K8S的HPA
| horiztal Pod Autoscaling:pod的水平自动伸缩,这是k8s自带的模块,它是根据Pod占用cpu比率到达一定的阀值,会触发伸缩机制 Replication controller ?副本控制器:控制pod的副本数 Deployment controller 节点控制器:部署pod Hpa:控制副本的数量以及控制部署pod |
| 如何检测 | Hpa是基于kube-contrroll-manager服务,周期性的检测pod的cpu使用率,默认是30秒检测一次 |
| 如何实现 | Hpa和replication controller,deployment controller,都属于k8s的资源对象,通过跟踪分析副本控制器和deployment的pod负载变化,针对性的地调整目标pod的副本数。 阀值:正常情况下,pod的副本数,以及达到阀值之后,pod的扩容最大数量 |
| 组件 | Metrics-server 部署到集群中,对外提供度量的数据 |
[root@master01 opt]# cd k8s/
[root@master01 k8s]# ls
a.yaml components.yaml metrics-server.tar
[root@master01 k8s]# docker load -i metrics-server.tar
[root@master01 k8s]# vim components.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
replicas: 3
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
image: bitnami/metrics-server:0.6.2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
[root@master01 k8s]# kubectl get pod -n kube-system
[root@master01 k8s]# kubectl top pod
[root@master01 k8s]# kubectl top node
[root@master01 k8s]# vim a.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: centos-test
labels:
test: centos1
spec:
replicas: 1
selector:
matchLabels:
test: centos1
template:
metadata:
labels:
test: centos1
spec:
containers:
- name: centos
image: centos:7
command: ["/bin/bash","-c","yum -y install epel-release;yum -y install stress;sleep 3600"]
resources:
limits:
cpu: "1"
memory: 512Mi
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-centos7
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: centos-test
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
[root@master01 k8s]# kubectl apply -f a.yaml
[root@master01 k8s]# kubectl top node
[root@master01 k8s]# kubectl get pod -o wide
[root@master01 k8s]# kubectl get hpa
[root@master01 k8s]# yum -y install stree
[root@master01 k8s]# kubectl exec -it centos-test-b7cd8766d-g84h9 bash
[root@centos-test-b7cd8766d-g84h9 /]# stress --cpu 2
[root@master01 k8s]# kubectl taint node node01 key=1:NoExecute
node/node01 tainted
[root@master01 k8s]# kubectl taint node node02 key=2:NoExecute
node/node02 tainted
[root@master01 k8s]# kubectl describe nodes node01 | grep -i taints
Taints: key=1:NoExecute
[root@master01 k8s]# kubectl describe nodes node02 | grep -i taints
Taints: key=2:NoExecute
[root@master01 k8s]# kubectl get hpa -w

 ?
?
?HPA的规则
| 1 | 定义pod的时候必须要有资源限制,否则HPA无法进行监控 |
| 2 | 扩容时即时的,只要超过阀值会立刻扩容,不是立刻扩容到最大副本数,他会在最小值和最大值之间波动,如果扩容数量满足了需求,就不会再扩容 |
| 3 | 缩容是缓慢地,如果业务的峰值较高,回收的策略太积极的话,可能会产生业务的崩溃,所以缩容的速度是缓慢的,周期性的获取数据,缩容的机制问题 |
?Pod的副本数扩缩容有两种方式
| 手动方式 | 手动方式,修改控制器的副本数 Kubectl scale deployment nginx1 --replicas=5 修改yaml文件,apply -f 部署更新 |
