27 redis 的 sentinel 集群
前言
redis 的哨兵的相关业务功能的实现?
哨兵的主要作用是?检测 redis?主从集群中的?master 是否挂掉,?单个哨兵节点识别?master 下线为主管下线,?超过?quorum 个?哨兵节点 认为 master?挂掉,?识别为?客观下线
然后做?failover 的相关处理,?重新选举?master?节点?
我们这里?来看一下 这里的整个流程
?
?
定时发送?ping, pub/sub ”Hello” 频道?
sentinel 这边有单独的定时任务处理部分,?它存取数据,?只做?监听集群中的数据节点,?哨兵节点?的相关功能
定时发送?info, ping, 向?“__sentinel__:hello” 发布当前哨兵的相关信息[ip, port, id, epoch]
info 这边主要是向各个节点发送 info?命令,?然后?哨兵节点这边定时更新 数据节点的元数据信息
ping 这边主要是类似于一个集群心跳的功能?
可以给根据?ping_period, PUBLISH_PERIOD 来更新发送的频率?
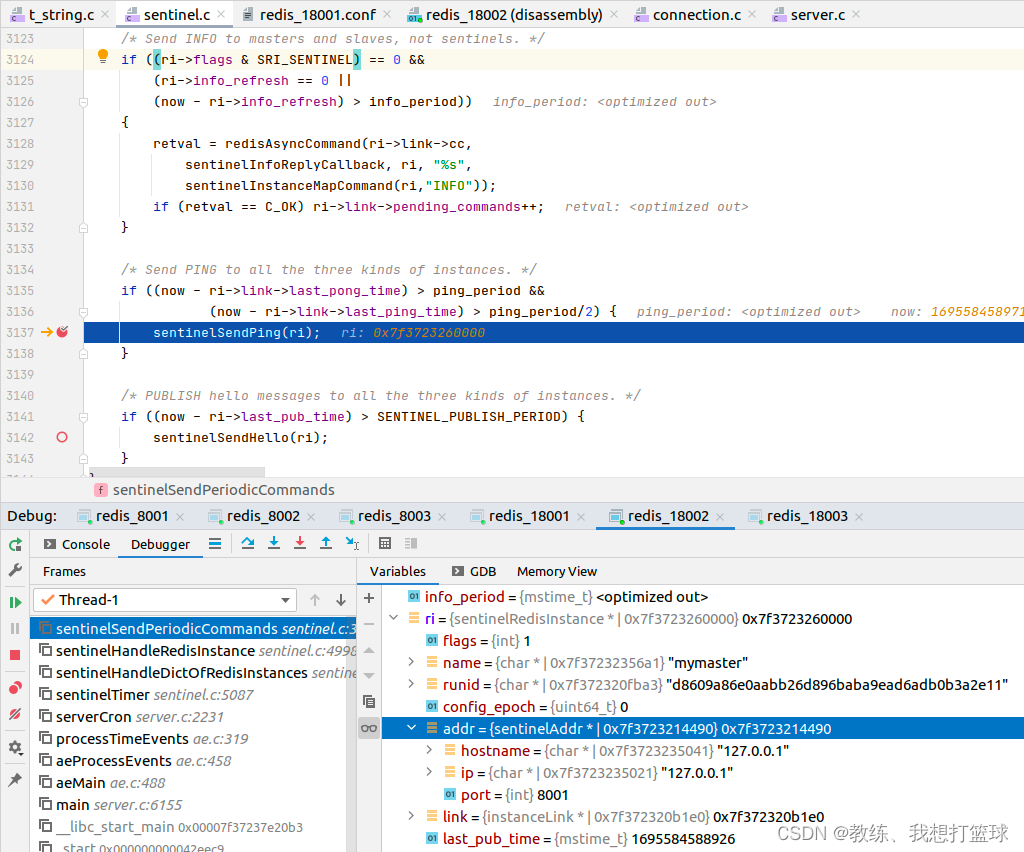
?
