hadoop集群环境搭建
1、版本描述:
hadoop-2.7.0、zookeeper-3.3.2
下载链接:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz
https://archive.apache.org/dist/hadoop/zookeeper/zookeeper-3.3.2/zookeeper-3.3.2.tar.gz
其他涉及的安装包可以从我分享的网盘中下载:
链接: https://pan.baidu.com/s/1t6PZwbtzwk0qsRlbEbsd4A
提取码: p4px
2、环境描述:
| ip | 主机名 | 配置 | 磁盘 | 操作系统 |
| 10.231.20.4 | minganrizhi-4 | 32核 256G内存 | 3T | Red Hat 7.3 |
| 10.231.20.3 | minganrizhi-3 | 32核 256G内存 | 3T | Red Hat 7.3 |
| 10.209.67.2 | minganrizhi-2 | 48核 376G内存 | 3T | BigCloud 8.2.2107 |
| 10.209.67.1 | minganrizhi-1 | 48核 376G内存 | 3T | BigCloud 8.2.2107 |
3、官网集群安装参考
Apache Hadoop 2.10.2 – Hadoop Cluster Setup
4、服务安装规划
| ip | 主机名 | 配置 | NN | DN | JN | ZKFC | ZK | RM | NM |
| 10.231.20.4 | minganrizhi-4 | 32核 256G内存 | √ | √ | √ | ||||
| 10.231.20.3 | minganrizhi-3 | 32核 256G内存 | √ | √ | √ | √ | √ | ||
| 10.209.67.2 | minganrizhi-2 | 48核 376G内存 | √ | √ | √ | √ | √ | √ | |
| 10.209.67.1 | minganrizhi-1 | 48核 376G内存 | √ | √ | √ | √ | √ | √ |
5、创建安装用户
useradd hhs
passwd hhs
6、配置域名映射
各个节点执行
vi /etc/hosts
10.231.20.4 minganrizhi-4
10.231.20.3 minganrizhi-3
10.209.67.2 minganrizhi-2
10.209.67.1 minganrizhi-1
7、配置无密钥登录
每个节点切换到 hhs 用户生成密钥
su - hhs
ssh-keygen -t rsa
执行命令后会在~目录下生成.ssh文件夹,里面包含id_rsa和id_rsa.pub两个文件。
原则上配置启动节点到其他节点的无密钥登录和两个NN的无密钥登录就可以了,为了后面安装方便,我们都配置下
cd .ssh
cp id_rsa.pub authorized_keys
依次将authorized_keys 复制到其他节点并把该节点的id_rsa.pub 添加到 authorized_keys,再把最终的authorized_keys分发到所有节点
交叉ssh测试下,这样再启动hadoop时就不会报Host key verification failed 了
8、关闭防火墙
systemctl stop firewalld
systemctl status firewalld
9、关闭selinux
vi /etc/selinux/config
SELINUX=enforcing 改为 SELINUX=disabled
10、调整操作系统最大数限制
vi /etc/security/limits.conf
* soft nofile 65535
* hard nofile 1024999
* soft nproc 65535
* hard noroc 65535
* soft memlock unlimited
* hard memlock unlimited
测试
ulimit -a
如果不修改,计算数据量增大时会报 打开的文件数过多 错误 ,因为linux处处皆文件,所以也会限制socket打开的数量,当各个节点数据传输增大时就会导致整个错暴漏出来
11、操作系统内核调优-网络部分
vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 1000 65534
net.ipv4.tcp_fin_timeout=30
net.ipv4.tcp_timestamps=1
net.ipv4.tcp_tw_recycle=1
如果 小文件特别多,错误文件特别多(主要时受损的压缩文件) 这个时候就会报如下错:
23/11/28 17:11:58 WARN hdfs.DFSClient: Failed to connect to /10.183.243.230:9866 for block BP-1901849752-10.183.243.230-1672973682151:blk_1074692119_951295, add to deadNodes and continue.
