轻量化/高效扩散模型文献综述
🎀个人主页: https://zhangxiaoshu.blog.csdn.net
📢欢迎大家:关注🔍+点赞👍+评论📝+收藏??,如有错误敬请指正!
💕未来很长,值得我们全力奔赴更美好的生活!
前言
近年来,计算机科学领域的生成式扩散模型迅猛发展,成为人工智能领域的热门研究方向。这一类模型,如GPT系列,以其强大的语言理解和生成能力,成功地应用于自然语言处理、文本生成、机器翻译等多个领域。然而,随着模型规模的不断扩大和任务复杂性的提高,扩散模型在实时推理上面临着巨大的计算量挑战。本文主要介绍了应对这一挑战近年来的一些经典工作。
尽管生成式扩散模型在各种任务中取得显著成果,但其复杂的计算结构导致了实时推理性能的下降。特别是在资源受限的环境下,例如移动设备或边缘计算平台,模型的大规模参数和计算需求限制了其广泛应用的可能性。为了解决这一问题,研究者们纷纷投入精力,探索扩散模型的压缩方法或寻求更高效的采样策略,以在保持模型性能的同时降低计算开销。
在这一背景下,模型压缩技术成为研究的焦点之一,旨在通过减少模型的参数数量和计算需求来提高实时推理性能。同时,研究人员也在探索更高效的采样方法,以加速生成式扩散模型的推理过程。这一领域的创新和进步将为将生成式扩散模型应用于实际场景提供更为可行和可持续的解决方案。随着技术的不断演进,人们对于解决扩散模型实时推理性能问题的努力将继续推动人工智能领域的发展。
