Conditional Image-to-Video Generation with Latent Flow Diffusion Models
1 Title 重试 ?? 错误原因
????????Conditional Image-to-Video Generation with Latent Flow Diffusion Models(Haomiao Ni eg) 重试 ?? 错误原因 重试 ?? 错误原因
2 Conclusion
????????This paper propose an approach for cI2V using novel latent flow diffusion models 重试 ?? 错误原因
(LFDM) that synthesize an optical flow sequence in the latent space based on the given condition to warp the given image. Compared to previous direct-synthesis-based works, our proposed LFDM can better synthesize spatial details and temporal motion by fully utilizing the spatial content of the given image and warping it in the latent space according to the generated temporally-coherent flow. The training of LFDM consists of two separate stages: 重试 ?? 错误原因 重试 ?? 错误原因
(1) an unsupervised learning stage to train a latent flow auto-encoder for spatial content generation, including a flow predictor to estimate latent flow between pairs of video frames, and (2) a conditional learning stage to train a 3D-UNet-based diffusion model (DM) for temporal latent flow generation. Unlike previous DMs operating in pixel space or latent feature space that couples spatial and temporal information, the DM in our LFDM only needs to learn a low-dimensional latent flow space for motion generation, thus being more computationally efficient. 重试 ?? 错误原因 重试 ?? 错误原因
重试 ?? 错误原因
3 Good Sentences
? ? ? ? 1、Our LFDM instead generates flow sequences based on both image x0 and condition y using diffusion models, which have emerged as a new paradigm in generation tasks.(Differences from previous flow-based I2V works.)
? ? ? ? 2、Unlike previous direct-synthesis or warp-free based methods, the spatial content of the given image can be consistently reused by our warp-based LFDM through the generated temporallycoherent flow. So LFDM can better preserve subject appearance, ensure motion continuity and also generalize to unseen images(The creative of this paper)
