【Hadoop】
Hadoop是一个开源的分布式离线数据处理框架,底层是用Java语言编写的,包含了HDFS、MapReduce、Yarn三大部分。
| 组件 | 配置文件 | 启动进程 | 备注 |
|---|---|---|---|
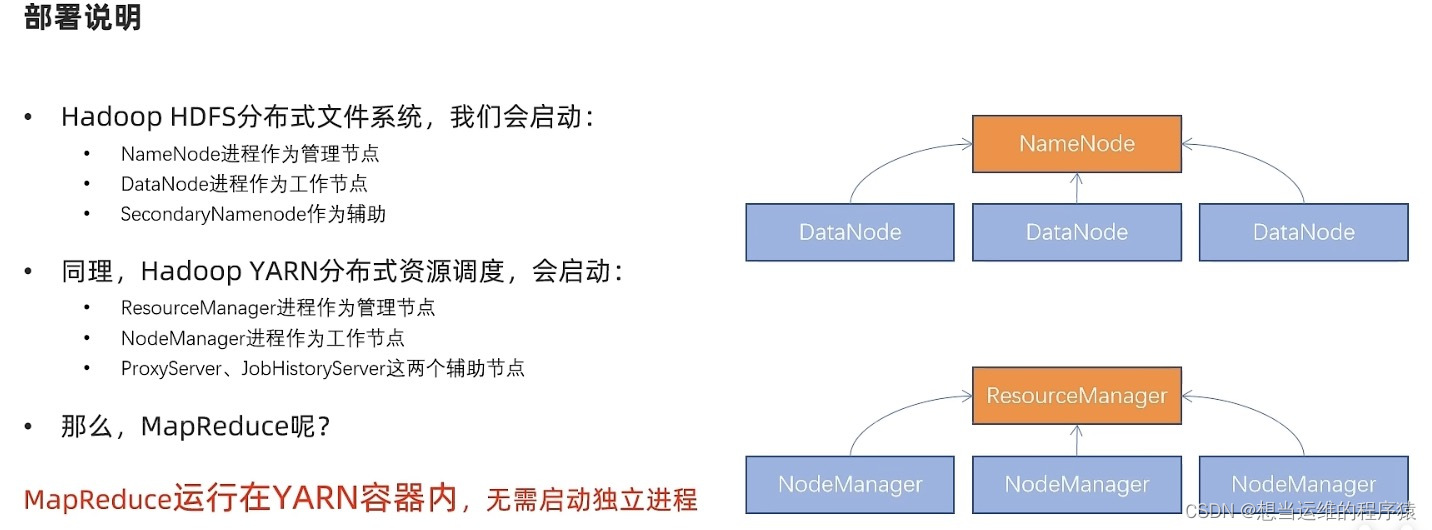
| Hadoop HDFS | 需修改 | 需启动 NameNode(NN)作为主节点 DataNode(DN)作为从节点 SecondaryNameNode(SNN)主节点辅助 | 分布式文件系统 |
| Hadoop YARN | 需修改 | 需启动 ResourceManager(RM)作为集群资源管理者 NodeManager(NM)作为单机资源管理者 ProxyServer代理服务器提供安全性 JobHistoryServer历史服务器记录历史信息和日志 | 分布式资源调度 |
| Hadoop MapReduce | 需修改 | 无需启动任何进程 MapReduce程序运行在YARN容器内 | 分布式数据计算 |
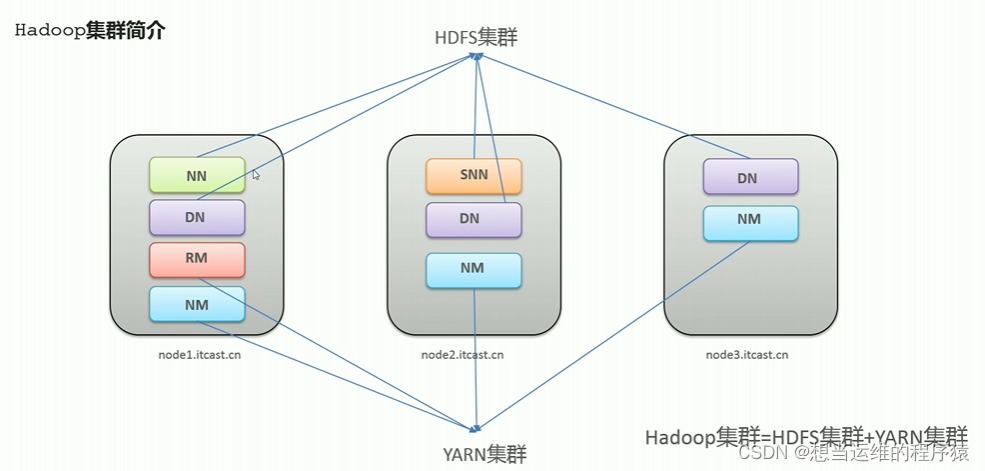
Hadoop集群 = HDFS集群 + YARN集群
图中是三台服务器,每个服务器上运行相应的JAVA进程
HDFS集群对应的web UI界面:
http://namenode_host:9870(namenode_host是namenode运行所在服务器的ip地址)
YARN集群对应的web UI界面:http://resourcemanager_host:8088(resourcemanager_host是resourcemanager运行所在服务器的ip地址)
一、HDFS
1.1 HDFS简介
- HDFS的全称为Hadoop Distributed File System,是用来解决大数据存储问题的,分布式说明其是横跨多台服务器上的存储系统
- HDFS使用多台服务器存储文件,提供统一的访问接口,使用户像访问一个普通文件系统一样使用分布式文件系统