1. Faster Diffusion
- 论文:Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models(南开/哈工大-2023)
- 代码:https://github.com/hutaiHang/Faster-Diffusion
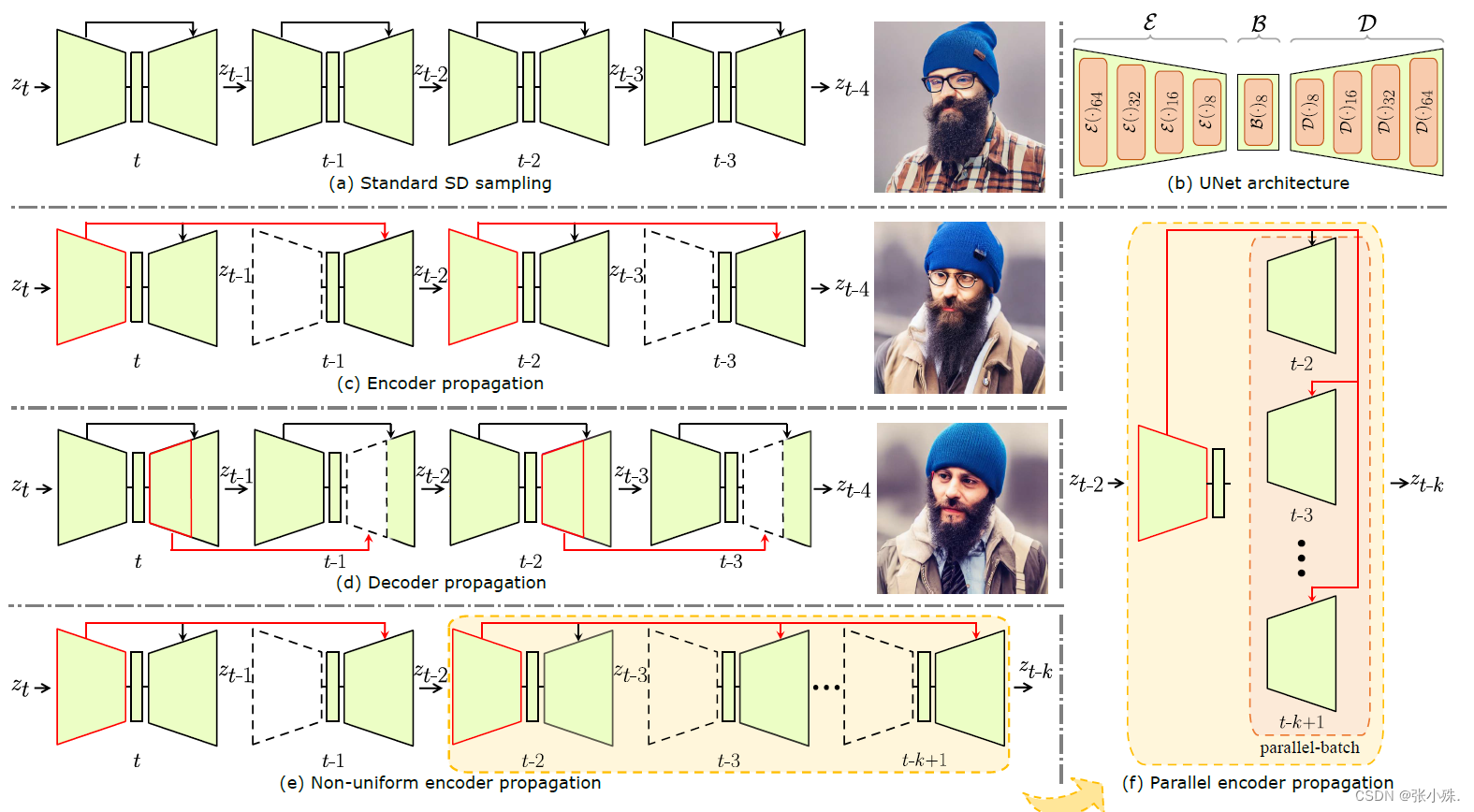
扩散模型中的一个关键组件是用于噪声预测的UNet。虽然一些研究已经探讨了UNet解码器的基本特性,但其编码器在很大程度上仍然未被深入研究。在这项工作中,对UNet编码器的首次全面研究。作者对编码器特征进行了经验分析,并为关于推理过程中它们的变化的重要问题提供了见解。
具体而言,作者发现编码器特征变化较为平缓,而解码器特征在不同时间步之间表现出显著的变化。这一发现启发作者在某些相邻时间步骤省略编码器,并在解码器中循环重复使用先前时间步骤的编码器特征。从而引入了一个简单而有效的编码器传播方案,以加速扩散采样用于各种任务。能够在某些相邻时间步骤并行执行解码器。此外,引入了一种先验噪声注入方法,以改善生成图像的纹理细节。除了标准的文本到图像任务,作者还在其他任务上验证了方法:文本到视频,个性化生成和参考引导生成。在不使用任何知识蒸馏技术的情况下,此方法方法分别将Stable Diffusion(SD)和DeepFloyd-IF模型的采样加速了41%和24%,同时保持了高质量的生成性能。
