issue unit
The Issue Unit
issue queue用来hold住,已经dispatched,但是还没有执行的uops;
当一条uop的所有的operands已经ready之后,request请求会被拉起来;然后issue select logic将会从request bit ==1的slot中,选择一条,进行issue;
一旦uop被issue了,则需要从issue queue中删除,为后续的dispatch instruction腾出位置;(什么时候删除,需要看实现,有的实现会提前唤醒,虽然已经issue了,但是可能replay);
一般不同类型的指令放在不同的issue queue里面;
Speculative Issue
可以采用speculatively issue的方式,来提升性能;
例如,推测load inst将会在cache中hit, 然后提前将依赖于该inst的指令提前issue, 其数据希望从bypass网络中拿到;
在这种场景下,issue queue不能删除这些speculatively issued的uops, 直到这些uops的推测状态,被resolved了;
如果提前issued的uops fail了,则所有这些speculatively issued的uops都必须要kill, 并replay;
?Issue Slot
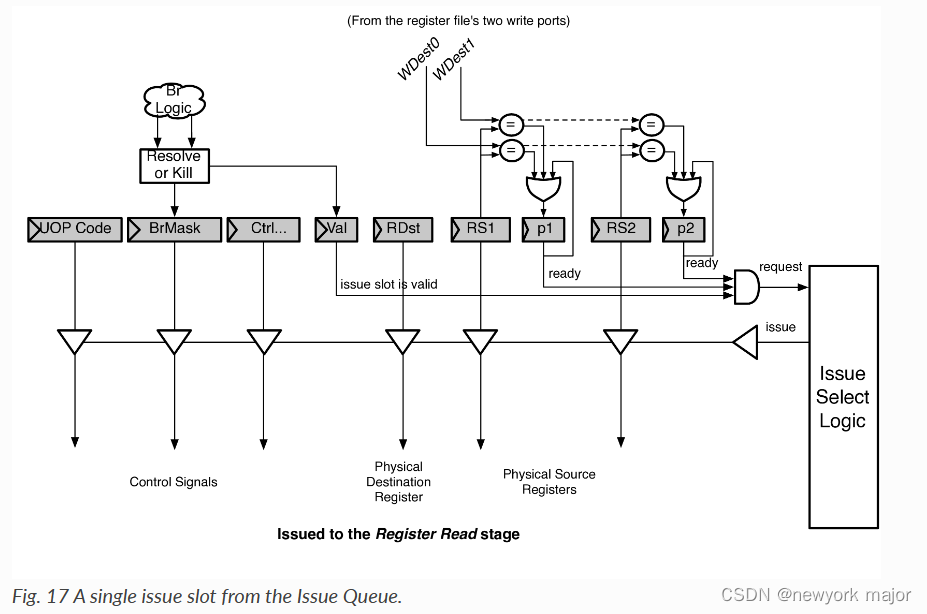
issue slot的内容如图所示,dispatch过来的uop将会存在这样一个entry中,其中p代表presence bit, 代表rs ready的意思;
一旦ready, issue slot将会拉起request请求,等待被iusse;
Issue Select Logic?
每个issue select logic port, 采用静态优先级编码,选择issue queue中第一个availablede uop;
每种类型的issue select logic port, 只会给对应的execution unit进行调度;
如果FU unvailable, 则不能进行调度选择;
?Un-ordered Issue Queue
?dispatch 的uop将会放在第一个可用的issue entry中,等待isseud;
这样会导致性能问题,尤其是在?unpredictable branches放在低优先级的slot,不能被isseud的场景;这种场景下,只能等到ROB fills up, issuew start to drain时,才能进行issue;
这样导致分支预测迟迟不能进行execution, 之前执行的,可能uops都在错误的分支上;
Age-ordered Issue Queue
dispatch 过来的指令,都放在issue queue的底部,优先级最低;
每个cycle, 每条指令都会向上移动,因此,最旧的指令,将会有最高的issue priority;
这样做性能比较好,但是功耗比较大;
Wake-up
?有两类,fast wakeup, slow wake up;
由于ALU UOPs可以通过bypass network发送写回数据,因此发出的ALU UOPs将在发issue时向Issue Queue广播其wakeup。
但是,floating-point操作、loads、可变延迟操作不会通过bypass network发送wakeup信号,而是在write-back阶段来自register file端口。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RK3399平台开发系列讲解(USB篇)USB2.0 包格式分类
- tensorflow入门 自定义层
- Spring Boot Banner 教程:自定义启动画面的艺术
- 【Mybatis技术专题】「夯实基本功系列」带你一同学习如何清晰的解决出现「多对一模型」和「一对多模型」的问题
- git教程(基于vscoede)
- 前端笔试题(二)
- .NET 8的正式发布,对Telerik开发工具意味着什么?
- vuejs/devtools本地安装
- python微博爬虫情感分析可视化系统 舆情分析 python 大数据 TF-IDF算法 Flask框架 毕业设计(源码)?
- kubectl命令行交互