- HDFS集群搭建完成后有个抽象统一的目录树,可以向其中放入文件,底层实际是分块存储(物理上真的拆分成多个文件,默认128M拆分成一块)在HDFS集群的多个服务器上,具体位置是在hadoop的配置文件中所指定的
- HDFS只支持对文件进行移动,读取、删除、追加操作,不支持任意修改文件。(一次写入,多次读取。只能追加,不能修改。)
1.2 HDFS shell命令行
- 命令行界面(command-line interface,缩写:cli),指用户通过指令进行交互
- Hadoop操作文件系统shell命令行语法:
hadoop fs [generic options]- 大部分命令与linux相同
hadoop fs -ls file:/// # 操作本地文件系统
hadoop fs -ls hdfs://node1:8020/ # 操作HDFS文件系统,node1:8020是NameNode运行所在的机器和端口号
hadoop fs -ls / #直接根目录,没有指定则默认加载读取环境变量中fs.defaultFS的值,作为要读取的文件系统
上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> <dst>
# 将本地文件传到HDFS文件系统中
# -f 覆盖目标文件
# -p 保留访问和修改时间,所有权和权限
# <localsrc>本地文件系统中的文件(客户端所在机器),<dst>HDFS文件系统的目录
下载HDFS文件
hadoop fs -get [-f] [-p] <src> <localdst>
# 将本地文件传到HDFS文件系统中
# -f 覆盖目标文件
# -p 保留访问和修改时间,所有权和权限
# <src>HDFS文件系统中的文件,<localdst>本地文件系统的目录
追加数据到HDFS文件中
hadoop fs -appendToFile <localsrc>...<dst>
# <localsrc>本地文件系统中的文件,<dst>HDFS文件系统的文件(没有文件则自动创建)
# 该命令可以用于小文件合并
1.3 HDFS架构
HDFS包含3个进程NameNode、DataNode、SecondaryNameNode
(都是Java进程,可以在服务器上运行jps查看正在执行的java进程)