2. Moblie Diffusion
- 论文:MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices(谷歌—2023)
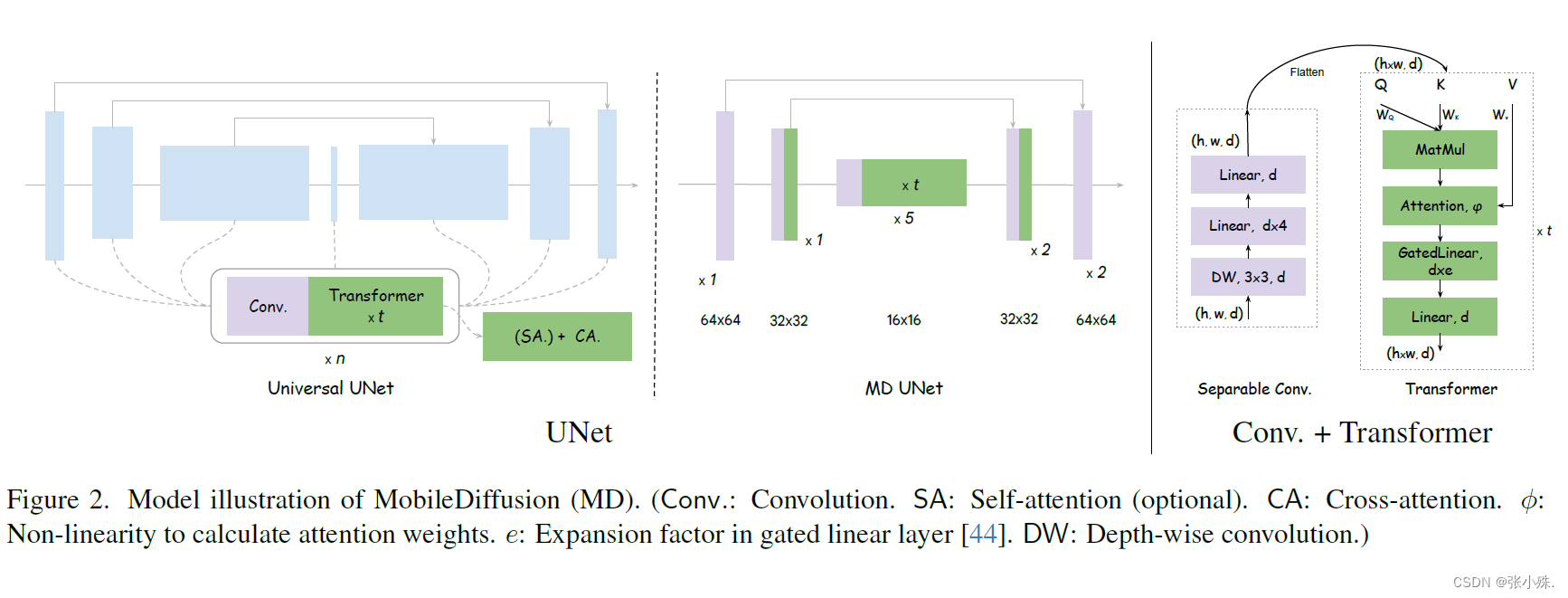
在移动设备上部署大规模文本到图像扩散模型受到其庞大的模型大小和慢速推理的阻碍。在本文中,作者提出了MobileDiffusion,这是一种通过在架构和采样技术方面进行广泛优化而获得的高效文本到图像扩散模型。对模型架构设计进行了全面的审查,以减少冗余,增强计算效率,并最小化模型的参数数量,同时保持图像生成质量。此外,在MobileDiffusion上采用了蒸馏和扩散-GAN微调技术,分别实现了8步和1步的推理。通过定量和定性的实证研究,我们展示了所提出技术的有效性。MobileDiffusion在移动设备上为生成一个512×512的图像实现了卓越的次秒级推理速度,创立了一个新的技术水平。
3. Q-Diffusion
- 论文:Q-Diffusion: Quantizing Diffusion Models(伯克利-2023 ICCV)
