2023.12.19 关于 Redis 通用全局命令
发布时间:2023年12月21日
目录
引言
- Redis 是根据键值对的方式存储数据的
- 必须要进入 redis-cli 客户端程序 才能输入?redis 命令
Redis 全局命令
- Redis 支持很多种数据结构
- 整体上来说,Redis 是键值对结构
- key 固定为字符串类型,但?value 有很多种类型
- 如 字符串、哈希表、列表、集合、有序集合 等
- 操作不同的数据结构,就会有不同的命令
- 全局命令就是能够搭配任意一个数据结构来使用的命令

SET & GET
- set 根据 key 和 value 来存数据
- key 和 value 都是字符串类型
语法:
set key value?实例理解
- 对于上述的 key value 不加上引号,其表示的就是字符串类型
- 当然也可以给 key 和 value 加上引号,单引号 或 双引号 都行!
注意:
- redis 中的命名不区分大小写
- get 根据 key 来取 value
- get 命令直接输入 key 就能得到 value
语法:
get key实例理解
??????
- 如果当前 key 不存在就会直接返回 nil
- 此处的 nil 和 null、NULL 表示同一个意思




KEYS
- 用来查询当前服务器上能匹配的 key
- 通过一些特殊符号(通配符)来描述 key 的模样,能匹配上述模样的 key 就能被查询出来
时间复杂度:
- O(N)
语法:
?keys pattern
- 此处的 pattern 为包含特殊符号的字符串,其存在的意义是去描述 另外的字符串长啥样的
? 匹配任意一个字符 * 匹配 0 个或者多个任意字符 [ab] 只能匹配到 a b ,别的都不行 相当于给出固定的选项 [^ae] 只有 a、e 匹配不了 其他的都能匹配 [a-e] 匹配 a - e 这个范围内的字符 包含两侧边界
实例理解
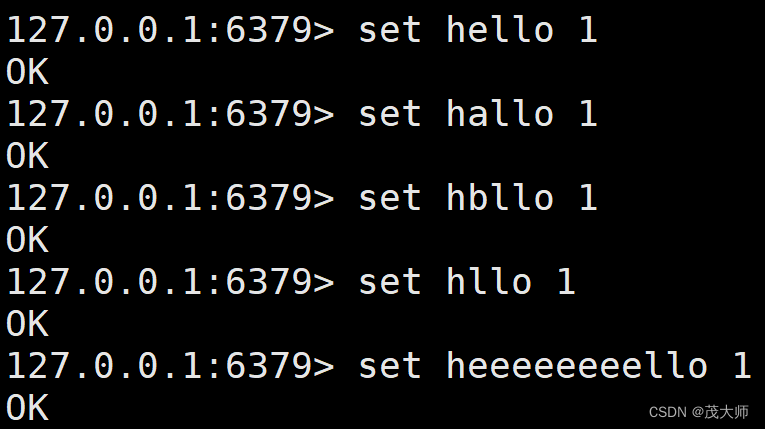
- 此处我们随意添加几个 键值对
- ?通配符
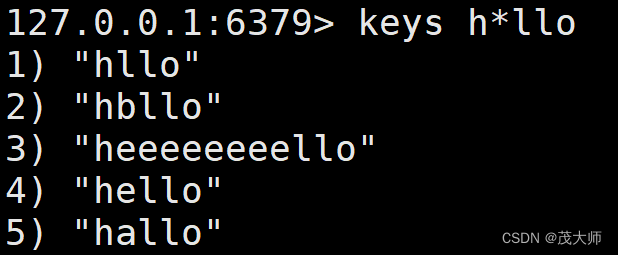
- * 通配符
- [ab] 通配符
- [^ae] 通配符
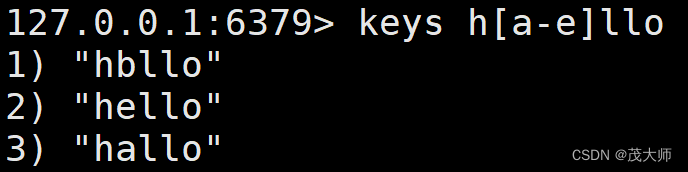
- [a-e] 通配符
注意:
- 上述匹配规则不需要刻意去背
注意事项:
- keys 命令的时间复杂度是 O(N)
- 所以 在生产环境上 一般会禁止使用 keys 命令
- 尤其是 keys * ,即查询 redis 中所有的 key
原因:
- 生产环境上的 key 可能会非常多!