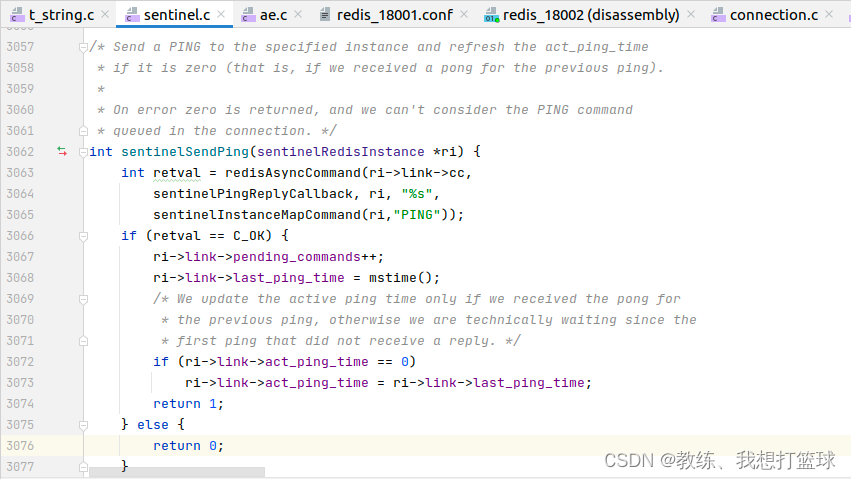
向各个数据节点发送?PING 之后,?会记录?last_ping_time 等等信息?
这里的?PING?就是一个心跳的功能?
?
哨兵节点这边初始化的时候,?和?master?创建连接的时候,?会订阅?“__sentinel__:hello”
各个哨兵节点就是通过?“__sentinel__:hello” 来感知哨兵列表的?
然后具体的?哨兵节点的哨兵列表的维护就是在 sentinelReceiveHelloMessages 中进行处理的?
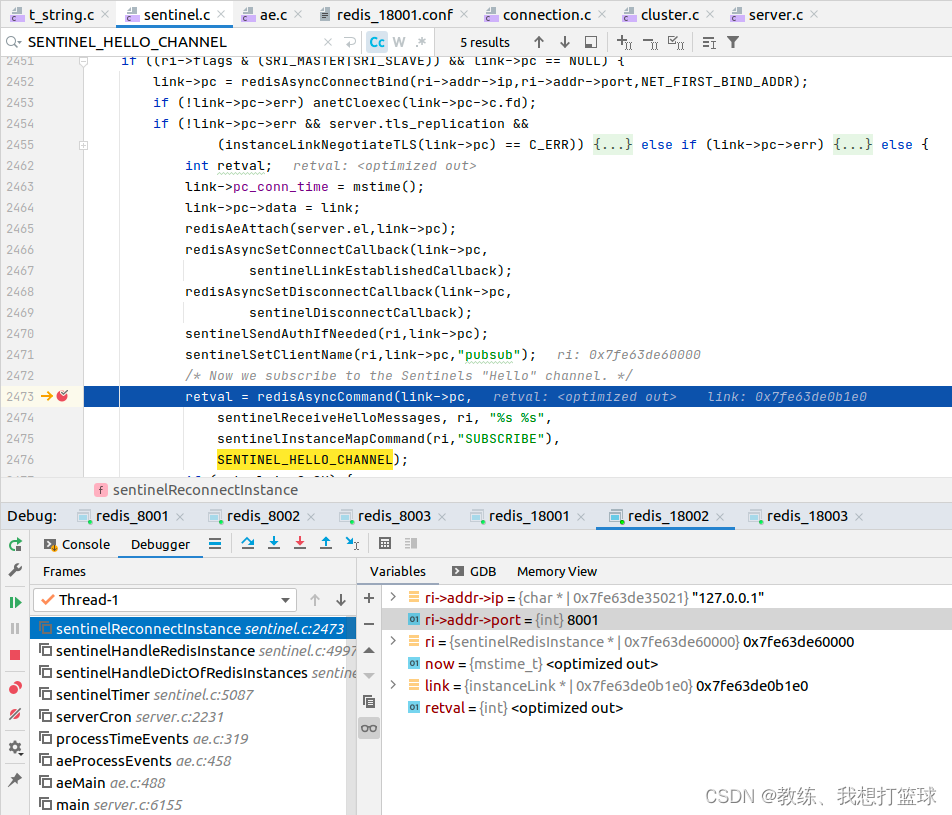
?