? ? ? ? 3、Though achieving promising performance, our proposed LFDM still suffers from several limitations. First, current experiments with LFDM are limited to videos containing a single moving subject.?Second, the current LFDM is conditioned on class labels instead of natural text descriptions. Text-to-flow is an interesting topic and we leave this direction as future work. Finally, compared with GAN models, LFDM is much slower when sampling with 1000-step DDPM.(Some limits of LFDM)
简介:
????????Conditional image-to-video (cI2V) 条件图像到视频生成旨在从图像(例如,人脸)和条件(例如,动作类的标签,比如微笑)开始合成新的可信视频。
????????cI2V任务的关键挑战在于同时生成与给定图像和条件相对应的真实空间外观和时间动态。
本文中提出了一种使用新颖的潜流扩散模型(LFDM)的 cI2V 方法,该模型根据给定条件在隐空间中合成光流序列以扭曲给定图像。
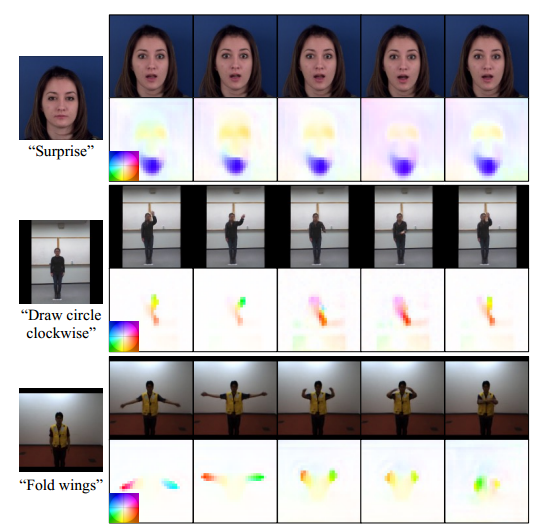
????????LFDM通过充分利用给定图像的空间内容,并根据生成的时间相干流在隐空间中进行扭曲,可以更好地合成空间细节和时间运动。
????????LFDM的训练包括两个独立的阶段:(1)无监督学习阶段,用于训练用于空间内容生成的潜流自编码器,包括用于估计视频帧对之间潜流的流预测器;(2)条件学习阶段,用于训练用于时间潜流生成的3D-UNet-based扩散模型(DM)LFDM中的DM只需要学习低维隐流空间进行运动生成,因此计算效率更高。
介绍:
????????给定单个图像![]() 和条件
和条件![]() ,cI2V的目标是合成一份
,cI2V的目标是合成一份![]()
![]()
从给定坐标系x0开始,满足条件y的0到k帧的真实视频,LFDM可以更好地保持被摄体的外观,确保运动的连续性。
????????为了理清空间内容和时间动态的生成,LFDM的训练被设计为包括两个独立的阶段。在第一阶段,受最近运动传递工作的启发,以无监督的方式训练潜流自动编码器(LFAE)。它首先估计了同一视频中参考帧和驱动帧之间的潜在光流,然后根据预测流对参考帧进行扭曲,并通过最小化扭曲帧与驱动帧之间的重构损失来训练LFAE。
????????在第二阶段,使用配对条件y和使用训练后的LFAE从训练视频中提取的潜流序列来训练DM,LFDM中的DM在一个简单的仅描述运动动力学的低维潜流空间中运行,得益于解耦的训练策略,LFDM可以很容易地适应新的领域
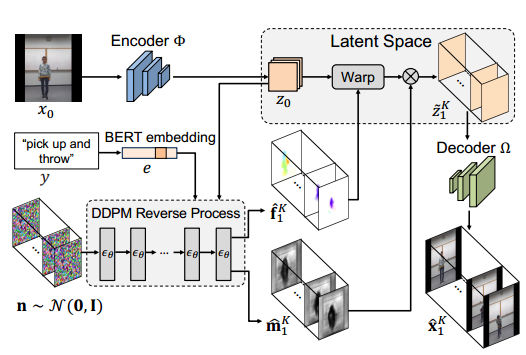
????????LFDM的视频生成(即推理)过程如图所示,首先采用在第二阶段训练的DM来生成隐流序列![]() 为了在新帧中生成遮挡区域,DM还生成一个遮挡图序列
为了在新帧中生成遮挡区域,DM还生成一个遮挡图序列![]() ,然后使用
,然后使用![]() 和
和![]() 对图像x0进行扭曲,逐帧生成视频
对图像x0进行扭曲,逐帧生成视频![]() ,通过对给定图像x0而不是之前的合成帧进行扭曲,可以避免伪影的积累
,通过对给定图像x0而不是之前的合成帧进行扭曲,可以避免伪影的积累
方法
![]() 是高斯噪声体积,其形状为
是高斯噪声体积,其形状为![]() ,这四个参数分别是长、高、宽和通道数。给定一个起始图像x0和条件y,
