OpenAI 官方 Prompt 工程指南:写好 Prompt 的六个策略
其实一直有很多人问我,Prompt 要怎么写效果才好,有没有模板。
我每次都会说,能清晰的表达你的想法,才是最重要的,各种技巧都是其次。但是,我还是希望发给他们一些靠谱的文档。
但是,网上各种所谓的 Prompt 框架、教程,真的乱七八糟,让人头都大。
直到前两天,12 月 15 号,OpenAI 在他们的文档里上线了 Prompt engineering,也就是提示词工程指南,至此,终于算是有了一个权威且有效的 Prompt 工程标准文档。
我花了 20 分钟看完了后,其实挺会心一笑的,整篇指南简洁、明确、高效,写的非常棒。
OpenAI 提到 6 条大的原则,分别是:
-
Write clear instructions(写出清晰的指令)
-
Provide reference text(提供参考文本)
-
Split complex tasks into simpler subtasks(将复杂的任务拆分为更简单的子任务)
-
Give the model time to "think"(给模型时间「思考」)
-
Use external tools(使用外部工具)
-
Test changes systematically(系统地测试变更)
我用这篇文章,来通俗易懂的给大家聊一下具体的原则和例子,第六条可以不看,对普通用户没啥大用。最后我会再放一张脑图,没空看的可以收藏一下文章,然后滑到最后去保存脑图。
我觉得可以信我,市面上 99% 的 Prompt 框架和技巧,都不如这一篇文章有用。
01
写出清晰的指令
这个其实就是我天天说的,任何 Prompt 技巧都不如清晰的表达你的需求,这就像人与人沟通一样,话都说不明白,怎么能让对面理解你呢?一味的靠抄 Prompt 模板,其实不是长久之计。
所以,写出清晰的指令,是核心中的核心。
如何写出清晰的指令,OpenAI 给出了 6 条小技巧:
1. 把话说详细
尽量多的提供任何重要的详细信息和上下文,说白了,就是把话说明白一点,不要一个太笼统。
比如:
不要说:「总结会议记录」
而是说:
「用一个段落总结会议记录。然后写下演讲者的 Markdown 列表以及他们的每个要点。
最后,列出发言人建议的后续步骤或行动项目(如果有)。」
2. 让模型充当某个角色
你可以把大模型想象成一个演员,你要告诉他让他演什么角色,他就会更专业更明确,一个道理。
比如:
充当一个喜欢讲笑话的喜剧演员,每当我当我请求帮助写一些东西时,你会回复一份文档,其中每个段落至少包含一个笑话或有趣的评论。
3. 使用分隔符清楚地指示输入的不同部分
三引号、XML 标签、节标题等分隔符可以帮助划分要区别对待的文本节。可以帮助大模型更好的理解文本内容。我最喜欢用"""把内容框起来。
比如:
用 50 个字符总结由三引号分隔的文本。"""在此插入文字"""
4. 指定完成任务所需的步骤
有些任务能拆就拆,最好指定为一系列步骤。明确地写出这些步骤可以使模型更容易去实现它们。
比如:
使用以下分步说明来响应用户输入。步骤 1 - 用户将为您提供三引号中的文本。用一个句子总结这段文字,并加上前缀「Summary:」。步骤 2 - 将步骤 1 中的摘要翻译成西班牙语,并添加前缀「翻译:」。
5. 提供例子
也就是经典的少样本提示,few-shot prompt,先扔给大模型例子,让大模型按你的例子来输出。
比如:
按这句话的风格来写 XX 文章:"""落霞与孤鹜齐飞,秋水共长天一色。渔舟唱晚,响穷彭蠡之滨"""
6. 指定所输出长度
可以要求模型生成给定目标长度的输出。目标输出长度可以根据单词、句子、段落、要点等的计数来指定。中文效果不明显,同时你给定的长度只是个大概,多少个字这种肯定会不精准,但是像多少段这种效果就比较好。
比如:
用两个段落、100 个字符概括由三引号分隔的文本。"""在此插入文字"""