?
哨兵节点认为?master?主观下线
就是?上一次ping心跳 到现在的时间超过了 down_after_period
或者?info心跳信息?到现在的时间超过了 down_after_period+20s
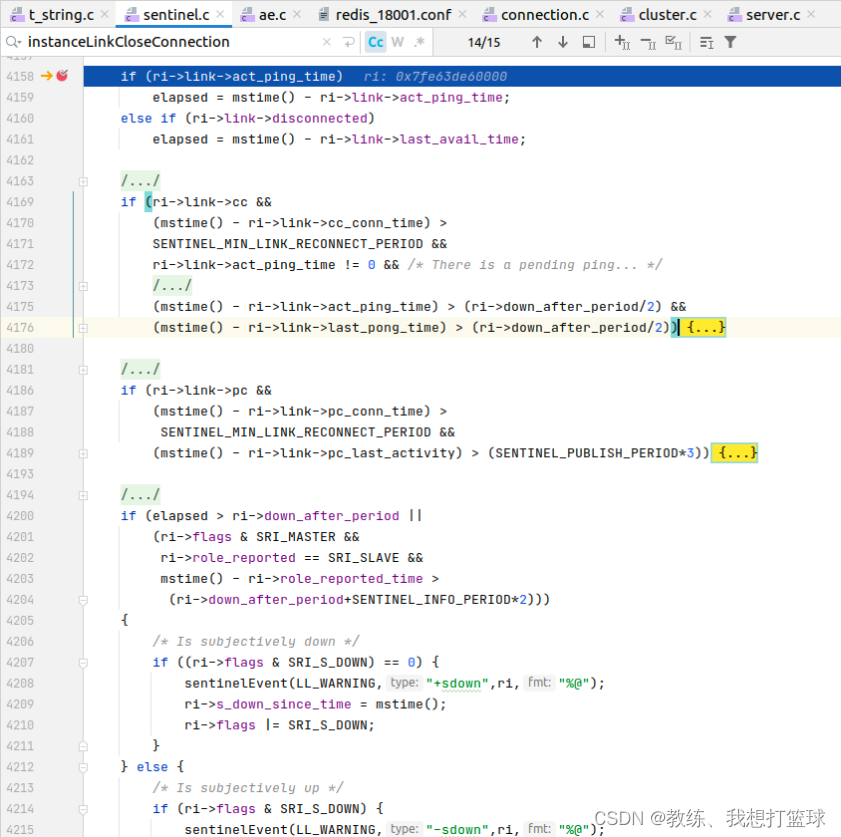
?
调用堆栈信息如下
?
?
哨兵集群认为?master?客观下线
当认为?master?客观下线的?哨兵节点数量超过了 quorum?个的时候, 哨兵集群认为?master?客观下线?
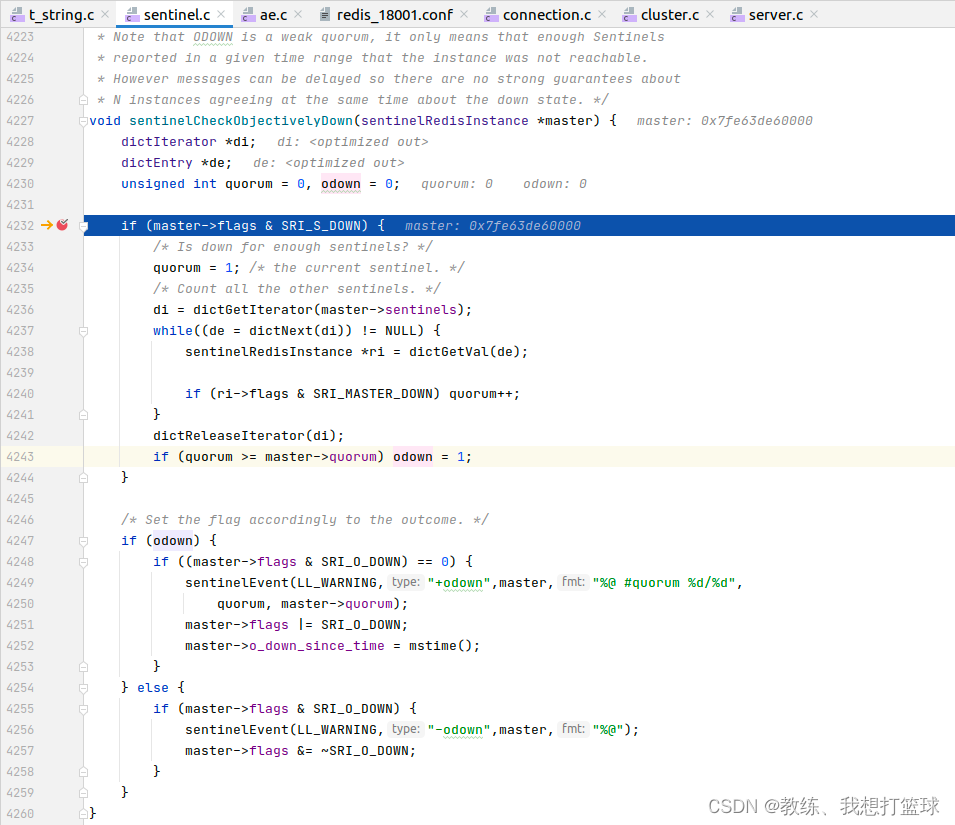
?
