机器学习-协同过滤
1、协同过滤要解决的问题
协同过滤算法主要用于推荐系统,推荐系统是信息过载所采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品。一些人的“选择恐惧症”、没有明确需求的人。
解决如何从大量信息中找到自己感兴趣的信息。
解决如何让自己生产的信息脱颖而出,受到大众的喜爱。
就相当于物以类聚,人以群分。

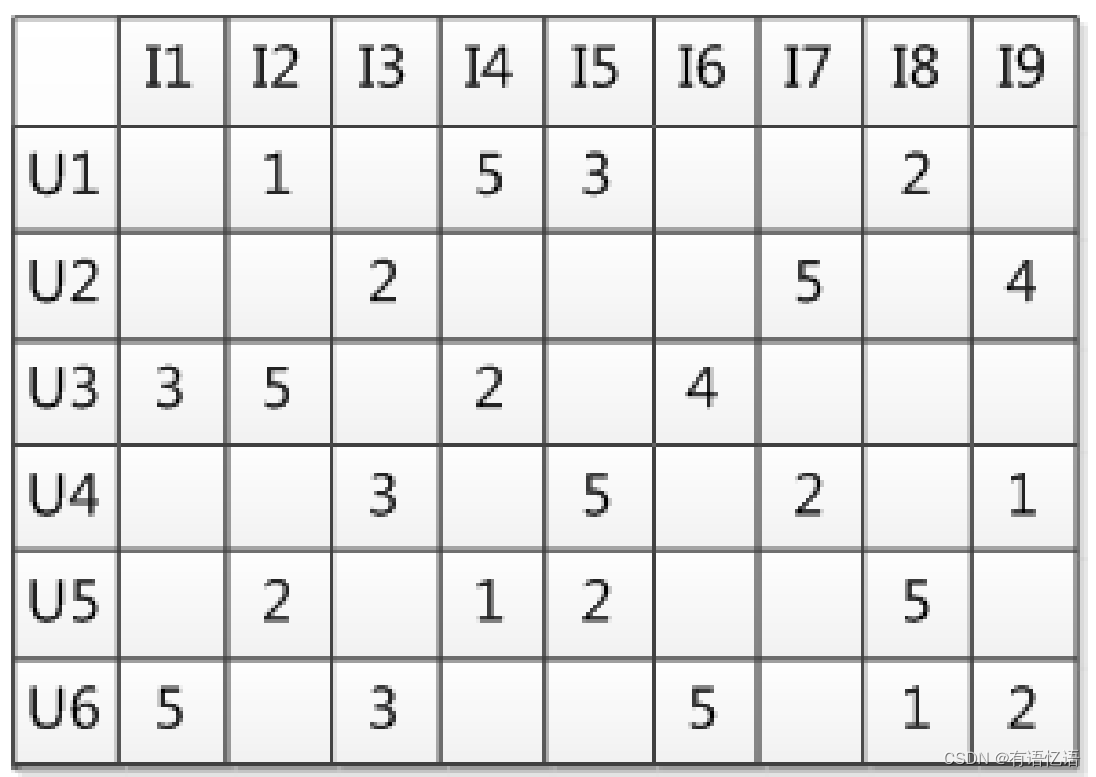
用户ID、物品ID、偏好值
偏好值就是用户对物品的喜爱程度,推荐系统所做的事就是根据这些数据为用户推荐他还没有见过的物品,并且猜测这个物品用户喜欢的概率比较大。
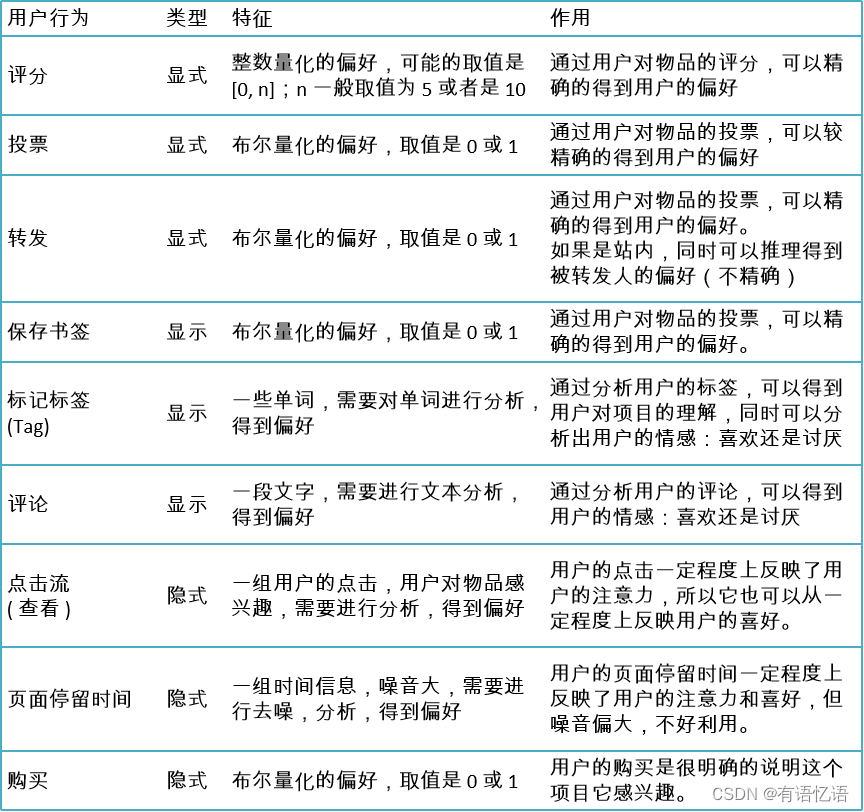
