Hadoop 实战 | 倒排索引 InvertedIndex
倒排索引概念
倒排索引(Inverted Index)是信息检索领域中的一种数据结构,它是一种反转(倒排)文档-词项关系的数据结构,以支持通过词项来查找相关文档。
在倒排索引中,每个词项都被映射到包含该词项的文档列表。并且在实际应用中,还需要给每个文档添加一个权值,用以指出每个文档与搜索内容的相关度。
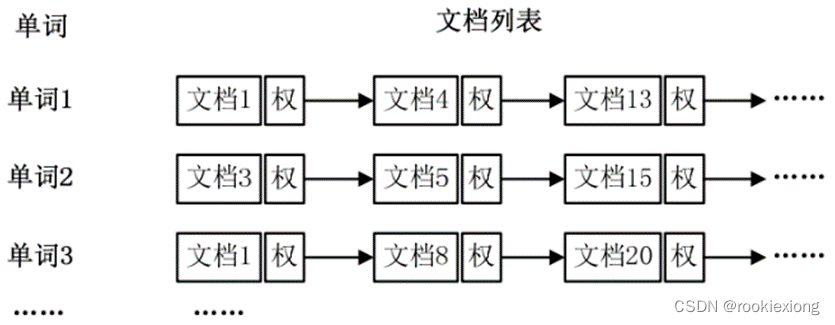
与倒排索引相对应的是正向索引,即文档-词项关系的数据结构。当用户发起查询关键词时,需要扫描索引库中的所有文档,找出所有包含关键词的文档,在检索过程中效率较低。
倒排索引在搜索引擎等信息检索系统中得到广泛应用。通过倒排索引,检索系统能够以更高效的方式在大规模文档集合中定位包含特定词项的文档,从而为用户提供快速准确的搜索结果。
倒排索引建立过程
词频统计见我的上一篇博客Hadoop 实战 | 词频统计WordCount-CSDN博客
在上一章WordCount的基础上,使用词频作为权重,即记录单词在文档中出现的次数。因此相较于上一章,需要统计信息增加了文档ID,即统计单词、文档ID和词频。因此大致流程与上一章基本相同,本实验在WordCount的基础上进行简单改动即可。
由于需要统计单词的来源文章,因此对于Mapper需要将生成的中间键值对由<word,1>改为 <word,ariticleID>;
而Reducer和之前不同的是,需要根据排序重组后的中间键值对<word, [ariticleID1, ariticleID2, …]>建立一个HashMap,用于存储每个ariticleID对应的出现次数。整体流程伪代码如下:
PSEUDO-CODE 3?? Inverted Index(倒排索引)
/* Map函数,处理每一行的文本 */
1:input <Key,Value>;?????????????????????????????????? //Value使用Text类型表示文本行
2:从文本中提取文档ID和实际文本内容snippet;
3:使用空格、单引号和破折号作为分隔符,将文本snippet分词;
4:for 文本snippet中的每个单词:
5:???? 去除特殊字符后将<word, ariticleID>写入context,发射给Reducer;
6:end for
/* Reduce函数,处理相同键的所有值 */
1:input <Key,Value>;???? //来自Map的<word,[ ariticleID1, ariticleID2,…]>
2:创建一个HashMap,用于存储每个ariticleID对应的出现次数;
3:for Value的每个ariticleID:
4:???? if ariticleID in HashMap then map(ariticleID)++;
5:?????else 在HashMap中添加该ariticleID,map(ariticleID) ←1;
6:end for
7:将Key和HashMap中的ariticleID和对应出现次数拼接并输出;
代码?
import java.io.IOException;
import java.util.StringTokenizer;
import java.util.HashMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
//import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
//import org.apache.hadoop.mapreduce.MapContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertedIndex {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, Text>{
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// Split DocID and the actual text
String DocId = value.toString().substring(0, value.toString().indexOf("\t"));
String value_raw = value.toString().substring(value.toString().indexOf("\t") + 1);
// Reading input one line at a time and tokenizing by using space, "'", and "-" characters as tokenizers.
StringTokenizer itr = new StringTokenizer(value_raw, " '-");
// Iterating through all the words available in that line and forming the key/value pair.
while (itr.hasMoreTokens()) {
// Remove special characters
word.set(itr.nextToken().replaceAll("[^a-zA-Z]", ""));
if(word.toString() != "" && !word.toString().isEmpty()){
context.write(word, new Text(DocId));
}
}
}
}
public static class IntSumReducer
extends Reducer<Text,Text,Text,Text> {
public void reduce(Text key, Iterable<Text> values,
Context context
) throws IOException, InterruptedException {
HashMap<String,Integer> map = new HashMap<String,Integer>();
for (Text val : values) {
if (map.containsKey(val.toString())) {
map.put(val.toString(), map.get(val.toString()) + 1);
} else {
map.put(val.toString(), 1);
}
}
StringBuilder docValueList = new StringBuilder();
for(String docID : map.keySet()){
docValueList.append(docID + ":" + map.get(docID) + " ");
}
context.write(key, new Text(docValueList.toString()));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "inverted index");
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!