PageHelper这次给我深深上了一课!
最近项目中出现了一些奇怪的现象!!查询全部分类的下拉列表只能查出5条数据?

明明有十多个结果,怎么只能返回5个?
当管理员在后台界面重置用户的密码的时候,居然报错了?
报错信息:sql中update语句不认识 “Limit 5”
可想而知,我的sql被拼接了“limit”分页参数!!!
PageHelper是怎么做到上面的问题的?
我首先得讲解一下基本使用。
代码如下:
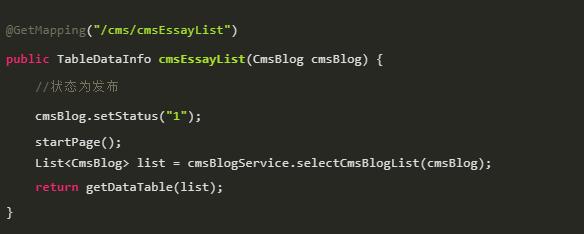
startPage()干啥了?
PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable)的参数分别是:
-
pageNum:页数 -
pageSize:每页数据量 -
orderBy:排序 -
reasonable:分页合理化,对于不合理的分页参数自动处理,比如传递pageNum是小于0,会默认设置为1.
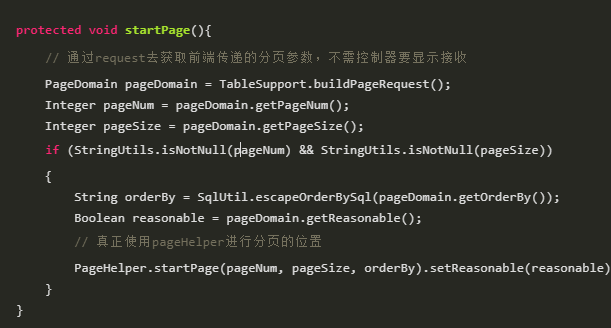
连续点击startpage构造方法到达如下位置:
/**
?*?开始分页
?*?@param?pageNum??????页码
?*?@param?pageSize?????每页显示数量
?*?@param?count????????是否进行count查询
?*?@param?reasonable???分页合理化,null时用默认配置
?*?@param?pageSizeZero?true且pageSize=0时返回全部结果,false时分页,null时用默认配置
?*/
public?static?<E>?Page<E>?startPage(int?pageNum,?int?pageSize,?boolean?count,?Boolean?reasonable,?Boolean?pageSizeZero)?{
????Page<E>?page?=?new?Page<E>(pageNum,?pageSize,?count);
????page.setReasonable(reasonable);
????page.setPageSizeZero(pageSizeZero);
????//?1、获取本地分页
????Page<E>?oldPage?=?getLocalPage();
????if?(oldPage?!=?null?&&?oldPage.isOrderByOnly())?{
????????page.setOrderBy(oldPage.getOrderBy());
????}
?????//?2、设置本地分页
????setLocalPage(page);
????return?page;
}
到达终点位置了,分别是:getLocalPage()和setLocalPage(page),分别来看下:
getLocalPage()
进入方法:
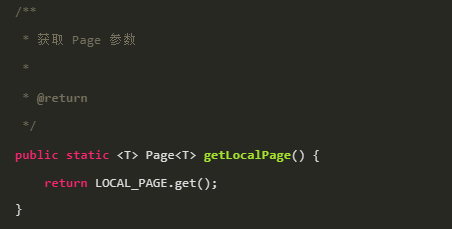
看看常量LOCAL_PAGE是个什么路数?
![]()
当一个请求来的时候,会获取持有当前请求的线程的ThreadLocal,调用LOCAL_PAGE.get(),查看当前线程是否有未执行的分页配置。
setLocalPage(page)
设置线程的分页配置:

经过前面的分析,我们发现,问题似乎就是这个ThreadLocal导致的。
是否在使用完之后没有进行清理?导致下一次此线程再次处理请求时,还在使用之前的配置?
mybatis使用pageHelper分析
前面提到过,通过PageHelper的startPage()方法进行page缓存的设置,当程序执行sql接口mapper的方法时,就会被拦截器PageInterceptor拦截到。
我们只关注intercept方法:
@Override
public?Object?intercept(Invocation?invocation)?throws?Throwable?{
????try?{
????????Object[]?args?=?invocation.getArgs();
????????MappedStatement?ms?=?(MappedStatement)?args[0];
????????Object?parameter?=?args[1];
????????RowBounds?rowBounds?=?(RowBounds)?args[2];
????????ResultHandler?resultHandler?=?(ResultHandler)?args[3];
????????Executor?executor?=?(Executor)?invocation.getTarget();
????????CacheKey?cacheKey;
????????BoundSql?boundSql;
????????//?由于逻辑关系,只会进入一次
????????if?(args.length?==?4)?{
????????????//4?个参数时
????????????boundSql?=?ms.getBoundSql(parameter);
????????????cacheKey?=?executor.createCacheKey(ms,?parameter,?rowBounds,?boundSql);
????????}?else?{
????????????//6?个参数时
????????????cacheKey?=?(CacheKey)?args[4];
????????????boundSql?=?(BoundSql)?args[5];
????????}
????????checkDialectExists();
????????//对?boundSql?的拦截处理
????????if?(dialect?instanceof?BoundSqlInterceptor.Chain)?{
????????????boundSql?=?((BoundSqlInterceptor.Chain)?dialect).doBoundSql(BoundSqlInterceptor.Type.ORIGINAL,?boundSql,?cacheKey);
????????}
????????List?resultList;
????????//调用方法判断是否需要进行分页,如果不需要,直接返回结果
????????if?(!dialect.skip(ms,?parameter,?rowBounds))?{
????????????//判断是否需要进行?count?查询
????????????if?(dialect.beforeCount(ms,?parameter,?rowBounds))?{
????????????????//查询总数
????????????????Long?count?=?count(executor,?ms,?parameter,?rowBounds,?null,?boundSql);
????????????????//处理查询总数,返回?true?时继续分页查询,false?时直接返回
????????????????if?(!dialect.afterCount(count,?parameter,?rowBounds))?{
????????????????????//当查询总数为?0?时,直接返回空的结果
????????????????????return?dialect.afterPage(new?ArrayList(),?parameter,?rowBounds);
????????????????}
????????????}
????????????resultList?=?ExecutorUtil.pageQuery(dialect,?executor,
????????????????????ms,?parameter,?rowBounds,?resultHandler,?boundSql,?cacheKey);
????????}?else?{
????????????//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
????????????resultList?=?executor.query(ms,?parameter,?rowBounds,?resultHandler,?cacheKey,?boundSql);
????????}
????????return?dialect.afterPage(resultList,?parameter,?rowBounds);
????}?finally?{
????????if(dialect?!=?null){
????????????dialect.afterAll();
????????}
????}
}
我们只需要关注几个终点位置:
设置分页:dialect.skip(ms, parameter, rowBounds)
此处的skip方法进行设置分页参数,内部调用方法:

继续跟踪getPage(),发现此方法的第一行就获取了ThreadLocal的值:
Page?page?=?PageHelper.getLocalPage();
统计数量:dialect.beforeCount(ms, parameter, rowBounds)
我们都知道,分页需要获取记录总数,所以,这个拦截器会在分页前先进行count操作。
如果count为0,则直接返回,不进行分页:

afterPage其实是对分页结果的封装方法,即使不分页,也会执行,只不过返回空列表。
分页:ExecutorUtil.pageQuery
在处理完count方法后,就是真正的进行分页了:
此方法在执行分页之前,会判断是否执行分页,依据就是前面我们通过ThreadLocal的获取的page。
当然,不分页的查询,以及新增和更新不会走到这个方法当中。
非分页:executor.query
而是会走到下面的这个分支:
resultList?=?executor.query(ms,?parameter,?rowBounds,?resultHandler,?cacheKey,?boundSql);
我们可以思考一下,如果ThreadLoad在使用后没有被清除,当执行非分页的方法时,那么就会将Limit拼接到sql后面。
为什么不分也得也会拼接?我们回头看下前面提到的dialect.skip(ms, parameter, rowBounds):
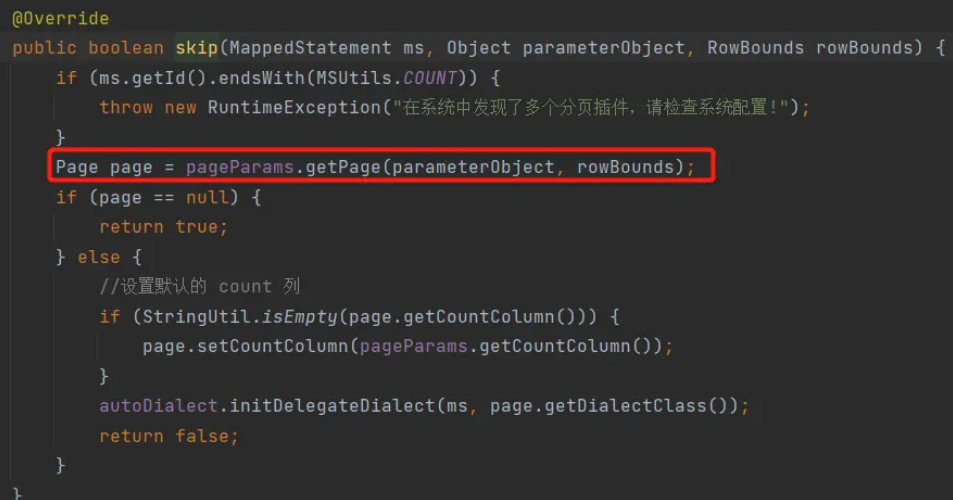
如上所示,只要page被获取到了,那么这个sql,就会走前面提到的ExecutorUtil.pageQuery分页逻辑,最终导致出现不可预料的情况。
在intercept方法的最后,会在sql方法执行完成后,清理page缓存:
finally?{
????if(dialect?!=?null){
????????dialect.afterAll();
????}
}
看看这个afterAll()方法:
@Override
public?void?afterAll()?{
????//这个方法即使不分页也会被执行,所以要判断?null
????AbstractHelperDialect?delegate?=?autoDialect.getDelegate();
????if?(delegate?!=?null)?{
????????delegate.afterAll();
????????autoDialect.clearDelegate();
????}
????clearPage();
}
只关注?clearPage():
/**
?*?移除本地变量
?*/
public?static?void?clearPage()?{
????LOCAL_PAGE.remove();
}
总结:

所以,在使用PageHelper进行分页时,执行sql的代码要紧跟startPage()方法。我们还需要手动调用clearPage()方法,在存在问题的方法之前。
最后说一句(求关注!!)
求一键三连:点赞、转发、在看。
搜索公众号:woniuxgg,在公众号中回复:笔记?获得蜗牛为你精心准备的实战语雀笔记
回复面试、开发手册、有超赞的粉丝福利。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 9.6+9.7
- Android apk完整性检测的实现思路和实现过程全记录
- 解决执行npm(或pnpm)时报:证书过期 certificate has expired问题
- Mybatis Flex 常见用法
- linux系统如何配置一个FTP服务器
- php-7.1.13的配置文件一览
- 【JavaScript 】JavaScript 数组对象操作数组的方法(很全带示例)
- uniapp小程序---二维码(生成、保存)
- JS——闭包经典使用场景和闭包面试必刷题
- JNI笔记