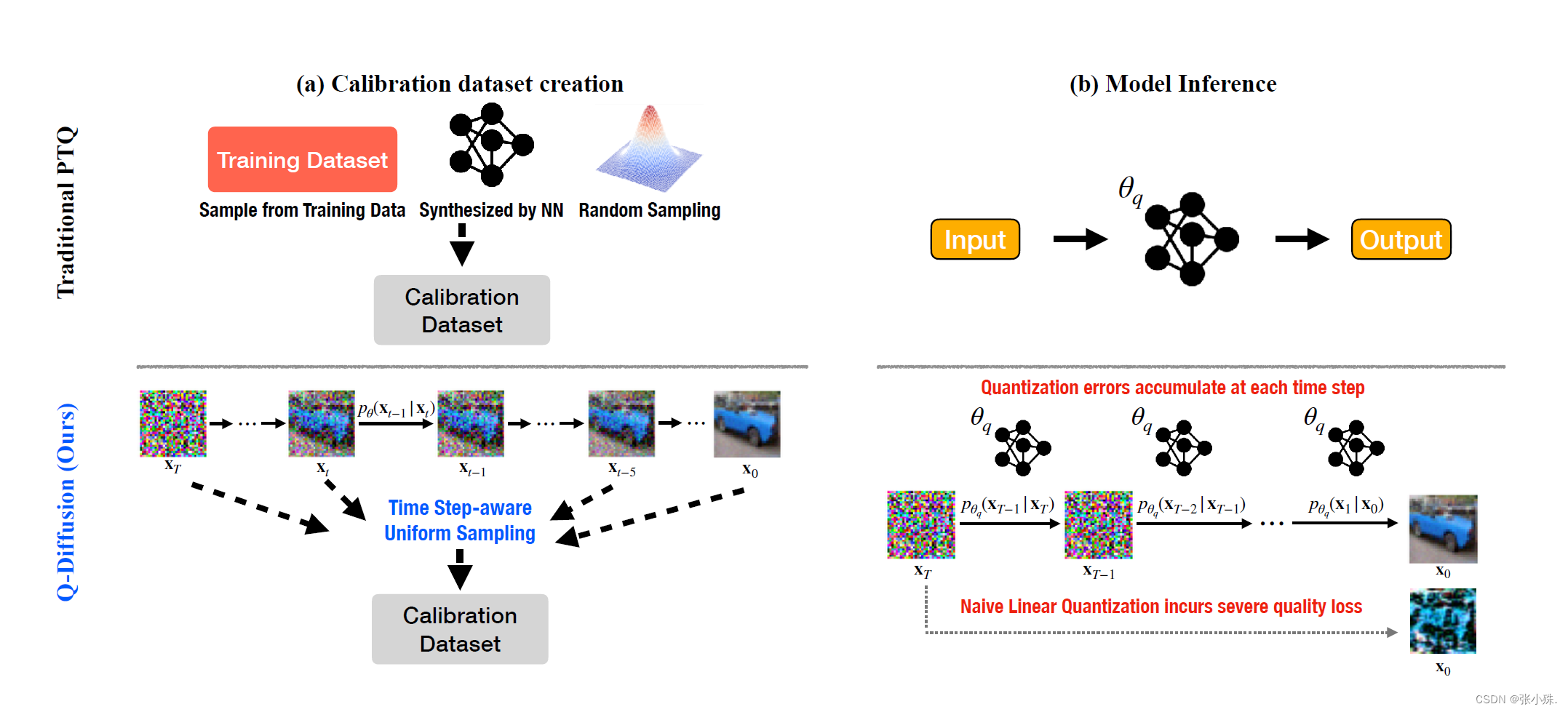
扩散模型通过使用深度神经网络进行迭代噪声估计,在图像合成方面取得了巨大成功。然而,噪声估计模型的慢推理速度、高内存消耗和计算强度阻碍了扩散模型的有效应用。尽管后训练量化(PTQ)被认为是其他任务的首选压缩方法,但它不能直接在扩散模型上使用。
作者提出了一种新颖的PTQ方法,专门针对扩散模型的独特多时间步流水线和模型架构,通过压缩噪声估计网络来加速生成过程。首先作者确定扩散模型量化的关键困难在于多个时间步长上噪声估计网络输出分布的变化,以及噪声估计网络内的快捷层呈双峰激活分布。通过时间步感知校准和分裂快捷量化来解决这些挑战。实验证明,提出的方法能够在没有训练的情况下将全精度的无条件扩散模型量化为4位,同时保持相当的性能(与传统PTQ相比,FID变化最多为2.34,而传统PTQ则超过100)。此方法还可应用于文本引导的图像生成,首次以4位权重运行稳定的扩散模型,保持高生成质量。
4. LWTDM
- 论文:Efficient Remote Sensing Image Super-Resolution via Lightweight Diffusion Models(自动化所—GRSL 2023)
- 代码:https://github.com/Suanmd/LWTDM
