【LMDeploy系列】模型部署与量化完全教程
前言
LMDeploy 是一个用于压缩、部署、服务 LLM 的工具包,由 MMRazor 和 MMDeploy 团队开发。
一、LMDeploy介绍
1-1、LMDeploy介绍
LMDeploy 是一个用于压缩、部署、服务 LLM 的工具包,由 MMRazor 和 MMDeploy 团队开发。它具有以下核心功能:
-
高效推理引擎(TurboMind):开发持久批处理(又称连续批处理)、阻塞KV缓存、动态拆分融合、张量并行、高性能CUDA内核等关键特性,确保LLM推理的高吞吐和低延迟。
-
交互式推理模式:通过在多轮对话过程中缓存注意力的k/v,引擎会记住对话历史,从而避免历史会话的重复处理。
-
量化:LMDeploy 支持多种量化方法和量化模型的高效推理。量化的可靠性已在不同尺度的模型上得到验证。

二、环境搭建与基础配置
2-0、环境搭建
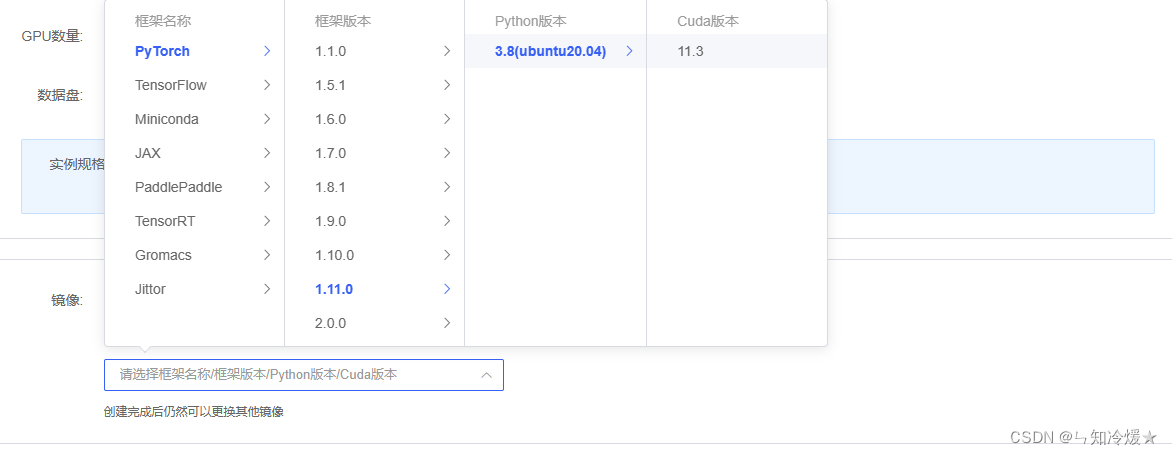
环境:租用autoDL,环境选torch1.11.0,ubuntu20.04,python版本为3.8,cuda版本为11.3,使用v100来进行实验。选择合适的在线平台。

2-1、创建虚拟环境
bash # 请每次使用 jupyter lab 打开终端时务必先执行 bash 命令进入 bash 中
# 创建虚拟环境
conda create -n CONDA_ENV_NAME
# 激活虚拟环境
conda activate CONDA_ENV_NAME
2-2、导入所需要的包
# 升级pip
python -m pip install --upgrade pip
# 下载速度慢可以考虑一下更换镜像源。
# pip config set global.index-url https://mirrors.cernet.edu.cn/pypi/web/simple
# lmdeploy安装,选择全部安装
pip install 'lmdeploy[all]==v0.1.0'
# 将其他依赖包放置在txt文件中并使用命令:pip install -r requirements.txt 来进行安装。
Notice: 依赖包如下所示。
accelerate==0.26.0
addict==2.4.0
aiohttp==3.9.1
aiosignal==1.3.1
aliyun-python-sdk-core==2.14.0
aliyun-python-sdk-kms==2.16.2
altair==5.2.0