调用堆栈信息如下
?
?
master 挂掉之后的重新选举?和更新
主观下线之后,?选择?哨兵 master?的流程
sentinelFailoverWaitStart 是选取?哨兵 master?的处理
sentinelFailoverSelectSlave 是从数据节点中选择?master?的处理?
sentinelFailoverSendSlaveOfNoOne 是切换?master?的处理?
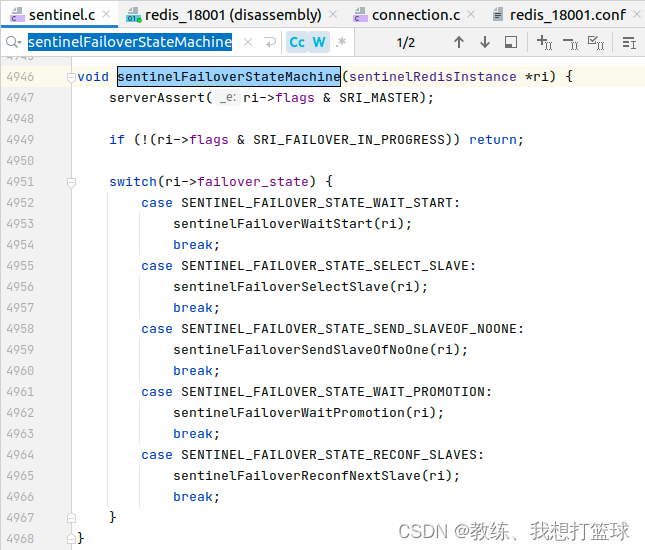
?
?
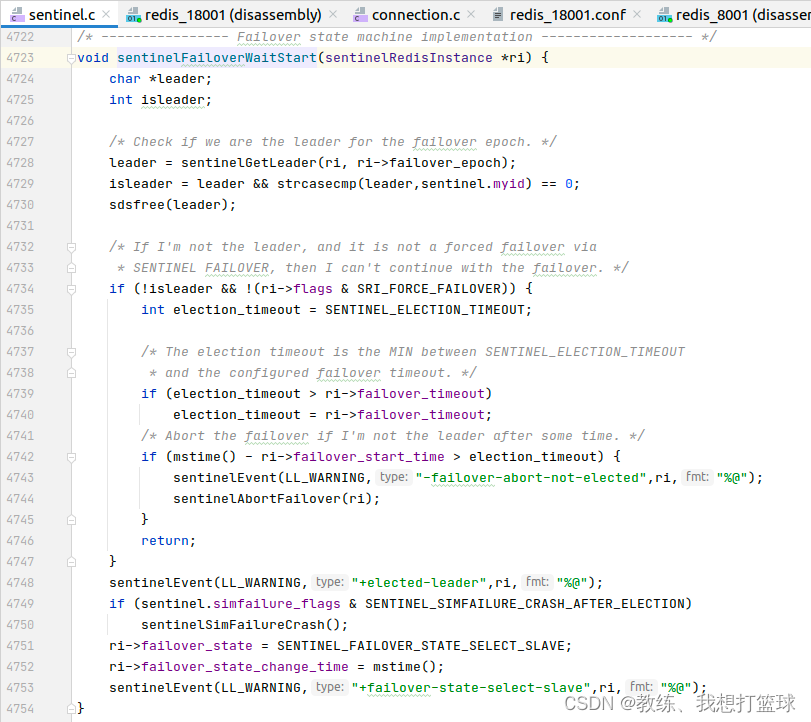
sentinelFailoverWaitStart 选取哨兵?master?
