BP神经网络入门
发布时间:2023年12月30日
前置知识:机器学习基本概念:监督学习与无监督学习、线性回归、梯度下降。
概念
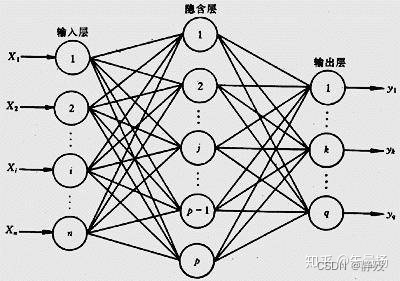
BP(Back-propagation,反向传播),在模拟过程中收集系统所产生的误差,返回这些误差到输出值(反向传播),并用这些误差来调整神经元的权重。
神经网络其实就是几层神经元,每层神经元里有几个神经元点。不同层级之间的神经元相互连接,每一个神经元只负责三件事:输入、判断、输出。通常,为了方便实际操作,我们令每一层的神经元数量相等。
运算过程:矩阵乘法
记权重矩阵为W,输入S,输出O,真值T,误差E,三者为列向量。
即
调参
实际就是梯度下降。
在这里我们使用Sigmoid函数作为激活函数。sigmoid函数可以把一个实数压缩至0~1之间。
在我们获得结果后,我们通过反向传播对w,b进行梯度调整,从而得到最优的w,b,最后在应用调整后的模型进行测试。
a1=x;
a2=w1*a1+b1;
z2=S(a2);
a3=w2*z2+b2;
z3=S(a3);
y=z3;
E=(y-y*)^2/2;注:S()指Sigmoid函数,y为模拟值,y*为真值。
Sigmoid函数

sigmoid函数连续、光滑、单调递增,以 (0,0.5) 中心对称,是一个良好的阈值函数。在x超出[-6,6]的范围后,函数值基本上没有变化,值非常接近,在应用中一般不考虑。
sigmoid函数的值域范围限制在(0,1)之间,恰巧与概率值的范围相对应,这样Sigmoid函数就能与一个概率分布联系起来了。
sigmoid函数的导数是其本身的函数,即
sigmoid函数可用作逻辑回归模型的分类器。除此之外还存在其自身的推到特性。
对于分类问题,尤其是二分类问题,都假定服从伯努利分布,则有
根据指数分布族的一半表现形式,有
伯努利分布可变形为:
故,伯努利分布也属于指数分布族,令,可得
此为sigmoid函数形式。
文章来源:https://blog.csdn.net/lty1392309506/article/details/135292662
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Javaweb见解2
- 卷积神经网络(CNN)、循环神经网络(RNN)和自注意力(self-attention)对比
- maven限制内存使用峰值/最大内存
- CMU\谷歌等最新研究综述:面向通用机器人的基础模型
- linux上比较好的截图软件
- 自媒体实战篇:自媒体运营核心
- 【Java集合篇】HashMap的put方法是如何实现的?
- Linux Shell 014-文本行排序工具
- 使用Visual Studio调试VisionPro脚本
- 一.初识Linux 1-3操作系统概述&Linux初识&虚拟机介绍