annotated-types==0.6.0
async-timeout==4.0.3
attrs==23.2.0
bitsandbytes==0.42.0
blinker==1.7.0
Brotli @ file:///tmp/abs_ecyw11_7ze/croots/recipe/brotli-split_1659616059936/work
cachetools==5.3.2
certifi @ file:///croot/certifi_1700501669400/work/certifi
cffi @ file:///croot/cffi_1700254295673/work
charset-normalizer @ file:///tmp/build/80754af9/charset-normalizer_1630003229654/work
click==8.1.7
contourpy==1.2.0
crcmod==1.7
cryptography @ file:///croot/cryptography_1694444244250/work
cycler==0.12.1
datasets==2.14.7
deepspeed==0.12.6
dill==0.3.7
distro==1.9.0
einops==0.7.0
filelock @ file:///croot/filelock_1700591183607/work
fonttools==4.47.0
frozenlist==1.4.1
fsspec==2023.6.0
func-timeout==4.3.5
gast==0.5.4
gitdb==4.0.11
GitPython==3.1.41
gmpy2 @ file:///tmp/build/80754af9/gmpy2_1645455533097/work
hjson==3.1.0
huggingface-hub==0.17.3
idna @ file:///croot/idna_1666125576474/work
importlib-metadata==6.11.0
Jinja2 @ file:///croot/jinja2_1666908132255/work
jmespath==0.10.0
jsonschema==4.20.0
jsonschema-specifications==2023.12.1
kiwisolver==1.4.5
lagent==0.1.2
markdown-it-py==3.0.0
MarkupSafe @ file:///opt/conda/conda-bld/markupsafe_1654597864307/work