随着扩散模型的出现,图像生成经历了重大的进步。在超分辨率任务中,扩散模型在生成更真实样本方面超过了基于GAN的方法。然而,这些模型也伴随着显著的成本:去噪网络依赖于庞大的U-Net,使其在高分辨率图像上计算密集,而扩散模型中的大量采样步骤导致推理时间延长。这种复杂性限制了它们在遥感中的应用,因为在这些场景中对高分辨率图像的需求很高。
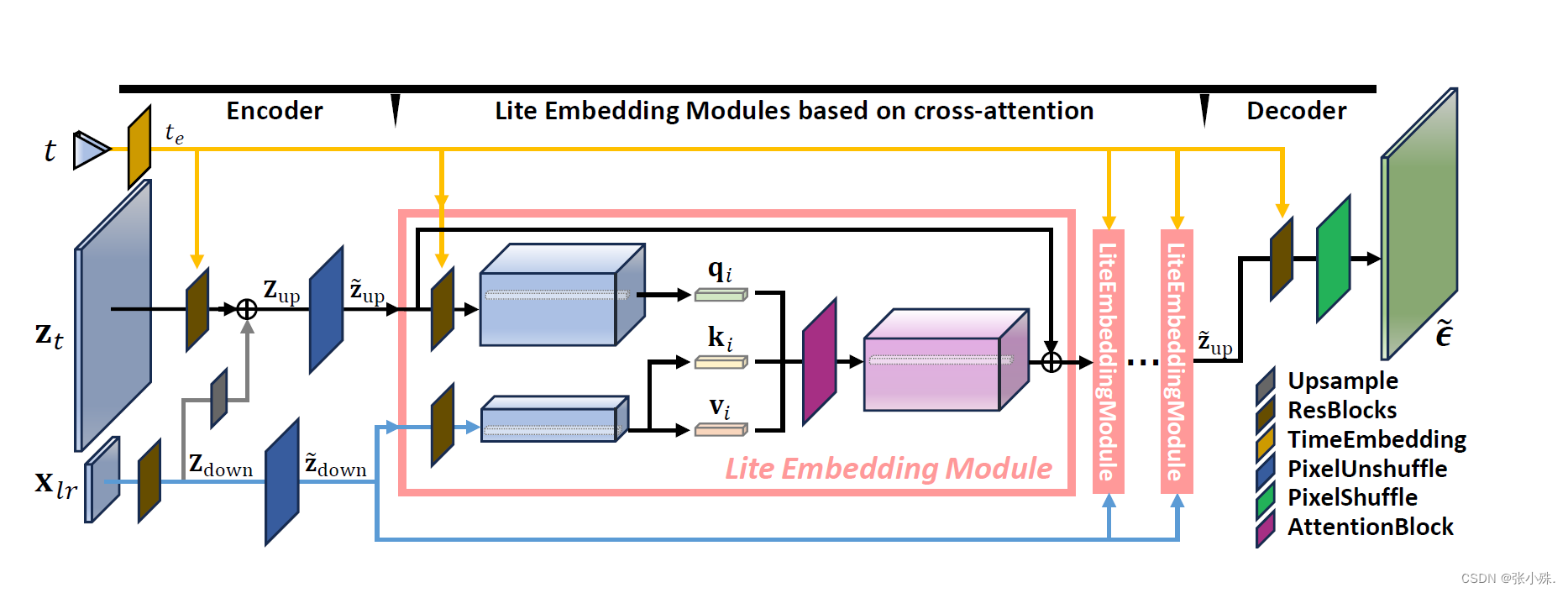
为了解决这个问题,作者提出了一种轻量级的扩散模型,LWTDM,它简化了去噪网络,并通过基于交叉注意力的编码器-解码器架构有效地整合了条件信息。此外,LWTDM作为一个创新模型,引入了来自去噪扩散隐式模型(DDIM)的加速采样技术。这种整合涉及对采样步骤的精心选择,以确保生成图像的质量。实验证实,LWTDM在精度和感知质量之间取得了良好的平衡,而其更快的推理速度使其适用于具有特定要求的多样遥感场景。
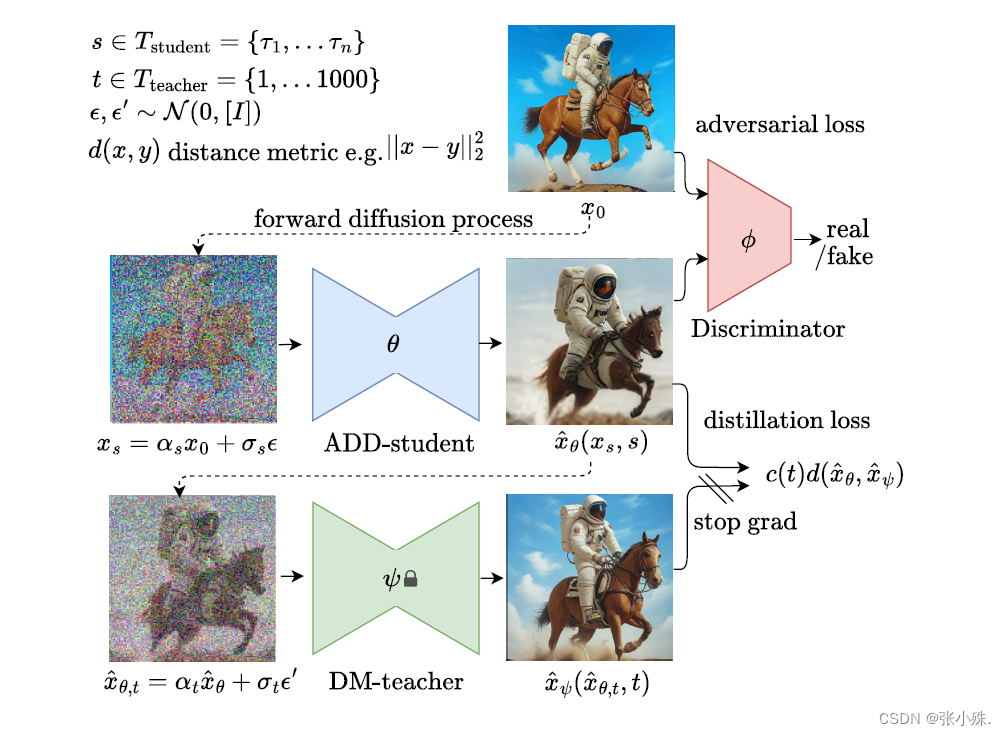
5. ADD
- 论文:Adversarial Diffusion Distillation(Stability AI—2023)