用户ID和物品ID一般通过系统的业务数据库就可以获得,偏好值的采集一般会有很多办法,比如评分、投票、转发、保存书签、页面停留时间等等,然后系统根据用户的这些行为流水,采取减噪、归一化、加权等方法综合给出偏好值。一般不同的业务系统给出偏好值的计算方法不一样。
协同是什么意思?
就是类似的几个实体,比较相同,有相同的方面。
过滤是什么意思?
就是把相同的、类似的物品或者人过滤出来。
基本思想
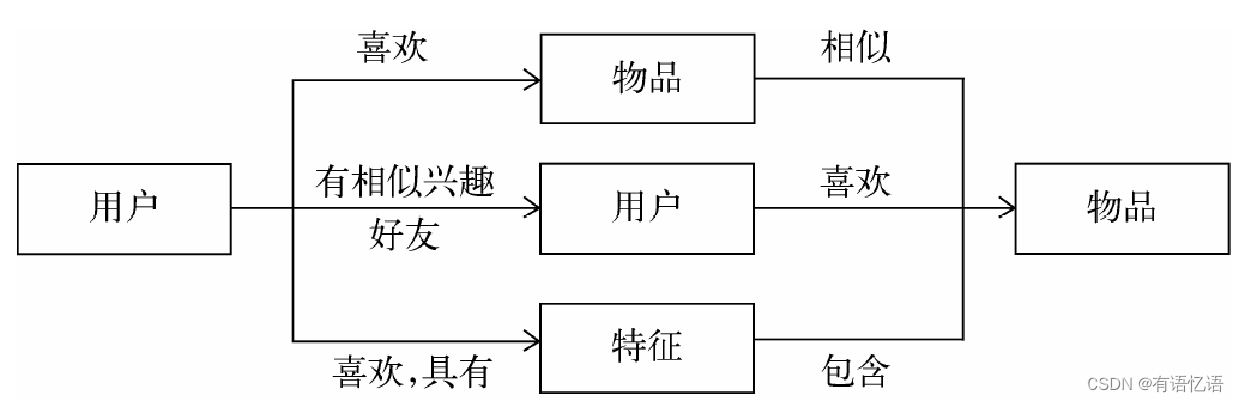
第一种方式是利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品。
第二种方式是利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品。
第三种方式是利用用户和物品的特征信息,给用户推荐那些具有用户喜欢的特征的物品。