matplotlib==3.8.2
mdurl==0.1.2
mkl-fft @ file:///croot/mkl_fft_1695058164594/work
mkl-random @ file:///croot/mkl_random_1695059800811/work
mkl-service==2.4.0
mmengine==0.10.2
modelscope==1.11.0
mpi4py-mpich==3.1.2
mpmath @ file:///croot/mpmath_1690848262763/work
multidict==6.0.4
multiprocess==0.70.15
networkx @ file:///croot/networkx_1690561992265/work
ninja==1.11.1.1
numpy @ file:///croot/numpy_and_numpy_base_1701295038894/work/dist/numpy-1.26.2-cp310-cp310-linux_x86_64.whl#sha256=2ab675fa590076aa37cc29d18231416c01ea433c0e93be0da3cfd734170cfc6f
opencv-python==4.9.0.80
oss2==2.18.4
packaging==23.2
pandas==2.1.4
peft==0.7.1
Pillow==9.5.0
platformdirs==4.1.0
protobuf==4.25.2
psutil==5.9.7
py-cpuinfo==9.0.0
pyarrow==14.0.2
pyarrow-hotfix==0.6
pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work
pycryptodome==3.20.0
pydantic==2.5.3
pydantic_core==2.14.6
pydeck==0.8.1b0
Pygments==2.17.2
Pympler==1.0.1
pynvml==11.5.0
pyOpenSSL @ file:///croot/pyopenssl_1690223430423/work
pyparsing==3.1.1
PySocks @ file:///home/builder/ci_310/pysocks_1640793678128/work
python-dateutil==2.8.2