,这四个参数分别是长、高、宽和通道数。给定一个起始图像x0和条件y,![]() 是这个条件下的真实视频,条件图像到视频(cI2V)生成的目标是学习将噪声体积n转换为合成视频的映射,
是这个条件下的真实视频,条件图像到视频(cI2V)生成的目标是学习将噪声体积n转换为合成视频的映射,![]() ,使得
,使得![]() 在x0和y的条件分布与
在x0和y的条件分布与![]() 在x0和y的条件分布相同,
在x0和y的条件分布相同,![]() ,只考虑类标签作为输入条件y。
,只考虑类标签作为输入条件y。
DM
????????LFDM是建立在去噪扩散概率模型(DDPM)之上的,给定数据分布![]() ,DDPM的前向过程产生一个马尔可夫链
,DDPM的前向过程产生一个马尔可夫链![]() ,通过根据方差表
,通过根据方差表![]() 逐步将高斯噪声添加到
逐步将高斯噪声添加到![]()
![]() ,方差
,方差![]() 是常数,当
是常数,当![]() 很小时,后验概率
很小时,后验概率![]() 可以用对角高斯很好地近似,如果链的T足够大,
可以用对角高斯很好地近似,如果链的T足够大,![]()
可以用标准高斯函数![]() 很好地近似。
很好地近似。
综上,![]() 可以被
可以被![]() 近似,
近似,![]() ,其中,
,其中,![]() 是常数。
是常数。
????????DDPM反向过程(也称为采样),它通过高斯噪声![]()
![]() 并用已学习的
并用已学习的![]() 逐渐降低马尔可夫链中的噪声
逐渐降低马尔可夫链中的噪声![]() 产生样品
产生样品![]() 。
。
? ? ? ? 为了学习![]() ,在s0中加入高斯噪声
,在s0中加入高斯噪声![]() ,生成样本
,生成样本![]() ,然后训练一个模型
,然后训练一个模型![]() ,利用以下均方误差损失来预测
,利用以下均方误差损失来预测![]()
![]()
其中,时间步长t从![]() 中均匀采样,而
中均匀采样,而![]() 可以从
可以从![]() 去模拟
去模拟![]() ,去噪模型
,去噪模型![]() ,通过一个带有残余块(residual blocks)和自关注层(self-attention layer)的时间条件型U-Net来训练, 而时间步长t则是通过正弦位置嵌入来指定的。
,通过一个带有残余块(residual blocks)和自关注层(self-attention layer)的时间条件型U-Net来训练, 而时间步长t则是通过正弦位置嵌入来指定的。
????????对于条件生成,抽样![]() ,可以训练一个y条件模型
,可以训练一个y条件模型![]() ,
,
在训练过程中,条件y被替换为一个固定概率的空标签![]() ,在采样过程中,产生的模型输出如下:
,在采样过程中,产生的模型输出如下:
![]() 其中,g为指导量表
其中,g为指导量表
训练
整体训练过程如图所示,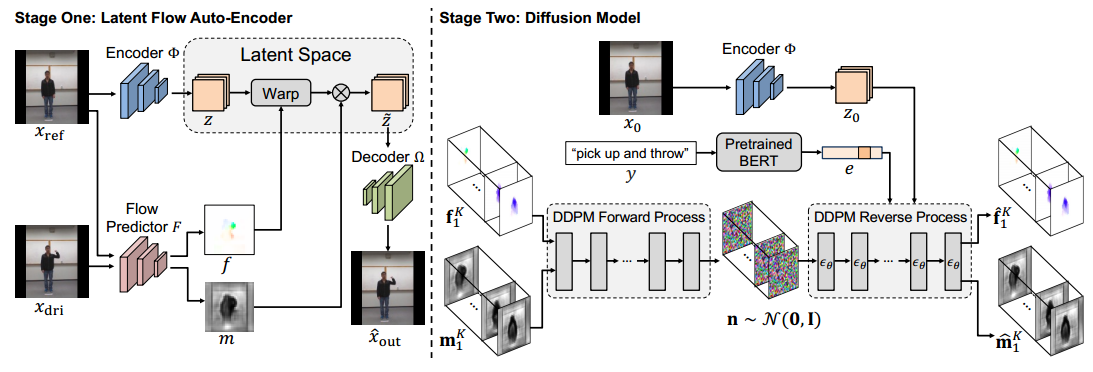
左边是训练潜流自编码器的第一阶段,右边是训练扩散模型的第二阶段。第二阶段的编码器![]() 是第一阶段训练好的。使用第一阶段训练过的流预测器F在
是第一阶段训练好的。使用第一阶段训练过的流预测器F在![]() 和groundtruth视频
和groundtruth视频![]() 的每一帧之间估计潜流序列
的每一帧之间估计潜流序列![]() 和
和![]() 遮挡图序列.
遮挡图序列.
Stage One: Latent Flow Auto-Encoder
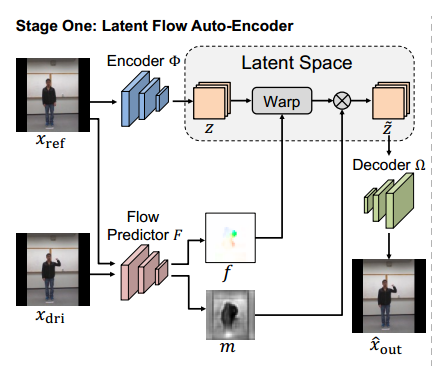
? ? ? ? 该潜流自编码器(LFAE)通过无监督的方法学习,包括三个可训练模块,分别是:图像编码器![]() ,流预测器
,流预测器![]() ,以及一个图像解码器
,以及一个图像解码器![]() 。
。![]() 用隐映射z来表示给出的图像x,
用隐映射z来表示给出的图像x,![]() 用来莫比视频帧之间的潜流f和遮挡图m,
用来莫比视频帧之间的潜流f和遮挡图m,![]() 解码扭曲的潜图
解码扭曲的潜图![]() 并把它作为输出
并把它作为输出![]() .
.
