NLP论文阅读记录 - 2022 | WOS 02 使用 BERT 模型进行抽取式文本摘要的性能研究
文章目录
前言

Performance Study on Extractive Text Summarization Using BERT Models(22)
0、论文摘要
概括任务可以分为两种方法:抽取式和抽象式。提取摘要从原始文档中选择显着句子形成摘要,而抽象摘要解释原始文档并用自己的语言生成摘要。
文献中已经用不同的方法研究了生成摘要的任务,无论是提取的还是抽象的,包括基于统计、图形和深度学习的方法。与经典方法相比,深度学习已经取得了令人鼓舞的性能,并且随着注意力网络(通常称为变压器)等不同神经架构的进步,摘要任务存在潜在的改进领域。
Transformer 架构及其编码器模型“BERT”的引入提高了 NLP 下游任务的性能。 BERT 是来自建模为编码器堆栈的转换器的双向编码器表示。 BERT 有不同的大小,例如具有 12 个编码器的 BERT-base 和具有 24 个编码器的 BERT-larger,但出于本研究的目的,我们重点关注 BERT-base。
本文的目的是通过一系列实验对基于 BERT 的模型变体在文本摘要方面的性能进行研究,并提出“SqueezeBERTSum”,这是一种使用 SqueezeBERT 编码器变体进行微调的训练摘要模型,该模型实现了有竞争力的 ROUGE 分数将 BERTum 基线模型性能保留了 98%,可训练参数减少了 49%。
一、Introduction
1.1目标问题
自动文本摘要是一个活跃的研究领域,可以定义为提取大型文档的重要句子或片段并将它们组合成文档的简短版本的过程。总结文本既省时又经济。就时间效率而言,通过阅读掌握文档要点的摘要版本,人类读者可以花费更少的时间来阅读文档。新闻组可以在多个文档上使用文档摘要工具来收集以较短版本讨论同一主题的每个文档的重要信息。就成本效率而言,摘要可用于压缩从一个设备传输到另一个设备的文本数据量。对于用户来说,在决定下载整个文档或文章进行阅读之前选择阅读文档或文章的摘要版本将是有益的。以目前的数据增长速度,很快就会有一种工具可以生成较短版本的文本数据作为人类读者的服务。
1.2相关的尝试
自动文本摘要的任务主要由三个阶段组成:数据预处理阶段、算法处理阶段和后处理阶段。
1.1.数据预处理阶段 这是在汇总之前清理原始源文档并将其转换为更兼容的数据格式的过程。数据预处理技术的例子有: (1) 去除文档中的噪声数据; (2) 句子和单词标记化; (3) 标点符号的去除; (4) 去除停用词,去除频繁出现的词,如(a)、(an)、(the)等; (5) 词干提取,即去除后缀和前缀; (6)单词词形还原,即将单词转化为其基本结构,例如将单词“play”转化为“play”; (7)词性标注。
1.2.算法处理阶段 这是从预处理文档生成摘要时应用算法方法的过程。算法处理包括提取或抽象概括,这将在本文后面进一步讨论;然而,提取技术比抽象技术更受欢迎[1],因为前者表现出更好的性能并且相对更容易实现。
1.3.后处理阶段 这是在生成目标摘要时应用任何数据转换的过程。正如我们将在文献中介绍的,此阶段对于某些方法来说是可选的。本文的目的是研究基于 BERT 的模型在提取摘要任务中的性能,这将在第 3 节中进一步解释。第 2 节涵盖自动文本摘要的文献,包括所使用的不同方法。第 3 节讨论了该方法,该方法描述了我们针对摘要任务微调基于 BERT 的变体(例如 DistilBERT 和 SqueezeBERT)的实验。第 4 节描述了我们的观察结果和实验结果。第 5 节总结了我们的工作并描述了后续可能采取的步骤。
1.3本文贡献
总之,我们的贡献如下:
二.文献综述
文本摘要可以分为两种类型的摘要:抽取式摘要和抽象摘要。提取摘要是通过重用原始文档的某些部分(例如句子)并将它们组合成摘要而形成的。为了生成提取摘要,根据最显着的信息对每个句子进行排名,然后在保留语法规则的同时将其重新排序为摘要。 SumaRuNNer [2] 是进行提取摘要的几项研究之一。通过解释原始文档并生成较短版本的有意义的句子来形成抽象摘要。这种方法涉及模型对文档的更多语义理解,以人类可理解的形式编写摘要。 Summarist 论文提出了这种方法的一个例子,该论文具有执行此类摘要的模块 [3]。
