LLM - 大模型速递之 Yi-34B 入门与 LoRA 微调

一.引言
目前国内大部分开源模型都集中在 7B、13B,而国外开源模型则是集中在 7B、13B、70B 的尺寸范围,算法开发很需要一个介于 13B-70B 的大模型,弥补 13B 模型能力不足和 70B 模型显卡不够的空档。虽然 LLaMA-1-33B 有一些衍生的 Chinese 版本,但是 LLaMA2 后期并未更新维护该模型,作者在测试中发现 LLaMA-1-33B 能力与新版的 Baichuan-2-13B 相近,所以放弃了这款 33B 模型。11 月零一万物正式开源发布首款预训练大模型 Yi-34B,今天也顺便分享下 Yi-34B 模型以及其 LoRA 微调,有需要的同学欢迎评论区交流讨论~
二.零一万物
1.模型简介
模型地址:?https://huggingface.co/01-ai/Yi-34B-Chat

此次发布包含两个基于先前发布的基本模型的聊天模型,两个由 GPTQ 量化的8位模型,两种由 AWQ 量化的 4 位模型:

大家可以在 Hugging-Face 官网下载模型,这里我们使用 Yi-34B-Chat 模型。
2.模型评估
◆?Base 模型表现

◆?Chat?模型表现

除此之外还有量化的模型对比,整体来说,国内开源的网站在 Model Performance 上一般都是 SOTA 的,不过表现好坏还是得实际下下来测测看,后面我们也会把模型拿下来看下怎么事。
3.模型测试
为了使用该模型,建议更新 Transformer 版本 >=?4.36.0:?
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = '01-ai/Yi-34b-Chat'
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
# Since transformers 4.35.0, the GPT-Q/AWQ model can be loaded using AutoModelForCausalLM.
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="auto",
torch_dtype='auto'
).eval()
# Prompt content: "hi"
messages = [
{"role": "user", "content": "hi"}
]
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to('cuda'))
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
# Model response: "Hello! How can I assist you today?"
print(response)
其对应的 tmplate 模板如下,可以在?tokenizer_config.json 文件在找到:
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
三.LoRA 微调
1.微调工具
GitHub:?https://github.com/hiyouga/LLaMA-Factory
◆?支持场景
微调我们选择 LLaMA-Factory 框架,之前介绍的 Baichuan、ChatGLM 微调也是基于该框架实现 LoRA 微调。目前框架已支持 Full-Parameter、Partial-Parameter、LoRA 和 QLoRA 以及 PT、SFT、RM、PPO 、DPO 的全套流程:

◆?硬件要求
这里我们 LoRA 微调 Yi-34B,需要 80 GB,正好对应单卡 A800,如果使用 P40-24G 需要 4 台,A100-32G 需要 3 台:

◆?环境配置?

LLaMA-Factory 需要上述依赖,下载对应代码后,创建 Python 环境安装 requirements 即可。?
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -r requirements.txt如果 pip install 比较卡顿,可以尝试切换 pip 源提高安装速度:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple?
2.微调代码
◆?运行脚本
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path path_to_llama_model \
--do_train \
--dataset alpaca_gpt4_en \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16这里是对应 train_sft.sh 的内容,具体执行时还需要和你的 GPU 环境所在机器匹配,有的是直接绑定 GPU 的实体机、也有 Docker,在对应环境执行上述脚本即可。
Tips:
训练过程中可能出现?torch.cuda.OutOfMemoryError: CUDA out of memory. 的错误,此时需要调小 batch_size,或者将 fp32 修改为 fp16;修改后依然报错 OOM 则需要开启 QLoRA 量化处理:
--quantization_bit 4/8 \3.微调参数
◆?参数解析?
model_name_or_path - 指向对应开源模型的地址
dataset - 指向训练数据标识,这里要求数据格式为 json,并且配置在 data/dataset_info.json 内
template - 指向模型对应模板
lora_target - 用于指定需要 LoRA 微调的 Layer Name
output_dir - 模型微调后的存储地址
per_device_train_batch_size - 每个设备的训练 batch_size
gradient_accumulation_steps - 梯度累计更新的 step
save_steps - 存储 checkpoint 的 step 数
num_train_epochs - 训练的 Epoch 数量
◆ 支持模型

Default module 对应 lora_target 参数,用来指定 LoRA 微调的模型 Layer,Template 对应 template 模板参数,主要适配模型原始模板,避免模型训练和输出异常。
Tips:
这里没有给出 Yi-34B 的信息,可以在源码中找到,这里直接给出:
lora_target='k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj'
template='yi'从这个 lora_target 不难看出 Yi-34B 框架师承 LLaMA-2,LLaMA-2 框架有需要可以参考:
LLM - Transformer && LLaMA2 结构分析与 LoRA 详解
4.微调流程
◆ 构建数据集

从 dataset 参数对应的训练集地址读取对应地址的 json 训练数据,关于数据处理可以参考:
LLM - 数据处理之 Process Dataset For LLM With PT、SFT、RM
◆ 模型配置
![]()
从 architectures 也再次印证 Yi-34B 师承 LLaMA-2 了,剩下一些之前分析过的参数,例如 Silu 激活函数、7168 的 Hidden Size、4096 的 max_position_embeddings 以及 vocab_size 64000 的词库。按照 requirements.txt 的要求,这里需要 transformer 的版本为 >= 4.36.0。
◆ 模型读取

