Spark---行动算子RDD
文章目录
1.行动算子
Spark的行动算子是触发作业执行的方法,它们会直接触发计算并返回结果。
行动算子可以分为两类:数据运算类和数据存储类。数据运算类算子主要用于触发RDD计算,并得到计算结果返回给Spark程序或Shell界面,例如reduce()函数。数据存储类算子用于触发RDD计算后,将结果保存到外部存储系统中,如HDFS文件系统或数据库,例如saveAsObjectFile()函数。
在Spark中,转换算子并不会马上进行运算,而是所谓的“惰性运算”,在遇到行动算子时才会执行相应的语句,触发Spark的任务调度并开始进行计算。行动算子可以直接对RDD进行操作,并且返回一个值或者将结果保存到外部存储系统。
1.1 reduce
聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据
函数定义:
def reduce(f: (T, T) => T): T
val data: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))
val res:Int = data.reduce((x, y) => x + y)
println(res)
1.2 collect
在驱动程序中,以数组 Array 的形式返回数据集的所有元素
函数定义:
def collect(): Array[T]
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回 RDD 中元素的个数
val countResult: Long = rdd.count()
1.3 first
返回 RDD 中的第一个元素
函数定义:
def first(): T
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回 RDD 中元素的个数
val firstResult: Int = rdd.first()
println(firstResult)
1.4 count
返回 RDD 中元素的个数
函数定义:
def count(): Long
val data: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))
val res: Long = data.count()
println(res)

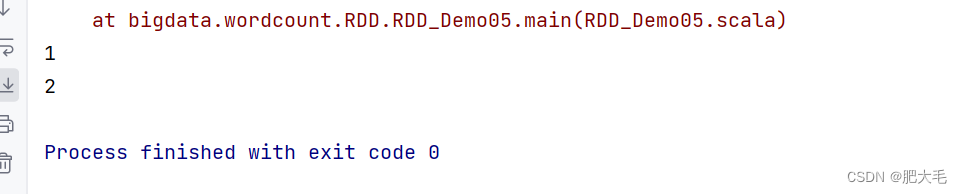
1.5 take
返回一个由 RDD 的前 n 个元素组成的数组
函数定义:
def take(num: Int): Array[T]
val data: RDD[Int] = sparkRdd.makeRDD(List(1, 2, 3, 4))
val res: Array[Int] = data.take(2)
res.foreach(println)
1.6 takeOrdered
返回该 RDD 排序后的前 n 个元素组成的数组
函数定义:
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
val data: RDD[Int] = sparkRdd.makeRDD(List(1,4,3,2))
val res: Array[Int] = data.takeOrdered(2)
res.foreach(println)

1.7 aggregate
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
函数定义:
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
val data: RDD[Int] = sparkRdd.makeRDD(List(1,4,3,2))
val res: Int =data.aggregate(0)(_+_,_+_)
println(res)

注意:aggregate在使用的时候与aggregateByKey的区别在于:aggregate设置的初始值不仅会与分区内的第一个元素相加,而且还会与分区间的第一个元素相加。
aggregateByKey设置的初始值只会与分区内的第一个元素相减加。
1.8 fold
折叠操作,aggregate 的简化版操作
函数签名
def fold(zeroValue: T)(op: (T, T) => T): T
val data: RDD[Int] = sparkRdd.makeRDD(List(1,4,3,2))
val res: Int =data.fold(0)(_+_)
println(res)
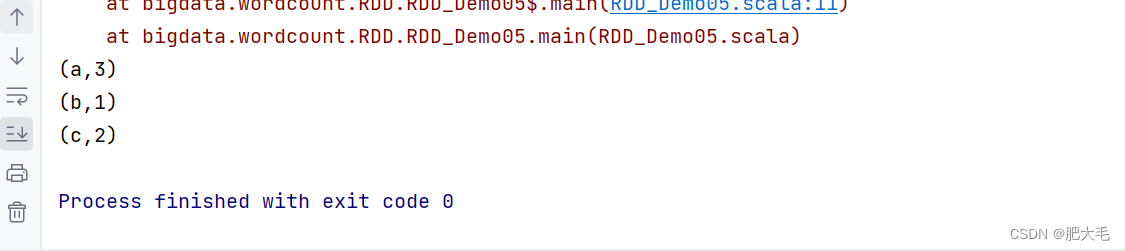
1.9 countByKey
统计每种 key 的个数
函数签名
def countByKey(): Map[K, Long]
val data:RDD[(String,Int)]= sparkRdd.makeRDD(List(("a",1),("a",2),("a",3),("b",4),("c",5),("c",6)))
val res: collection.Map[String, Long] =data.countByKey()
res.foreach(println)
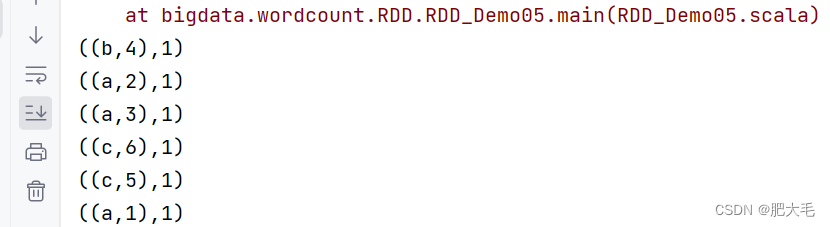
1.10 countByValue
countByValue用于统计RDD中每个元素的出现次数。这个方法返回一个Map,其中键是RDD中的元素,值是每个元素在RDD中出现的次数。
val data:RDD[(String,Int)]= sparkRdd.makeRDD(List(("a",1),("a",2),("a",3),("b",4),("c",5),("c",6)))
val res=data.countByValue()
res.foreach(println)
1.11 save 相关算子
函数定义:
def saveAsTextFile(path: String): Unit
def saveAsObjectFile(path: String): Unit
def saveAsSequenceFile(
path: String,
codec: Option[Class[_ <: CompressionCodec]] = None): Unit
// 保存成 Text 文件
rdd.saveAsTextFile("output")
// 序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
// 保存成 Sequencefile 文件
rdd.map((_,1)).saveAsSequenceFile("output2")
1.12 foreach
分布式遍历 RDD 中的每一个元素,调用指定函数
函数定义:
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
//收集后打印
rdd.map(num=>num).collect().foreach(println)
//分布式打印
rdd.foreach(println)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux各类小技巧(快捷键)
- 2024年ADB 命令知多少?一文2000字详细 ADB 命令大全来啦
- LVGL学习笔记 显示和隐藏 对象的属性标志位 配置
- 【Vue3】2-11 : 生命周期钩子函数及原理分析
- Linux系统下文本编辑常用的命令有哪些?
- VITS(Conditional Variational Autoencoder with Adversarial Learning)论文解读及实现(一)
- 【.NET Core】反射(Reflection)详解(三)
- FREERTOS(入门自学)----任务创建和删除
- 混淆技术概论
- TLG10UA06、TLG10UA03替代型号WiFi透传模块