HDFS是主从模式(Master - Slaves),基础架构如下:
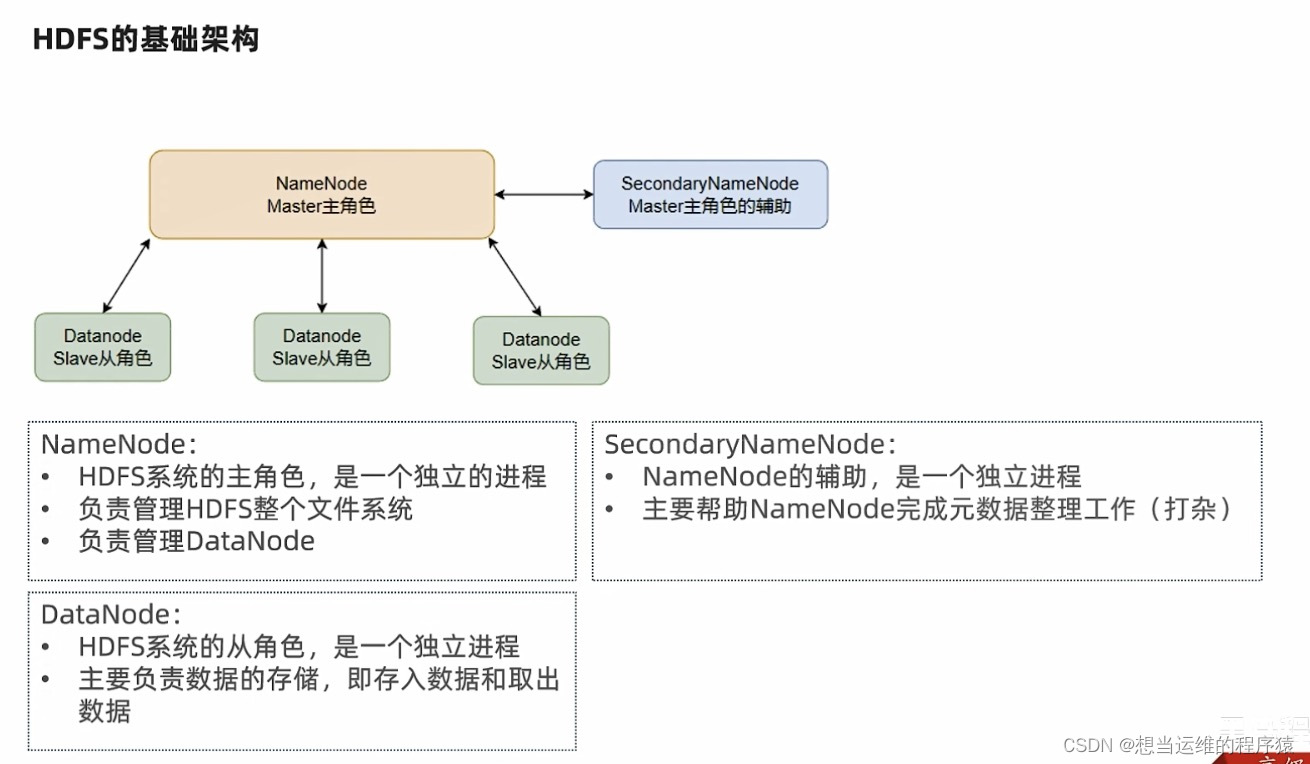
- NameNode: 维护和管理文件系统元数据,包括HDFS目录树结构,文件和块的存储位置、大小、访问权限等信息。NameNode是访问HDFS的唯一入口
- DataNode: 负责具体的数据块存储,定期向NameNode汇报心跳(默认每10分钟)信息
- SecondNameNode: 是NameNode的辅助节点,但不能替代NameNode。主要是进行元数据文件(FsImage和EditsLog)的合并并推送给NameNode。
- NameNode不持久化存储每个文件中各个块所在的DataNode的位置信息,这些信息在系统启动时从DataNode重建
- NameNode是Hadoop集群中的单点故障
- NameNode所在机器通常配置大内存(RAM),因为元数据都存在内存中,定时进行持久化存到磁盘中。
- DataNode所在机器通常配置大硬盘空间,因为数据存在DataNode中
HDFS集群部署举例:
node1、node2、node3表示三台服务器,形成一个集群:

node1服务器性能比较高,因此在node1上运行三个进程:NameNode、DataNode、SecondaryNameNode
在node2及node3上只运行DataNode进程
1.4 HDFS写数据流程
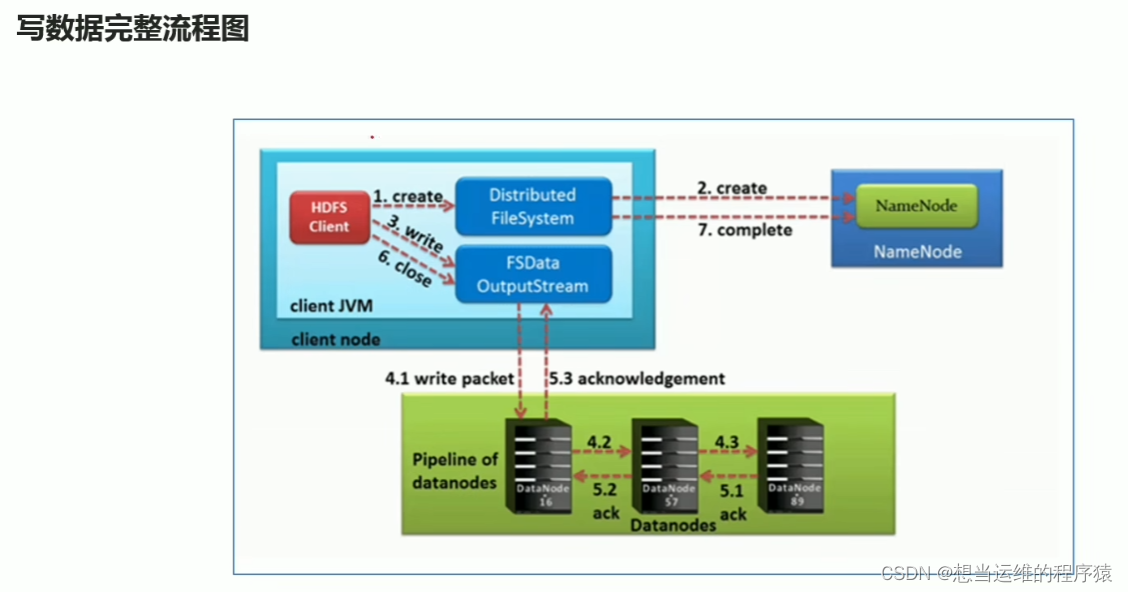
- HDFS客户端创建对象实例DistributeFileSystem(Java类的对象),该对象中封装了与HDFS文件系统操作的相关方法。
- 调用DistributeFileSystem对象的create()方法,通过RPC请求NameNode创建文件,NameNode执行各种检查判断:目标文件是否存在,客户端是否有权限等。检查通过后返回FSDataOutputStream输出流对象给客户端用于写数据。
- 客户端用FSDataOutputStream开始写数据