sentinelGetLeader 是选择哨兵?master?的核心逻辑
哨兵master 才会往下面走下面的?从 slave?节点中选择?master?的流程?
?
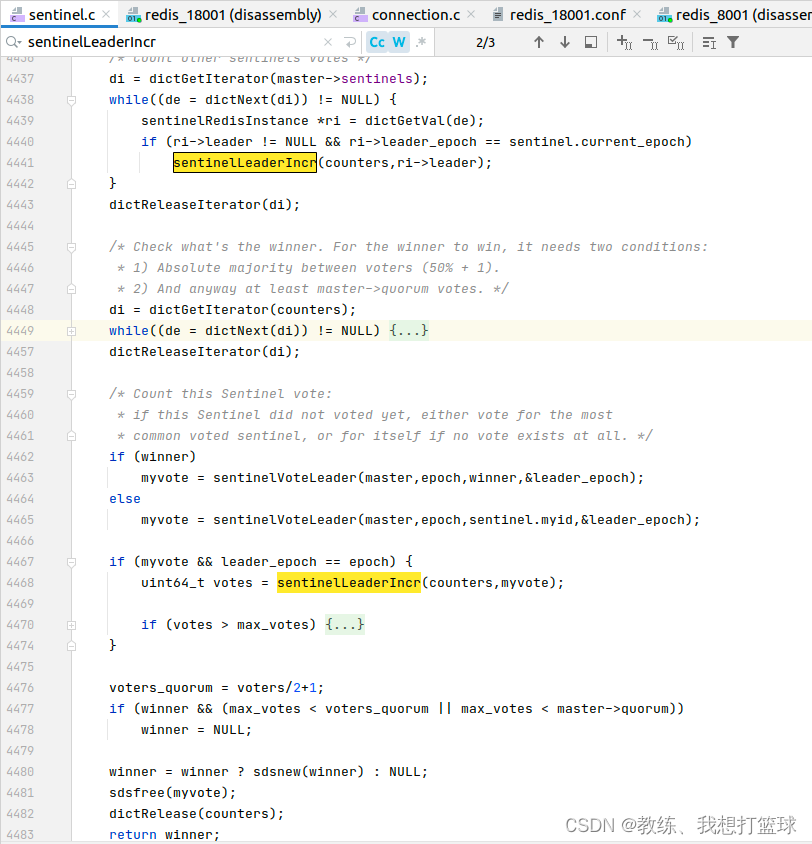
选取哨兵?master?的相关处理?
先统计其他哨兵的相关投标,?然后?自己再进行投票?选择票数最多的哨兵 或者 自己
然后?投票之后,?再来选择?票数最多的哨兵?
最终筛选?是否满足基础条件,?大于?(哨兵数量/2+1) 并且大于?master选举的数量?
?
?