pytz==2023.3.post1
pytz-deprecation-shim==0.1.0.post0
PyYAML==6.0.1
referencing==0.32.1
regex==2023.12.25
requests @ file:///croot/requests_1690400202158/work
rich==13.7.0
rpds-py==0.16.2
safetensors==0.4.1
scipy==1.11.4
sentencepiece==0.1.99
simplejson==3.19.2
six==1.16.0
smmap==5.0.1
sortedcontainers==2.4.0
sympy @ file:///croot/sympy_1668202399572/work
tenacity==8.2.3
termcolor==2.4.0
tiktoken==0.5.2
tokenizers==0.14.1
toml==0.10.2
tomli==2.0.1
toolz==0.12.0
torch==2.0.1
torchaudio==2.0.2
torchvision==0.15.2
tornado==6.4
tqdm==4.66.1
transformers==4.34.0
transformers-stream-generator==0.0.4
triton==2.0.0
typing_extensions @ file:///croot/typing_extensions_1690297465030/work
tzdata==2023.4
tzlocal==4.3.1
urllib3 @ file:///croot/urllib3_1698257533958/work
validators==0.22.0
watchdog==3.0.0
xxhash==3.4.1
yapf==0.40.2
yarl==1.9.4
zipp==3.17.0
三、部署
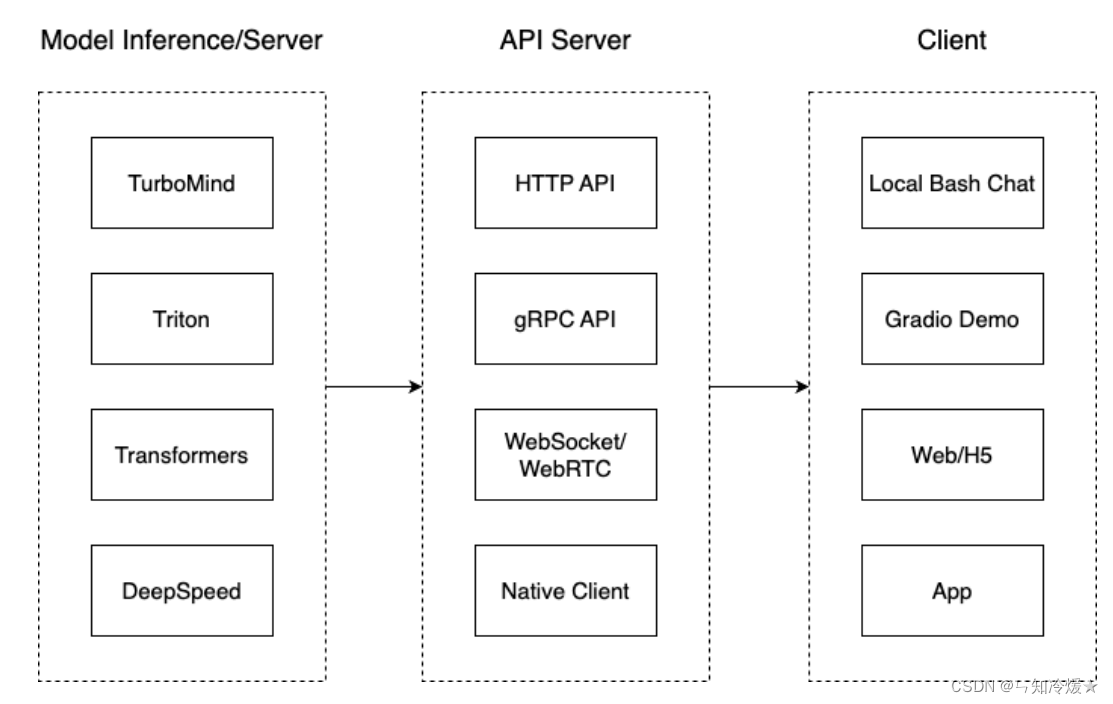
我们把从架构上把整个服务流程分成下面几个模块:
- 模型推理/服务:主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- Client(客户端):可以理解为前端,与用户交互的地方。交互方式可以分为使用本地bash进行交互、使用Gradio构建的demo进行交互、通过网页进行交互、以及通过手机APP进行交互