- 客户端写入数据时,将数据分成一个个数据包(packet 默认64k),内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储(即3个DataNode)。DataStreamer将数据包流式传输(每一个packet 64k传输一次)到pipeline的第一个DataNode,第一个DataNode存储数据后传给第二个DataNode,第二个DataNode存储数据后传给第三个DataNode。
- 传输的反方向上,会通过ACK机制校验数据包传输是否成功
- 客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。
- DistributeFileSystem告诉NameNode文件写入完成。
二、Yarn
2.1 Yarn简介
Yarn是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。
通用: 不仅支持MapReduce程序,理论上支持各种计算程序,YARN只负责分配资源,不关心用资源干什么。
资源管理系统: 集群的硬件资源,和程序运行相关,比如内存、cpu等
调度平台: 多个程序同时申请计算资源如何分配,调度的规则
2.2 Yarn架构
Yarn与HDFS一样,也是主从模式,包含以下4个进程
- ResourceManager:管理整个群集的资源,负责协调调度各个程序所需的资源。(申请资源必须找RM)
- NodeManager:管理单个服务器的资源,负责调度单个服务器上的资源提供给应用程序使用。
NodeManager通过创建Container容器来分配服务器上的资源。
应用程序运行在NodeManager所创建的容器中。
一个服务器上可以创建多个Container容器,各Container容器之间相互独立,实现了一个服务器上跑多个程序。
Container容器是具体运行 Task(如 MapTask、ReduceTask)的基本单位。
一个NodeManager上会运行多个Container。
- ProxyServer代理服务器: ProxyServer默认继承在ResourceManager中,可以通过配置分离出来单独启动,可以提高YARN在开放网络中的安全性。