- redis 是一个单线程的服务器
- 如果执行 keys?* 的时间过长,可能导致?redis 服务器被阻塞,从而无法给其他客户端提供服务
严重后果:
- redis 经常被用作缓存 挡在 mysql 前面
- 如果 redis 被?keys * 阻塞了,那么此时其他查询 redis 的操作便会超时
- 从而这些请求就会 直接查询 mysql 数据库
- 这么一大波 突然来临的请求会让 mysql 措手不及,进而导致 mysql 数据库挂掉
- 最终导致整个系统瘫痪



EXISTS
- 判定 key 是否存在
时间复杂度:
- O(1)
- redis 按照 哈希表 的方式组织这些 key
语法:
exists key [key...]返回值:
我们的 exists 是可以判断多个 key 是否存在的,所以其返回值为?key 存在的个数
实例理解
注意事项:
- 此处红框写法 与?绿框写法 相差很大
原因:
- redis 是一个 客户端 服务器 结构的程序
- 客户端和服务器之间通过 网络 来进行通信
- 绿框写法 相较于 红框写法 会产生更多轮次的网络通信
补充:
- 网络通信 相较于 直接操作内存,效率更低、成本更高
- 所以 redis 很多命令均支持一次能操作多个 key? 或者 支持多种操作


DEL
- 删除指定的 key
- 可以一次删除 一个 或 多个
时间复杂度:
- O(1)
语法:
del key [key ...]返回值:
- 删除掉的?key 的个数
实例理解
注意事项:
- 学 mysql 的时候,像删除 类型的操作,如 drop database、drop table 等 都是非常危险的操作,一旦删除,数据就无了
- redis 主要的应用场景为 用作缓存
- 此时 redis 中存的只是 热点数据,全量数据均存在?mysql 数据库中
- 如果把 redis 中的 key 删除几个,一般来说问题不会大
- 但是如果把 所有的数据 或 一大半的数据 都删除,这种影响便会很大
原因:
- 本来 redis 是帮 mysql 负重前行的
- 此时 redis 中没数据了,mysql 便需要应对大量的请求,然后 mysql 便会很容易挂掉
补充:
- 相比之下,如果是 mysql 数据库,哪怕误删了一个数据 都可能会造成很大的影响
- 但是如果把 redis 也作为数据库,此时误删数据也会造成很大的影响
- 因为此时 redis 中存储的是 全量数据
- 如果把?redis 作为消息队列,这种情况误删数据影响大不大,需要具体问题具体分析
总结:
- 不要乱删数据

EXPIRE
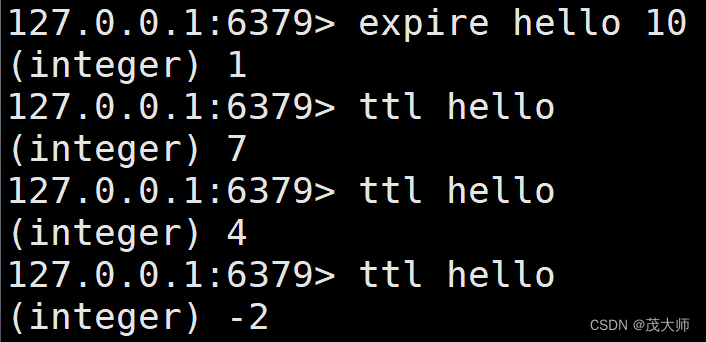
- 给指定的 key 设置过期时间
- 即 key 存活时间超出这个指定的值,就会被自动删除
语法:
- 此处的时间单位为 秒
expire key seconds
- 对于计算机来说,秒是一个非常长的时间
- 此处的时间单位为 毫秒
pexpire key millisecond返回值:
- 此处设定过期时间 必须是针对已经存在的 key 设置,设置成功返回 1 设置失败 返回 0
实例理解
经典业务场景:
- 很多业务场景,是有时间限制的
- 比如手机验证码,点外卖的优惠券,在指定时间内有效、基于 redis 实现分布式锁
redis 实现分布式锁:
- 为了不能避免出现不能正确解锁的情况,通常都会在加锁的时候设置一下过期时间
- 所谓的 redis 作为分布式锁,就是给 redis 里写一个特殊的 key value

TTL
- 查看当前 key 的过期时间
- 时间单位为 秒
时间复杂度:
- O(1)
语法:
ttl key返回值:
- 剩余过期时间 -1 表示没有关联过期时间?-2 表示 key 不存在
实例理解
redis 相关的经典面试题 :
- redis 中?key 的过期策略是怎么实现的?