- API Server。一般作为前端的后端,提供与产品和服务相关的数据和功能支持,即提供API支持。
3-0、模型转换
TurboMind: 是一款关于 LLM 推理的高效推理引擎,基于英伟达的 FasterTransformer 研发而成。它的主要功能包括:LLaMa 结构模型的支持,persistent batch 推理模式和可扩展的 KV 缓存管理器。这里使用TurboMind来推理模型,使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。
3-0-1、在线转换
概述:以下为支持转换的模型类型,以下每一行命令都会启动一个本地对话界面,通过bash可以与LLM进行对话。
# 需要能访问 Huggingface 的网络环境
# 在 huggingface.co 上面通过 lmdeploy 量化的模型,如 llama2-70b-4bit, internlm-chat-20b-4bit
lmdeploy chat turbomind internlm/internlm-chat-20b-4bit --model-name internlm-chat-20b
# huggingface.co 上面其他 LM 模型,如 Qwen/Qwen-7B-Chat
lmdeploy chat turbomind Qwen/Qwen-7B-Chat --model-name qwen-7b
# others:也可以直接启动本地的 Huggingface 模型,如下所示。
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b
如下图所示为使用Qwen-7B-Chat:
3-0-2、离线转换
概述:离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式, 执行完成后将会在当前目录生成一个 workspace 的文件夹。 这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。
# 转换模型(FastTransformer格式) TurboMind, 可以通过 --tp 指定显卡数量,默认一张卡。
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/
3-1、TurboMind 推理+命令行本地对话
概述:使用本地对话(Bash Local Chat)来调用TurboMind,这里的参数是上边离线转换后目录下的workspace文件夹。