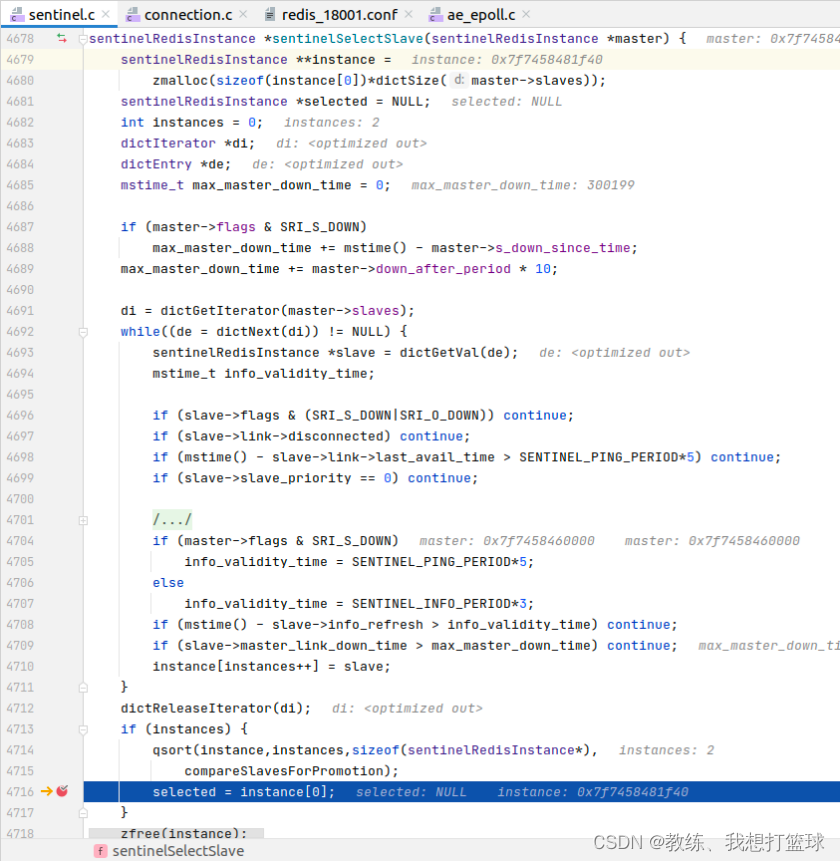
sentinelSelectSlave 选择新的?master?数据节点
处理方式如下,?筛选掉?一部分的节点,?经过筛选的节点为备选列表,?然后还有具体的选择规则?
筛选掉?主观客观下线?的节点?
筛选掉?失联的节点
筛选掉?ping?网络存在问题的节点?
筛选掉?配置 priority?为?0 的节点?
筛选掉?info心跳 超过一定时间的节点
筛选掉和?master?这边失联时间较长的节点,?说明它可能和集群沟通有问题?
?
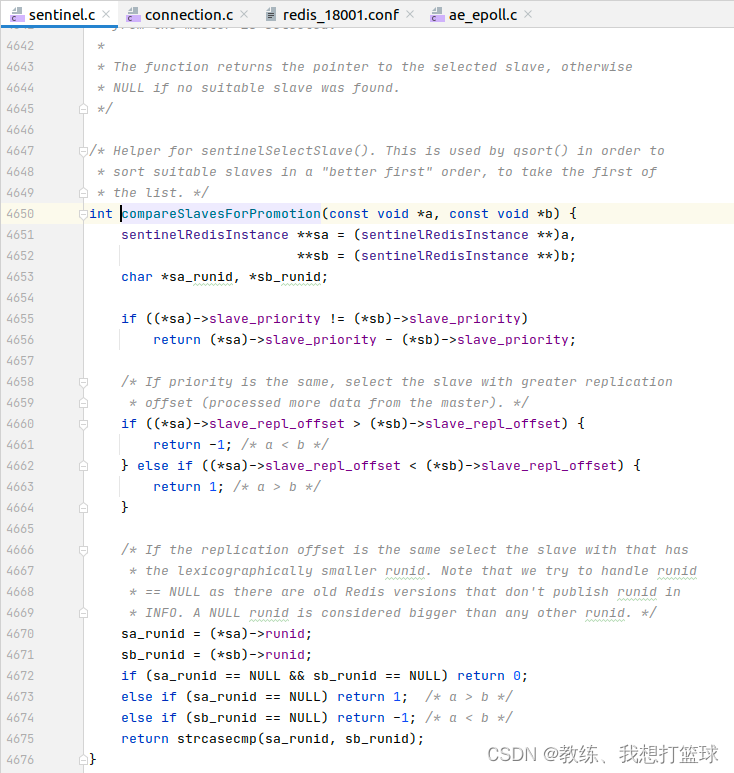
master 这边选择规则如下?
优先级为?slave_priority, slave_repl_offset, runId 的比较?
其中?slave_repl_offset 指代的是?该 slave 节点和 master?这边同步的偏移,?偏移越大,?和?master?这边丢失的数据越少?
