FAST-LIO2:论文和算法解析
文章目录
题目:FAST-LIO2:快速直接激光雷达惯性里程计
参考链接:
ikd-Tree: 港大开源增量式 kd-tree 结构
kd-tree 原理深入理解
本文对FAST-LIO2论文进行翻译解析,非逐句翻译,对一些介绍性内容进行总结,对关键算法给出一些自己的理解。
整体上看,FAST-LIO2的改进点主要在第一个版本上增加了ikd-tree和去除了特征匹配,采用直接匹配的方式构建残差。
摘要
本文介绍了FAST-LIO2算法:一种快速、鲁棒、通用的激光雷达-惯性里程计框架。FAST-LIO2基于高效的紧密耦合迭代卡尔曼滤波器,具有两个关键的新颖之处,可实现快速,稳健和准确的激光雷达导航(和测绘)。
第一种方法是直接将原始点注册到地图上然后更新地图,而不提取特征。这样可以利用环境中的细微特征,从而提高准确性。消除手工设计的特征提取模块,也使其能够适应不同扫描模式的新兴激光雷达;第二个主要的新颖之处是通过增量k-d树数据结构(ikd-Tree)来维护映射,这使得增量更新(即激光点插入、删除)和动态重新平衡成为可能。与现有的动态数据结构(八叉树,R*-tree,nanoflann k-d tree)相比,ikd-Tree进行下采样时可以获得更好的整体性能。
我们对来自各种公开LiDAR数据集的19个序列进行了详尽的基准比较。FAST-LIO2与其他先进的激光雷达惯性导航系统相比,在更低的计算负荷下实现了更高的精度。在小视场的固态激光雷达上进行了各种实际实验。总体而言,FAST-LIO2具有计算效率高(例如,在大型室外环境中高达100Hz的里程计和建图),鲁棒性强(例如,在旋转高达1000度/秒的杂室内环境中得到可靠的姿态估计),多用途(即适用于多线机械雷达和固态激光雷达,无人机和手持平台,以及基于英特尔和arm的处理器),同时仍然实现比现有方法更高的精度。我们实现的系统FAST-LIO2和数据结构ikd-Tree在Github上都已经开源。
一、简介
视觉SLAM可以提供精确的定位结果,但是无法提供3D稠密地图用于避障和路径规划。
激光LIDAR可以解决上述问题,且当前激光雷达的体积结构、成本和性能都在不断优化。使得广泛应用和商业化成为可能。
激光雷达在SLAM技术中的应用同样也存在一些问题:
- LIDAR数据量庞大,对计算效率要求高
- 面对无结构环境,基于特征提取的激光SLAM方法效果不佳,同时也会收到FOV、扫描方式和点密度的影响,需要很多额外数据处理的适配工作
- IMU可以弥补LIDAR的运动畸变,但本身的偏置和外参等信息需要进行标注和更新
- 针对点云在空间中的稀疏分布问题,需要高效的点云检索方法
在这项工作中,我们通过两个关键的新技术:增量k-d树和直接点配准来解决这些问题。更具体地说,我们的贡献如下:
- 增量k-d树数据结构
提供高校的最近邻搜索,支持增量式地图更新,包括云点的插入与删除、树的上采样和下采样,极大减少计算成本,在计算资源受限可以达到100HZ的里程计和建图频率。 - 基于IKD-TREE的原始点云配准
基于ikd-Tree,实现原始点云的注册,而非基于特征提取方法,使算法可以适应不同的环境和LIDAR传感器。 - 将上述改进应用到FAST-LIO中
- 在丰富的数据集和工作环境测了算法的性能,并和其他算法进行对比分析。
二、相关工作
2.1雷达惯导里程计
