强化学习算法发展一览
文章目录
贝尔曼方程
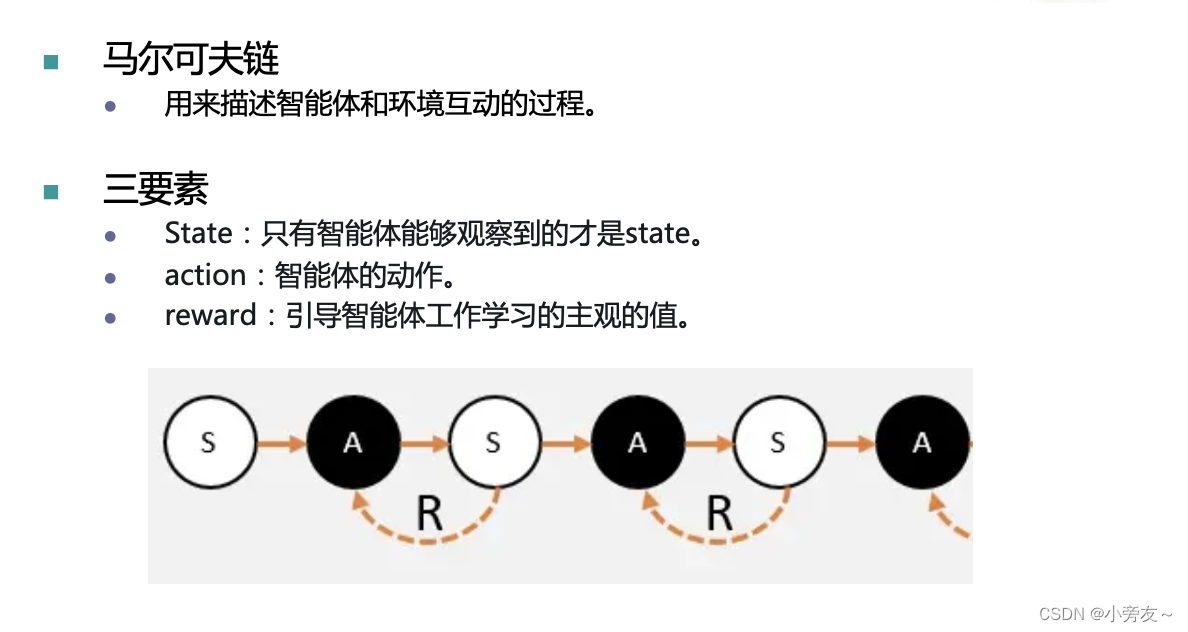

通过马尔可夫链我们知道说「当智能体从一个状态S,选择动作A,会进入另外一个状态S’;同时,也会给智能体奖励R」。
接下来我们介绍一下贝尔曼方程,贝尔曼方程是所有强化学习算法的基础,我们可以看到,他一共包含了三个部分,分别是价值函数及策略函数。那么价值函数指的是智能体从某一个状态开始,根据给定的策略与环境进行交互直到终止该智能体所能获得的累积回报G,该累积回报的均值就被称为是价值函数。策略函数是关于动作的一个概率分布,代表选择到不同动作的概率值。那么策略函数也包括了两种,分别是随机性策略及确定性策略,随机性策略指的是动作的概率分布。那么这里我们可以看出,价值函数的意义就是能够将未来的价值换算到当前时间步。可以想一下,如果我们提前知道价值函数的值的话,在相应的节点就可以根据价值函数的值进行动作的选择了。
蒙特卡洛估计