java.net.BindException: Cannot assign requested address
“Cannot assign requested address.”是由于linux分配的客户端连接端口用尽,无法建立socket连接所致,虽然socket正常关闭,但是端口不是立即释放,而是处于TIME_WAIT状态,默认等待60s后才释放,端口才可以继续使用。在http查询中,需要发送大量的短连接,这样的高并发的场景下,就会出现端口不足,从而抛出Cannot assign requested address的异常。
查看当前linux系统的可分配端口
cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999
当前系统的端口数范围为32768~60999, 所以能分配的端口数为28231。如果我的连接数达到了28231个,就会报如上错误。
1、修改端口范围
vi /etc/sysctl.conf
#1000到65534可供用户程序使用,1000以下为系统保留端口
net.ipv4.ip_local_port_range = 1000 65534
2、配置tcp端口的重用配置,提高端口的回收效率
vi /etc/sysctl.conf
#调低端口释放后的等待时间,默认为60s,修改为15~30s 表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_fin_timeout=30
#修改tcp/ip协议配置, 通过配置/proc/sys/net/ipv4/tcp_tw_resue, 默认为0,修改为1,释放TIME_WAIT端口给新连接使用
net.ipv4.tcp_timestamps=1
#修改tcp/ip协议配置,快速回收socket资源,默认为0,修改为1 需要开启net.ipv4.tcp_timestamps该参数才有效果
#更不为提到却很重要的一个信息是:当tcp_tw_recycle开启时(tcp_timestamps同时开启,快速回收socket的效果达到),对于位于NAT设备后面的Client来说,是一场灾难——会导到NAT设备后面的Client连接Server不稳定(有的Client能连接server,有的Client不能连接server)。也就是说,tcp_tw_recycle这个功能,是为“内部网络”(网络环境自己可控——不存在NAT的情况)设计的,对于公网,不宜使用。
net.ipv4.tcp_tw_recycle=1
12、jdk安装
tar -xzvf jdk-8u181-linux-x64.tar.gz
mkdir /usr/java
mv jdk1.8.0_181 /usr/java
配置环境变量
vi /etc/profile
#-------------java setting ----------------
export JAVA_HOME=/usr/java/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
刷新配置
source /etc/profile
验证
java -version
目前是用root安装的jdk,需要修改下归属
chown hhs:hhs /usr/java
13、ntp时间同步
这里用到三个包
cd /opt/software/hhs_install_package/ntp_rpm
需要用root用户来安装
rpm -Uvh *.rpm --nodeps --force
配置:
vi /etc/ntp.conf
master:
注释掉其他server
填写
server 127.127.1.0 fudge
127.127.1.0 stratum 8
限制从节点ip段信息,可以不配置
restrict 10.243.71.0 mask 255.255.255.0 nomodify notrap
slaver:
server minganrizhi-3 prefer
启动、查看状态命令
systemctl status ntpd
systemctl restart ntpd
报错:
/lib64/libcrypto.so.10: version `OPENSSL_1.0.2' not found (required by /usr/sbin/ntpd)
解决
备份原有libcrypto.so.10
mv /usr/lib64/libcrypto.so.10 /usr/lib64/libcrypto.so.10_bak
从其他服务器找到对应的so文件复制到/usr/lib64目录下
cp libcrypto.so.1.0.2k /usr/lib64/libcrypto.so.10
手动同步
ntpdate -u ip
查看同步状态
ntpdc -np
ntpstat
14、单台节点解压hadoop安装包,并进行配置
修改安装包的所属于用户
mkdir /opt/software
chmod 777 -R /opt/software
chown hhs:hhs -R /opt/software/hhs_install_package
tar -xzvf hadoop-2.7.0.tar.gz
14.1目录建立和调整
查看自己的服务器找一个空间较大的目录
df -h?
创建准备目录
mkdir -p /app/hadoop
mkdir -p /app/hadoop/data
mkdir -p /app/hadoop/jn
mkdir -p /app/hadoop/data/tmp
mkdir -p /app/hadoop/dfs
mkdir -p /app/hadoop/dfs/data
mkdir -p /app/hadoop/dfs/name
mkdir -p /app/hadoop/tmp
mkdir -p /app/zookeeper/data
mkdir -p /app/zookeeper/dataLog
赋权限
chmod 777 -R /app
chown hhs:hhs -R /app/hadoop
14.2、配置Hadoop守护程序的环境
vi /etc/profile
#-------------hadoop setting ----------------
export HADOOP_HOME=/opt/software/hhs_install_package/hadoop-2.7.0
export HADOOP_PREFIX=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
刷新配置
source /etc/profile
vi hadoop-env.sh
vi /opt/software/hhs_install_package/hadoop-2.7.0/etc/hadoop/hadoop-env.sh
配置JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_181
14.3、配置Hadoop相关配置文件
core-site.xml 配置
vi /opt/software/hhs_install_package/hadoop-2.7.0/etc/hadoop/core-site.xml
<property>
? <name>fs.defaultFS</name>
? <value>hdfs://mycluster</value>
</property>
<property>
? ?<name>ha.zookeeper.quorum</name>
? ?<value>minganrizhi-1:2181,minganrizhi-2:2181,minganrizhi-3:2181</value>
?</property>
?<property>
? ?<name>hadoop.tmp.dir</name>
? ?<value>/app/hadoop/tmp</value>
</property>
<property>
? <name>dfs.journalnode.edits.dir</name>
? <value>/app/hadoop/jn</value>
</property>
hdfs-site.xml 配置
vi /opt/software/hhs_install_package/hadoop-2.7.0/etc/hadoop/hdfs-site.xml
<property>
? ? <name>dfs.replication</name>
? ? <value>3</value>
</property>
<property>
? ? <name>dfs.namenode.name.dir</name>
? ? <value>/app/hadoop/dfs/name</value>
</property>
<property>
? ? <name>dfs.datanode.data.dir</name>
? ? <value>/app/hadoop/dfs/data</value>
</property>
<property>
? <name>dfs.nameservices</name>
? <value>mycluster</value>