1. 纯激光SLAM
目前纯激光SLAM多参考了LOAM结构,分为特征提取,里程计和建图三个模块。为减小匹配计算量对点云进行了特征提取,然后通过scan-to-scan和scan-to-map获取精确的位姿信息。LEGO-LOAM在匹配时分离的地面点减小计算,并引入回环检测。LOAM-Livox算法直接基于scan-to-map实现里程计位姿估计提高了位姿估计精度,但是由于每一步都需要更新地图点k-d树使得计算量增加。
2. 雷达-惯导里程计
IMU在激光SLAM中的作用主要有3个:
(1)提供点云匹配的初始位姿
(2)用于去除点云的运动畸变
(3)将基于IMU的状态估计加入到SLAM的残差方程,实现紧耦合
FAST-LIO2基于FAST-LIO算法实现,在之前工作的基础上提出一种新的数据结构数据结构ikd-Tree,同时基于该数据结构实现点云到地图的直接匹配,在减小计算量的同时scan-to-map的匹配方式提高了位姿估计精度。
2.2 建图过程中的动态数据结构
为了实现建图,需要一种动态的数据结构支持增量更新和高校的kNN搜索。
-
R-TREE
基于数据在空间上的接近程度聚类为一个矩形,该矩形包括了相互距离接近的几个叶节点。然后该矩形和其同一节点的其他矩形被更大的矩形包含,依次类推直到根节点。
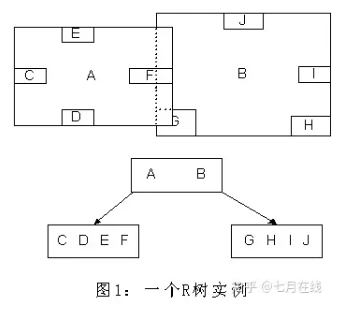
-
R*-TREE
R* 树和R树一样允许矩形的重叠,但在构造算法R*树不仅考虑了索引空间的“面积”,而且还考虑了索引空间的重叠。 -
八叉树
八叉树通过递归地将空间均匀地分成八个轴对齐的立方体来组织三维点云。当立方体为空或满足停止规则(例如,最小分辨率或最小点数)时,立方体的细分停止。新的点被插入到八叉树上的叶节点上,如果有必要,将应用进一步的细分。八叉树同时支持kNN搜索和箱形搜索,后者返回给定轴对齐长方体中的数据点。 -
K-D树
(1)最上层为根节点,最下层为叶子节点,其余为中间节点
(2)上层节点是下层节点的父节点
(3)下层节点是上层节点的子节点,子节点根据维度的比较分左右子节点,也即父节点的左子树和右子树
(4)每一层都需要指定一个维度(如3D坐标XYZ中的X维度),并在该维度上取一个值,X小于该值的点被划分到左子树,大于该值被划分为右子树
(5)每到下一层,需要选择新的划分维度和划分值,采用方差较大的维度作为本层分割的维度 -
增量kd树:ikd-Tree
传统的静态 kd-tree 结构存在着大量数据增删的情况下会失去平衡性,导致深度不均衡和搜索效率下降等问题,如果为了解决静态 kd-tree 的不均衡问题而频繁重新构建 kdtree 会产生巨大的时间开销。
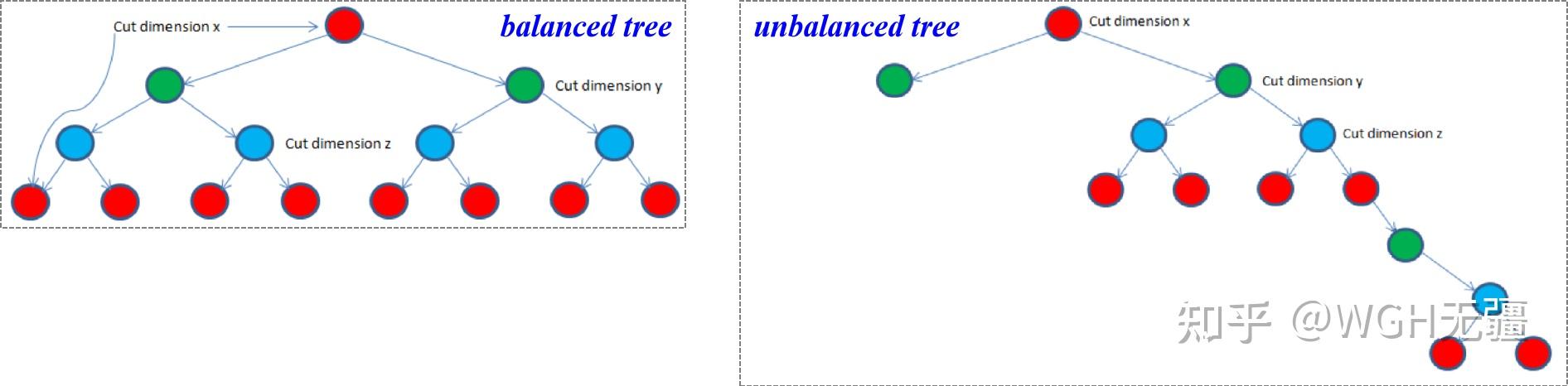
基于这一问题,本文作者提出了ikd-tree,支持增量式的插入和删除,支持自行调整 tree 的结构、始终保持动态平衡。对于删除策略,采用了lazy delete算法,即当需要删除一个节点时,ikd-Tree不直接删除他,而是将这个节点标记为删除状态,在检索时直接跳过。等到下次真正需要更新树时再统一进行删除。
三、系统架构
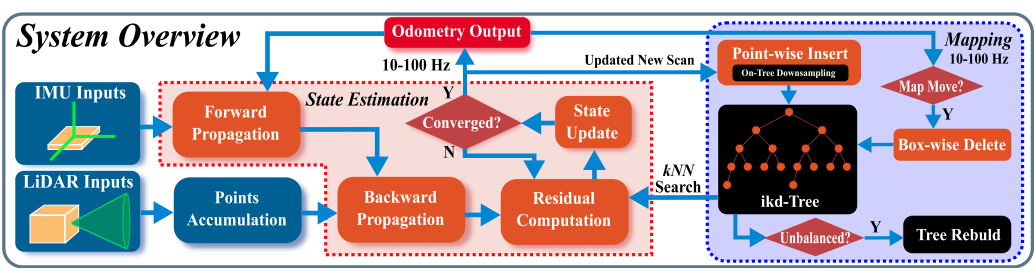