在整个文献中,已经采用了不同的方法来生成提取摘要,例如 Luhn [4] 的基于频率计数的方法,或 TextRank [5] 的基于图形的方法,它将文档表示为句子图,其中句子之间的边缘根据相似性测量进行连接。 LexRank [6] 是另一种基于特征向量概念的基于图的方法。潜在语义分析 (LSA) [7] 是一种基于统计的方法,尝试通过对大小为 m × n 的文档矩阵 D 应用奇异值分解来查找文档中的句子,其中 m 是句子数,n 是句子数术语数量。 SumBasic [8] 是一种贪婪搜索近似方法,它使用基于频率的句子来设置单词概率的权重以最小化冗余
2.1 总结方法
2016 年,Cheng 和 Lapata 提出了一种注意力编码器-解码器架构,用于在 CNN/DailyMail 语料库上训练的提取性单文档摘要 [9]。他们的模型基于编码器-解码器方法,其中编码器学习句子和文档的表示,而解码器使用注意力机制根据编码器的表示对每个句子进行分类[10]。他们首先使用单层卷积神经网络有效地获得了句子级别的表示向量,而没有长期依赖性。之后,他们使用递归地组成句子的循环神经网络构建文档的表示[9]。第一步称为卷积句子编码器,第二步称为循环文档编码器。第三步是句子提取器,这是另一个循环神经网络,它应用注意力机制在阅读后直接提取显着句子。标记决策是根据编码文档和先前标记的句子来做出的。完成此序列标记任务后,第四步是单词提取器。该任务负责使用分层注意力架构生成摘要中的下一个单词,并计算下一个单词包含在摘要中的概率[9]。
2019 年,Joshi、Eduardo、Enrique 和 Laura 提出了 SummCoder [11],这是一种基于深度自动编码器的提取文本摘要的无监督框架。在他们的方法中,提取摘要问题被定义为给定文档的句子选择问题。确定摘要中应包含哪个句子基于三个指标: 1. 句子内容相关性指标; 2. 句子新颖性度量; 3.句子位置相关性度量。
该框架根据上述三个指标对句子进行排序,并将问题表述如下:给定一个包含 N 个句子 D = (S1, S2, …, SN) 的文档 D,句子 I 嵌入到向量 VSi 中,这是使用前面提到的三个度量计算的编码器表示,然后进行解码。
2019年,岳东等人。提出了一种训练神经网络执行单文档提取摘要的新方法,而无需启发式生成提取标签。他们将这种方法称为 BanditSum,因为它将提取摘要视为上下文强盗问题,其中模型接收要摘要的文档(称为上下文),然后选择要包含在摘要中的句子序列(称为操作)[ 12]。他们的论文使用策略梯度强化学习方法应用提取摘要。 Bandit 是一种决策形式化,其中代理重复选择多个操作之一,并根据该选择获得奖励。对于提取摘要,每个文档都被标记为上下文,并且文档句子的每个有序子集都是不同的操作。代理需要从一系列动作中学习,确定哪一个会产生最高的奖励。这种方法是在 CNN/DM 数据集上进行训练的,作者在他们的工作中得出结论,当好的摘要句子出现在源文档的较晚位置时,BanditSum 的表现明显优于其他竞争方法。
W.S.埃尔-卡萨斯等人。 2020 年提出了一个基于图的框架,结合了四种称为 EdgeSumm 的提取算法[13]。 EdgeSumm 包括基于图、基于统计、基于语义和基于中心性的方法,据报道,这些方法的性能得分高于 ROUGE-1 和 ROUGE-2 中最先进的系统。他们提出的方法旨在通过引入用于总结与领域无关的文档的通用框架来解决总结问题。它首先根据预处理步骤的输出构建文本图模型,然后计算图中每个节点的权重,该权重基于词频以及标题中单词的出现次数和其他重要因素。然后,应用搜索图算法来尝试找到将最常见的单词或主题链接在一起的短语或边,并且算法的输出是每个选定边的列表。
句子。然后,应用候选摘要算法,该算法根据哪个句子具有从搜索图算法输出的候选边缘列表中选择的至少一条边缘来选择要包括在摘要中的句子。 EdgeSumm 应用于标准数据集,例如 DUC2001 和 DUC2002,对于 DUC2002 数据集中的 ROUGE-1 和 ROUGE-L 指标,其性能优于最先进的文本摘要系统。
2019年,Yang Liu提出了一种微调的BERT摘要方法,称为BERTSum [14]。 BERT 是一堆预先训练的 Transformer 编码器,可以通过注意力机制更好地理解文本数据,使其成为可用于各种下游任务的上下文化语言模型。在他的方法中,他使用 BERT 输出每个句子的表示,因为 BERT 被训练为掩码语言模型,然后他修改了 BERT 的输入序列和嵌入,使提取摘要成为可能。图1展示了BERTSum模型的完整架构,其中他在每个句子之前插入了分类标记[CLS],在每个句子之后插入了[SEP]标记,然后在片段嵌入层引入了区间段嵌入来区分不同的句子
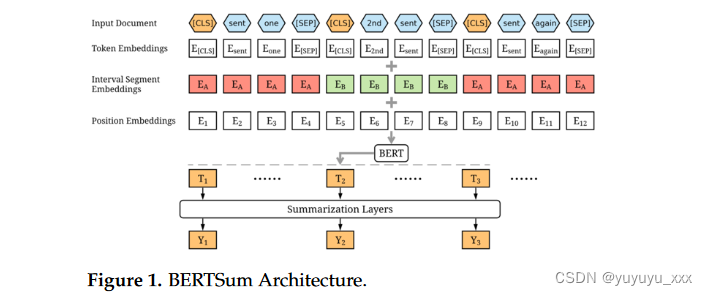
