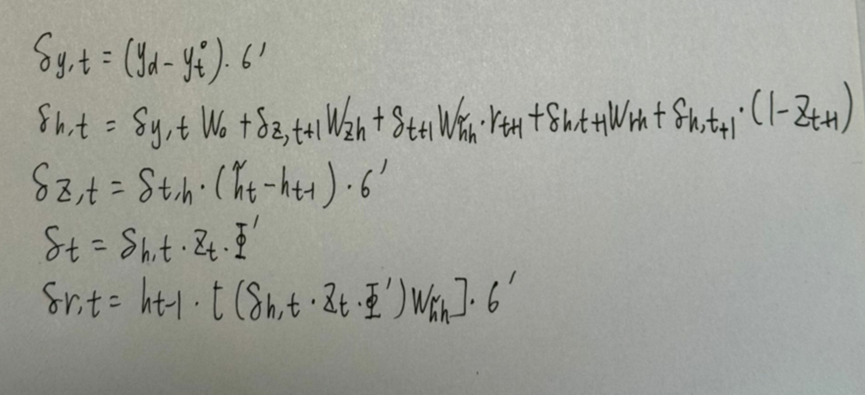
在算出了对各参数的偏导之后,就可以更新参数,依次迭代知道损失收敛。
概括来说,LSTM和CRU都是通过各种门函数来将重要特征保留下来,这样就保证了在long-term传播的时候也不会丢失。此外GRU相对于LSTM少了一个门函数,因此在参数的数量上也是要少于LSTM的,所以整体上GRU的训练速度要快于LSTM的。不过对于两个网络的好坏还是得看具体的应用场景。
总结
GRU是LSTM的简化轻量版,训练速度快于LSTM,但并不意味着任何场景都优于LSTM,还要具体问题具体分析。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 打包CSS
- Python字典操作指南,掌握编程中必备的数据结构!
- 开发属于你的数据采集器,DataScale Collector详解
- UnicodeUtil.java
- Gradle笔记
- selenium+python配置chrome浏览器的选项的实现
- 【LeetCode】226. 翻转二叉树(简单)——代码随想录算法训练营Day15
- LeetCode-2865. 美丽塔 I
- springboot/java/php/node/python在线考试系统【计算机毕设】
- 多维时序 | MATLAB实现RIME-CNN-LSTM-Multihead-Attention多头注意力机制多变量时间序列预测