FAST-LIO2的系统架构如上图所示。连续采样的LiDAR原始点首先在10ms和100ms之间的时间段内累积(一般将20ms作为一个周期),累积的点云称为Scan。新Scan中累计的点云会和地图点进行匹配以实现状态估计,该局部地图通过一个紧耦合的迭代卡尔曼滤波器实现(流程图的红色部分)。局部地图中的地图点由ikd-Tree(蓝色大虚线块,见章节5)维护。如果当前LiDAR的FoV跨越地图边界,则从ikd-Tree中删除距离LiDAR姿态最远的地图区域的历史点。因此,ikd-Tree跟踪具有一定长度(本文称为“地图大小”)的大立方体区域内的所有地图点,并在状态估计模块中用于计算残差。优化后的姿态最终将新扫描中的点注册到全局帧中,并以里程计的频率插入到ikd-Tree中实现将它们合并到地图中,这个过程即建图。
四、状态估计
FAST-LIO2的状态估计继承自FAST-LIO的紧耦合迭代卡尔曼滤波[22],但进一步融合了LiDAR-IMU外部参数的在线校准。在这里,我们简要地解释了过滤器的基本配方和工作流程,详细信息请参阅[22]。
A. 卡尔曼模型
1.状态转换模型
定义第一帧IMU为全局坐标系,定义
T
L
I
T^{I}_{L}
TLI?为未知的外参。定义IMU积分模型如公式1,运动学模型如公式2:
公式2表示:当前时刻状态 = 上一时刻状态 + 两个时刻之间的运动
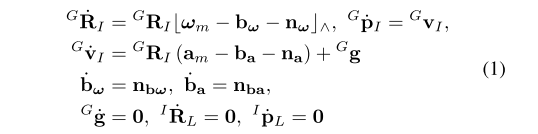
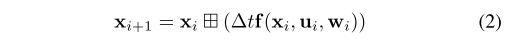
2.测量模型
运动学激光雷达通常一个接一个地对点进行采样。因此,当激光雷达经历连续运动时,所得到的点在不同的姿势下进行采样。为了纠正这种扫描中的运动,我们采用了[22]中提出的反向传播方法,该方法根据IMU测量值估计扫描中每个点相对于扫描结束时的姿态的LiDAR姿态。估计的相对姿态使我们能够根据扫描中每个单独点的精确采样时间将所有点投影到扫描结束时间。因此,可以将扫描中的点视为在扫描结束时同时采样的所有点。
记第K个Scan中第j个点为
p
j
L
p^{L}_{j}
pjL?,Scan中所有的点均已经进行运动补偿投影至Scan结束时刻对应的坐标系下,上标L表示改组点的坐标系为Scan结束时刻对应的坐标系。则考虑噪声影响后的LIDAR点坐标为:
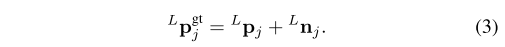
Scan中的某个点通过外参变换到IMU坐标系,然后通过所估计的位姿变换到世界坐标系,该点会存再于全局地图中一个小的平面块上。连接Scan中的投影点与该平面块中的某个点可以得到一个向量(公式4右侧括号中的部分),理想情况下该向量会和平面的法向量垂直,即点乘结果为0,具体表现为公式4。要注意的是k时刻下LIDAR到IMU的外参也是状态变量的一部分。
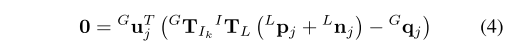
更进一步的,可以将上式写为公式5的形式。
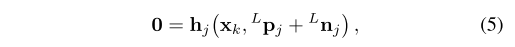
B.迭代卡尔曼滤波
基于IMU积分结果实现预测过程,基于LIDAR的匹配残差实现更新过程。整个过程和FAST-LIO不一样的地方在于LIDAR匹配残差的构建方式,原来通过特征提取和匹配实现帧间匹配和地图匹配,在本文FAST-LIO2中,直接使用scan-to-map的方法进行匹配(具体见2残差计算)。