那么我们下面看一下如何求价值函数,第一个方法是蒙特卡洛估计法,这是一种基于采样的方法,给定智能体一个确定的策略pi,让智能体不停的与环境进行交互,从而得到很多条轨迹,然后就可以根据价值函数的定义,将轨迹的回报累加起来求均值求得价值函数。说简单点就是硬算。
但是这种方式会一些缺点,第一个是他只能用于环境有明确终止的情况下,第二个是他比较耗费资源,毕竟如果轨迹的变化很多的话,那么他的方差也会比较大。
另外在实际实现的时候一般是将经验均值转化成增量均值来计算。也就是左下角的这个公式,N代表的是轨迹的数量,实际操作的时候将这部分转化成学习率即可。
时序差分估计
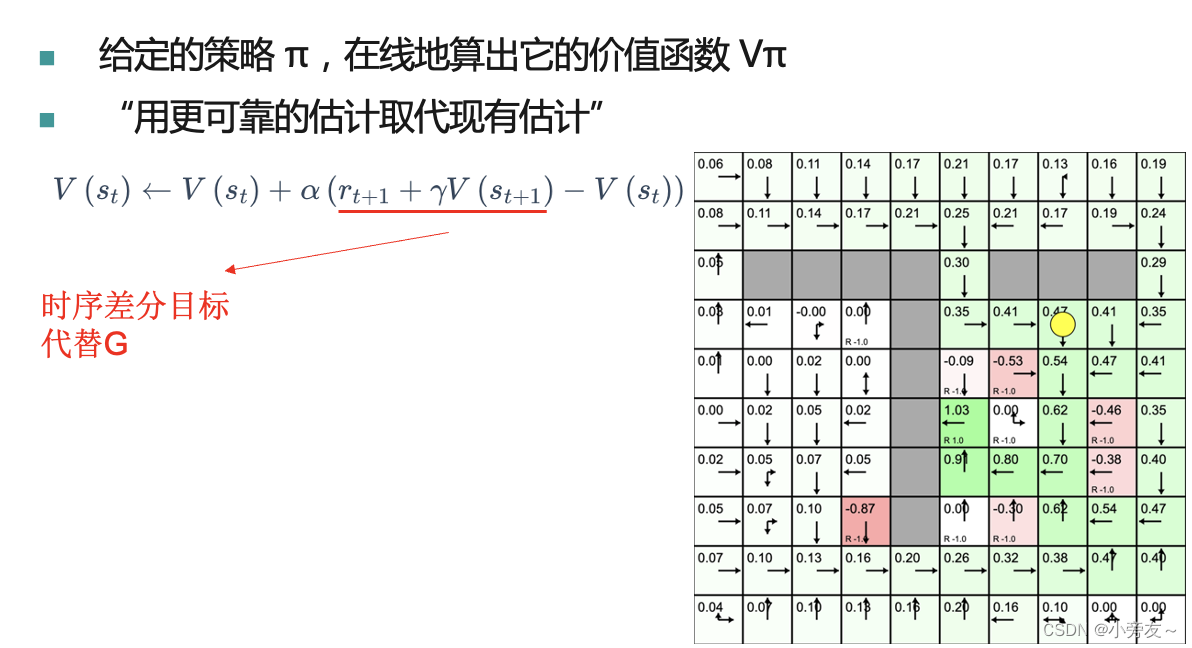
还有另一种计算价值函数的方法称作时序差分估计。对比蒙特卡洛估计,时序差分估计不需要智能体到终止状态才能计算价值函数,使用时序差分估计时,智能体每走一步就能够回头更新价值函数。一句话简单概括就是「用更可靠的估计取代现有估计」。V(St)是现有估计,r+V(St+1)是更可靠估计。 那么为什么这是更可靠估计呢,这是因为其式子中包含了环境反馈的奖励R,所以不断用更可靠估计取代现有估计,就能慢慢接近真实值。时序差分估计同样是采取的增量更新的方式。
时序差分与蒙特卡洛区别