BERT 层的输出是上下文嵌入,它进入多个特定于摘要的层以捕获文档级特征以提取摘要。作者从1到N计算每个句子Si的最终预测得分Y,其中N是句子的数量,然后计算二元分类熵作为损失函数来对Si是否应该包含在摘要中进行分类
该空间中的摘要将被选择作为输出摘要。作者在五个数据集上进行了实验,证明了匹配框架的有效性,他们认为这种基于匹配的摘要框架的力量尚未得到充分利用。 2.2. ROUGE评估算法生成摘要并没有绝对正确的答案。人类读者生成的每个摘要都不同于
三.本文方法
本节描述每个实验的目标,以研究使用 BERT 编码器的变体微调模型时的摘要性能 [17]。本节还讨论了为提取摘要而训练和评估的不同架构。我们使用BERTSum作为基线模型并修改了源代码,该源代码可在BERTSum论文[18]中找到。这是我们修改后的源代码,用于进行下面的以下实验,可以在 https://github.com/ShehabMMohamed/PreSumm 上找到,于 2021 年 11 月 25 日访问。
3.1 总结为两阶段学习
3.1.1 基础系统
3.2 重构文本摘要
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果


4.6 细粒度分析
五 总结
鉴于实验结果,考虑到 SqueezeBERT 摘要模型的性能,在 NLP 任务中进一步采用基于计算机视觉的技术具有巨大的潜力。考虑到表 5 中的摘要性能和可训练参数的减少,SqueezeBERT 摘要器可以在架构压缩的情况下进行生产和部署,用于实时摘要生成,而不是部署由约 1.2 亿个数据组成的原始 BERT 摘要器参数,而提出的模型由约 6200 万个参数组成。
我们训练了 BERT 基线,并将其用作所谓的“压缩模型”(例如 DistilBERT 和 SqueezeBERT)的基准。训练后,这些总结化模型都保留了高于基线模型 90% 以上的性能水平,该模型有大约 1.205 亿个参数需要训练。第一个实验是尝试引入基于蒸馏的 BERT 模型,该模型的参数数量减少了约 35%,在测试模型时,它保留了约 98% 的 BERT 模型。第二个实验是训练一个名为 SqueezeBERT 的更高效模型,该模型用分组卷积层替换所有注意力层,以实现高效计算。这个实验产生了一个有趣的观察结果,即 SqueezeBERT 在使用一元语法时保持了与 DistilBERT 相同的性能,并且在使用二元语法和最长公共序列时具有稍微更好的性能。 SqueezeBERT 保留了基线模型 98% 的性能,参数减少了 49%(由 6213 万个参数组成,而不是基线模型的 1.205 亿个参数)。 SqueezeBERT 是训练摘要器的一个很好的选择,其大小几乎是原始模型的一半,并且摘要性能的降级最小。它还给出了一个关键的观察结果,即通过使用受计算机视觉文献[24-26]启发的高效网络(例如分组卷积层),它可以改进 NLP 下游任务,并且在本文中,它通过减少训练时间,同时保持表现。这一观察总结了基于 BERT 的变体的性能研究结果,旨在扩展摘要任务中的文献。
思考
这些实验是在 Google Colab 的单个 GPU 资源上进行的,虽然对于上述实验来说已经足够了,但还有一些额外工作的空间,例如对这些微调模型进行超参数调整,以产生更好的摘要性能。未来另一个可能的工作是在特定领域的数据集上训练这些模型,并生成专用于特定用例的提取摘要器,例如医学或学术提取摘要器。未来可能的进一步工作是探索微调 SqueezeBERT 模型以进行抽象总结而不是提取总结的潜力,并在有任何重大发现时报告性能结果。为了进一步减小预训练模型的大小,还有采用模型压缩技术的空间,例如量化和剪枝。量化是一系列技术,旨在减少神经网络中存储每个参数和/或激活所需的位数,同时保持该网络的准确性。该技术已应用于不同的 NLP 研究中 [27,28]。
剪枝的目的是直接从网络中消除某些参数,同时保持准确性,从而减少该网络的存储和潜在的计算成本;对于该 NLP 的应用,本研究演示了剪枝的应用 [28]。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 微信小程序控制元素显示隐藏
- redis 从0到1完整学习 (十三):RedisObject 之 Set 类型
- geyser互通服基岩版进不去
- Keras实现seq2seq
- Appium+python自动化(三)- SDK Manager(超详解)
- 【Leetcode 78】子集 —— 回溯法
- 【星海随笔】浅谈用户态和内核态
- Python 与其他编程语言相比有哪些独特之处?
- MMWave API
- 51单片机的外部中断的以及相关寄存器的讲解