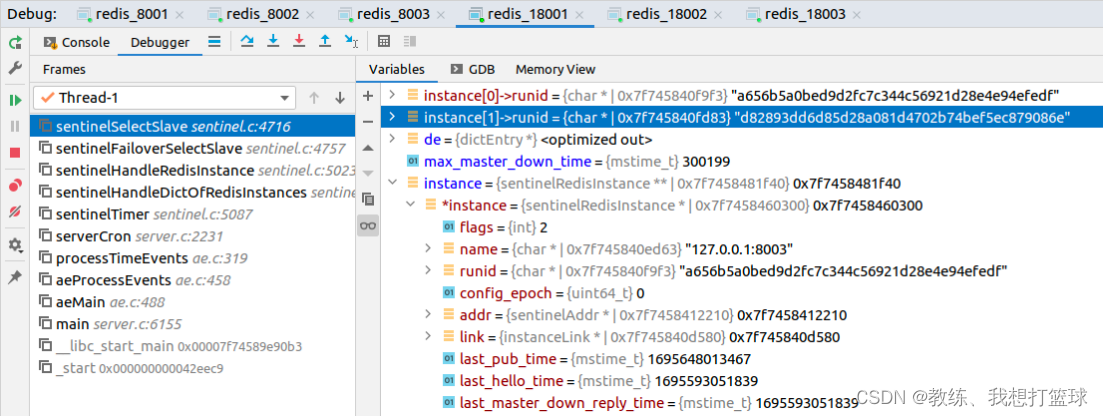
就我们这里的场景,?挂掉了目前的?master?节点?redis_8002, 然后?redis_8001, redis_8003 的?slave_priority, slave_repl_offset 均相同,?然后就是根据?runId 进行选择了?
?
然后上下文如下,?根据?runId 的规则,?选择了?redis_8003, 然后?redis_8003 成为了新的?master?节点?
?
?
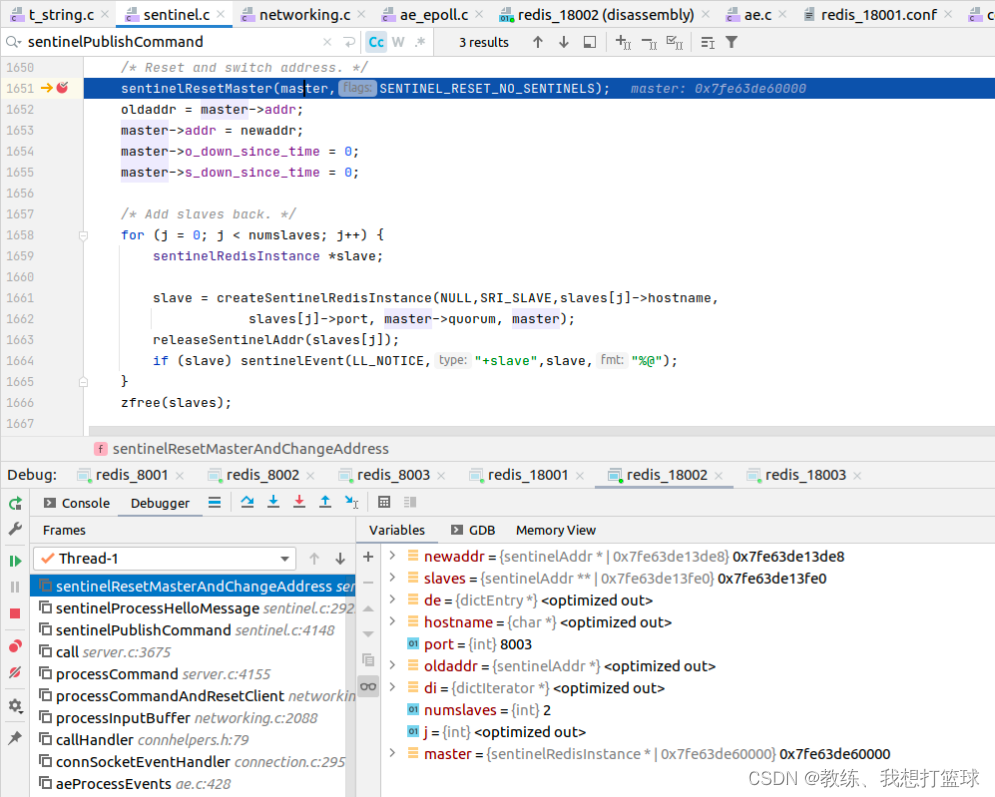
Master 信息的传播
其他的哨兵节点是通过 PUBLISH “__sentinel__:hello” 这边的业务处理来进行更新?master?的?
