开源大模型应用开发
1.大语言模型初探
ChatGLM3简介
ChatGLM3-6B 是一个基于 Transformer 的预训练语言模型,由清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练发布。该模型的基本原理是将大量无标签文本数据进行预训练,然后将其用于各种下游任务,例如文本分类、命名实体识别、情感分析等。
ChatGLM3-6B 的核心功能是语言建模,即通过预测下一个单词或字符来建立一个语言模型。该模型采用了 Transformer 结构,这是一种基于自注意力机制的深度神经网络结构,能够有效地捕捉文本中的长期依赖关系。
ChatGLM3-6B 模型具有多种预训练任务,例如文本分类、命名实体识别、情感分析等。在预训练过程中,模型会学习到各种语言知识和模式,从而能够更好地完成各种下游任务。
ChatGLM3-6B 模型的局限性在于它只能处理已经训练好的模型,无法直接用于新的、未标注的数据。此外,由于预训练模型是基于无标签数据的,因此它可能无法完全捕捉到某些特定的语言知识和模式。
总的来说,ChatGLM3-6B 是一个功能强大的语言模型,能够在各种文本相关的任务中表现出色。它的核心功能是基于 Transformer 结构的自注意力机制,能够捕捉文本中的长期依赖关系。同时,它还具有多种预训练任务,能够更好地完成各种下游任务。然而,它的局限性在于只能处理已经训练好的模型,无法直接用于新的、未标注的数据。
