【AIGC】基于多个图像ID嵌入的定制化逼真人物照片(photomaker)

?前言
通过一张图或者多张图像输入,该文方法可以记住人物ID,改变属性、改变风格和混合人物ID的效果。效果SOTA。类似的工作有ipadapter,lora,Dreambooth.这些方法不是消耗算例和时间就是效果不明显,不具有泛化性。
摘要
最近的一些文生图工作在结合文本提示词的情况下合成真人图片已经取得了巨大的进展。这些工作不能同时满足高效,高的ID置信度和文本控制的自由性。我们的工作PhotoMaker是一个有效的个性化文生图生成方法。可以输入任意张ID图像然后通过堆叠来保留ID信息。嵌入信息不局限于系统的ID,也可以不同的ID。为了PhotoMaker的训练,我们专门构建了一个数据集制作管道。这个数据集有着更好的ID保留能力,能提高图像生成速度,质量。
引言
?GANs模型的生成能力有限,只能定制生成脸部区域,结果就是场景有限,缺失多样性。得益于巨大的文本图片对数据集,更大的生成模型和文本/视觉编码器可以产生好的语义嵌入,基于扩散的生成工作得以快速发展。扩散膜模型可以生成丰富的场景和真实的面部细节,其表现出来的i控制力也依赖于文本提示词和结构的引导。
定制化文生图算法包括DreamBooth,但是需要批量的相同ID图像来微调模型参数。该方法能够生成高质量的ID图像,但是缺点也很明显,训练数据需要人工收集比较耗时,定制每一个ID需要10-30分钟的训练,消耗大量算力资源,模型越大越明显。为了简化和加速生成过程,以现有的人的数据集的驱动训练视觉编码器、hypernetworks将输入ID图像表示为嵌入层或者LORA模型。这些方法效果在保真度和多样性上不如DreamBooth。
通过DreamBooth的启发,提供不同视角,不同表情,防止模型记住与ID无关的表情;提供多张统一ID的图像,在训练过程中可以更准确的表示人物的特征ID。
本文的做法将多张输入ID图像堆叠在一起。该嵌入可以使需要生成ID的统一表示,每一个子部分表示一个输入ID图像。为了更好的将ID表示和文本嵌入集成到网络中,我们替换了文本提示词中的类别词嵌入为堆叠的ID嵌入。结果嵌入同时表示要定制的ID和要生生成的上下文信息。这一设计我们无需添加任何模块,生成模型的交叉注意力层可以自适应的将ID信息包含在堆叠的ID嵌入中。
?本文方法展现的优势,第一,允许用户在生成时传入多张ID图像;第二,比DreamBooth快上130倍;第三,在生成保真度和多样性上SOA;第四,控制力强,泛化能力强。
相关工作
文生图扩散模型?
SDXL模型,在人物肖像生成上有很高的质量保证。?
个性化的扩散模型
DreamBooth、Textual Inversion?
方法
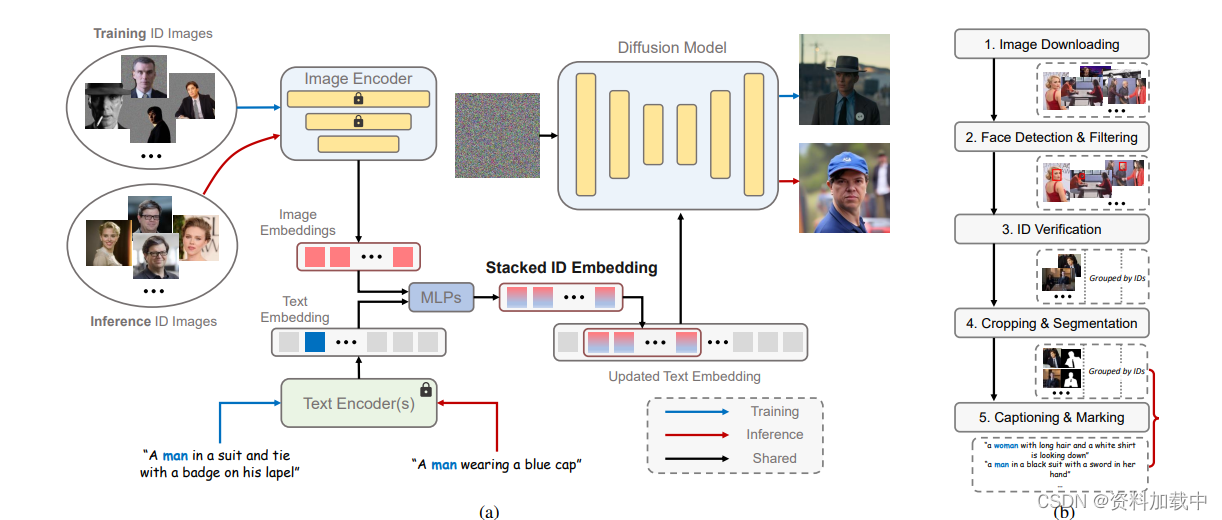
?