</property>
<property>
? <name>dfs.ha.namenodes.mycluster</name>
? <value>nn1,nn2</value>
</property>
<property>
? <name>dfs.namenode.rpc-address.mycluster.nn1</name>
? <value>minganrizhi-1:8020</value>
</property>
<property>
? <name>dfs.namenode.rpc-address.mycluster.nn2</name>
? <value>minganrizhi-2:8020</value>
</property>
<property>
? <name>dfs.namenode.http-address.mycluster.nn1</name>
? <value>minganrizhi-1:50070</value>
</property>
<property>
? <name>dfs.namenode.http-address.mycluster.nn2</name>
? <value>minganrizhi-2:50070</value>
</property>
<property>
? <name>dfs.namenode.shared.edits.dir</name>
? <value>qjournal://minganrizhi-1:8485;minganrizhi-2:8485;minganrizhi-3:8485/mycluster</value>
</property>
<property>
? <name>dfs.client.failover.proxy.provider.mycluster</name>
?<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
? <name>dfs.ha.fencing.methods</name>
? <value>sshfence</value>
</property>
<property>
? <name>dfs.ha.fencing.ssh.private-key-files</name>
? <value>/home/hhs/.ssh/id_rsa</value>
</property>
?<property>
? ?<name>dfs.ha.automatic-failover.enabled</name>
? ?<value>true</value>
?</property>
?<property>
? <name>dfs.ha.fencing.ssh.connect-timeout</name>
? <value>30000</value>
</property>
yarn-site.xml 配置
vi /opt/software/hhs_install_package/hadoop-2.7.0/etc/hadoop/yarn-site.xml
<property>
? ? <name>yarn.nodemanager.aux-services</name>
? ? <value>mapreduce_shuffle</value>
</property>
<property>
? <name>yarn.resourcemanager.ha.enabled</name>
? <value>true</value>
</property>
<property>
? <name>yarn.resourcemanager.cluster-id</name>
? <value>cluster1</value>
</property>
<property>
? <name>yarn.resourcemanager.ha.rm-ids</name>
? <value>rm1,rm2</value>
</property>
<property>
? <name>yarn.resourcemanager.hostname.rm1</name>
? <value>minganrizhi-3</value>
</property>
<property>
? <name>yarn.resourcemanager.hostname.rm2</name>
? <value>minganrizhi-4</value>
</property>
<property>
? <name>yarn.resourcemanager.address.rm1</name>
? <value>minganrizhi-3:8033</value>
</property>
<property>
? <name>yarn.resourcemanager.address.rm2</name>
? <value>minganrizhi-4:8033</value>
</property>
<property>
? <name>yarn.resourcemanager.zk-address</name>
? <value>minganrizhi-1:2181,minganrizhi-2:2181,minganrizhi-3:2181</value>
</property>
<property>
? <name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
? <value>true</value>
</property>
<property>
? <name>yarn.resourcemanager.recovery.enabled</name>
? <value>true</value>
</property>
<property>
? <name>yarn.resourcemanager.store.class</name>
? <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
? <name>yarn.log-aggregation-enable</name>
? <value>true</value>
</property>
mapred-site.xml 配置
cp mapred-site.xml.template mapred-site.xml
vi /opt/software/hhs_install_package/hadoop-2.7.0/etc/hadoop/mapred-site.xml
<property>
? <name>mapreduce.framework.name</name>
? <value>yarn</value>
</property>
slaves 配置
vi /opt/software/hhs_install_package/hadoop-2.7.0/etc/hadoop/slaves
minganrizhi-1
minganrizhi-2
minganrizhi-3
minganrizhi-4
分发到其他3台
cd /opt/software/hhs_install_package
scp -r hadoop-2.7.0 hhs@minganrizhi-1:/opt/software/hhs_install_package
scp -r hadoop-2.7.0 hhs@minganrizhi-2:/opt/software/hhs_install_package
scp -r hadoop-2.7.0 hhs@minganrizhi-4:/opt/software/hhs_install_package
15、在规划的三台服务器上部署Zookeeper
chown hhs:hhs -R /opt/software/hhs_install_package/zookeeper-3.3.2.tar.gz
scp -r zookeeper-3.3.2.tar.gz hhs@minganrizhi-1:/opt/software/hhs_install_package
scp -r zookeeper-3.3.2.tar.gz hhs@minganrizhi-2:/opt/software/hhs_install_package
tar -xzvf zookeeper-3.3.2.tar.gz
cd /opt/software/hhs_install_package/zookeeper-3.3.2/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改 dataDir 其他保持默认值
dataDir=/app/zookeeper/data
dataLogDir=/app/zookeeper/dataLog
#leader和follow通信端口和投票选举端口
server.1=minganrizhi-1:2888:3888
server.2=minganrizhi-2:2888:3888
server.3=minganrizhi-3:2888:3888
整体文件内容如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial?