本篇只做简述,详细过程见博客:
《FAST-LIO论文解析》
1. 预测过程
即IMU积分过程,见公式6:
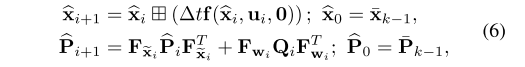
2. 残差计算
对于k个Scan的状态
x
k
x_k
xk?的第k次迭代,更新结果为
x
^
k
k
\hat{x}^{k}_{k}
x^kk?,当
k
=
0
k=0
k=0时,
x
^
k
k
=
x
k
\hat{x}^{k}_{k}=x_k
x^kk?=xk?。然后将Scan中的每个点投影到世界坐标系下,并通过ikd-tree找到与该点最接近的5个点。由这5个点可以得到平面的法向量
u
j
u_j
uj?和质心
q
j
q_j
qj?,然后可以通过测量模型构建残差方程:
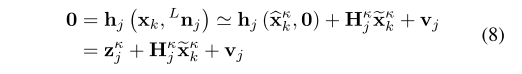
3.迭代更新
推导过程省略了,详细过程见博客:
《FAST-LIO论文解析》
总之就是最终构建了关于IMU预测过程以及基于LIDAR匹配残差的最大后验分布(MAP),公式13的意义即求解使得误差最小时对应的系统状态。
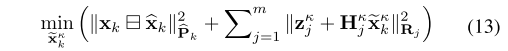
对与同一个Scan数据,基于迭代卡尔曼滤波会不断对系统状态进行更新,假设迭代m次。则将迭代过程中更新部分产生的一阶雅格比
H
j
k
H^{k}_{j}
Hjk?,误差的协方差矩阵
R
j
R_j
Rj?和匹配残差
z
j
z_j
zj?整合起来,最终得到迭代卡尔曼滤波的更新方程:

最后更新最优状态估计、误差的协方差矩阵、世界坐标系下的LIDAR坐标(因为外参未知,所以也需要估计),对应公式15和公式16
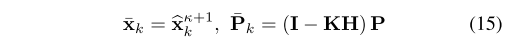
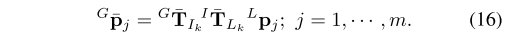
算法伪代码如下:
输入:上一个SCAN的最优状态估计
x
ˉ
k
?
1
\bar{x}_{k-1}
xˉk?1?和
p
ˉ
k
?
1
\bar{p}_{k-1}
pˉ?k?1?
当前SCAN的激光特征点
当前SCAN对应的IMU数据
(
a
m
,
w
m
)
(a_m, w_m)
(am?,wm?)
- 基于前向传播得到状态预测值 x ^ k \hat{x}_{k} x^k?和先验误差的协方差矩阵 p ^ k \hat{p}_{k} p^?k?
- 基于后向传播得到初始位姿和运动补偿后的3D点
- 迭代前:迭代次数
k=-1, X ^ k k = 0 = X ^ k \hat{X}^{k=0}_{k} = \hat{X}_{k} X^kk=0?=X^k? - 迭代
| 1. 迭代次数k=k+1
| 2. 计算IMU前向传播先验一阶雅格比 J k J^k Jk和先验误差的协方差矩阵P
| 3. 计算点云匹配残差 z j k z^k_j zjk?和残差的一阶泰勒展开雅矩阵 H j k H^k_j Hjk?
结束:当本次误差和上次误差之间的差值小于某个阈值 - 更新状态估计和卡尔曼增益
- 更新状态估计值 x ˉ k \bar{x}_k xˉk?和后验估计协方差矩阵 P ˉ k \bar{P}_k Pˉk?
- 得到全局坐标系下的3D点
输出:
x
ˉ
k
\bar{x}_k
xˉk?和
P
ˉ
k
\bar{P}_k
Pˉk?
