Flink电商实时数仓(六)
发布时间:2023年12月25日
交易域支付成功事务事实表
- 从topic_db业务数据中筛选支付成功的数据
- 从dwd_trade_order_detail主题中读取订单事实数据、LookUp字典表
- 关联三张表形成支付成功宽表
- 写入 Kafka 支付成功主题
执行步骤
- 设置ttl,通过Interval join实现左右流的状态管理
- 获取下单明细数据:用户必然要先下单才有可能支付成功,因此支付成功明细数据集必然是订单明细数据集的子集。要注意:Interval Join要求表中均为Append数据,即“只能新增,不能修改”,订单明细表数据生成过程中用到了left join,生成了回撤流,看似不满足Interval Join的条件。但是,回撤数据进入Kafka会以null值形式存在,如果用Kafka Connector将订单明细封装为动态表,null值会被过滤,最终得到的是相同主键存在重复数据的Append流(动态表本质上就是流),满足Interval Join的条件。
- Interval join只支持事件时间,因此数据必须携带水位线;建表时水位线的相关语法为
water for order_time as order_time - interval '5' second,这里要求数据是timestamp(3) - 原有的时间数据类型是bigint类型的ts,使用
row_time as TO_TIMESTAMP_LTZ(ts,3)这个函数即可将原有的时间数据转换为水位线所需的数据类型
- Interval join只支持事件时间,因此数据必须携带水位线;建表时水位线的相关语法为
- 筛选支付数据:
- 支付状态为支付成功
- 操作类型为update
- 构建 LookUp 字典表
- 联上述三张表形成支付成功宽表,写入 Kafka 支付成功主题
核心代码如下
public void handle(StreamExecutionEnvironment env, TableEnvironment tableEnv, String groupId) {
//核心业务逻辑
//1. 读取TopicDB主题数据
createTopicDb(groupId,tableEnv);
//2. 筛选支付成功的数据,从业务数据topic_db中
filterPaymentTable(tableEnv);
//3. 读取下单详情表数据, 从kafka读取数据
createOrderDetailTable(tableEnv, groupId);
//4. 创建base.dic字典表,从HBase维度数据中读取
createBaseDic(tableEnv);
//tableEnv.executeSql("select * from order_detail").print();
//tableEnv.executeSql("select * from base_dic").print();
//tableEnv.executeSql("select to_timestamp_ltz(ts,3) from order_detail");
//5. 使用interval join 完成支付成功流和订单详情数据关联
intervalJoin(tableEnv);
//6. 使用lookup join完成维度退化
Table resultTable = lookupJoin(tableEnv);
//7. 创建upsert kafka连接器写出
createKafkaSink(tableEnv);
resultTable.insertInto(Constant.TOPIC_DWD_TRADE_ORDER_PAYMENT_SUCCESS).execute();
}
事实表动态分流
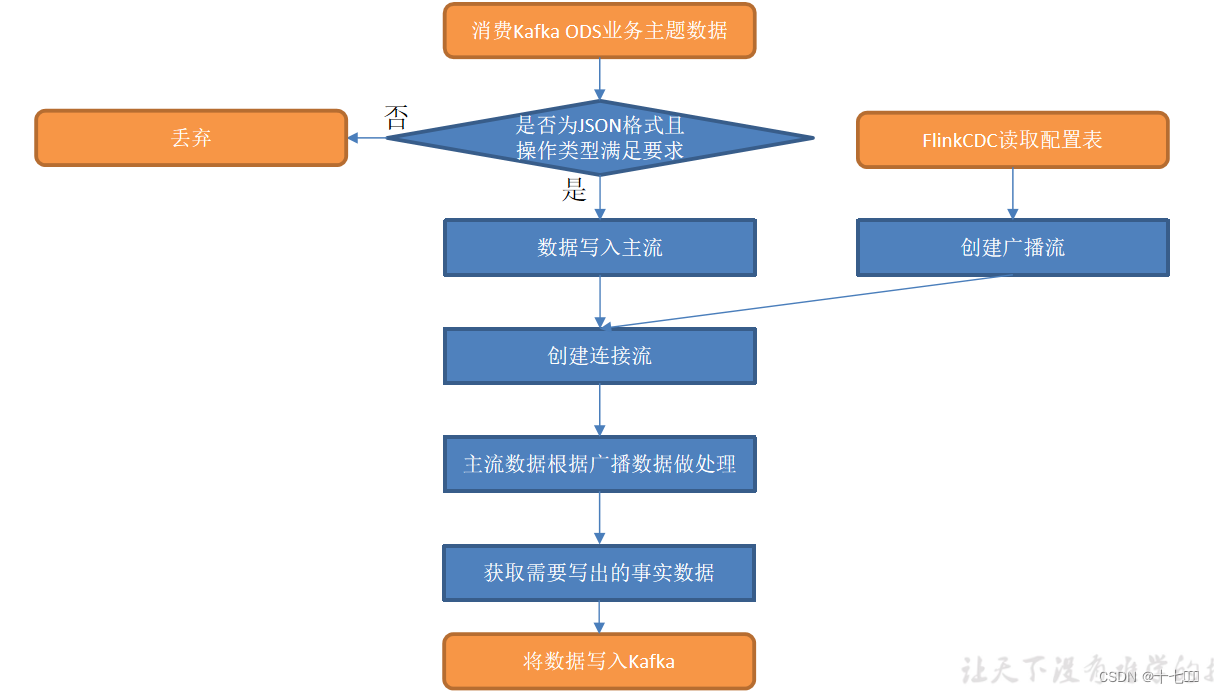
