爬取咚漫漫画
发布时间:2024年01月24日
'''
一、数据来源分析
1.确定自己的需求:
采集哪个网站的上面的数据内容
正常的访问流程:
1.选中漫画--->目录页面 (请求列表页面,获取所有的章节链接)
2.选择一个漫画内容--->漫画页面 (请求章节链接,获取所有漫画内容url)
3.看漫画内容(保存数据 ,漫画图片内容保存下来)
二、代码实现过程(开发者工具抓包分析)
1.查看漫画图片url地址,是什么样子的
2.分析url地址在哪里
'''
import requests
import re
import os
index = 0
url = 'https://www.dongmanmanhua.cn/BOY/landuoshaoyedejuexing/list?title_no=2237' # 某一漫画主页地址
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
# print(response.text)
chapter_name_list = re.findall('width="77" height="73" alt="(.*?)">',response.text) # 提取漫画章节名
href_list = re.findall('data-sc-name="PC_detail-page_related-title-list-item".*?href="(.*?)"',response.text,re.S) # 提取章节的url地址
name = re.findall('<title>(.*?)_官方在线漫画阅读-咚漫漫画</title>',response.text) # 提取漫画名称
filename = f'{name}\\'
if not os.path.exists(filename):
os.mkdir(filename) # 创建一个文件夹
for chapter_name,href in zip(chapter_name_list,href_list): # 便利章节url地址列表
href = 'https:'+href
# print(chapter_name,href)
img_data = requests.get(url=href,headers=headers).text # 获得章节页面代码
img_url_list = re.findall('alt="image" class="_images _centerImg" data-url="(.*?)"',img_data) # 得到图片的url地址,单纯访问会遇到403 Forbidden
new_headers = {
"Referer":
"https://www.dongmanmanhua.cn/",
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
} # 在访问图片地址前加上refer防盗链
for img_url in img_url_list: # 遍历图片url地址
img_content = requests.get(url=img_url,headers=new_headers).content
index = index+1
with open(filename+chapter_name+str(index)+'.jpg',mode='wb') as f: # 下载图片二进制数据
f.write(img_content)运行结果:
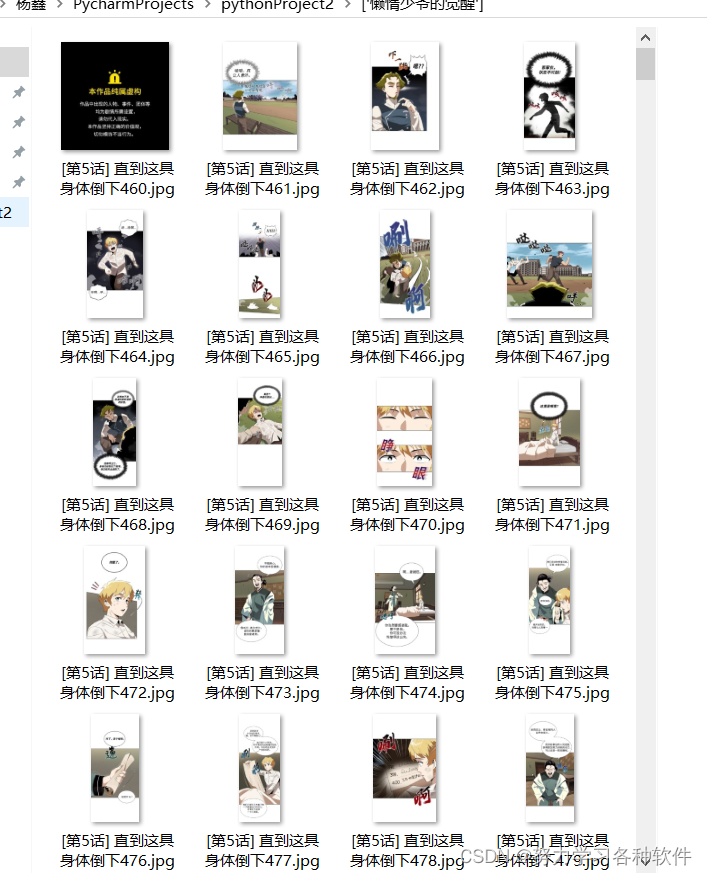 ?
?
总结:
1.获得图片url地址,如果访问遇到403 Forbidden 在下载图片时,要加上防盗链refer
对代码进行改进:
import requests
import re
import os
def get_html(html_url):
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=html_url,headers=headers).text
return response
def get_info(response):
chapter_name_list = re.findall('width="77" height="73" alt="(.*?)">', response) # 提取漫画章节名
href_list = re.findall('data-sc-name="PC_detail-page_related-title-list-item".*?href="(.*?)"', response,
re.S) # 提取章节的url地址
name = re.findall('<title>(.*?)_官方在线漫画阅读-咚漫漫画</title>', response) # 提取漫画名称
return chapter_name_list,href_list,name
def get_img_data(href_list):
new_img_url_list = []
for href in href_list:
href = 'https:'+href
img_data = get_html(href)
img_url_list = re.findall('alt="image" class="_images _centerImg" data-url="(.*?)"',
img_data) # 得到图片的url地址,单纯访问会遇到403 Forbidden
for img_url in img_url_list:
new_img_url_list.append(img_url)
return new_img_url_list
def save(name,img_url_list):
filename = f'{name}\\'
if not os.path.exists(filename):
os.mkdir(filename)
index = 0
new_headers = {
"Referer":
"https://www.dongmanmanhua.cn/",
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
} # 在访问图片地址前加上refer防盗链
for img_url in img_url_list:
img = requests.get(url=img_url,headers=new_headers).content
index = index+1
with open(filename+str(index)+'.jpg',mode='wb') as f:
f.write(img)
if __name__ == '__main__':
response = get_html('https://www.dongmanmanhua.cn/BOY/landuoshaoyedejuexing/list?title_no=2237')
chapter_name_list,href_list,name = get_info(response)
img_url_list = get_img_data(href_list)
save(name,img_url_list)下载的很慢,怎么写代码让程序运行的更快呢??
?
文章来源:https://blog.csdn.net/m0_57265868/article/details/135829960
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 50.常用shell之 chmod - 更改文件权限 的用法及衍生用法
- Deep MultimodalLearningA survey on recent advances and trends
- 论文精读:EVA-CLIP Improved Training Techniques for CLIP
- 北京工业元宇宙赋能新型工业化,推动工业制造业数字化转型发展
- 卷积层里的多输入与多输出通道(channel)
- Python如何使用Excel文件
- Docker
- 写在学习webkit过程的前面
- 门禁管理:我才知道这个技术,可以如此高效!
- Linux终端常见用法总结