如上图
时序差分与蒙特卡洛结合

我们知道说时序差分是一步一更新,蒙特卡洛是完成一个完整的回合再更新,他俩结合一下就是中和一下,比如n步一更新。在计算n步时序差分目标之后就可以采取增量更新的方法,这也是后面将会介绍的广义优势估计所采取的策略。
Q-learning 和 Sarsa
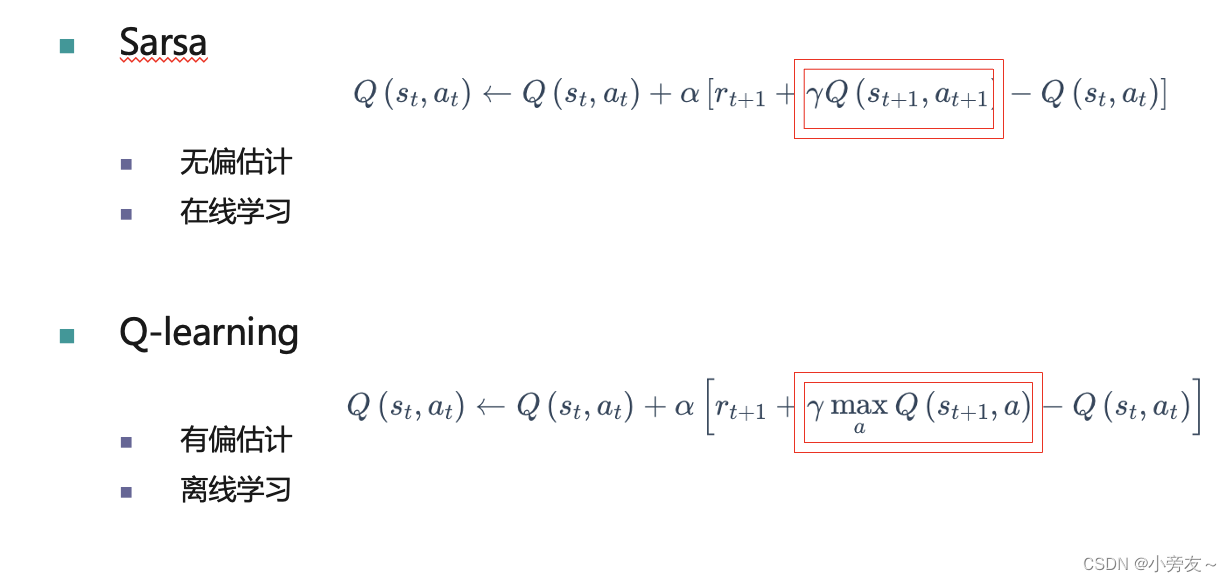
接下来我们介绍比较经典的传统强化学习方法Q-learning和Sarsa。对比之前的时序差分估计,这两个方法是将状态价值函数转化为了动作价值函数,因为在训练智能体的时候我们最希望得到的也就是动作价值函数,所以直接求解Q值会显得更简单。将这两种算法放在一起讲主要是因为这两个算法只有一点不一样,他们更新价值函数时候选用的时序差分目标不一样,一个是选择下一个动作价值函数值最大的动作,一个是选择下一个实际执行的动作。