| 自动扩缩容 | Hap的监控的是cpu |
资源限制
| pod的资源限制:在部署pod的时候加入resources字段,通过limits/request来对pod进行限制。 除了pod的资源限制还有命名空间的资源限制 |
命名空间资源限制
| 如果你有一个lucky-cloud项目部署在test1的命名空间。如果lucky-cloud不做限制或者命名空间不做限制,他依然会占满所有集群资源。 k8s集群部署pod的最大数量:1万个 |
vim ns.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: centos-test2
namespace: test1
labels:
test: centos2
spec:
replicas: 11
selector:
matchLabels:
test: centos2
template:
metadata:
labels:
test: centos2
spec:
containers:
- name: centos
image: centos:7
command: ["/bin/bash", "-c", "yum -y install epel-release;yum -y install stress;sleep 3600"]
resources:
limits:
cpu: 1000m
memory: 512Mi
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: ns-resource
namespace: test1
spec:
hard:
#硬限制
pods: "10"
#表示在这个命名空间内只能部署10个pod
requests.cpu: "2"
#最多只能占用多个个cpu
requests.memory: 1Gi
#最多只能占用多少内存
limits.cpu: "4"
#最大需要多少cpu
limits.memory: 2Gi
#最大需要多少内容
configmaps: "10"
#当前命名空间内能创建最大的configmap的数量 10个
persistentvolumeclaims: "4"
#当前命名空间只能使用4个pvc
secrets: "9"
#创建加密的secrets。只能9个
services: "5"
#创建service只能5个
services.nodeports: "2"
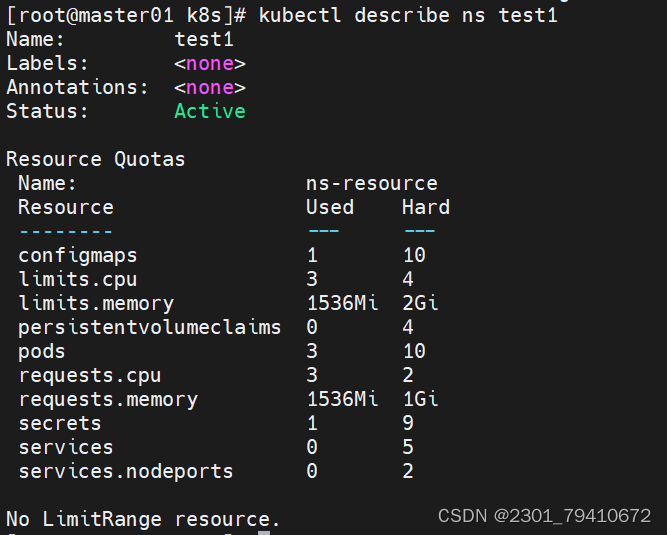
#nodeport类型的svc只能2个[root@master01 k8s]# kubectl describe ns test1
#查看命名空间的限制
 ?
?
?通过命名空间的方式对容器进行限制
vim ns2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: centos-test
namespace: test2
labels:
test: centos2
spec:
replicas: 1
selector:
matchLabels:
test: centos1
template:
metadata:
labels:
test: centos1
spec:
containers:
- name: centos
image: centos:7
command: ["/bin/bash", "-c", "yum -y install epel-release;yum -y install stress;sleep 3600"]
---
apiVersion: v1
kind: LimitRange
#表示使用limitrange来进行资源控制的类型
metadata:
name: test2-limit
namespace: test2
spec:
limits:
- default:
memory: 512Mi
cpu: "1"
defaultRequest:
memory: 256Mi
cpu: "0.5"
type: Container
#对所有部署在这个命名空间内的容器统一进行资源限制
#default: limit
#defaultRequest: request
#type: Container、Pod、Pvc都可以总结
| HPA自动扩缩容 命名空间 第一种 ResourceQuota 可以对命名空间进行资源限制 第二种 LimitRange 直接声明在命名空间当中创建pod。容器的资源限制,这是一种统一限制,所有的pod都受这个条件的制约 Pod的资源限制:一般是我们创建的时候声明号的,必加选项 直接使用resources: ??????????limit: 命名空间资源限制:对命名空间使用cpu和内存一定会做限制,上面和这个两个都必须要做 ResourceQuota 核心: 防止整个集群的资源被一个服务或者一个命名空间占满 命名空间统一资源限制 |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python基础 10 -- 元组&集合
- C语言的前置声明
- P1003 [NOIP2011 提高组] 铺地毯————C
- MURD1060-ASEMI快恢复TO-252封装二极管MURD1060
- 文献速递:人工智能医学影像分割---基于合成MRI辅助的深度注意力全卷积网络的CT前列腺分割
- 物理服务器和大宽服务器的区别对比
- 关于超大目录数据异常增长的问题排查
- CG Magic分享为什么3d渲染时,渲到一半进度条不动呢?
- chisel入门初步1——基4的booth编码的单周期有符号乘法器实现
- 代码随想录算法训练营第六天|哈希表理论基础,242.有效的字母异位词,349. 两个数组的交集,202. 快乐数,1. 两数之和