理解:
- 一个 redis 中可能同时存在很多 key
- 这些 key 中可能有很大一部分都有过期时间
- 此时 redis 服务器咋知道哪些 key 已经过期要被删除,哪些 key还没过期?
回答:
- redis 的整体策略有三种
1、定期删除
- 此处需要结合定期删除的操作,即每次抽取一部分验证过期时间
- 必须保证这个抽取检查的过程足够快!
- 为啥这里对于定期删除的时间 有明确的要求呢?
- 因为 redis 是单线程的程序,其主要的任务为 处理每个命令的任务
- 如果扫描过期的 key 消耗时间太多,就可能导致正常处理请求命令被阻塞,即产生了类似于 keys * 这样的效果
2、惰性删除
- 假设一个?key 已经到过期时间了,此时并不会将其直接删除,即?key 还会保存在 redis 中
- 紧接着如果后面的访问中用到了这个 key?
- 那么此次访问将会让 redis 服务器触发删除 key 的操作,与此同时再返回一个 nil?
3、内存淘汰策略
注意:
- redis 中没有采取 定时器 的方式实现过期 key 的删除
- 如果有多个 key 过期 也可以通过一个定时器
- 在高效 且 节省 cpu 的前提下 来处理多个 key,如 基于优先级队列 或 基于时间轮 均可以实现比较高效的定时器
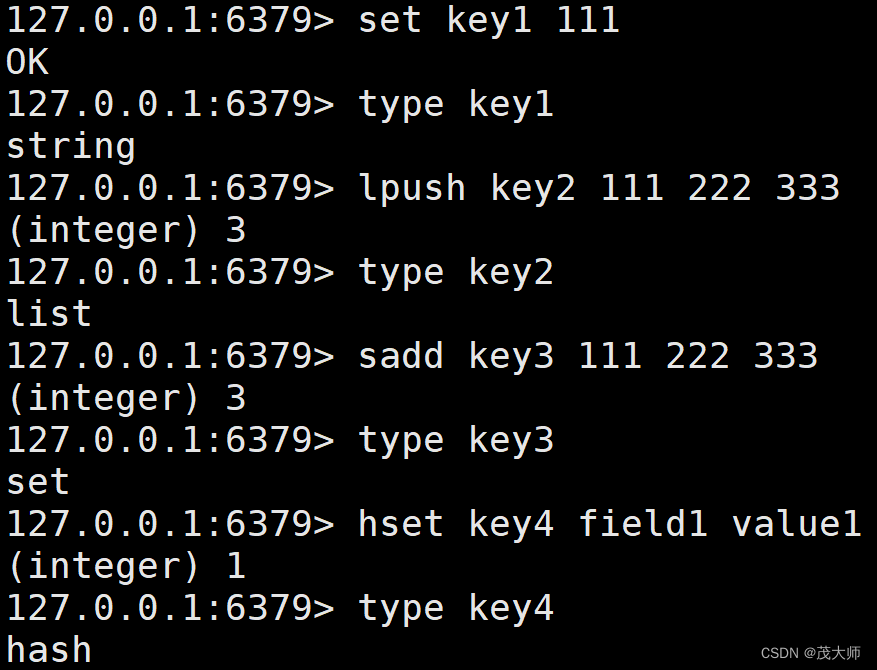
TYPE
- 返回 key 对应?value 的数据类型