具体我们可以看这张图,左边是Sarsa算法,右边是Q-learning算法,最开始的时候两个算法时一致的,当处于一个随机状态St时,智能体根据策略采取动作At然后到了状态St+1,到这里就开始不一样了,Sarsa在St+1时再根据策略选取动作At+1,然后利用St, At, R, St+1, At+1这五个值对价值函数进行更新;而Q-learning则是根据St+1这个状态下所有能选择的动作的价值来判断,他选择的是最有价值的那一个动作。
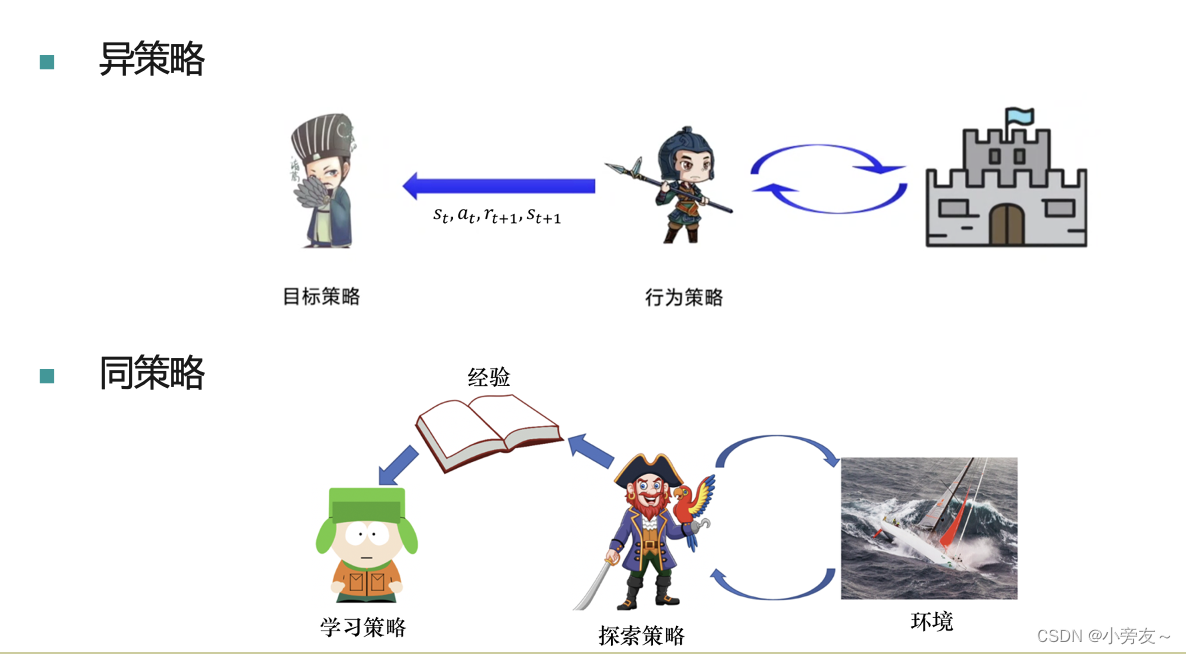
这里就涉及到同策略和异策略的说法,同策略相当于是以身试险,根据智能体实际采取的策略对价值函数更新,而异策略相当于有另外一个军师策略对行为策略进行指导。
当然这两个算法还有一个不同之处在于Sarsa是一种无偏估计,而Q-learning是一种有偏估计,或者叫过估计。
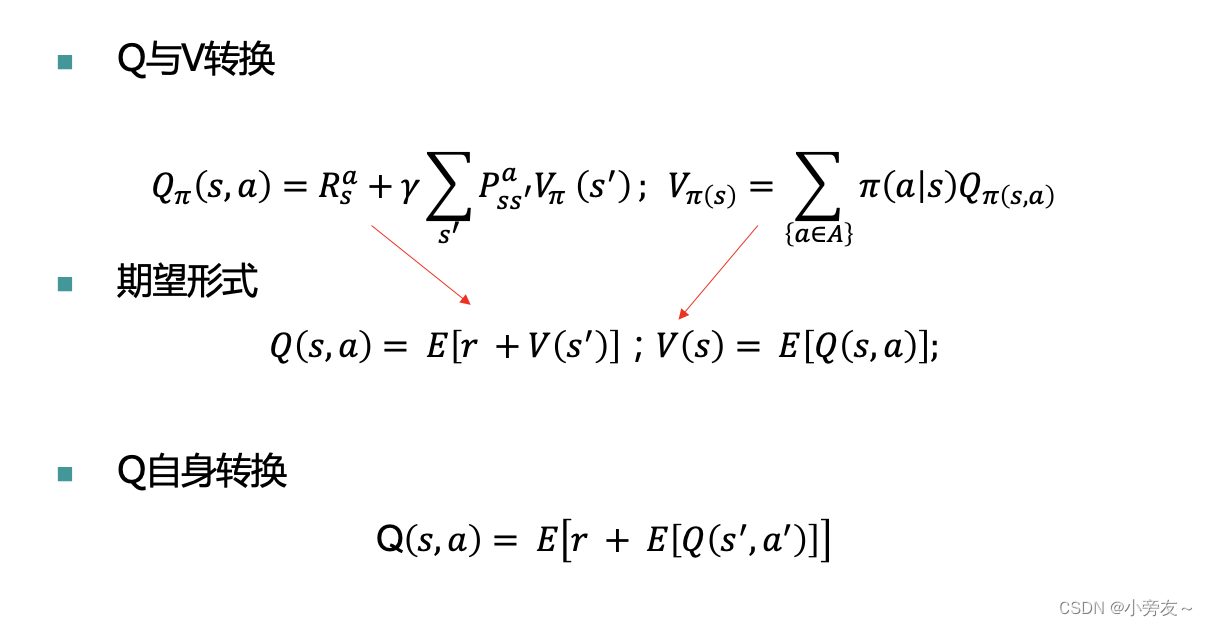
这边我们给出一个证明,还是回到之前说的贝尔曼方程,这里是将价值函数进行转换,Q值转换成V值,其中P表示的是环境的状态转移函数,是智能体再某个状态下采取动作会跳转到其他状态的概率密度。将他们写成期望的形式,V就是子节点的Q的期望,Q就是子节点的V的期望,然后将两个期望代入就可以得到最后一个式子。价值函数Q(s,a)是等于r加上Q(ss,aa)的均值的。
那么对于Sarsa由于它是采取的实际策略,所以他其实某种程度上来说可以看作是一种蒙特卡洛式的采样,当采样的足够多的时候,他就是等于下一步动作价值函数的均值,而Q-learning由于一直采取的是最大的动作,所以明显是会大于均值的,所以Q-learning是一种有偏的估计。
Double Q-learning