- JobHistoryServer历史服务器: 记录历史程序运行信息和日志,开放web ui提供用户通过网页访问日志。
YARN架构图:
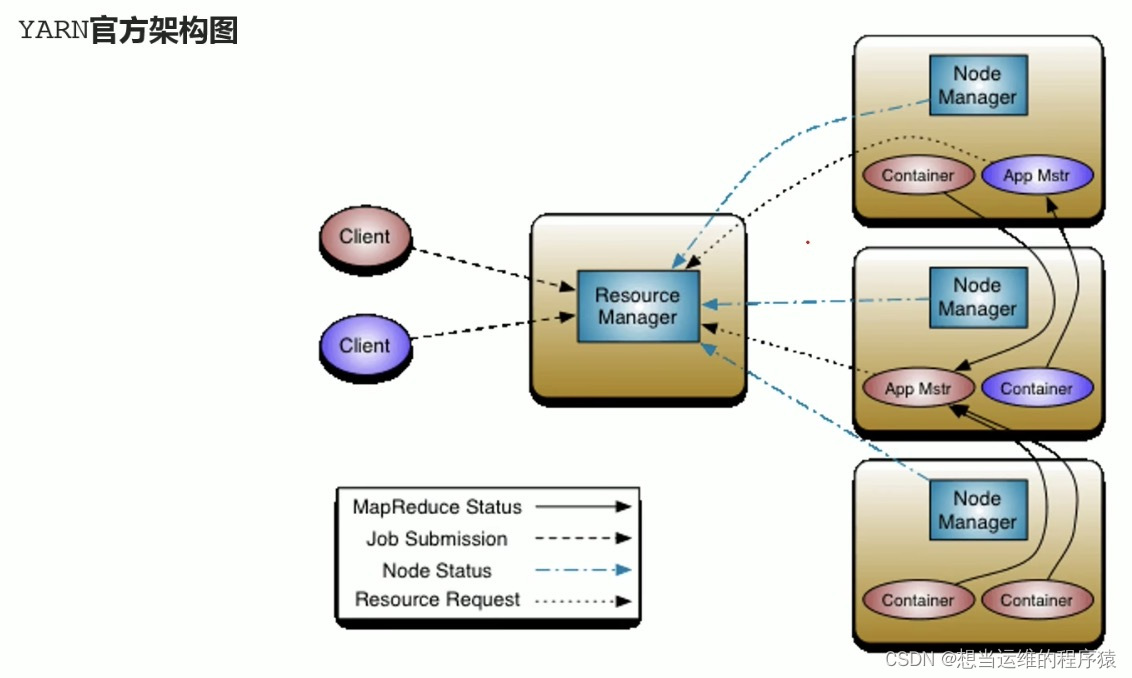
ApplicationMaster(App Mstr): 应用程序内的“老大”,负责程序内部各阶段的资源申请,管理整个应用。(当YARN上没有程序运行,则没有这个组件)
一个应用程序对应一个ApplicationMaster。
ApplicationMaster 运行在 Container 中,是应用程序的第一个Container,之后会请求ResourceManager要更多的Container,来运行应用的各个任务(比如 MapTask、ReduceTask)。
YARN 中运行的每个应用程序都有一个自己独立的 ApplicationMaster。(以MapReduce为例,其中的MRAppMaster就是对应的具体实现,管理整个MapReduce程序)
YARN集群部署举例:
node1、node2、node3表示三台服务器,形成一个集群:

node1性能高,因此在node1上运行四个进程:ResourceManager、NodeManager、ProxyServer、JobHistoryServer
在node2及node3上只运行NodeManager进程
2.3 Yarn调度器和调度算法
Hadoop作业调度器主要有三种:FIFO Scheduler(先进先出调度器)、Capacity Scheduler(容量调度器)和Fair Scheduler(公平调度器)
Apache Hadoop 3.1.3默认的资源调度器是CapacityScheduler。
- FIFO Scheduler:单队列,根据提交作业的先后顺序,依次执行
- Capacity Scheduler:多队列,每个队列配置一定的资源,每个队列内部采用FIFO策略
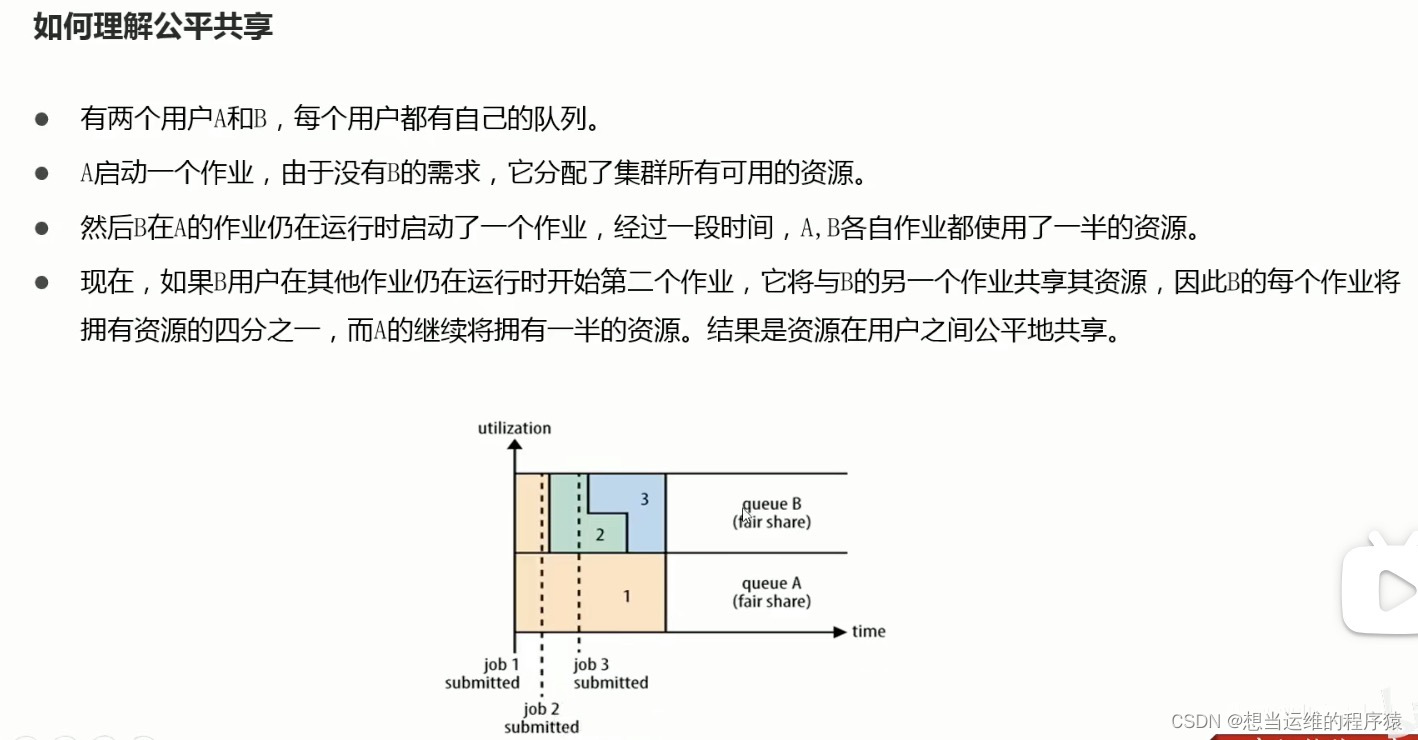
- Fair Scheduler:资源在每个用户之间公平共享,充分利用资源
三、MapReduce
MapReduce只能用来做离线计算,不能做实时计算。