时间复杂度:
- O(1)
语法:
type key返回值:
- none、string、list、set、zset、hash、stream 等
- none 表示 key 不存在
- stream 表示当 redis 作为消息队列的时候,value 将使用这个类型
实例理解
注意:
- 在 redis 中,上述类型操作方式差别很大,使用的命令都是完全不同的
redis 引入定时器高效处理过期 key
- ?redis 引入定时器实现高效处理过期 key 有两种方式
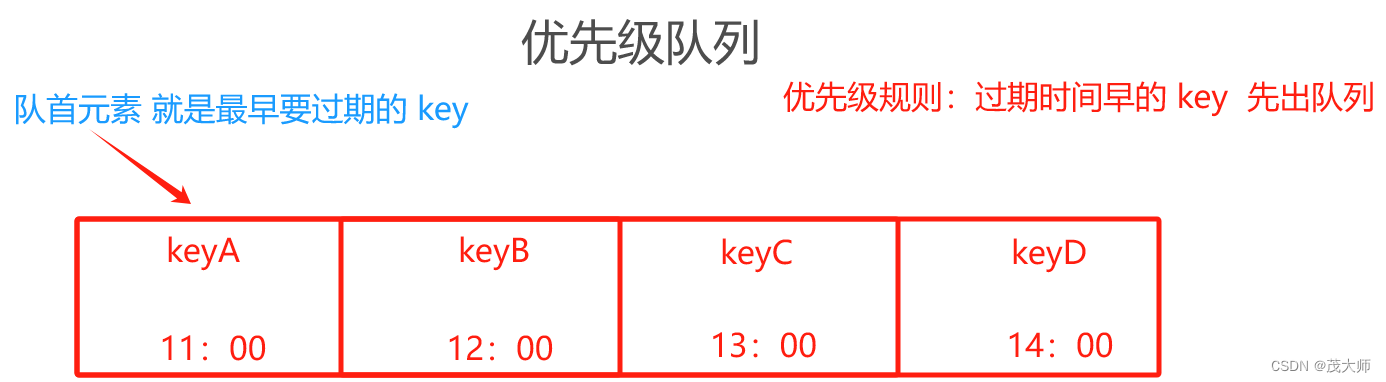
基于优先级队列方式
- 当然也可以通过 堆 的方式
基本概念
- 正常队列为先进先出
- 优先级队列则是?按照自定义指定的优先级 先出
- 在 redis 处理过期 key 场景中,可以设置优先级为:过期时间越早? 优先级越高
实例理解
- 假设有很多?key 被设置了过期时间
- 此时定时器中只要分配一个线程,让这个线程去检查队首元素 看其是否过期即可
- 如果队首元素还没过期,在队首元素之后元素一定没过期
优势:
- 此时 扫描线程 无需遍历所有?key ,仅需盯住 队首元素 即可
补充:
- 在 扫描线程 检查队首元素过期时间时,根据 过期时间 与 当前时间 之差来设置一个等待时间
- 当等待时间差不多到了,系统再唤醒该线程
- 此时扫描线程便不需要高频扫描 队首元素,把 cpu 的开销也节省下来了