02
提供参考文本
给大模型文本或者文档,能大幅度降低大模型胡说八道的概率。其实就是把大模型当知识库来用。
1. 让模型使用参考文本作答
知识库的经典用法,让大模型使用我们提供的信息来组成其答案。
比如:
使用提供的由三重引号引起来的文章来回答问题。如果在文章中找不到答案,请写「我找不到答案」。"""<在此插入文档""""""<在此插入文档"""
问题:<在此插入问题>
2. 让模型通过引用参考文本来回答
如果已经给了文本,则可以直接要求模型通过引用所提供文档中的段落来为其答案添加引用。可以提高正确性,增加可验证性。
比如:
您将获得一份由三重引号和一个问题分隔的文档。您的任务是仅使用提供的文档回答问题,并引用用于回答问题的文档段落。如果文档不包含回答此问题所需的信息,则只需写:「信息不足」。如果提供了问题的答案,则必须附有引文注释。使用以下格式引用相关段落({「引用」:…})。
"""<在此插入文档>"""
问题:<在此插入问题>
03
将复杂的任务拆分为更简单的子任务
其实跟人类一样,你作为 Leader,让下属一次性去做一个非常大的事,出错的概率是很大的,很多大项目也是这样,你甚至无从下手。所以经常我们在工作中,都说的是要拆,拆各种细节、子任务、子目标等等。大模型也是同样的道理。
把复杂的任务给拆给更为简单的子任务,大模型会有更好的表现。
1. 使用意图分类来识别与用户查询最相关的指令
意图识别是一个很经典的例子。比如在客服场景中,用户问了一个问题「我断网了咋整」,你让大模型直接回复其实是挺蛋疼的,但是这时候就可以拆,先拆大分类下的意图识别,再回答具体的问题。
比如还是「我断网了咋整」这个问题:
步骤 1,先判断问题类别:

现在,大模型根据步骤 1,知道「我断网了咋整」是属于技术支持中的故障排除了,我们就可以再继续步骤 2:

这时候,用户的「我断网了咋整」就能得到非常有效的回答了。
2. 对于需要很长对话的对话应用,总结或过滤之前的对话
这个技巧偏开发者。普通用户可以跳过。
因为模型具有固定的上下文长度,因此用户和助手之间的对话无法无限期地继续。
解决此问题有多种解决方法,第一个是总结对话中的历史记录。一旦输入的大小达到预定的阈值长度,这可能会触发总结部分对话的查询,并且先前对话的摘要可以作为系统消息的一部分包括在内。或者,可以在整个对话过程中在后台异步总结之前的对话。
这两种方法都行,或者还可以把过去的所有聊天记录存成向量库,后续跟用户对话的时候动态查询嵌入,也可以。
3. 分段总结长文档并递归构建完整总结
同样偏开发者。普通用户可以跳过。
其实就是总结几百页 PDF 文档的原理,比如让大模型总结一本书,肯定是超 Token 上限了嘛,所以可以使用一系列查询来总结文档的每个部分。章节摘要可以连接和总结,生成摘要的摘要。这个过程可以递归地进行,直到总结整个文档。OpenAI 在之前的研究中已经使用 GPT-3 的变体研究了这种总结书籍的过程的有效性。
详细的可以看这篇文档:https://openai.com/research/summarizing-books
04
给模型时间「思考」
Think step by step(一步步思考)这个神级提示词的源头。其实也就是链式思考(CoT),Chain-of-Thought Prompting,非常非常有用的一个策略。
还是跟人一样,我直接问你 12314992*177881 等于多少你肯定也懵逼,但是我要是给你时间让你一步步计算,学过小学数学的我觉得都能算出来对吧。
OpenAI 在 CoT 的基础上,又详细给出了 3 个技巧:
1. 让模型在急于得出结论之前找出自己的解决方案
比如你扔个数学题给大模型,你让他判断对或者不对,你会发现结果很随机,一会对或者不对,但是如果你先让他自己做一遍,再去判断对与不对,结果就会准非常多了。
比如你可以说:
首先制定自己的问题解决方案。然后将你的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。在你自己完成问题之前,不要决定学生的解决方案是否正确。
2. 使用内心独白来隐藏模型的推理过程
非常有意思的一个技巧,你可能会问不是说一步一步思考把推理过程放出来效果会更好嘛。
你说的对,但是这条技巧是面对开发者的,对于某些应用程序,大模型用于得出最终答案的推理过程不适合与用户共享。例如,在辅导应用程序中,我们可能希望鼓励学生得出自己的答案,但模型关于学生解决方案的推理过程可能会向学生揭示答案。
所以就有了这么一个内心独白的技巧。内心独白的想法是让模型将原本对用户隐藏的部分输出放入结构化格式中,以便于解析它们。然后,在向用户呈现输出之前,将解析输出并且仅使部分输出可见。
比如:

接下来,我们可以让模型使用所有可用信息来评估学生解决方案的正确性。

最后,我们可以让大模型使用自己的分析来以乐于助人的导师的角色构建回复。

用多次跟 API 通讯的方式,同时隐藏模型的推理过程,来完成一次学生的辅导方案对话。
3. 询问模型在之前的过程中是否遗漏了什么内容
这个技巧在长文本问答中常用,比如我们给了一个文档,要让大模型模型来列出与一个特定问题相关的信息。如果源文档很大,模型通常会过早停止并且无法列出所有相关信息。在这种情况下,通过使用后续的 promtp 让模型查找之前传递中错过的任何相关信息,通常可以获得更好的性能。
比如我让他根据我的文档,给我列出这个问题在文档中的相关片段:「北京烤鸭到底好吃在哪」,然后让他用 JSON 格式输出
[{"相关片段":"..."},
在输出停止以后,我们可以再问一句:
还有更多相关片段吗?注意不要重复摘录。还要确保相关片段包含解释它们所需的所有相关上下文 - 换句话说,不要提取缺少重要上下文的小片段。
05
使用外部工具
大模型并不是万能的,很多东西吧,大模型的效果并没有那么好,比如数学、比如一些实时问题等等,所以需要一些外部工具来帮助处理。
换句话说,如果第三方工具能稳定的获得结果,那其实并不需要大模型去做什么,或者只让大模型做一个答案组装类的工作就够了。
1. 使用基于嵌入的搜索实现高效的知识检索
绝大部分知识库的原理,检索增强生成 (RAG),Retrieval Augmented Generation,比如我问如何评价马上要上映的电影《海王 2》,你让大模型自己去答肯定就废了,它是静态的,根本不知道《海王 2》要上映了,所以需要先去联网进行查询,查完以后把一堆资料灌回来,让大模型自己根据自己查到的这些资料进行回答。这是动态的信息。
但是也有静态的知识库,就是用的向量匹配的方式,常见步骤:加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k 个 -> 匹配出的文本作为上下文和问题一起添加到 prompt 中 -> 提交给大模型生成回答。
就是这么玩的。
2. 使用代码执行来进行更准确的计算或调用外部API
都知道大模型自己的计算能力垃圾,所以 OpenAI 建议,如果遇到需要计算的东西,最好让大模型写一段计算的 Python 代码,毕竟 Python 最计算题很成熟了。
比如:
求以下多项式的所有实值根:3*x**5 - 5*x**4 - 3*x**3 - 7*x - 10。您需要通过将 Python 代码括在三个反引号中来编写和执行,例如"""代码放在这里"""。用它来执行计算。
当然,都用 Python 了,你也可以把自己的 API 文档复制给它,让大模型知道该如何写代码调用你的 API。
3. 给模型提供特定的功能
很偏开发者的一个技巧,普通用户可以直接跳过。
简而言之,你可以通过 API 请求,传递一系列特定的函数描述。告诉模型哪些函数是可用的,以及这些函数的参数应该是什么样的。然后模型模可以生成相应的函数参数,这些参数随后会以 JSON 格式通过 API 返回。