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace
如下图所示:输入后两次回车进行对话,退出时输入exit 回车两次即可。

3-2、TurboMind推理+API服务
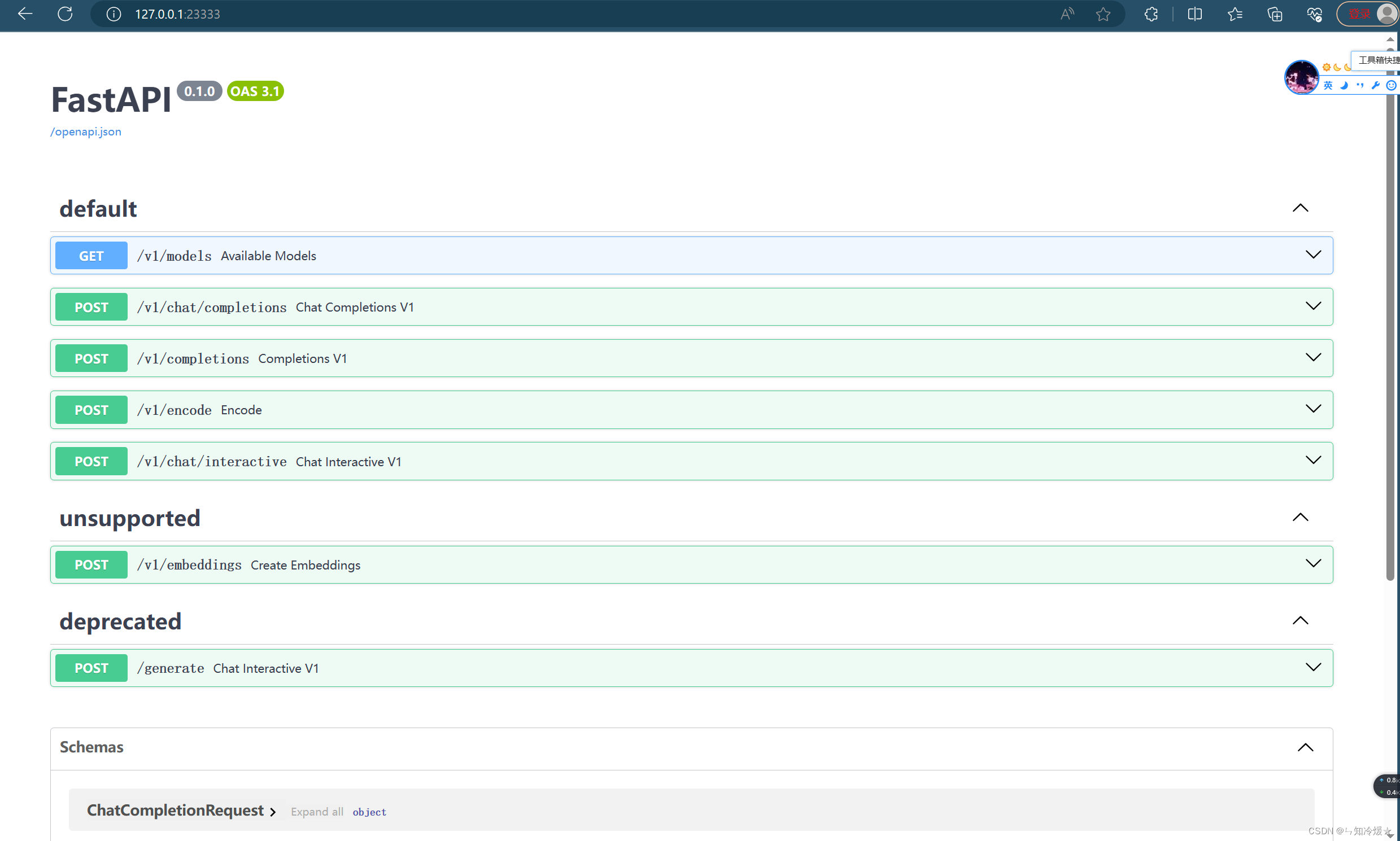
概述:通过以下命令来启动API服务。
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
# 参数分别表示workspace地址、服务地址、端口号、实例数、显卡数量
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
启用成功后如下图所示:
新开一个vs命令行,执行Client命令:
# ChatApiClient+ApiServer(注意是http协议,需要加http)
lmdeploy serve api_client http://localhost:23333
启用成功后如下图所示:可以与服务进行交互。

3-3、网页 Demo 演示
3-3-1、ApiServer+Turbomind+Gradio
# 启动server
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True
Notice:之后将Client映射本地,详细映射方法请见附录2。
配置成功后如下图所示:
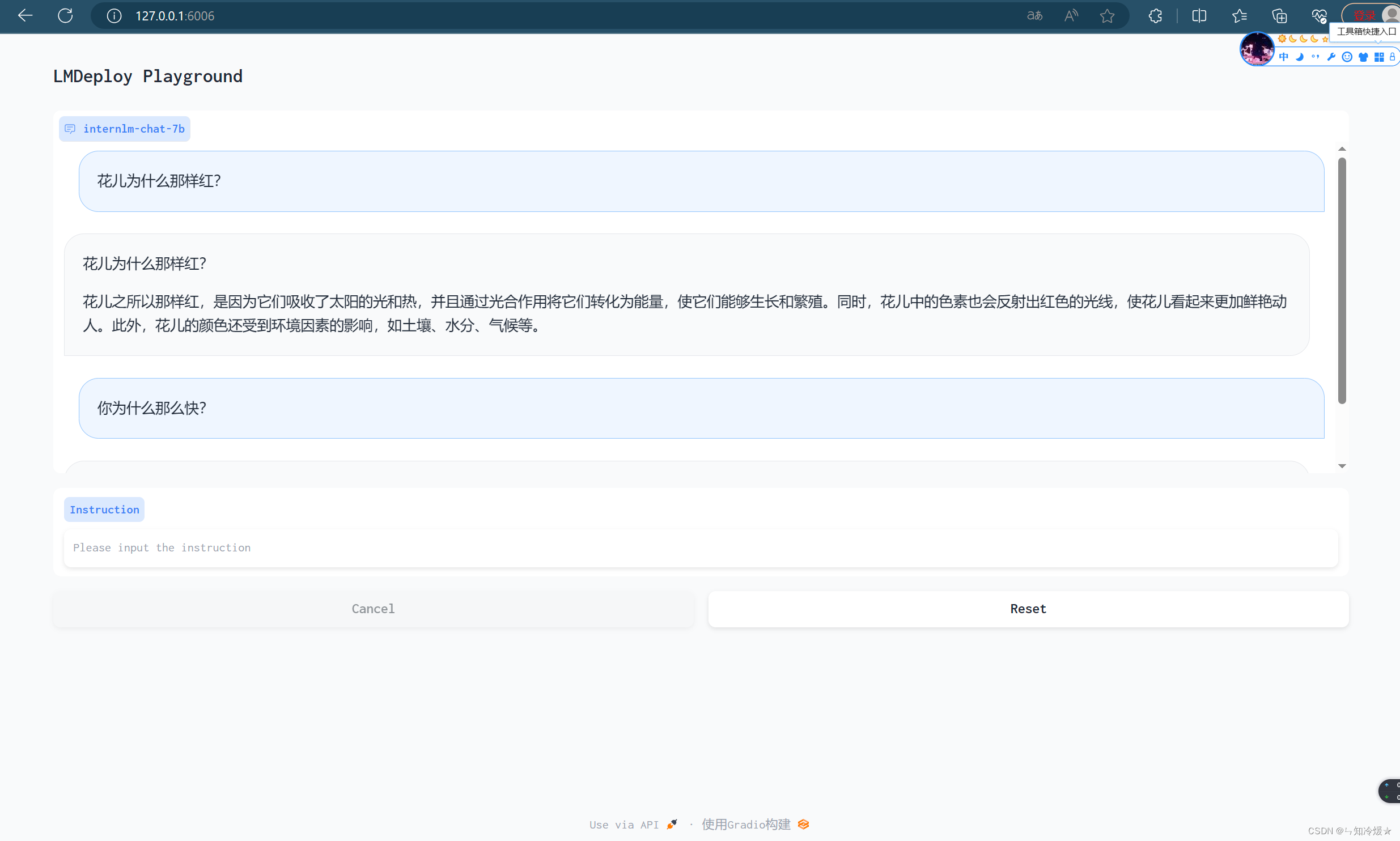
3-3-2、Turbomind+Gradio
概述:跳过API服务,直接与TurboMind 连接,之后映射本地。
# Gradio+Turbomind(local)
lmdeploy serve gradio ./workspace
3-4、TurboMind 推理 + Python 代码集成
概述:Python 直接与 TurboMind 进行交互。
from lmdeploy import turbomind as tm
# load model
# 加载模型并且使用turbomind 来创建实例进行推理
model_path = "/root/share/temp/model_repos/internlm-chat-7b/"
tm_model = tm.TurboMind.from_pretrained(model_path, model_name='internlm-chat-20b')
generator = tm_model.create_instance()