问题:
- 在线程休眠的时候 插入了一个新 key,且该 key 的过期时间为?10:30
解决办法:
- 在新任务添加的时候,唤醒一下正在休眠的线程
- 即重新检查一下 队首元素,再根据时间差距重新调整阻塞时间
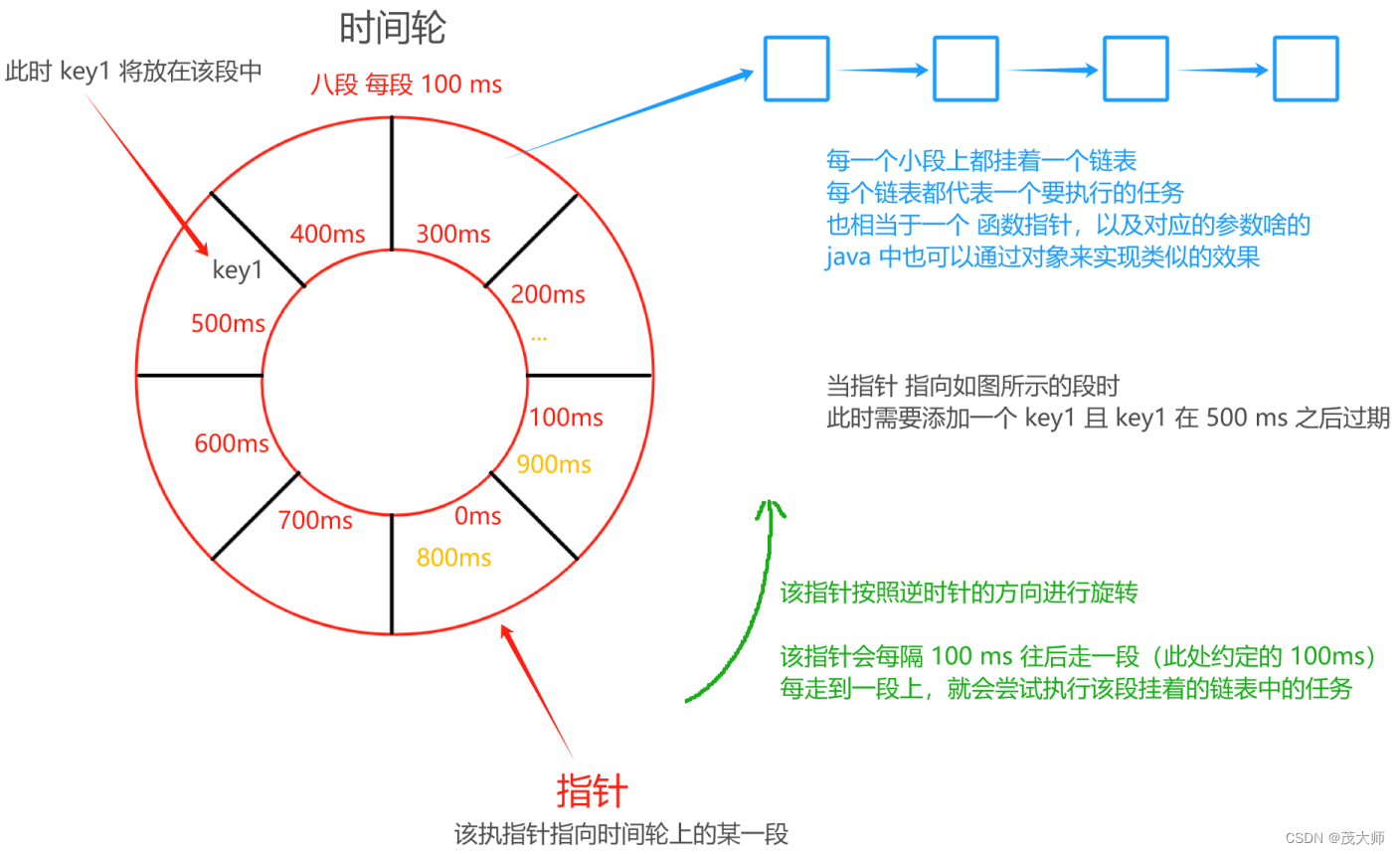
基于时间轮方式
- 把时间划分成多个小段
- 对于时间轮来说,每个格子是多少时间,一共多少个格子,都是需要根据实际场景灵活调配的
文章来源:https://blog.csdn.net/weixin_63888301/article/details/135136137
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ubuntu 20.04 aarch64 平台交叉编译 libffi 库
- 洛谷P1433——最优性剪枝与位运算状压dp
- 芯知识 | 什么是可重复擦写(Flash型)语音芯片?
- 十二、K8S之污点和容忍
- 使用Python监控服务器在线状态
- python3 统计redis中每个DB占用的内存大小
- 【Python&RS】基于Python对栅格数据进行归一化(统一量纲至0~1)
- Nuxt如何将服务测数据存储到Vuex中
- 【Java代码审计】RCE篇
- el-checkbox 实现展示区分 label 和 value(展示值与选中获取值需不同)