那么针对这个问题有Double Q-learning的提出,其核心思想是减小Q-learning的偏差。
照着念。Q1函数选取的下一步最有价值的动作并不一定是Q2函数下一步最优价值的动作,以此来缓解Q-learning的过估计问题。
DQN
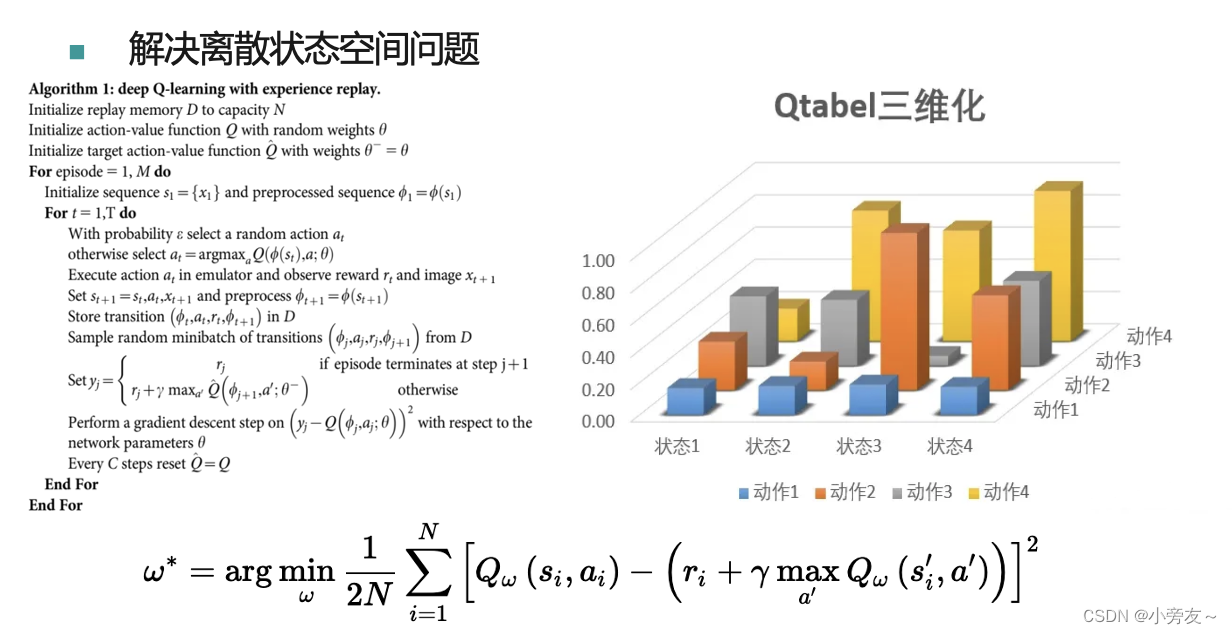
其实Q-learning算法还有另外一个问题,就是他只能处理离散状态空间的问题,因为在实际实现的过程中一般是通过实例化一个二维数组来实现,当状态空间连续的话,存在无穷多个状态,无法单纯的用表格来表示。
所以出现了DQN算法,用神经网络来模拟Q表格。DQN本身和Q-learning算法就算法本身而言差别并不是很大,只是用神经网络模拟了Q表格,DQN算法的目标函数依旧是时序差分目标,这里我们可以看到这里是构建了一个均方差损失函数。