MapReduce程序在运行时有三类进程:
- MRAppMaster:负责整个MR程序的过程调度及状态协调
- MapTask: 负责map阶段的整个数据处理流程
- ReduceTask: 负责reduce阶段的整个数据处理流程,一个ReduceTask输出一个文件,多个ReduceTask则会输出多个文件
- 在一个MR程序中MRAppMaster只有一个,MapTask和ReduceTask可以有一个也可以有多个
- 在一个MR程序中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段
- 在整个MR程序中,数据都是以kv键值对的形式流转的
MapReduce整体执行流程图:
左边是maptask,右边是reducetask,红框里是shuffle过程(shuffle包含了map和reduce)
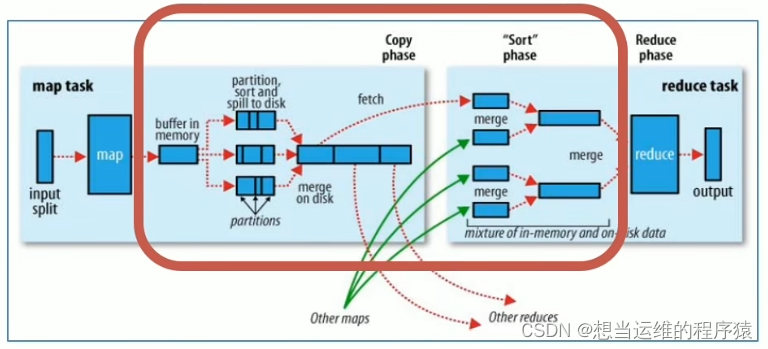
2.1 map阶段执行过程(2次排序,溢出之前进行排序(快速排序),所有溢出文件合并后排序(归并排序))
- 第一阶段: 把所要处理的文件进行逻辑切片(默认是每128M一个切片),每一个切片由一个MapTask处理。
hdfs中文件存储的block默认也是128M,是物理切片,真的将文件拆开
mapreduce的切片是逻辑切片,并不会将文件拆开
例如mapreduce设置切片为100M,一个文件512M,HDFS上存储为4个block,逻辑切片为6个,开启6个MapTask执行计算
- 第二阶段: 按行读取切片中的数据,返回<key,value>对,key对应行数,value是本行的文本内容
- 第三阶段: 调用Mapper类中的map方法处理数据,每读取解析出来一个<key,value>,调用一次map方法
- 第四阶段(默认不分区): 对map输出的<key,value>对进行分区partition。默认不分区,因为只有一个reducetask,分区的数量就是reducetask运行的数量。