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between?
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/app/zookeeper/data
dataLogDir=/app/zookeeper/dataLog
# the port at which the clients will connect
clientPort=2181
server.1=minganrizhi-1:2888:3888
server.2=minganrizhi-2:2888:3888
server.3=minganrizhi-3:2888:3888
dataDir下添加myid 文件
cd /app/zookeeper/data
echo 1 > myid (minganrizhi-1机器)
echo 2 > myid(minganrizhi-2机器)
echo 3 > myid(minganrizhi-3机器)
启动 zookeeper
cd /opt/software/hhs_install_package/zookeeper-3.3.2/bin
./zkServer.sh start
查看运行状态
./zkServer.sh status
2台的是 follower 1台的是 leader
16、启动journalnode进程
在规划好的minganrizhi-1、minganrizhi-2、minganrizhi-3上执行
cd /opt/software/hhs_install_package/hadoop-2.7.0/sbin
hadoop-daemon.sh start journalnode
验证
jps
17、格式化NameNode
在规划好的一台NameNode节点上执行 (minganrizhi-1)
hadoop namenode -format
分发格式化后的文件到另一台namenode
格式化完后,会在 /app/hadoop/dfs/name 目录生成一些文件
/app/hadoop/dfs/name 是 hdfs-site.xml 中配置的 namenode的数据目录
namenode 格式化会先生成一份空的fsimage 保证hdfs启动的时候可以正常启动
现在将current 目录复制到 另一台namenode的/app/hadoop/dfs/name下
scp -r current hhs@minganrizhi-2:/app/hadoop/dfs/name
18、格式化ZKFC
hdfs zkfc -formatZK (选择namenode中的一台执行即可 minganrizhi-1)

19、启动hadoop集群
cd /opt/software/hhs_install_package/hadoop-2.7.0/sbin
./start-all.sh
查看各个节点的角色是否和规划的一样,
如果有服务不正常,可以看下对应服务的日志
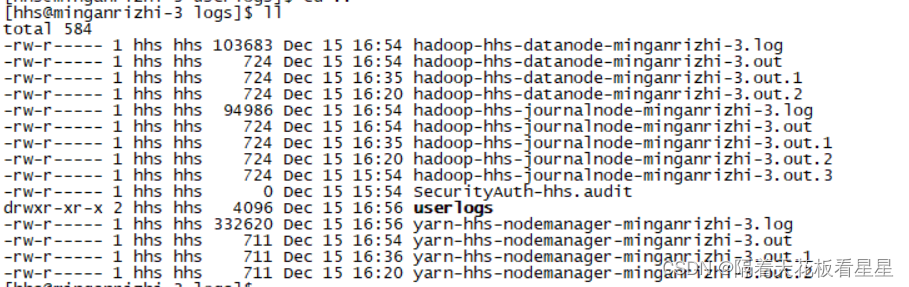
cd /opt/software/hhs_install_package/hadoop-2.7.0/logs
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Git使用教程 gittutorial
- 1.Linux快速入门
- Leetcode349两个数组的交集(java实现,思路超清晰想学会的进来!)
- 【面试总结】Java面试题目总结(一)
- 2023启示录丨自动驾驶这一年
- 毕业设计:python人脸识别考勤系统 签到系统 深度学习 Flask框架 Dlib库 MySQL数据库 大数据(源码+论文)?
- 2024 年 11 款最佳 ANDROID 数据恢复软件应用
- 【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
- jdk 线程池与 tomcat 线程池对比
- CRM软件排行榜前十 好用的CRM管理系统品牌