堆叠ID嵌入?
编码器。使用的CLIP图像编码器来提取图像嵌入,使其与原来扩散模型中的文本表示空间对齐。在将ID图像送入图像编码器之前,我们会将图像中非指定的ID图像区域填充随机噪声来消除其他ID和背景的影响。由于原始的CLIP图像编码器是由自然图像来训练的,所以为了让CLIP模型更好的从添加过掩码的图像中提取ID嵌入,我们在训练PhotoMaker网络时也同时放开了CLIP的部分transformer层来微调。我们还引入了额外的可学习投影层,将从图像编码器获得的嵌入注入到与文本嵌入相同的维度中。
表示N个某用户的输入ID图像,因此我们获得提取的嵌入
{e∈ R| i = 1。. . N },其中D表示投影尺寸。每个嵌入对应于输入图像的ID信息。 对于给定的文本提示T,我们使用预训练的CLIP文本编码器E提取文本嵌入t ∈ R,其中L表示嵌入的长度。
堆叠。最近的工作[17,50,62]表明,在文本到图像模型中,个性化的字符ID信息可以由一些唯一的令牌表示。我们的方法也有类似的设计,以更好地表示输入的人类图像的ID信息。具体来说,我们标记相应的类词(例如,男人和女人)在输入标题(见第二节)。3.3)。然后在文本嵌入中类词对应的位置提取特征向量与每个图像嵌入e融合。我们使用两个MLP层来执行这样的融合操作。融合嵌入可以表示为{e∈ R| i = 1。. . N }个。通过结合类词的特征向量,这种嵌入可以更全面地表示当前输入的ID图像。此外,在推理阶段,这种融合操作也为定制的生成过程提供了更强的语义可控性。例如,我们可以通过简单地替换类词来定制人类ID的年龄和性别(参见第二节)。4.2)。
在获得融合嵌入之后,我们将它们沿着长度维度沿着连接以形成堆叠的id嵌入:
这种堆叠的ID嵌入可以用作多个ID图像的统一表示,同时它保留每个输入ID图像的原始表示。它可以接受任意数量的ID图像编码嵌入,因此,它的长度N是可变的。与基于DreamBooth的方法[2,50]相比,该方法输入多个图像来微调模型以进行个性化定制,我们的方法本质上是同时向模型发送多个嵌入。在将相同ID的多个图像打包成一批作为图像编码器的输入之后,可以通过单个前向传递来获得堆叠的ID嵌入,与基于调谐的方法相比显著提高了效率。与此同时,与其他基于嵌入的方法[61,62]相比,这种统一表示可以保持有希望的ID保真度和文本可控性,因为它包含更全面的ID信息。此外,值得注意的是,虽然我们在训练过程中只使用了同一ID的多个图像来形成这个堆叠的ID嵌入,但我们可以在推理阶段使用来自不同ID的图像来构建它。这种灵活性为许多有趣的应用开辟了可能性。例如,我们可以将现实中存在的两个人混合在一起,或者将一个人和一个知名人物IP混合在一起(参见第二节)。4.2)。
合并。我们使用扩散模型中固有的交叉注意机制来自适应地合并堆叠ID嵌入中包含的ID信息。我们首先将原始文本嵌入t中与类词对应的位置处的特征向量替换为堆叠的id嵌入s,从而产生更新文本嵌入t∈ R。然后,交叉注意操作可以公式化为:
(2)其中,Rk(·)是可以由UNet去噪器从输入潜伏编码的嵌入。W、W和W是投影矩阵。此外,我们可以通过提示加权来调整一个输入ID图像在生成新的自定义ID中的参与程度[3,21],展示了我们的PhotoMaker的灵活性。最近的工作[2,32]发现,通过简单地调整注意力层的权重可以实现良好的ID定制性能。为了使原始扩散模型更好地感知堆叠ID嵌入中包含的ID信息,我们还训练了注意层中矩阵的LoRA [2,25]残差?。
面向身份的人体数据构建
由于我们的PhotoMaker需要在训练过程中对同一ID的多个图像进行采样以构建堆叠的ID嵌入,因此我们需要使用按ID分类的数据集来驱动PhotoMaker的训练过程。然而,现有的人类数据集要么不注释ID信息[29,35,55,68],要么它们包含的场景的丰富性非常有限[36,41,60](即,他们只关注面部区域)。因此,在本节中,我们将介绍一个用于构建以人为中心的文本图像数据集的管道,该数据集按不同的ID进行分类。图2(B)示出了所提出的流水线。通过这个管道,我们可以收集到一个面向ID的数据集,这个数据集包含大量的ID,每个ID都有多个图像,包含不同的表情、属性、场景等
