非常非常实用!不能错过,独家原创,9种很少人听过,但却实用的混沌映射!!!以鲸鱼混沌映射为例,使用简便
很多人在改进的时候,想着增加混沌映射,增加初始种群的多样性,可是,大多数论文中常见的映射,都被别人使用了,或者不知道被别人有没有使用,
本文介绍9种很少人知道,但非常实用混沌映射,其中有几种是改进型,有几种是原本映射。
此代码本人独家原创!倒卖必究!!!,我把每个映射,都封装成一个函数了,使用简便!
如图initialization1-9为以下9种混沌映射,initialization为伪随机初始化,WOA是鲸鱼算法,CWOA是混沌鲸鱼算法。直接运行main函数即可,如果想用其他映射,只需要在CWOA中改下数字。
结构简单,也可以直接复制,在其他想改进的算法中使用。

-
Logistic-tent混沌映射
2.Tent-Logistic-Cosine混沌映射
3.SPM映射,非常均匀
4.Sinusoidal 混沌映射,是经典混沌映射之一。
5.二维Henon混沌映射,
6.Funch映射
7.Singer映射,作为混沌映射的典型代表,数学形式简单,具有遍历性和随机性。
8.高斯映射。
9.Iterative 映射
每种映射里面有相应的参考文献,可根据参考文献查看相应的公式和原理,也可以自行搜索原理,使用其他参考文献。
改进时添加混沌映射有用吗?
混沌映射(Chaotic Mapping)可以用于初始化粒子群算法的种群。混沌映射的特点是具有随机性、敏感性和确定性混合,因此可以提供一些不错的初始值,有助于增加算法的全局搜索性能。以下是混沌映射在初始化粒子群算法种群中的一些潜在作用:
1.增加种群的多样性:混沌映射生成的随机数序列具有较强的随机性,可以在种群中引入更多的多样性。这有助于避免算法陷入局部最优解,提高全局搜索能力。
2.提高全局搜索性能:混沌映射的敏感性和迭代特性有助于使粒子群算法在初始阶段更好地探索搜索空间。通过使用混沌映射生成的初始值,可以增加算法的全局搜索性能。
3.避免重复初始化:由于混沌映射生成的数值较为独特,使用混沌映射初始化可以减少种群中个体初始值的重复情况,提高算法的探索效率。
4.改善算法的收敛速度:混沌映射生成的初始值有助于使粒子群算法更快地朝着全局最优解方向收敛。这可以缩短算法的收敛时间,提高效率。
5.适用于高维问题:混沌映射可以生成高维空间中的随机数序列,适用于高维问题的初始化。这对于那些具有大量决策变量的优化问题是有益的。
尽管混沌映射在初始化粒子群算法中有一些潜在的优势,但其效果可能取决于具体的问题和算法设置,所以有些函数里面效果不一定优于原算法。在一些情况下,简单的随机初始化也可能达到良好的效果。因此,是否使用混沌映射初始化种群取决于具体问题的性质以及对算法性能的需求。在实践中,可以进行实验比较,评估使用混沌映射初始化和不使用的效果。
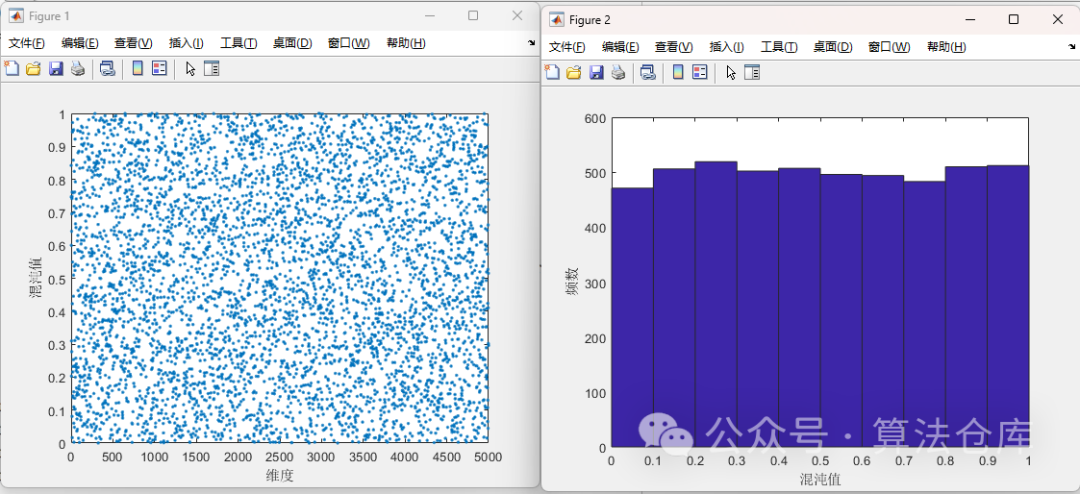
下面是SPM混沌映射的混沌值和频数分布,分布十分均匀,效果极佳!