2、相似度度量
物品A与物品B之间的相似度通过A、B特有的特征向量来度量
度量方法有很多
欧氏距离:
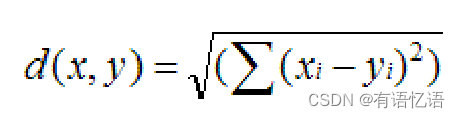
余弦相似度:
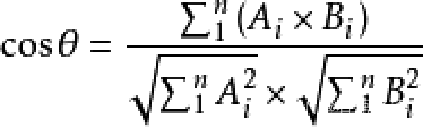
3、邻域大小
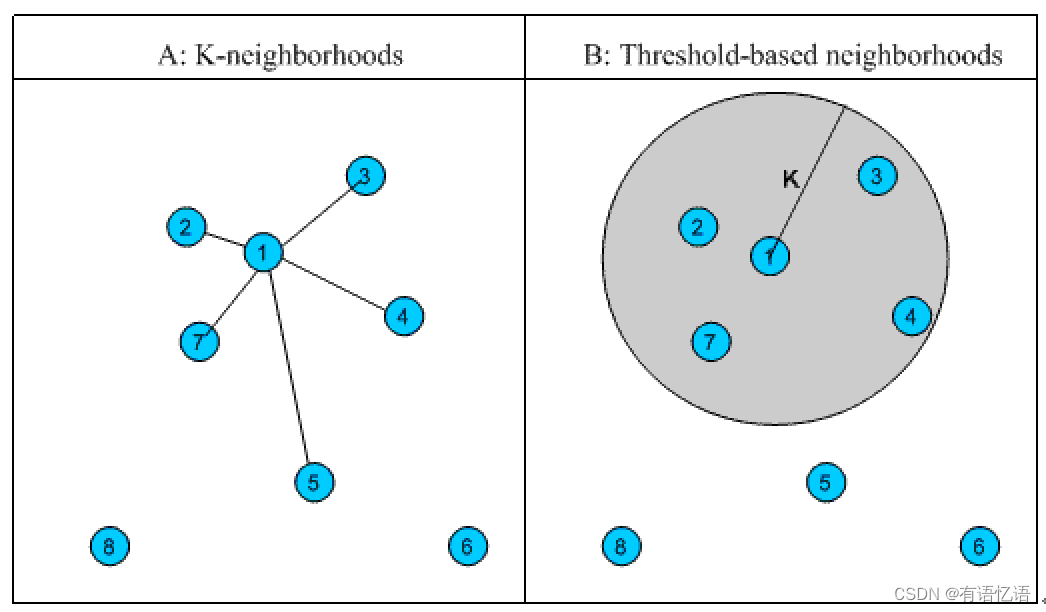
有了相似度的比较,那么比较多少个用户或者物品为好呢?一般会有基于固定大小的邻域以及基于阈值的领域。具体的数值一般是通过对模型的评比分数进行调整优化。
4、基于用户的CF


5、基于物品的CF
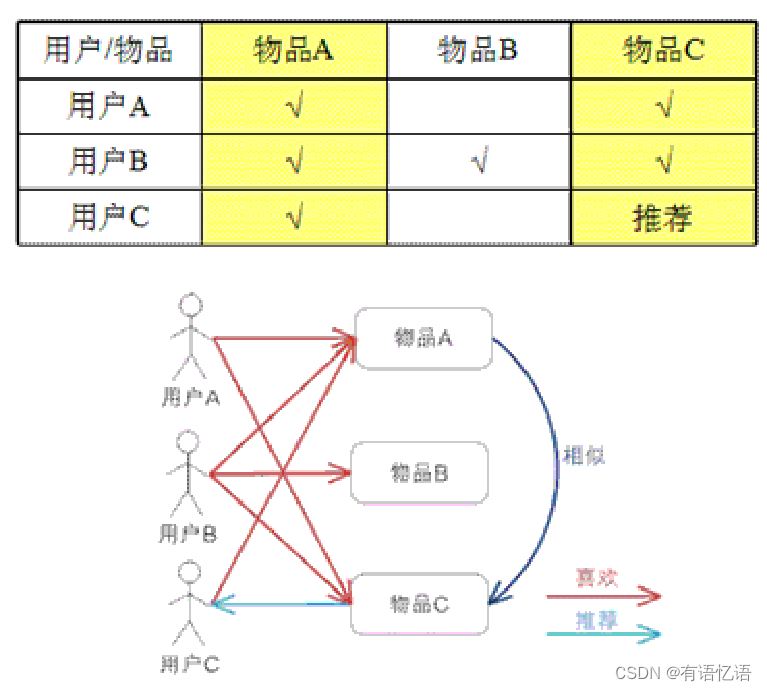


6、基于LFM思想的矩阵分解-ALS
思想是什么?