全局坐标系下的3D点
五、建图
在本节中,我们将描述如何增量地维护建图(即插入和删除),并通过ikd-Tree对其执行k-nearest search。为了从理论上证明ikdTree的时间效率,给出了完整的时间复杂度分析。
A.地图管理
地图点被组织成一个ikd树,该树通过以里程计频率合并点云的新Scan来动态增长。为了防止地图的大小过度增长,在ikd-Tree上只保留LiDAR当前位置周围长度为L的大局部区域内的地图点,如图3所示。地图区域初始化为长度为L的立方体,以LiDAR初始位置p0为中心。假设LiDAR的检测区域是一个以式(15)得到的LiDAR当前位置为中心的检测球。假设探测球半径为r = γR,其中R为LiDAR FoV范围,γ为大于1的松弛参数。当激光雷达移动到检测球接触地图边界的新位置p’时,地图区域向增加激光雷达检测区域与接触边界的距离的方向移动。映射区域移动的距离设为常数d = (γ?1)R。在新地图区域和旧地图区域之间的减法区域中的所有点将通过V-C中详细的逐框删除操作从ikd-Tree中删除。
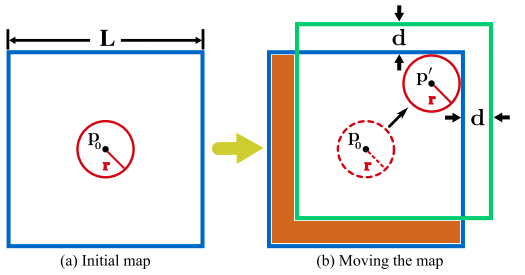
图中(a)中的蓝色区域为初始的地图区域,红色圈圈为初始雷达的扫描范围。在(b)中,雷达移动到了蓝色区域的边界位置时会对ikd树维护的地图进行更新,具体做法就是删除橙色区域中的地图部分,然后增加d所在的新位置部分。
B.树的结构与创建
1.数据结构
(1)一般的kd-tree只在叶子节点上储存地图点,ikd-tree在叶节点和中间节点上均储存地图点,用于动态插入和维持树的平衡
(2)每个地图点对应于ikd-tree上的单个节点,因此可以互换得使用地图点和树节点
(3)属性point储存地图点的坐标和反射率信息,属性leftchild和rightchild分别是指向其左子节点和右子节点的指针,属性axis记录分割空间的分割轴,属性treesize维护以当前节点为根节点的树节点数量(包括有效节点和无效节点)。
(4)当想要从地图中删除点时,将布尔变量置true表示该节点正在等待被删除,如果在当前节点上根的整个(子)树被删除,则treedeleted设置为true。
(5)属性invalidnum表示从子树中删除的点的数量
(6)属性range记录(子)树中点的范围信息,范围指包含该树所有点的定轴长方体,长方体由对角线定点表示,在每个维度上分别具有最小和最大坐标。
2.ikd树的创建
构建ikd-Tree类似于构建静态k-d树。ikd树沿着最长的维度在空间的中点处递归地分割空间,直到子空间中只剩下一个点。在构造过程中初始化数据结构中的属性,包括计算树的大小和(子)树的范围信息。
这里“最长的维度”,指对地图点的XYZ三个维度上的值进行比较,选择方差较大的那个作为划分左右节点的目录
C.地图的增量式更新
ikd-Tree上的增量更新指的是增量操作之后的动态重新平衡,详见章节V-D。ikd-Tree支持两种类型的增量操作:逐点操作和逐框操作。点方向的操作指k-d树插入、删除或重新插入单个点,而按框操作插入、删除或重新插入给定轴向长方体中的所有点。在这两种情况下,点插入都进一步与树的上下采样相结合,这将使地图保持在预定的分辨率。在本文中,我们只解释了FAST-LIO2地图管理所需要的逐点插入和逐框删除。读者可以参考我们在Github存储库上的ikd-Tree的开源完整实现,以及其中包含的技术文档,以了解更多细节。
1.基于树降采样操作的点插入

考虑到机器人应用,我们的ikd-Tree支持同时进行点插入和地图下采样,具体算法见算法2。
- 给定一个地图点p(由状态估计模块得到)和降采样分辨率l,该算法将空间均匀地划分为长度为l的立方体;
- 找到包含点p的立方体
C
D
C_D
CD?(
第2行) - 只保留最靠近
C
D
C_D
CD?中心
p
c
e
n
t
e
r
p_center
pc?enter的点(
第3行)。 - 通过在kd-tree中搜索
C
D
C_D
CD?所有的点,并将他们和新地图点p放在同一个向量中(
第4-5行) - 比较
向量V中每个点到中心 p c e n t e r p_center pc?enter的距离来获得最近的点 p n e a r e s t p_nearest pn?earest(第6行) - 删除
C
D
C_D
CD?中的现有点(
第7行) - 将最接近的点插入k-d树(
第8行)。 - 基于平衡标准检查和维护基于新地图点更新的子树,以保持ikd-Tree的平衡性(
第22行)
算法第11-24行为ikd-tree的点插入函数,通过递归实现。
-
该算法从根节点开始向下搜索,直到找到一个空节点来追加一个新节点(
12-14行) -
新叶节点的属性初始化如表1所示。

-
在每个非空节点上,沿着划分轴将新点与存储在树节点上的点进行比较,以便进一步递归(
15-20行) -
这些被访问节点的属性(例如树大小、范围)将使用最新信息进行更新(
21行) -
对于用新点更新的子树,基于平衡性准则进行检查和维护,以保持ikd-Tree的平衡属性
2.基于延迟标签的逐框删除
在删除操作中,我们使用延迟删除策略。也就是说,这些点不会立即从树中删除,而只是通过将属性deleted设置为true来标记为“已经被删除的状态”。如果以节点T为根的子树上的所有节点都已删除,则T的属性treedeleted设为true。因此,deleted和treedeleted属性被称为延迟标签。标记为“删除”的点将在重建过程中从树中删除。
逐框删除是利用属性范围中的range信息和树节点上的延迟标签实现的。如V-B所述,属性range由具有边界的长方体
C
T
C_T
CT?表示,伪代码如算法3所示。

- 输入:
- C O C_O CO?:将要被删除的点的边界
- T:将要被删除点从属的根节点
- 算法递归地向下搜索T,并比较删除点的边界 C O C_O CO?和根节点的边界 C T C_T CT?