我们前面所讲的算法可以看出来基本都是在计算价值函数,无论是蒙特卡洛还是时序差分还是DQN等,其实强化学习的另一个分支是计算策略,前面是通过价值函数来指导智能体选择动作,现在这种策略梯度方法是直接通过求一个显式的策略来指导智能体。
这里根据公式我们可以看出,J代表的是策略pi下的累积回报,我们将策略参数化,然后通过对参数求导可以得到最下面的形式,这个式子也被称之为策略梯度。其中pi就是我们所说的策略函数,R代表的是累积回报。直观上理解一下就是带权重的梯度。
REINFOECE

还是和前面一样,我们介绍一下如何求策略梯度。这里主要是要求这里的累积回报,其实之前的求价值函数的方法都可以用上
第一个方法称为REINFORCE,也就是我们最开始说的蒙特卡洛方法用到了策略梯度计算上,同样是根据参数化的策略,让智能体不停的与环境进行交互,采集出很多很多的轨迹,然后计算回报的均值。将这个均值作为梯度的权重带到策略梯度算法中进行更新
Actor-Critic
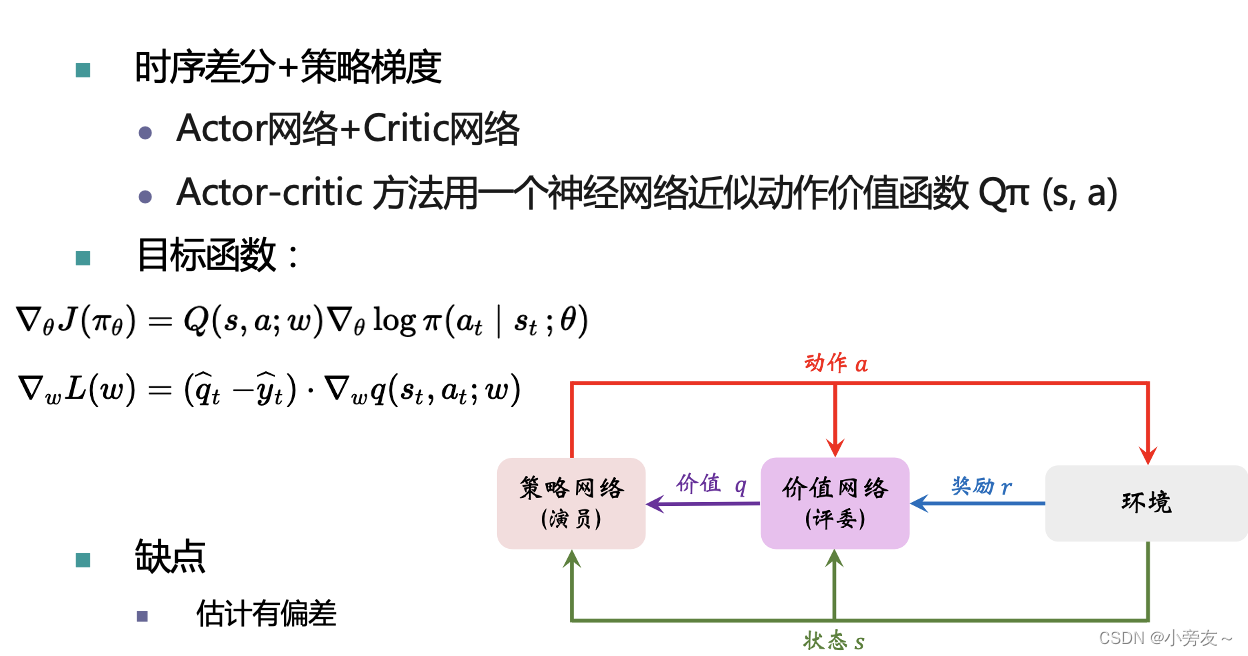
第二个求解策略梯度的方法叫做A-C,这其实是一类方法,后续有很多强化学习算法都是基于这个框架。那么A-C方法其实是时序差分+策略梯度的一个结合。参考我们之前介绍的时序差分方法,是采用更可靠的估计来更新现有估计。可以看到右下角的图,该算法中共有两个网络Actor和Critic,介绍一下这个图。
Actor是根据策略梯度进行更新,Critic是根据环境给的奖励r进行更新。
至于这里为什么不直接吧环境的奖励R反馈给actor,我是这样理解的,因为actor真正需要的是累积回报的期望,R对于策略梯度来说是毫无意义的,也就是说Critic是训练来提供累积回报期望的,也就是动作价值函数。
这里我们再回到之前的策略梯度的式子,策略梯度就是一个带权重的梯度,那么这个权重对于网络的更新是比较重要的,在实际上,如果只使用累积回报期望的话训练的效果往往不好,因为一般来说奖励都是正值,如果在最开始的时候采样到了比较差的轨迹,但是由于奖励依旧是正值会造成网络向比较差的方向优化,所以这造成了直接使用累积回报作为权重的话策略梯度的方差很大。
那么为了解决这个问题,提出的是带基线的A-C
基线Actor-Critic