投资顾问给用户推荐理财产品,推荐哪个?
A:我手上的这一个VIP客户,做事比较谨慎、不爱冒风险,不是冲动型客户。
B:那这款理财产品,虽然收益比较高,但投资大、风险也比较高,估计不适合他。
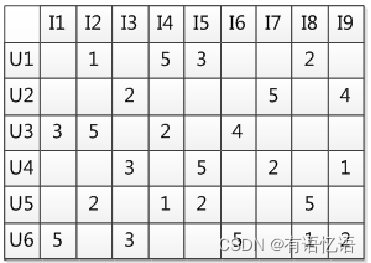

隐语义向量
既然要打分,那么?
(潜在特征模型)隐语义模型
P:用户是不是有一些隐含的特征?
Q:物品是不是有一些隐含的特征?
ALS优化
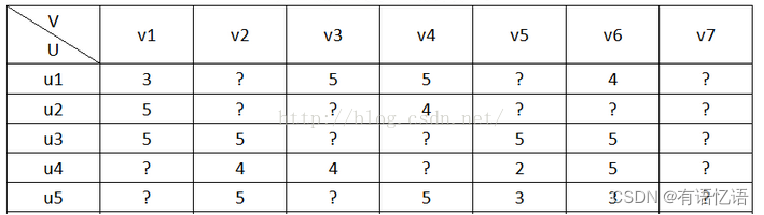
既然要打分,那么?
损失函数:吉洪诺夫正则化

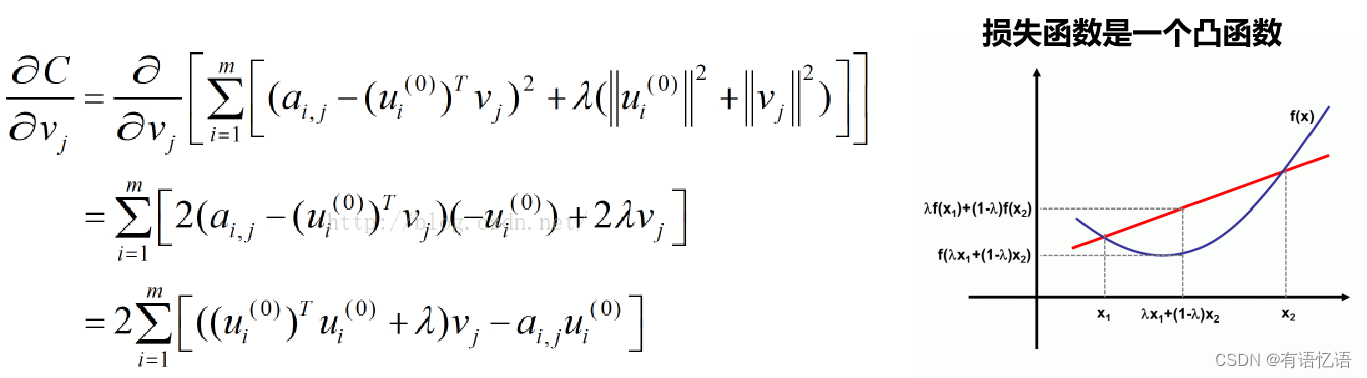
7、协同过滤推荐架构
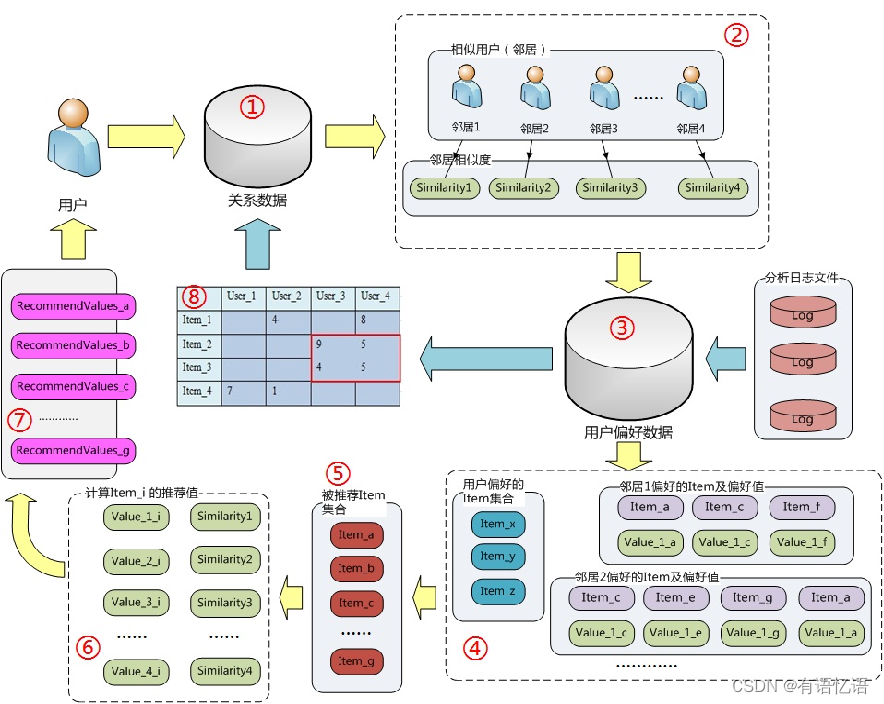
①.?查询的是与该用户相似的用户,所以一来直接查了关系数据源。以及相似用户与该用户的相似度。
②.?对数据集进行优化,得到相似用户和相似度。
③.? 查询关系数据源,得到相似用户即邻居偏好过的物品;如步骤④;图中由于空间小,没有把所有邻居的偏好关系都列出来,用……表示。其次还要得到该用户偏好过的物品集合。
?④.?被推荐的Item集合是由该用户的所有邻居的偏好过的物品的并集,同时再去掉该用户自己偏好过的物品。作用就是得到你的相似用户喜欢的物品,而你还没喜欢过的。
?⑤.?集合优化同基于物品的协同过滤算法的步骤②。
?⑥.?也是对应类似的,依次计算被推荐集合中Item_i 的推荐值,计算的方式略有不同,Value_1_i表示邻居1对,Item_i的偏好值,乘以该用户与邻居1的相似度 Similarity1;若某个邻居对Item_i偏好过,就重复上述运算,然后取平均值;得到Item_i的推荐值。
⑦、⑧.?与上一个算法的最后两部完全类似,只是步骤??⑧你竖着看,判断两个用户相似的法子和判断两个物品相似的法子一样。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 为什么不直接public,多此一举用get、set,一文给你说明白
- SpringMVC获取参数与页面跳转
- 鸿蒙Harmony(十一)Stage模型
- 基于SpringBoot+Vue的实验室耗材管理系统设计实现(源码+lw+部署文档+讲解等)
- C++&Python&C# 三语言OpenCV从零开发(4):视频流读取
- TA百人计划学习笔记 1.2.3.1 P矩阵补充
- MySQL-多表查询
- 小程序基础学习(请求封装)(重点,核心)
- 人工智能 RL 算法边缘服务器
- 《MCtalk·CEO对话》正式上线!首期对话高成资本