# process query
# 构造输入,对输入进行编码
query = "你好啊兄嘚"
prompt = tm_model.model.get_prompt(query)
input_ids = tm_model.tokenizer.encode(prompt)
# inference
# 进行推理
for outputs in generator.stream_infer(
session_id=0,
input_ids=[input_ids]):
res, tokens = outputs[0]
response = tm_model.tokenizer.decode(res.tolist())
print(response)
四、量化
量化:是一种以参数或计算中间结果精度的下降来换取空间节省(以及同时带来的性能提升)的策略。
正式介绍 LMDeploy 量化方案前,需要先介绍两个概念:
- 计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速。
- 访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
4-1、KV Cache 量化
KV Cache 量化是将已经生成序列的 KV 变成 Int8。
4-1-1、计算 minmax
主要思路是通过计算给定输入样本在每一层不同位置处计算结果的统计情况。
- 对于 Attention 的 K 和 V:取每个 Head 各自维度在所有Token的最大、最小和绝对值最大值。对每一层来说,上面三组值都是 (num_heads, head_dim) 的矩阵。这里的统计结果将用于本小节的 KV Cache。
- 对于模型每层的输入:取对应维度的最大、最小、均值、绝对值最大和绝对值均值。每一层每个位置的输入都有对应的统计值,它们大多是 (hidden_dim, ) 的一维向量,当然在 FFN 层由于结构是先变宽后恢复,因此恢复的位置维度并不相同。这里的统计结果用于下个小节的模型参数量化,主要用在缩放环节
对应命令如下:选择 128 条输入样本,每条样本长度为 2048,数据集选择 C4,输入模型后就会得到上面的各种统计值。
# 计算 minmax
lmdeploy lite calibrate \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./quant_output
4-1-2、通过 minmax 获取量化参数
对应命令如下:获取每一层的 K V 中心值(zp)和缩放值(scale)。