对抗性扩散蒸馏(ADD),一种新颖的训练方法,可以在仅1-4步内高效地对大规模基础图像扩散模型进行采样,同时保持高图像质量。作者使用得分蒸馏来利用大规模现成的图像扩散模型作为教师信号,结合对抗损失,以确保即使在一到两个采样步骤的低阶段,图像仍具有高保真度。文中分析显示,模型在单步中明显优于现有的少步方法(GAN、潜在一致性模型),并在仅四步的情况下达到了最先进的扩散模型(SDXL)的性能。ADD是第一个通过基础模型解锁单步、实时图像合成的方法。
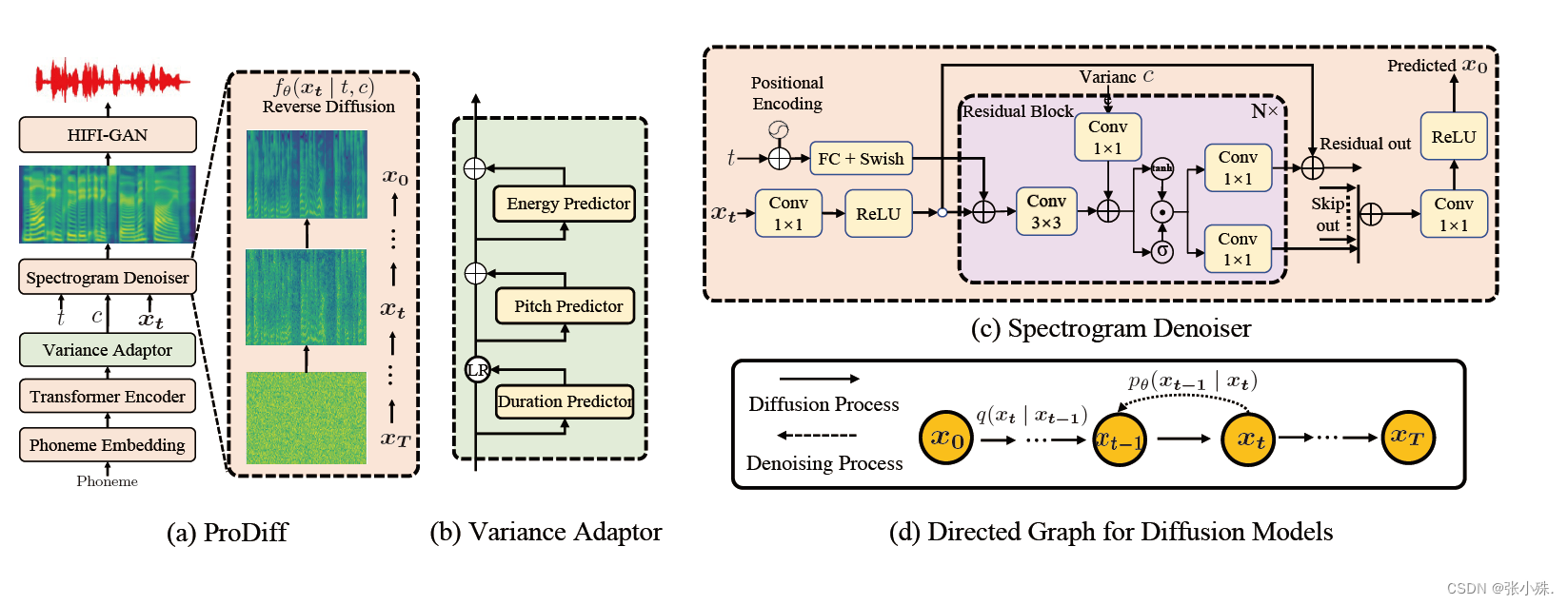
6. ProDiff
- 论文:ProDiff: Progressive Fast Diffusion Model for High-Quality Text-to-Speech(浙江大学-2022 MM)
去噪扩散概率模型(DDPMs)最近在许多生成任务中取得了领先的性能。然而,由于继承的迭代采样过程成本,它们在文本转语音部署中的应用受到了阻碍。通过对扩散模型参数化的初步研究,作者发现以前的基于梯度的TTS模型需要数百或数千次迭代才能保证高样本质量,这对于加速采样构成了挑战。
在这项工作中,作者提出了ProDiff,一种用于高质量文本转语音的渐进快速扩散模型。与以往估计数据密度梯度的工作不同,ProDiff通过直接预测干净数据来参数化去噪模型,以避免在加速采样中出现明显的质量降级。为了解决减少扩散迭代次数带来的模型收敛挑战,ProDiff通过知识蒸馏减少目标站点上的数据方差。具体而言,去噪模型使用N步DDIM教师生成的梅尔频谱图作为训练目标,并将该行为提炼到一个具有N/2步的新模型中。因此,它允许TTS模型进行精确的预测,并进一步将采样时间减少数个数量级。
实验评估表明,ProDiff只需2次迭代即可合成高保真度的梅尔频谱图,同时保持与使用数百步的最先进模型相竞争的样本质量和多样性。ProDiff在单个NVIDIA 2080Ti GPU上实现了24倍于实时的采样速度,使扩散模型首次实际应用于文本转语音合成部署。文中广泛消融研究表明,ProDiff中的每个设计都是有效的,并进一步展示ProDiff可以轻松扩展到多说话人设置。
总结
文中有不对的地方欢迎指正。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python算法例31 阶乘尾部零的个数
- signaltap立即触发的错误解决方法
- CSS 动态提示框
- 【JavaEE进阶】 图书管理系统开发日记——壹
- Linux 系统惨遭黑客入侵,我们如何挽救?
- 网络安全产品之认识入侵防御系统
- 缓冲流得到
- 20240103-通过布局让自己的生活有有意义人生有价值
- Spring:StopWatch
- JAVA毕业设计118—基于Java+Springboot的宠物寄养管理系统(源代码+数据库)