- 如果CT和CO之间没有交集,则递归直接返回,而不更新树(
第2行) - 如果CT完全包含在CO中,则将属性
deleted和treedeleted设置为true(第5行) - 当(子)树上的所有点都被删除时,属性
invalidnum等于treesize - 对于CT相交但不包含在CO时,
- 取出T中的一个点p,如果当前点p属于CO,则首先将该点从树中删除(
第9行) - 然后继续递归查找子节点(
第10-11行) - 在逐框删除操作结束后,对当前节点T进行属性更新和平衡性维护(
12-13行)
- 取出T中的一个点p,如果当前点p属于CO,则首先将该点从树中删除(
3.属性更新
在每次增量操作之后,使用AttributeUpdate函数将被访问节点的属性更新为最新信息。该函数通过汇总其两个子节点上对应的属性和自身上的点信息来计算属性treesize和invalidnum;range属性通过将两个子节点的range信息与存储在该节点上的的地图点信息确定;如果两个子节点的Treedeleted都为true并且节点本身被删除,则节点T的Treedeleted被设置为true。
D.平衡的恢复
在每次增量操作之后,ikd-Tree主动监测树的平衡性,并通过仅重新构建相关子树来动态地重新平衡自身。
1.平衡准则
平衡准则由两个子准则组成:α-平衡准则和α-删除准则。
(1)α-平衡准则:
假设ikd-Tree的一个子树的根节点为T,当且仅当满足公式17时认为该子树是α-平衡的,即通过比较左右子树与T节点的treesize进行判断:
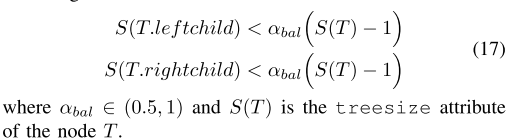
(2)α-删除准则
当T中无效节点的数量相对于T总结点数量的占比小于一定阈值,认为T节点不满足删除准则。

如果ikd-Tree的一个子树同时满足这两个条件,则该子树是平衡的。如果所有子树都是平衡的,那么整个树就是平衡的。违反任何一个准则都将触发重建过程以重新平衡该子树:α-balanced准则维持树的最大高度。可以很容易地证明,α平衡树的最大高度为 l o g 1 / α b a l log_{1/α_{bal}} log1/αbal??,其中n为树的大小;α-deleted准则确保子树上的无效节点(即标记为“deleted”)被删除,以减小树的大小。减少k-d树的高度和大小可以在将来实现高效的增量操作和查询。
2.重建及并行重建
单线程的重建见B小节,此处主要介绍双线程子树重建的算法流程。
大致意思就是创建了一个临时副本,将原来子树中的有效点复制一份,副本负责重建子树,原来的主线程继续接收新的信息,二者互不影响
对于主线程,如果有新的地图点增加进来就先存在队列里,等副本中的子树重建完成再将新增信息添加到重建后的子树中
最后把副本中重建好的子树替换掉原来的,并将对应节点进行更新
假设在子树T上触发重建(如图4所示),首先将子树平铺成点存储向量V,在平铺过程中丢弃标记为“deleted”的树节点。然后以V中的所有点构建一个新的平衡k-d树,构造方法见第B节。当在ikd-Tree上重建一个大的子树时,可能会出现相当大的延迟,从而破坏FAST-LIO2的实时性能。为了保持较高的实时性,我们设计了一种双线程重建方法。我们提出的方法不是简单地在第二个线程中重建,而是通过操作日志避免了两个线程中的信息丢失和内存冲突,从而始终保持最近邻搜索的完全准确性。
