技术探讨—动捕模型抖动问题揭秘|单RGB摄像头动作捕捉的挑战与困境
发布时间:2023年12月27日
为什么用视觉动捕方案进行动作捕捉,会容易出现模型抖动问题?其根源在于视觉动捕的技术路线。
众所周知,视觉动捕技术不同于传统的光学动捕、惯性动捕,是通过摄像头来对人体运动数据进行捕捉。
市面上做视觉动捕的采用的摄像头一般会分为2类,带深度信息的深度摄像头和不带深度信息的普通RGB摄像头。
今天带大家主要讨论一下基于单RGB摄像头的视觉动捕。
从技术流程看:
Step1:通过摄像头捕捉人体运动精准提取稳定的2D关键点
A:视觉动捕是用摄像头捕捉人体数据,相当于给运动的人体拍照片,再从拍到的照片上提取出人体的2D关键点。而在这个过程中会出现两个问题点:
1、为了使动作更加连贯流畅,通常1S内摄像头会拍摄很多张图像。但不是每一张图像提取的关键点都是准确的。

2、人体运动过程中某些动作会出现遮挡部分身体,导致难以准确提取遮挡部分的关键点。
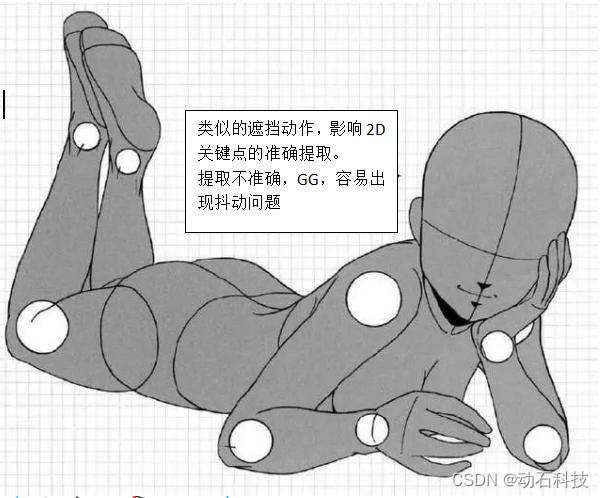
在这两点原因的作用下,单RGB摄像头准确提取2D关键点成为技术难度之一。
Step2:通过2D点拟合计算出高精度3D信息
A:单RGB摄像头捕捉的关键点是2D的,而动捕是三维的,从二维关键点如何得到三维关键点是一个非适定的问题(2d图像上的单个点在3d空间中有无数个对应点,而三维点映射到二维图像点就只对应唯一点)。
由2D关键点→3D关键点,需要进行计算推导。但这样不仅计算量很大,而且很容易出现计算异常,深度信息估算不准的情况。这不仅对外接的电脑配置要求较高(电脑配置低,计算就会慢,延迟会增加),对视觉动捕的算法要求更为严苛。
所以,很多时候,视觉动捕技术就是在比拼算法。
如何查看视觉动捕方案的稳定性?(就是动捕模型是否抖动?)
1、角色模型
越贴近真人状态的3D模型越考验动捕方案的稳定性,而像一些二次元模型,会因为人物体态和造型等原因,在运动过程中隐藏一些抖动问题(尤其是深度方向)。
2、运动状态
静止状态下人眼更容易看见抖动。在检验视觉动捕方案的稳定性时可以从以下几个动作判断:人物相对静止、小幅度动作、人物轻微摇晃、换人......?
文章来源:https://blog.csdn.net/DSKJ_DSFun/article/details/135112979
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 火车山谷2:运营帝国,决策至上——《Train Valley 2: The Pandeia Project》游戏
- Python并发编程基础概念
- PKL型旁通式孔板流量计有效地提高了瓦斯抽放效果
- ZZULIOJ 1121: 电梯
- 21 RT1052的LPIIC
- 华为DHCP配置
- Flink实时电商数仓(十)
- 内存卡为什么会提示格式化,内存卡提示格式化还能恢复吗
- Python对Excel文件中不在指定区间内的数据加以去除的方法
- JUC AQS ReentrantLock源码分析