? ? ? ? 在整个训练过程中,首先从同一视频中随机选择两帧,分别是一个参考帧![]() 以及一个驱动帧
以及一个驱动帧![]() ,它们都是RGB帧,大小为
,它们都是RGB帧,大小为![]() 。然后编码器把
。然后编码器把![]() 表示为大小为
表示为大小为![]() 的隐映射z。
的隐映射z。![]() 和
和![]() 也会被送入流预测器模拟从驱动帧到参考帧的反向隐流
也会被送入流预测器模拟从驱动帧到参考帧的反向隐流![]() ,f和z的空间大小相同,都为
,f和z的空间大小相同,都为![]() ,f的两个通道分别是描述帧之间的水平方向上和垂直方向上的运动。选择反向流f是因为它可以通过可微双线性采样操作实现。
,f的两个通道分别是描述帧之间的水平方向上和垂直方向上的运动。选择反向流f是因为它可以通过可微双线性采样操作实现。
? ? ? ? 但是,因为扭曲只能使用z中现有的外观信息,所以仅使用f不足以生成![]() 的隐图,当存在遮挡时,LFAE应该能够在z中生成那些不可见的部分。流预测器
的隐图,当存在遮挡时,LFAE应该能够在z中生成那些不可见的部分。流预测器![]() 还模拟大小为
还模拟大小为![]() 的隐遮挡图m,m包含从0到1的值,以指示遮挡程度,其中1不被遮挡,0表示完全被遮挡。最终扭曲的隐映射
的隐遮挡图m,m包含从0到1的值,以指示遮挡程度,其中1不被遮挡,0表示完全被遮挡。最终扭曲的隐映射![]() 可以通过以下方式产生:
可以通过以下方式产生:![]() ,其中,
,其中,![]() 表示向后扭曲。
表示向后扭曲。
? ? ? ? 之后![]() 会解码
会解码![]() 的可见部分修复隐遮挡部分,用于生成输出图像
的可见部分修复隐遮挡部分,用于生成输出图像![]() ,这个输出应该与
,这个输出应该与![]() 相同,因此,可以仅使用未标记的视频帧在具有以下重建损失的情况下训练LFAE:
相同,因此,可以仅使用未标记的视频帧在具有以下重建损失的情况下训练LFAE:![]()
Stage Two: Diffusion Model
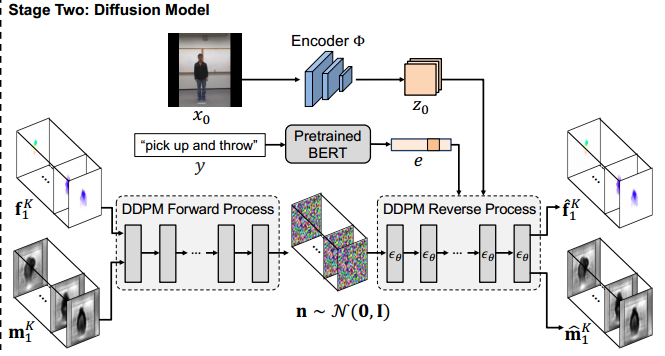
????????在第二阶段,训练基于3D UNet的扩散模型(DM)来合成时间相干的隐流序列。在第一阶段训练好的两个部分在第二阶段是必须的。????????
? ? ? ? 给定一个视频![]() 及其相应的类条件y,首先计算从第一帧到第k帧的隐流序列,
及其相应的类条件y,首先计算从第一帧到第k帧的隐流序列,![]() ,以及遮挡流序列
,以及遮挡流序列![]() 。这个计算方法是应用第一阶段中训练好的F,F模拟开始帧x0以及其他每一个帧xi之间的fi和mi,i从1到K,fi和mi的大小分别为
。这个计算方法是应用第一阶段中训练好的F,F模拟开始帧x0以及其他每一个帧xi之间的fi和mi,i从1到K,fi和mi的大小分别为![]() ,沿着通道维度将其组合
,沿着通道维度将其组合![]() 然后通过DDPM前向传播逐渐添加3D高斯噪声的方式把s0映射到标准高斯噪声
然后通过DDPM前向传播逐渐添加3D高斯噪声的方式把s0映射到标准高斯噪声![]() 。
。
? ? ? ? 随后编码器![]() 进一步将起始帧x0表示为隐映射z0,并且预训练的BERT将类条件y编码为文本嵌入e,以z0和e为条件,基于具有以下损失的条件3D U-Net训练去噪模型
进一步将起始帧x0表示为隐映射z0,并且预训练的BERT将类条件y编码为文本嵌入e,以z0和e为条件,基于具有以下损失的条件3D U-Net训练去噪模型![]() ,用于预测st中的噪声
,用于预测st中的噪声![]()
????????![]()
其中时间步长t是从{1,…,T}均匀采样的,![]() 在DDPM反向采样过程中使用,被用于输出大小为
在DDPM反向采样过程中使用,被用于输出大小为![]() 的
的![]() ,其中
,其中![]() 分别是合成的隐流序列和遮蔽图序列,所以DM中的隐流空间的大小为
分别是合成的隐流序列和遮蔽图序列,所以DM中的隐流空间的大小为![]() 。如果隐流空间的大小
。如果隐流空间的大小![]() 远远小于图像的大小
远远小于图像的大小![]() ,那么空间的维度也就可以远远低于RGB像素空间的维度。
,那么空间的维度也就可以远远低于RGB像素空间的维度。
????????此外,隐流空间仅包含运动和形状特征,因此更加容易建模,并有助于降低成本
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++顺序结构
- Spring Boot更换Spring fox为Springdoc
- Python内置函数一览表
- 机器学习:手撕 AlphaGo(一)
- 【STM32】STM32学习笔记-软件SPI读写W25Q64(38)
- 深入解析Db2中的MERGE INTO语句
- 【史上最细教程】CentOS7 下载安装 RabbitMQ(两种方式:手动安装 / Docker安装)
- 西门子触摸屏维修6AV7880-0AA22-2DA2
- 吸虫塔智能测报分析系统
- SDCMS靶场漏洞挖掘