?
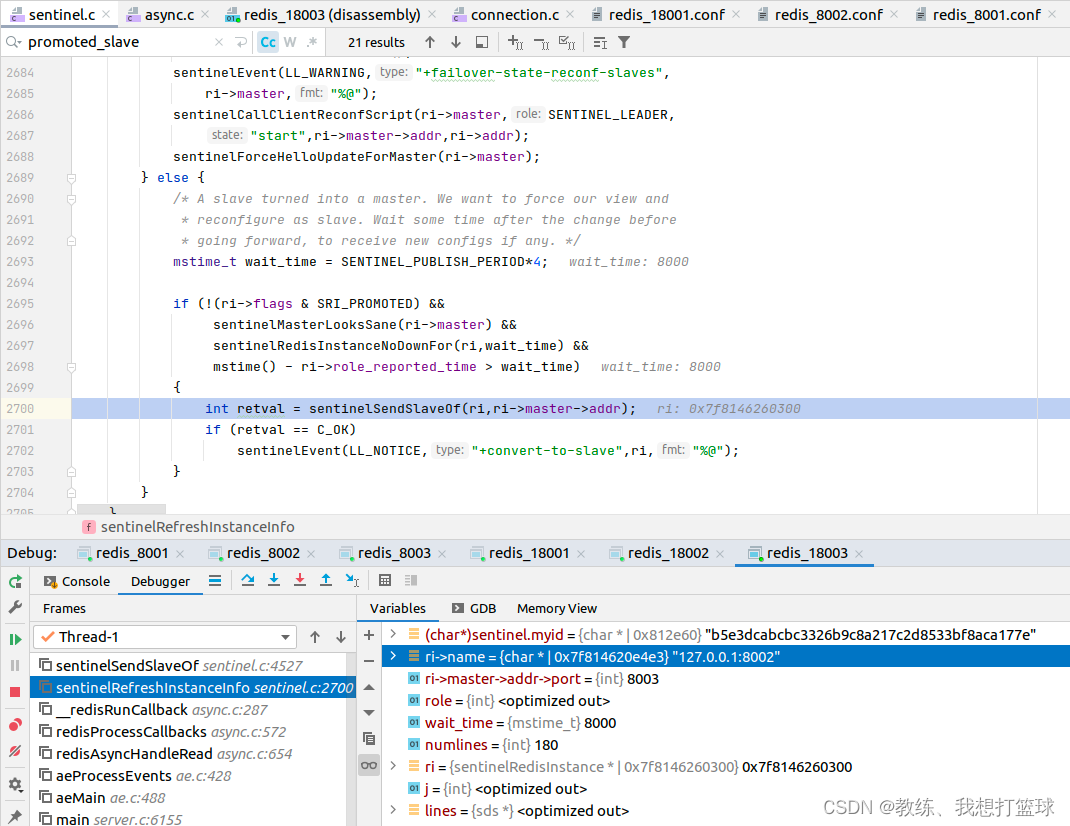
然后从节点这边的?slaveOf 主从关系是?哨兵节点这边向 slave?节点这边发送的信息?
进而通知?其他的 slave?节点,?master 更新了,?需要全量?或者 增量重新同步数据了
?
?
完
?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- unity 编辑器的日志打印界面详解(有些不常见的问题)
- 2024几个测试接口的好工具,效率加倍~
- textarea 内容自适应,高度向上扩展
- 华为交换配置OSPF与BFD联动
- 前后置、断言、提取变量、数据库操作功能
- 哈尔滨学院新生入学系统(源码+开题)
- Nginx优化与防盗链
- docker-compose 升级;yaml文件编写;gpu使用;Portainer监控管理容器
- Linux反向、分离解析与主从复制
- 【面试突击】数据库面试实战(上)