算法4给出了重建方法。当违反平衡准则时,当子树的大小小于预定值 N m a x N_{max} Nmax?时,在主线程中重新构建子树;否则,子树将在第二个线程中重新构建。第二个线程上的重建算法显示在函数ParRebuild中。表示要在第二个线程中重建的子树为 Γ \Gamma Γ,其根节点为T。
- 第二个线程将锁定所有增量更新(即点插入和删除),但不锁定该子树上的查询(第12行)。
- 然后,第二个线程将子树T中包含的所有有效点复制到点数组V中(这里是先将子树展开再复制),同时保持原始子树不变,以便在重建过程中进行可能的查询(第13行)。
- 在扁平化之后,原始子树将被解锁,以便主线程接受进一步的增量更新请求(第14行)。这些请求将同时记录在一个名为operation logger的队列中。
- 一旦第二个线程从数组V构建了一个新的平衡k-d树
Γ
′
\Gamma^{'}
Γ′(第15行),
IncrementalUpdates函数会再次对 Γ ′ \Gamma^{'} Γ′进行更新(第16-18行)。 - 注意,并行重建开关被设置为false,因为它已经在第二个线程中。
- 在处理完所有挂起的请求后,原子树 Γ \Gamma Γ上的点信息与新子树 Γ ′ \Gamma^{'} Γ′上的点信息完全相同,只是新子树在树结构上比原子树更均衡。
- 该算法锁定节点T,使其不受增量更新和查询的影响,并用新的节点T‘替换它(第20-22行)。
- 最后,该算法释放原始子树的内存(第23行)。
这种设计保证了在第二个线程的重建过程中,主线程中的映射过程仍然以odometry频率进行,没有任何中断,尽管由于k-d树结构暂时不平衡,效率较低。我们应该注意到LockUpdates不会阻塞查询,查询可以在主线程中并行执行。相比之下,LockAll阻塞所有访问,包括查询,但它完成得非常快(即,只有一条指令),允许主线程中的及时查询。函数LockUpdates和LockAll是通过互斥(mutex)实现的。

E. K-邻域搜索
虽然与那些著名的k-d树库中的现有实现相似[43]-[45],但最近搜索算法在ikd-Tree上进行了彻底优化。树节点上的range信息被很好地利用来加速我们的最近邻搜索,使用了[41]中详细介绍的“边界-重叠-球”测试。
维护一个优先级队列q来存储到目前为止遇到的k个最近的节点及其到目标点的距离。从树的根节点向下递归搜索时,首先计算目标点到树节点的长方体
C
T
C_T
CT?的最小距离
d
m
i
n
d_{min}
dmin?。如果最小距离
d
m
i
n
d_{min}
dmin?大于等于q中的最大距离,则无需处理该节点及其子节点。
这里就是看子树的range和目标点解空间的range是否存在交叉,如果两个range不存在交叉则直接将该子树以及其所有的子节点全部减枝,以减小搜索范围,提高运算速度。
此外,在FAST-LIO2(以及许多其他LiDAR里程计)中,只有当邻居点在目标点周围的给定阈值范围内时才会被视为内点,从而用于状态估计,这自然为最近邻的范围搜索提供了最大搜索距离[43]。在这两种情况下,范围搜索通过比较 d m i n d_min dm?in和最大距离来修剪算法,从而减少回溯的数量提高实时性能。值得注意的是,我们的ikd-Tree支持并行计算架构的多线程k近邻搜索。
F.时间复杂度分析
1.增量操作