简单来说就是让累积回报的期望再减去一个与参数无关的式子,看ppt上的公式我们可以看到共有这么多种形式,利用基线可以达到降低轨迹方差,让actor-critic网络层统一等
由于直接使用策略梯度,梯度g的方差会很大,会降低学习速度,所以通过基线b来降低奖励R的方差。b通常设置为R的一个期望估计,目的是减小 R 的方差
因为如果都是正数的话,在最开始的时候基本都是随机采样,如果采样到奖励较少的但是由于其作为权重对网络进行了更新,可能会导致网络收敛不到一个比较好的结果
还有的好处是可以统一网络结构
策略梯度方法虽然直观,但在实践中往往难以取得效果,这是因为每条轨迹的奖励本身具有较大的方差,可能导致训练难以收敛。具体而言,如果有些较大价值的轨迹没有被采样到,根据现有优化目标,模型可能反而会提升一些价值较小的轨迹的策略概率。因此,如果我们能让奖励有正有负,坏于平均值的奖励被认定为负数,这样即便只采样到这些不太好的轨迹,我们仍然能让模型对这些轨迹的策略概率下降。
A2C

利用了基线的其中一个算法叫做A2C,他使用的是优势函数,也就是上一页PPT的时序差分残差做策略梯度的权重,这种方式就能够统一actor和critic的输入。
连各种方法高偏差证明:

这个其实是展示了用蒙特卡洛和时序差分求策略梯度的一些缺点,其中蒙特卡洛虽然是无偏的,但是其方差比较大,时序差分虽然方差小,但是其估计是有偏差的,下面的公式是一个简单的证明,这是由于网络模拟与实际值是存在差异的。所以为了中和这两个缺陷,广义优势估计被提出了
广义优势估计

GAE其实和我们最开始的时候提到的n步TD是一样的思想, 计算多个n步时序差分目标,然后加权平均作为策略梯度的权重。
但是这种方法有一个不好的地方在于对于学习率比较敏感,为了解决这个问题,TPRO算法被提出。
TPRO

这是一个置信域优化算法,其实是一个数值优化方面的算法,算是数值优化算法用在了强化学习的策略梯度更新上。
这里简单介绍一下置信域方法:对于我们的累积回报J,他可能是一个非常复杂的式子,可能会非常难以计算,而置信域算法通过在置信域内构建一个可以近似J的式子,对这个近似的式子做最优化来替代对原始的式子做最优化。
TPRO优化过程共分为两步,近似和最大化。
这里置信域的范围可以有很多种定义的方法,该方法是将不同分布的KL散度作为置信域的划分。
这个方法的优势在于对学习率不敏感,改善了GAE学习率敏感的问题
PPO

但是TPRO有一个缺点是计算耗时比较长,TPRO虽然看起来很好用但是计算复杂度非常高。PPO主要是对其计算做了一些简化。
PPO时目前openai默认的强化学习算法,在许多问题上都表现的比较稳定。
由于AC大部分是在线学习算法,效率很低,当策略更新之后原来的数据就都不能用了。
PPO可以看成是一种离线算法,其用到了一个称为重要性采样的方法,即再设置另外一个固定不变的策略,让该算法变成异策略的算法,固定不变的策略用来采样给计算的策略使用。其实就是把分布px转化成qx的分布,qx在一段时间内是固定的,这个公式可以看出其将px转化成qx,但还多了一个比值,即两个策略的比值,所以PPO的目标函数利用clip将分布限制在了一定的范围内。
同时还要保证两个策略之间的距离不能太大,不然在采样次数不够多的情况下很可能会不一样,因为二者的方差不一样大,而且方差的差距正好是两个策略的比值。
重要性采样:

DDPG
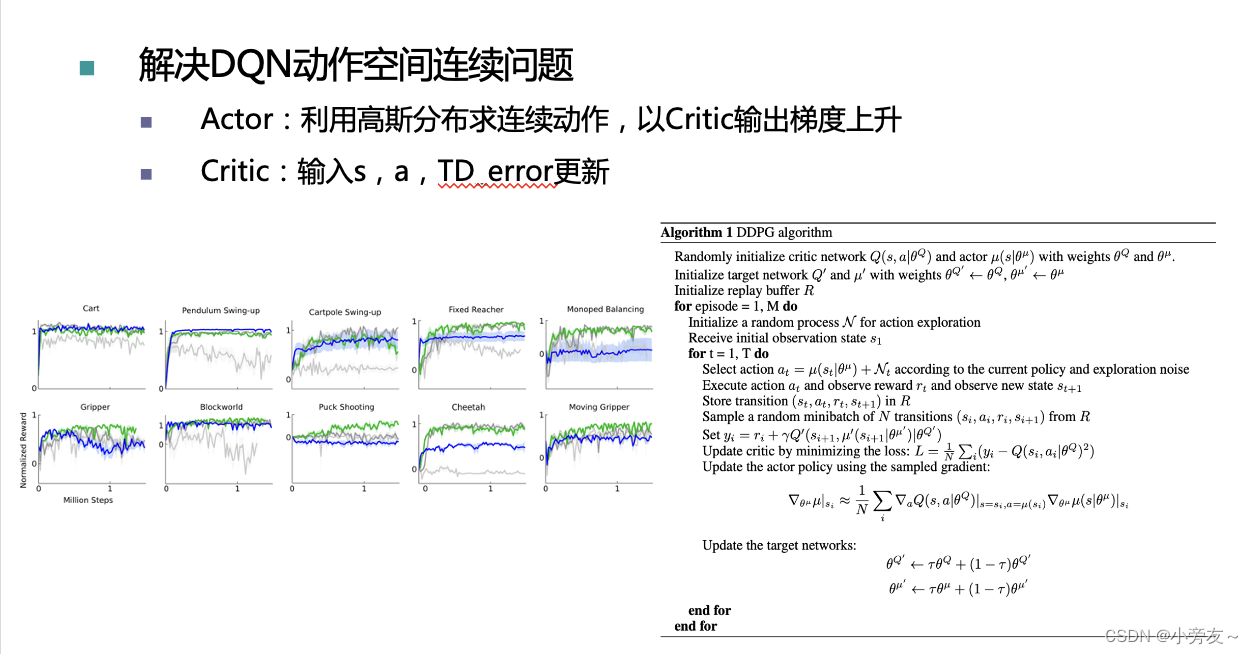
DDPG可以看成是DQN的再进化型,DDPG的出现主要是为了解决连续动作空间的问题,这是DQN等无法解决的。有说法是将其归类到A_C框架的衍生,其实我觉得更像是DQN的衍生或者说DPG的衍生。
这是一个确定性策略算法。Critic是原本DQN的网络,这里额外添加了一个actor网络是为了能够输出连续动作。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一文详解CRM系统多少钱一套、定价依据、成本效益
- 目标仿真工具软件
- 《WebKit 技术内幕》之七(3): 渲染基础
- 丢掉破解版,官方免费了!!!
- 【深度学习目标检测】十七、基于深度学习的洋葱检测系统-含GUI和源码(python,yolov8)
- Activiti7工作流引擎:多租户
- centos 编译安装 python 和 openssl
- msvcr120.dll下载安装方法分享,教你快速修复msvcr120.dll的缺失问题
- 深度盘点:除了BRC20外 这些公链潜力铭文也值得关注
- 【学习总结】地面路谱分析