该数据集不仅有助于我们的PhotoMaker的训练过程,而且可能会激发未来潜在的ID驱动研究。数据集的统计数据见附录。
图像下载。我们首先列出一个名人名单,可以从VoxCeleb1和VGGFace2获得[7]。我们根据列表在搜索引擎中搜索名字并抓取数据。每个名字下载了大约100张图片。为了生成更高质量的肖像图像[44],我们在下载过程中过滤掉了分辨率最短边小于512的图像。
人脸检测和过滤。我们首先使用RetinaNet [16]来检测人脸边界框,并过滤掉小尺寸(小于256 × 256)的检测。如果图像不包含任何符合要求的边界框,则图像将被过滤掉。然后,我们对剩余的图像进行ID验证。
身份验证。由于一张图像可能包含多张人脸,我们首先需要确定哪张人脸属于当前身份组。具体来说,我们将当前身份组的检测框中的所有人脸区域发送到ArcFace [15]中以提取身份嵌入并计算每对人脸的L2相似度。我们将每个身份嵌入与所有其他嵌入计算的相似度求和,以获得每个边界框的得分。我们为每个具有多个面的图像选择具有最高总和分数的边界框。在边界框选择之后,我们重新计算每个剩余框的总和得分。我们按ID组计算总分的标准差δ。我们根据经验使用8δ作为阈值来过滤掉具有不一致ID的图像。
裁剪和分割。我们首先根据检测到的人脸区域用更大的正方形框裁剪图像,同时确保裁剪后人脸区域可以占据图像的10%以上。由于我们需要在将输入ID图像发送到图像编码器之前从输入ID图像中移除不相关的背景和ID,因此我们需要为指定的ID生成掩码。具体来说,我们使用Mask2Former [14]来执行“person”类的全景分割。我们保留与ID对应的面部边界框重叠最高的掩模。此外,我们选择丢弃未检测到掩模的图像,以及边界框和掩模区域之间没有重叠的图像。
字幕和标记我们使用BLIP 2 [33]为每个裁剪的图像生成字幕。因为我们需要标记类单词(例如,男人、女人和男孩),为了促进文本和图像嵌入的融合,我们使用BLIP2的随机模式重新生成不包含任何类别词的字幕,直到出现类别词。在获得标题后,我们将标题中的类词进行单值化,使其聚焦于单个ID。接下来,我们需要标记当前ID对应的类词的位置。仅包含一个类词的标题可以直接
仅包含一个类词的标题可以直接注释。对于包含多个类词的标题,我们计算每个身份组的标题中包含的类词。出现次数最多的类字将是当前标识组的类字。然后,我们使用每个身份组的类字来匹配和标记该身份组中的每个标题。对于不包括与相应身份组匹配的类词的标题,我们采用依赖解析模型[24]根据不同的类词对标题进行分段。我们计算分割后的子标题与图像中特定ID区域之间的CLIP得分[45]。此外,我们通过SentenceFormer [48]计算当前片段的类词与当前身份组的类词之间的标签相似度。我们选择标记CLIP得分和标签相似度的最大乘积对应的类词。
参考链接
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SQL进阶:Case语句使用
- python+selenium操作下拉框
- 芯课堂 | 通过ISP升级芯片固件方法及框架
- 四十六----react路由
- 写了个在线 SQL 转换工具,支持 Oracle、Mysql、SQLServer 语句互转。
- 刚开始做抖店,还在摸索阶段没什么头绪?完整做店思路教程如下!
- 编程羔手(新手):什么时候用常量,什么时候用枚举类?
- 恢复.EKING勒索病毒加密数据:数据安全的必备知识
- 基于BP神经网络的租金预测
- ppt美化的的几个小技巧