ikd树的最大高度可以很容易地从等式(17)证明为 l o g 1 / α b a l ( n ) log_{1/α_{bal}}(n) log1/αbal??(n)。而静态k-d树的时间复杂度为 l o g 2 n log_2^n log2n?。因引理直接从[40]中获得,其中k-d树上的点插入的时间复杂度被证明为O(logn)。总结下采样和插入的时间复杂度得出结论,使用树上下采样的插入的时间复杂度是O(logn)。
2.子树重建
重建的时间复杂度分为两类:单线程重建和并行双线程重建。在前一种情况下,重建由主线程递归执行。当维数k较低时,每一级花费排序的时间(即O(n))并且logn级的总时间是O(nlogn) [40]。对于并行重建,在主线程中消耗的时间仅仅是展平(其暂停主线程进一步的增量更新,算法4,第12-14行)和树更新(其花费恒定时间O(1),算法4,第20-22行),而不是构建(其由第二线程并行执行,算法4,第15-18行),导致时间复杂度为O(n)(从主线程来看)。总之,对于双线并行重建,重建ikd树的时间复杂度为O(n ),对于单线程重建,时间复杂度为O(nlogn)。
3.最近邻搜索
因为ikd树的最大高度保持不大于 l o g 1 / α b a l ( n ) log_{1/α_{bal}}(n) log1/αbal??(n),其中n是树的大小,从根节点向下搜索到叶节点的时间复杂度是O(logn)。在搜索树上k-最近邻的过程中,回溯的次数与一个常数lˉ成正比,而这个常数与树的大小无关[41]。因此,在ikd树上获得k-最近邻的期望时间复杂度是O(logn)。
六、试验结果
数据集介绍:巴拉巴拉。
A.软硬件环境
巴拉巴拉
B.ikd-tree数据结构评估
分别将ikd-tree和八叉树、R*-树、nanoflann kd树放在FAST-LIO2算法中,对kNN搜索时间、地图点插入时间(使用地图下采样)、由于地图移动而进行的逐框删除时间、新扫描点的数量和地图点的数量(即树的大小)进行比较。
综上,ikd-tree的整体性能优于其他的数据结构,即使某个指标略有不如但是在其他方面和对整个SLAM系统的优化都较为出色。
C.精度估计
在本节中,我们将整个系统FAST-LIO2与其他最先进的lidar -惯性里程计和测绘系统进行比较,包括LILI-OM[17]、LIO-SAM[30]和LINS[31]。
在进行比较时,由于FAST-LIO2没有回环检测模块,因此关闭了其他算法的回环检测模块进行比较。
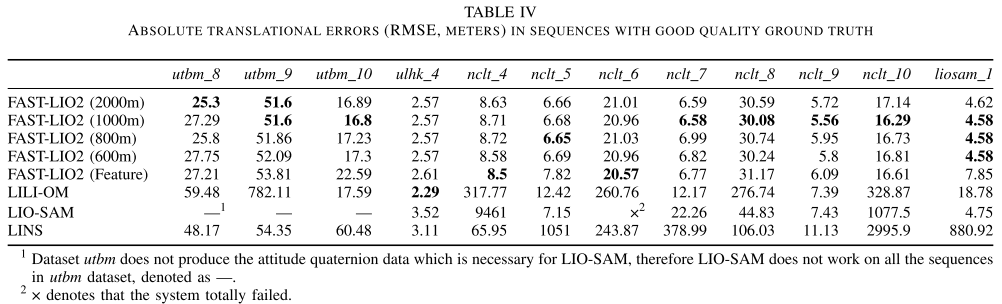
漂移误差:
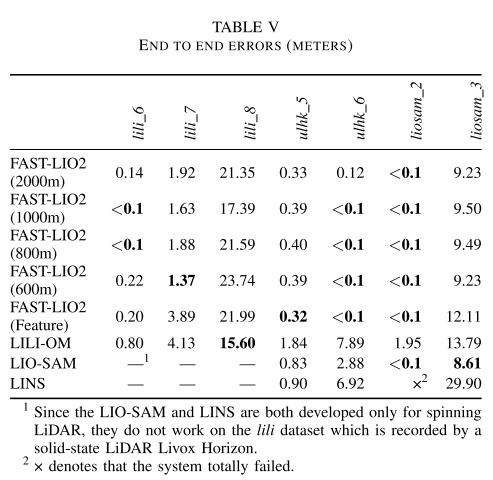
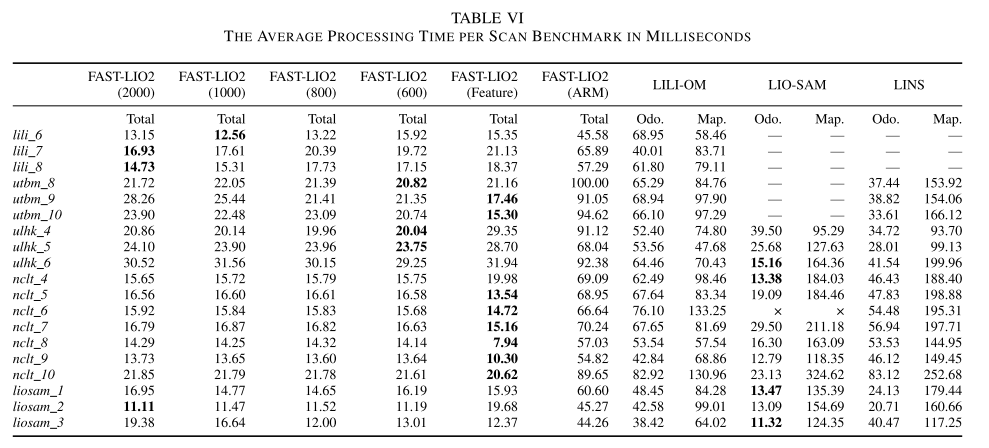
D.实时性评估
七、实车测试
略。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 电商价格治理的有效手段
- 强化学习应用(一):基于Q-learning的物流配送路径规划研究(提供Python代码)
- 探索中国顶级攻击面管理工具:关键优劣势解析
- 大学生HTML期末大作业——HTML+CSS+JavaScript旅游网站
- 2023.12.27每日一题
- C++算法学习五.栈与队列
- 网上招聘系统(JSP+java+springmvc+mysql+MyBatis)
- 【华为OD】统一考试C卷真题:100%通过:执行任务赚积分 C语言代码实现【源码+思路】
- 验证码:防范官网恶意爬虫攻击,保障用户隐私安全
- 登录校验、JWT令牌、Filter、Interceptor