模型读取一共耗时 10min+,30B+ 的模型读起来还是比 13B 慢很多:
◆ Tokenizer 数据

训练前需要将对应的训练数据使用 Tokenizer.model 进行 Token 化,转换为 TokenIds 传递给后续的 Transformers 使用。
◆ 模型训练
logging_steps 参数控制打印的频率,出现下述日志以及对应的训练信息且 Loss 正常降低代表训练正常,如果没训练多久 Loss 突降为 0.0 大概率为训练数据有问题,可以人工查看下有无异常。

save_steps 参数控制 checkpoint 的保存频率,在对应 output 目录下可以查看训练存储的多个 CKPT,下面为一个 CKPT 存储的信息:

Tips:
训练完毕后可以加载对应 LoRA Weights 进行后续的预测推理工作,可以参考:
◆ 显存占用
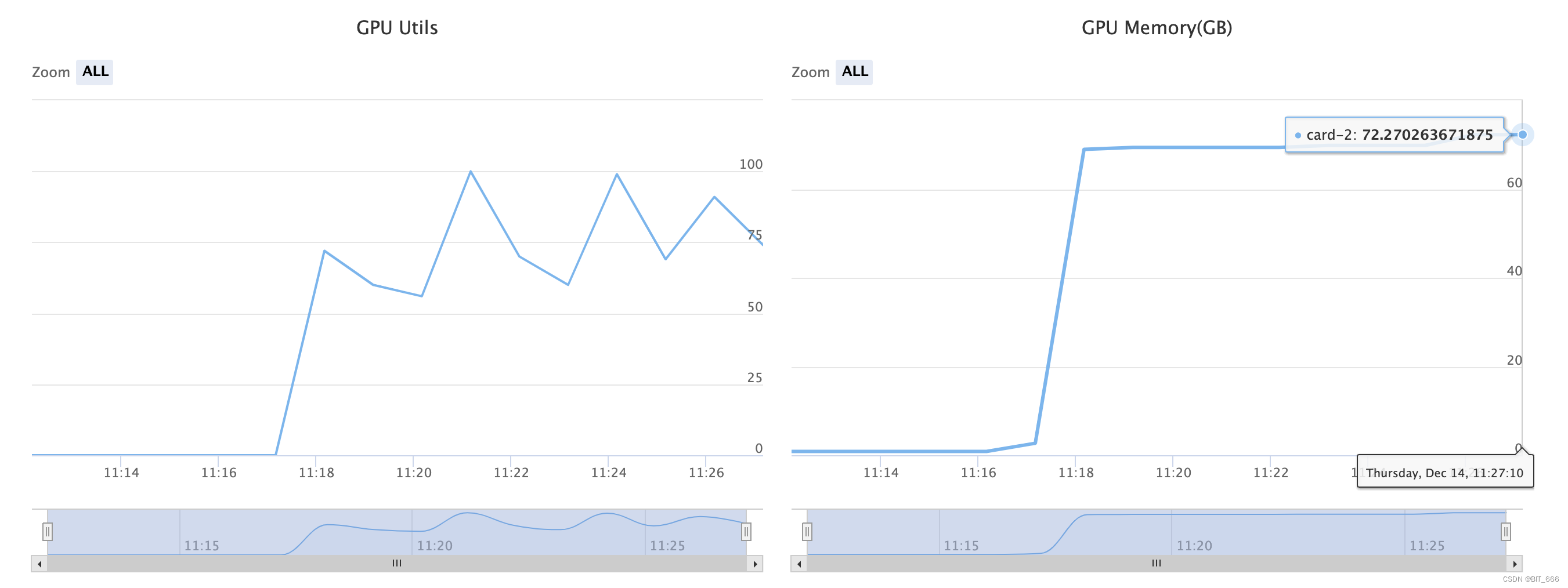
训练我们使用单张 A-800 执行,使用 --fp16 精度,batch_size 取 4 时会出现 OOM,修改为 batch_size=1 后训练正常,此处显存占用大约为 72G+,如果使用多卡可以使用?accelerate 加载多卡配置进行训练。
四.总结
上面介绍了国产开源的 Yi-34B 以及其 LoRA 微调训练的流程,按照 Hugging Face 上的评测,其能力已经直逼 GPT-4,光说不练假把式,后期博主也会实际测试下相同问题二者的回复效果。除此之外,最近新出的 MOE Mistral-8x7B 也大放异彩,后续博主也会分享其训练流程,其参考了深度学习里 MOE 专家模型的特性,同时使用 8 个 7B 模型进行训练推理。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 链表--简单学习
- 重学MySQL之关系型数据库和非关系型数据库
- CNAS中兴新支点——源代码审计对企业有哪些好处?
- 统一密钥管理在信息安全领域有什么作用
- Python 实现程序自动以管理员权限运行的方法
- Docker中创建并配置MySQL、nginx、redis等容器
- 基于51单片机的数字时钟系统设计
- (第48-59讲)STM32F4单片机,FreeRTOS【事件标志、任务通知、软件定时器、Tickless低功耗】【纯文字讲解】【原创】
- Kotlin学习之05
- 联系人管理