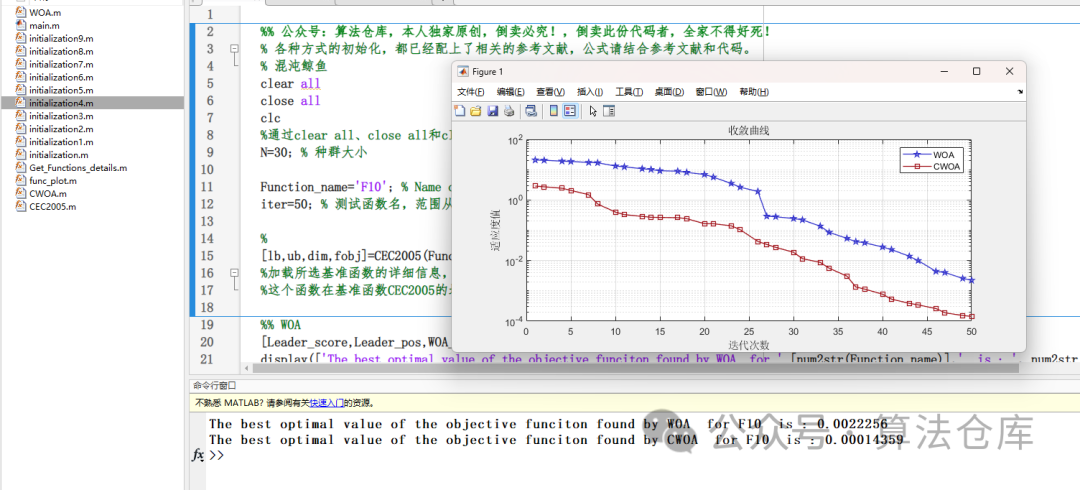
下面以鲸鱼优化算法为例,采用Sinusoidal 混沌映射:



是否进行种群混沌初始化?
混沌映射作为一种初始化手段,确实可以增加算法的多样性和全局搜索性能,但在算法的后续迭代中,最终结果仍然受到算法自身的迭代更新和搜索策略的影响。即使是在初始化时采用了混沌映射,后续迭代中的搜索空间探索和个体更新仍然可能导致最终结果的不同。
正如我所指出的,随机生成的粒子也有一定概率在后续迭代中表现更好。因此,混沌映射作为一种初始化手段,并不是绝对必要的,而是一种可能有助于提高算法性能的选择。在实践中,对于不同的问题和算法,可以进行多次实验,通过比较使用混沌映射和不使用的结果,来确定是否采用混沌映射作为初始化的一部分。
总体来说,混沌映射是一种引入随机性的手段,用于增加算法的多样性和全局搜索能力,但并非适用于所有情况。在选择初始化方法时,需要综合考虑问题特性、算法性能和实验结果。
matlab源码获取,关注个人公众号:算法仓库,后台回复:CWOA
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 可狱可囚的爬虫系列课程 10:在网站中寻找 API 接口
- Windows10 Docker Desktop安装
- Vue插槽详解-使用slot分发内容
- 解决hbuilderx打包网址成为5+app,点击返回按钮直接退出app的BUG
- 【二分查找】【z型搜索】LeetCode240:搜索二维矩阵
- 论文阅读:基于MCMC的能量模型最大似然学习剖析
- 笨蛋学设计模式行为型模式-备忘录模式【22】
- qnm 它早该火了!前端大型项目必需品
- C# 图解教程 第5版 —— 第18章 泛型
- 第十七章 : Spring Cloud中分布式锁理论与实践(一)