# 通过 minmax 获取量化参数
lmdeploy lite kv_qparams \
--work_dir ./quant_output \
--turbomind_dir workspace/triton_models/weights/ \
--kv_sym False \
--num_tp 1
4-1-3、修改配置
修改 weights/config.ini 文件,把 quant_policy 改为 4 即可。更加详细的介绍请看结尾参考文章。
附录:
1、显卡使用
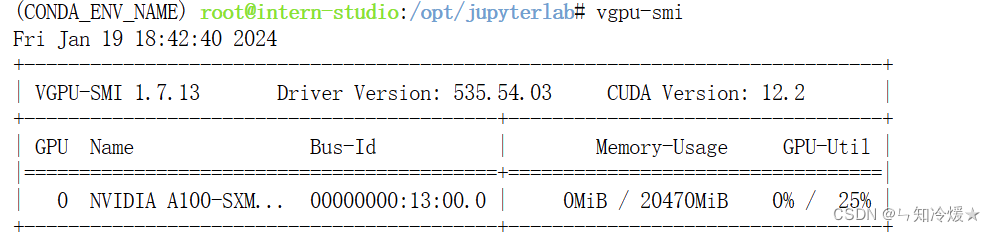
查看显卡使用情况:
vgpu-smi
如下图所示:
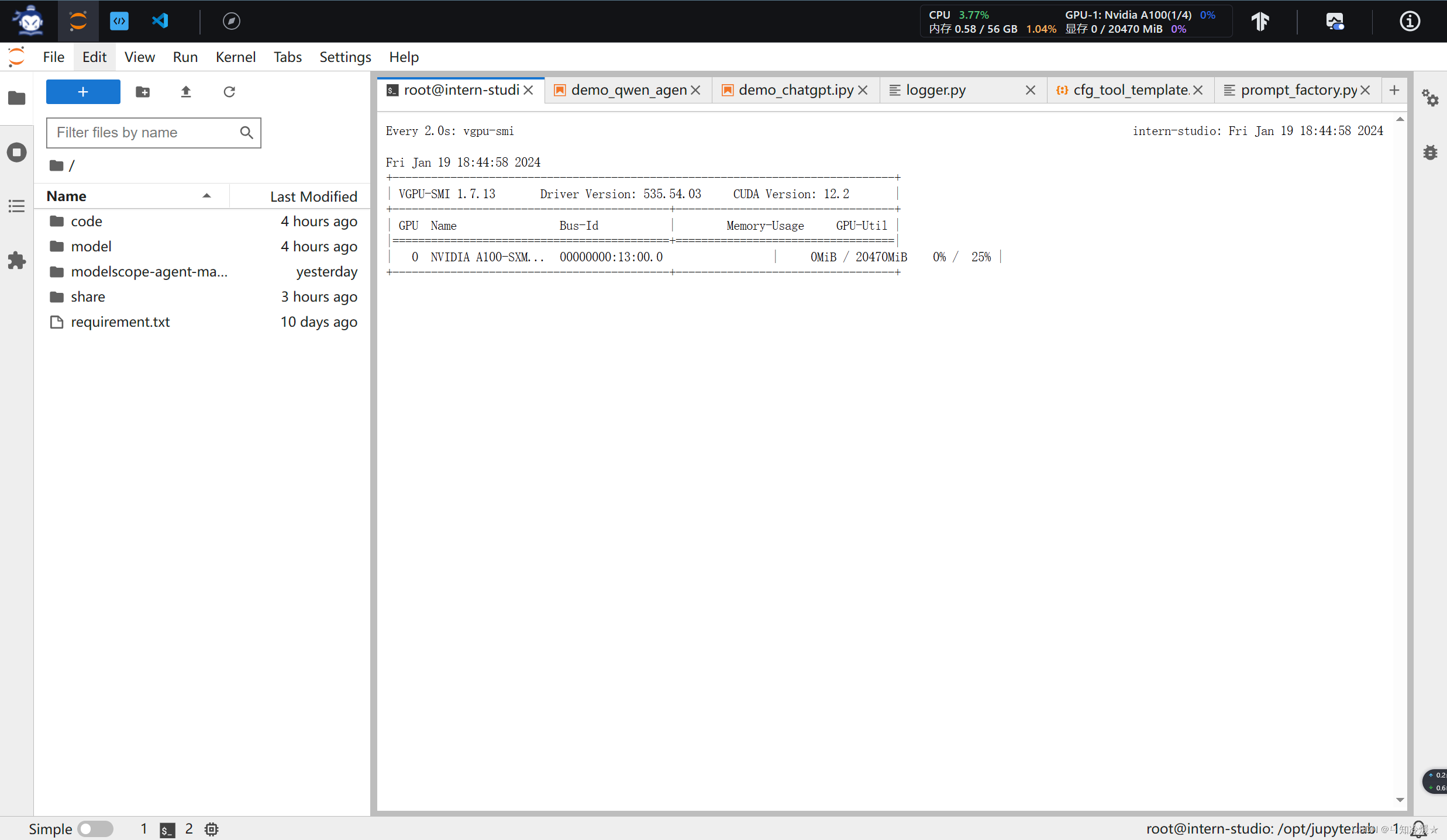
实时检测GPU使用情况:
watch vgpu-smi
如下图所示:
2、配置本地端口(服务器端口映射到本地)
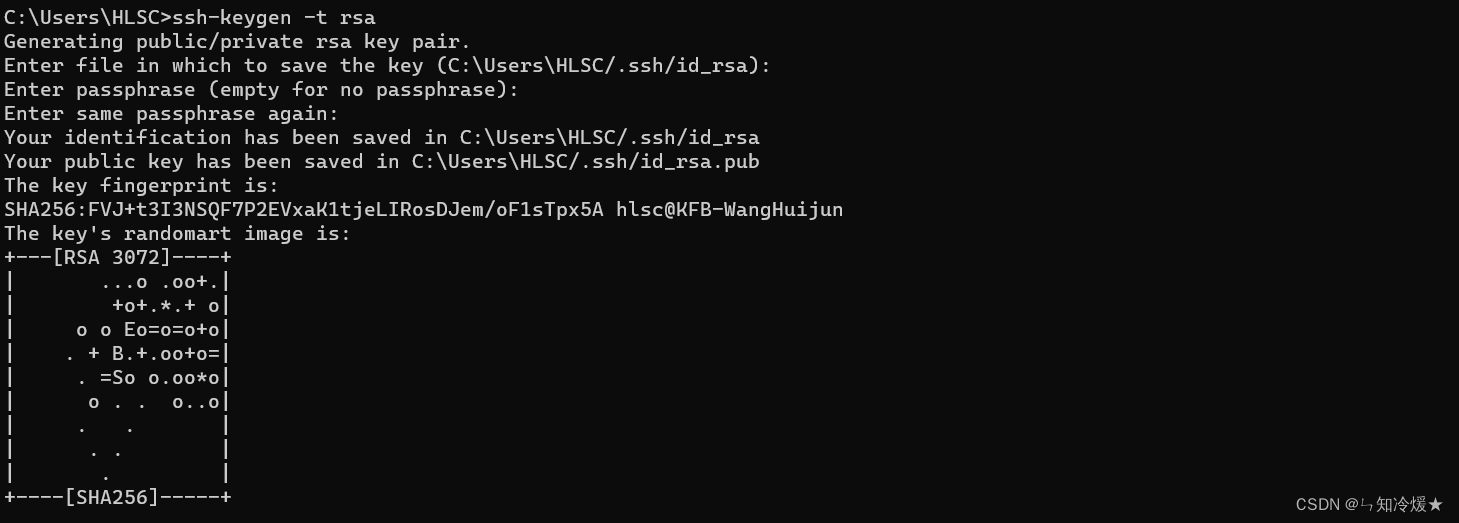
- 步骤一:本地打开命令行窗口生成公钥,全点击回车就ok(不配置密码)。
# 使用如下命令
ssh-keygen -t rsa
默认放置路径如下图所示:
-
步骤二:打开默认放置路径,复制公钥,在远程服务器上配置公钥。
-
步骤三:本地终端输入命令
# 6006是远程端口号(如下图所示,远程启动的端口号为6006),33447是远程ssh连接的端口号,
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 33447
如下图所示:本节API服务启动的页面展示
参考文章:
LMDeploy 的量化和部署.
lmdeploy——github.
仅需一块3090显卡,高效部署InternLM-20B模型.
总结
最近有些许疲惫。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Checklist系列:MySQL自检五十五问,万字整理,推荐收藏
- 养车平台源码定制化需求指南:10种实用功能一览
- 自清洗过滤器工作原理尺寸选型参数,内部结构,压差开关如何调节
- 补题与周总结:leetcode第 376 场周赛
- 两道有挑战的问题(算法村第九关黄金挑战)
- app自动化测试(Android)–触屏操作自动化
- (第29天)Oracle 数据泵传输表空间
- 【STM32单片机】迷宫游戏设计
- Day58|Leetcode 739. 每日温度 Leetcode 496. 下一个更大元素 I
- docker容器部署.NETCore 项目前后分离整过程