- 第五阶段: Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill之前会根据key按照字典序(a~z)对每个溢出文件内部进行排序sort(这一步会溢出很多排序好的小文件)
- 第六阶段: 对所有溢出的文件进行最终的merge合并,合并后再次排序,形成一个文件(即确保一个maptask只输出一个文件)
2.2 reduce阶段执行过程(1次排序,所有maptask输出的文件合并后进行排序(归并排序))
- 第一阶段: ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据
- 第二阶段: 把拉取来的数据,全部进行合并merge,即把分散的数据合并成一个大的数据,再对合并后的数据进行排序
- 第三阶段: 对排序后的<key,value>调用reduce方法,key相同<key,value>调用一次reduce方法。最后把输出的键值对写入到HDFS中
2.3 shuffle机制
- shuffle指的是将map端的无规则输出变成具有一定规则的数据,便于reduce端接收处理。
- 一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称为Shuffle
- Shuffle过程是横跨map和reduce两个阶段的,分别称为Map端的Shuffle和Reduce端的Shuffle
- Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复,是导致mapreduce计算慢的原因
- 分组、排序、Combiner、分组
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vscode怎么运行程序代码的两种方法
- (JAVA)-(网络编程)-UDP协议
- asp.net core跨域
- Mysql主从同步和mysqldump备份
- 国军标质量管理体系认证的步骤和要求?
- 修改iview的表格table展开的默认icon和样式
- 加入Microsoft Teams会议的几种方法,总有一种适合你
- 数据结构 | 数组
- LOG360:构建坚实网络安全防线的利器
- 高级 Bootstrap:发挥 Sass 定制的威力