dwd层其他的事实表都是从topic_db中去业务数据库一张表的变更数据,按照某些过滤后写入kafka的对应主题,它们处理逻辑相似且较为简单,可以结合配置表动态分流在同一个程序中处理。有点类似我们前面实现DIM层的动态配置。
- 清洗过滤和转换:判断是否满足json格式,如果满足转换为jsonObj对象
- 读取配置表数据,使用flink-cdc读取
- 转换数据格式,转换到对应bean对象中
- 配置信息广播话,然后跟主流数据进行连接
- 筛选出需要的字段
- 根据表中的sink table字段来动态写出到对应的kafka主题中
核心代码如下
public static void main(String[] args) {
new DwdBaseDb().start(10019, 4, "dwd_base_db", Constant.TOPIC_DB);
}
@Override
public void handle(StreamExecutionEnvironment env, DataStreamSource<String> stream) {
//核心业务逻辑
//1. 读取topic_db数据
//stream.print();
//2. 清洗过滤和转换, jsonObjStream是主流数据
SingleOutputStreamOperator<JSONObject> jsonObjStream = filterJson(stream);
//jsonObjStream.print();
//3. 读取配置表数据,使用flink-cdc读取,读取配置文件时并发度最好为1
DataStreamSource<String> tableProcessDwd = getTableProcessDwd(env);
//tableProcessDwd.print();
4. 转换数据格式 string -> TableProcessDwd -> broadcastStream,广播流数据
SingleOutputStreamOperator<TableProcessDwd> processDwdStream = getProcessDwdStream(tableProcessDwd);
MapStateDescriptor<String, TableProcessDwd> mapStateDescriptor = new MapStateDescriptor<>("process_state", String.class, TableProcessDwd.class);
BroadcastStream<TableProcessDwd> broadcastStream = processDwdStream.broadcast(mapStateDescriptor);
//5. 连接主流和广播流,对主流数据进行判断是否需要保留
SingleOutputStreamOperator<Tuple2<JSONObject, TableProcessDwd>> processStream = processBaseDb(jsonObjStream, broadcastStream, mapStateDescriptor);
//processStream.print();
//6. 筛选最后需要写出的字段
SingleOutputStreamOperator<JSONObject> dataStream = filterColumns(processStream);
//7. 通过sink_table的表名来动态写出到对应kafka主题
//在setRecordSerializer()设置
dataStream.sinkTo(FlinkSinkUtil.getKafkaSinkWithTopicName());
}
文章来源:https://blog.csdn.net/qq_44273739/article/details/135178442
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!