你都拿到 JSON 数组了,跟数据库可以做多少交互相信也不用我多说了吧,做数据查询、数据处理等等,啥玩意都行。
处理完以后再返回一个 JSON 数组给大模型,让大模型变成人类语言输出给用户,完事。
06
系统地测试变更
主要是帮助开发者判断更改 Prompt(例如新指令或新设计)是否使系统变得更好或更差。毕竟大部分时间的样本量都比较小,很难区分真正有改进还是纯粹的运气。
所以,OpenAI 建议搞个评估程序,用来判断优化系统的设计是否有效。
这块我就不细说了,有兴趣的或者正在开发自己的 AI 应用的,可以自己去看看:
https://platform.openai.com/docs/guides/prompt-engineering/strategy-test-changes-systematically
OpenAI 这个 Prompt engineering 写的相当详细了,我真的觉得,比市面上太多太多的框架和课程都要好。
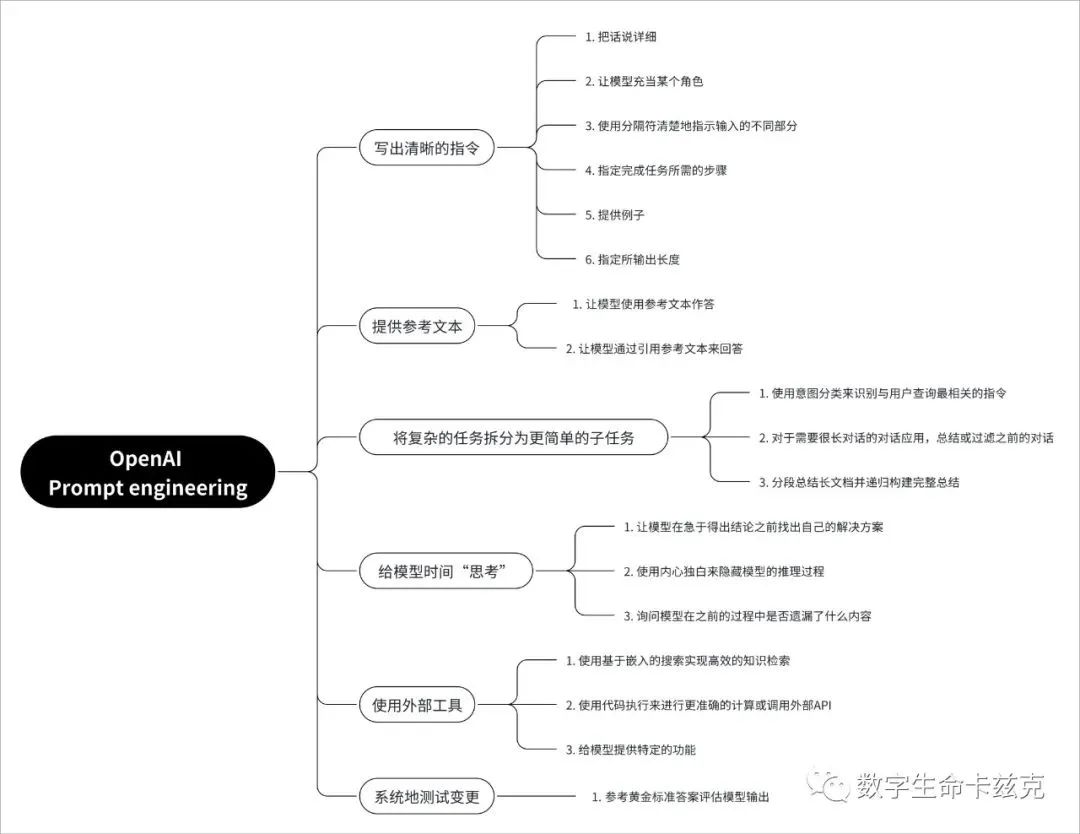
为了方便大家偶尔复习,我也做了一张脑图,可以跟文章结合着看。
07
Notion、Google 和 Claude 的补充
关于 prompt 的指南,谷歌、微软、Notion 等也都有专门的文章讨论,核心观点其实与 OpenAI 的略有类似。
比如谷歌的教程提及到:
清楚地传达最重要的内容或信息。(说清楚你的目的)
构造提示词:首先定义其角色,提供上下文/输入数据,然后给出指令。(定义角色,提供详细的背景,再给出你的要求)
提供具体的、多样化的例子,能让模型参照例子生成更准确的结果。(提供参考例子)
使用限制条件来限制模型输出的范围,避免其产生与指令无关或不准确的信息。(限制输出内容的「主题范围」)
将复杂任务分解成一系列更简单的提示词。(对于复杂任务,拆分成多个简单的步骤出来)
指导模型在生成响应之前评估或检查其自身的响应。比如,「限制回应在三句话以内」,「用 1 到 10 分来评价你回应的简洁性」,或「你认为这样做正确吗?」。(限制「输出质量」)
思维链推理:针对复杂的问题,在提供指令的最后加一句「让我们一步步思考」(Let's think step by step.),可以让模型按照严谨的逻辑推理过程输出结果。(「让我们一步步思考」)
而 Notion 的教程中提到:
不要用负面描述
在提示词里描述任务要求时,用「只输出 markdown」这样的正面描述,不要用「别输出 markdown 以外的内容」。
2. 给 AI 套人设
AI 不那么擅长区分好坏,但很擅长模仿,如果要 AI 做的某件事是某个人设擅长应对的,可以让 AI 代入那个人设。
详细指南文档:
Notion:如何编写出色的 prompt
https://www.notion.so/blog/how-to-write-ai-prompts
Cluaude AI 提示词官方教程
https://mp.weixin.qq.com/s/tfkpHOs2jhz3UORh0CvU4Q
OpenAI prompt 指南
https://platform.openai.com/docs/guides/prompt-engineering
谷歌生成式 AI 提示工程
https://developers.google.com/machine-learning/resources/prompt-eng?hl=zh-cn
微软提示工程指南
https://learn.microsoft.com/zh-cn/azure/ai-services/openai/concepts/advanced-prompt-engineering?pivots=programming-language-chat-completions
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!