2.LangChain及其核心组件介绍
LangChain简介
LangChain是一个开源框架,允许从事人工智能的开发者将例如GPT-4的大语言模型与外部计算和数据来源结合起来。该框架目前以Python或JavaScript包的形式提供。
假设,你想从你自己的数据、文件中具体了解一些情况(可以是一本书、一个pdf文件、一个包含专有信息的数据库)。LangChain可以将GPT-4和这些外部数据连接起来,甚至可以让LangChain帮助你采取你想采取的行动,例如发一封邮件。
实践课程:
1、实现pdf、jpg格式文档的加载与解析
2、实现一个于基ChatGLM3+LangChain的聊天应用,需要有Gradio界面
文件位置:chat.ipynb
3、基于LangChain+ChatGLM3实现本地知识库问答,需要有Gradio界面。
支持txt、md、pdf、jpg四种格式的本地文件。
文件位置:langchain_chatglm3_V3.ipynb
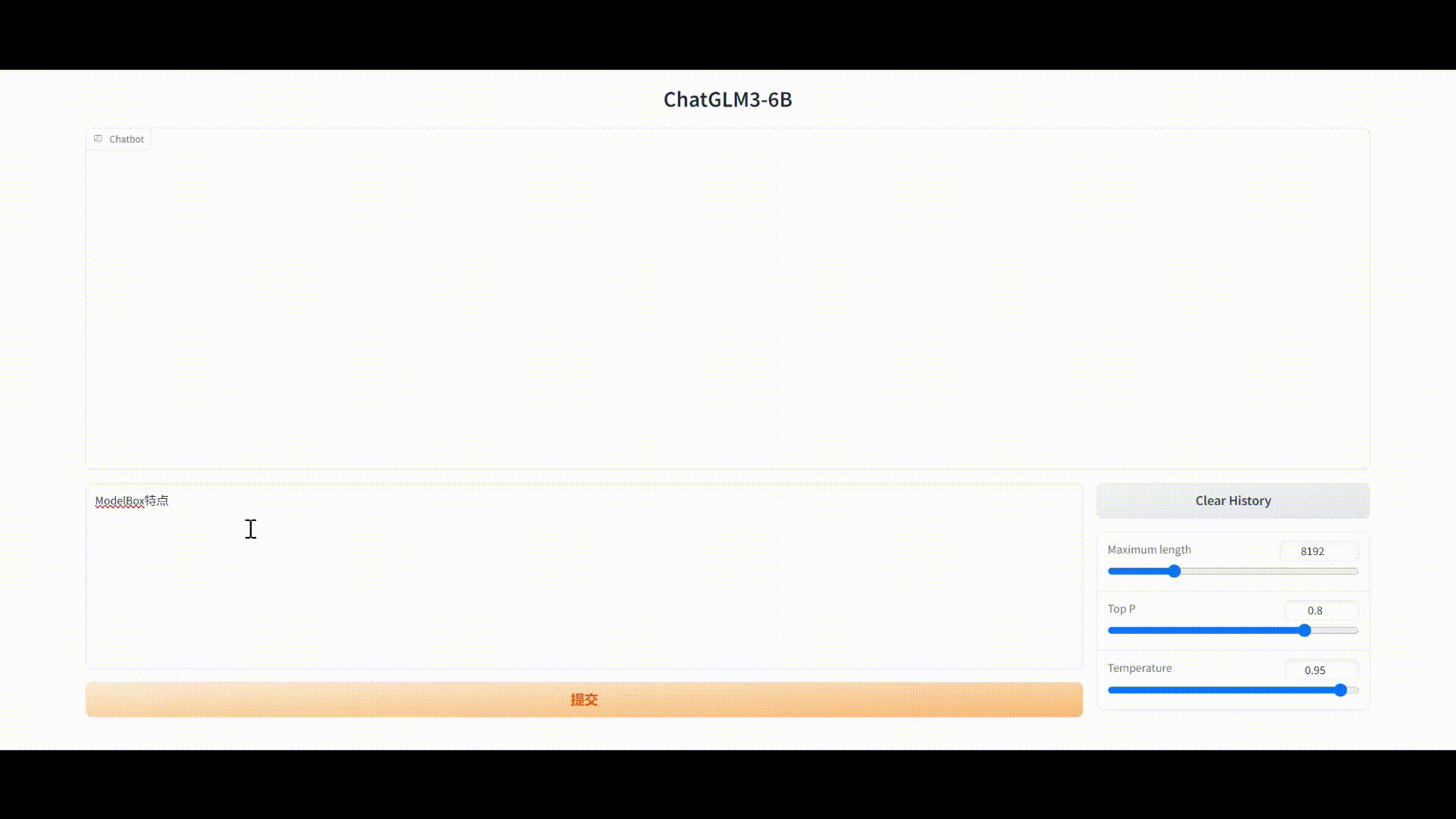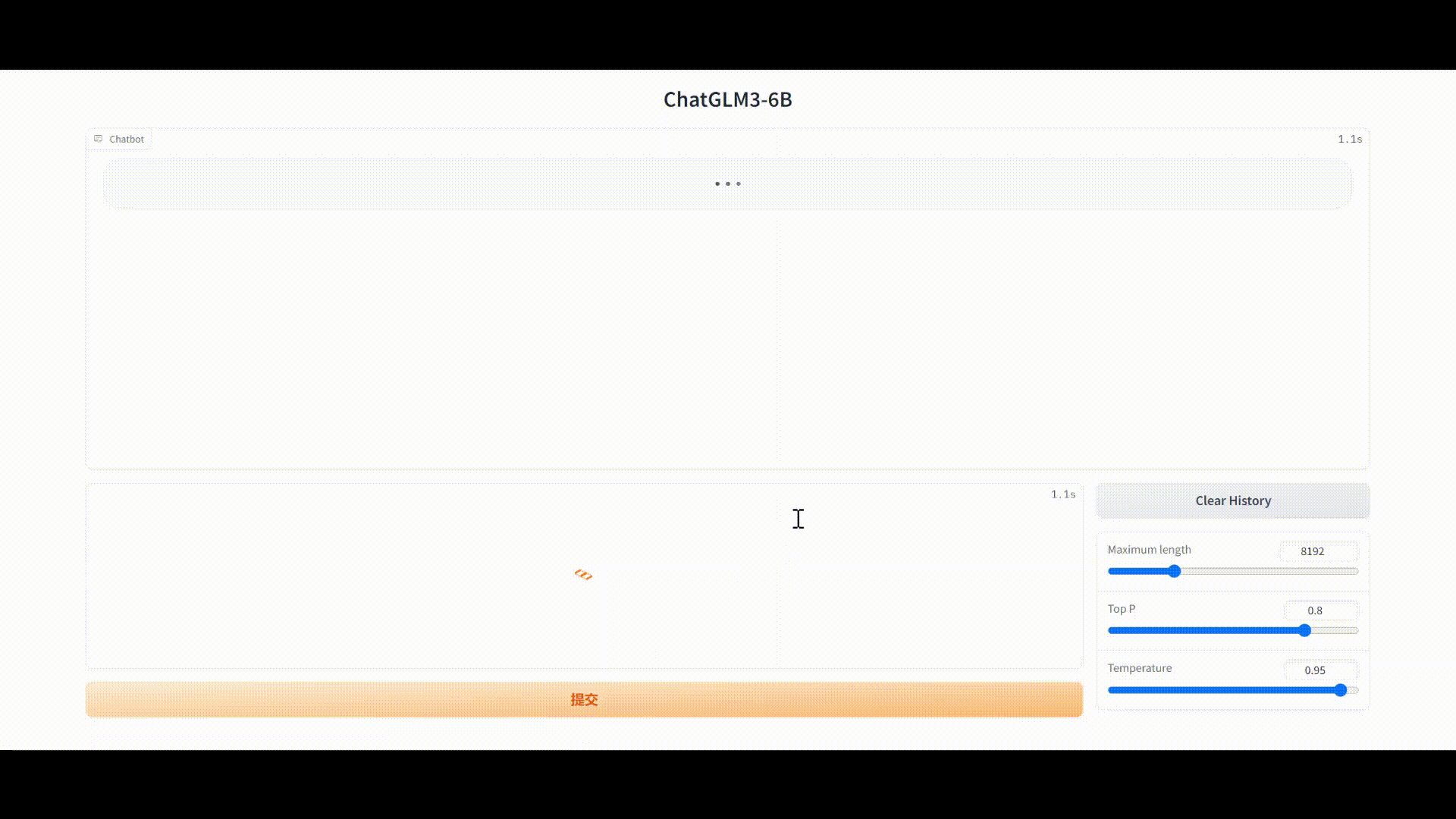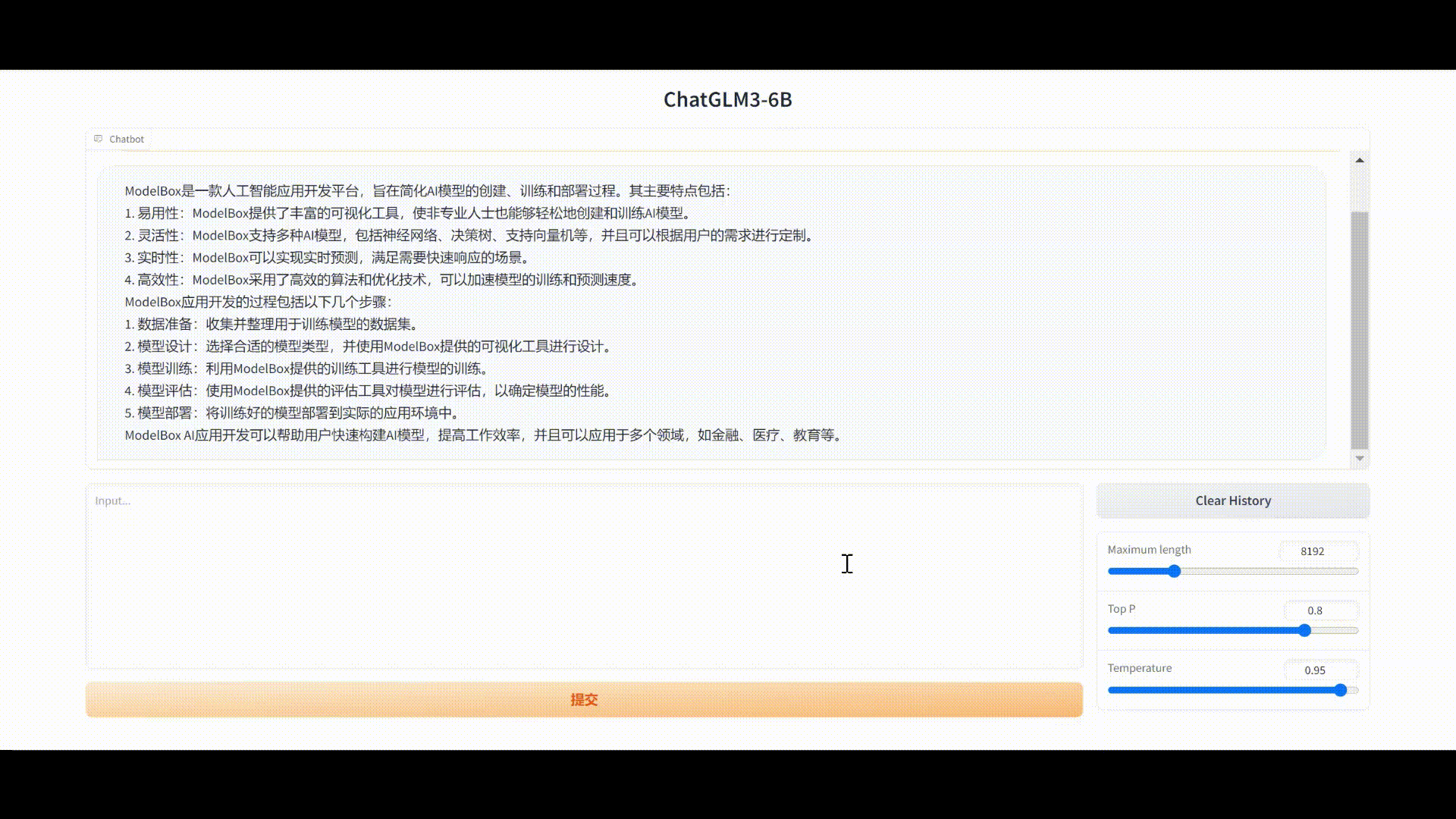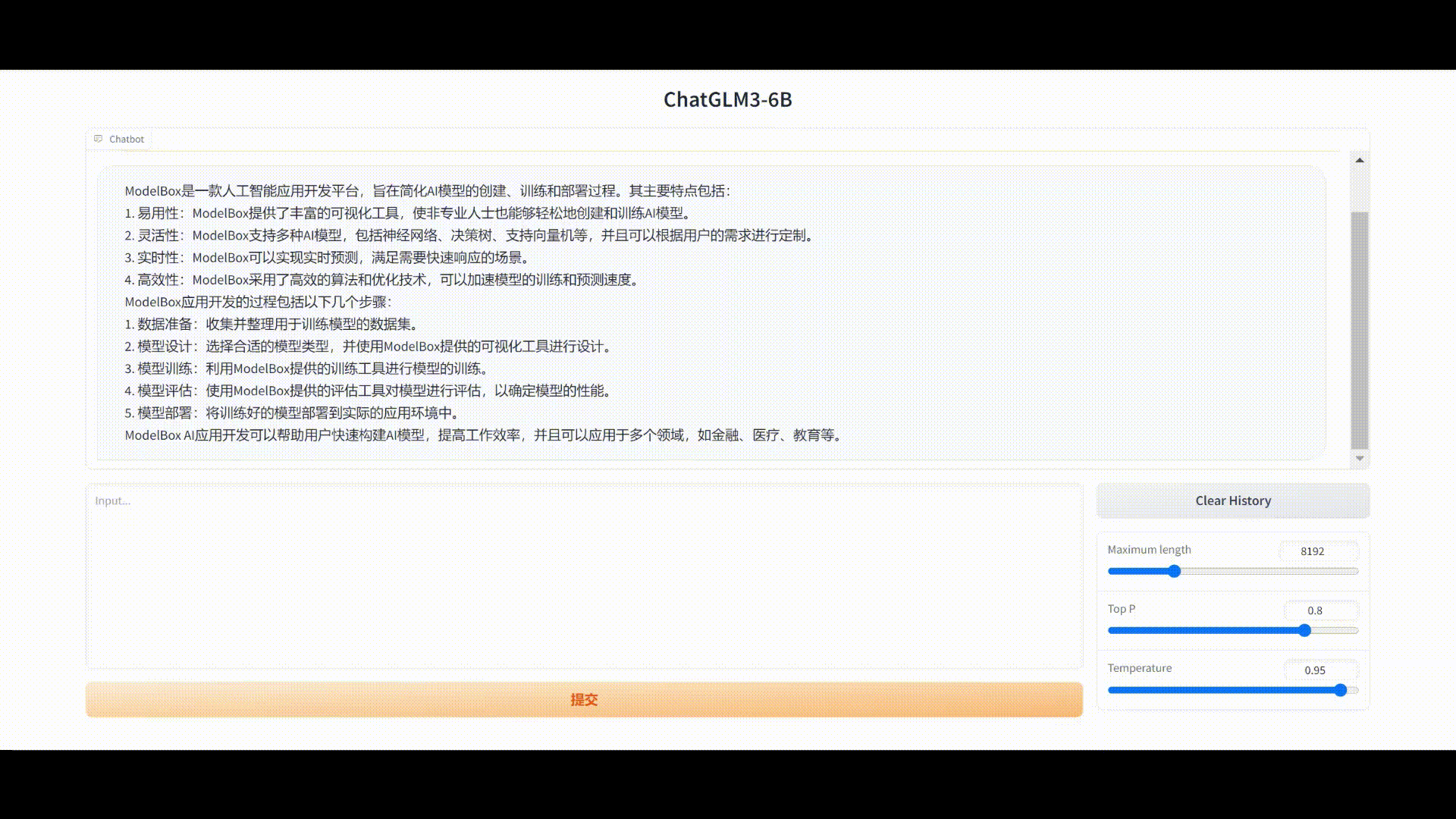
最终Gradio界面问答如图:
直接生成文本:
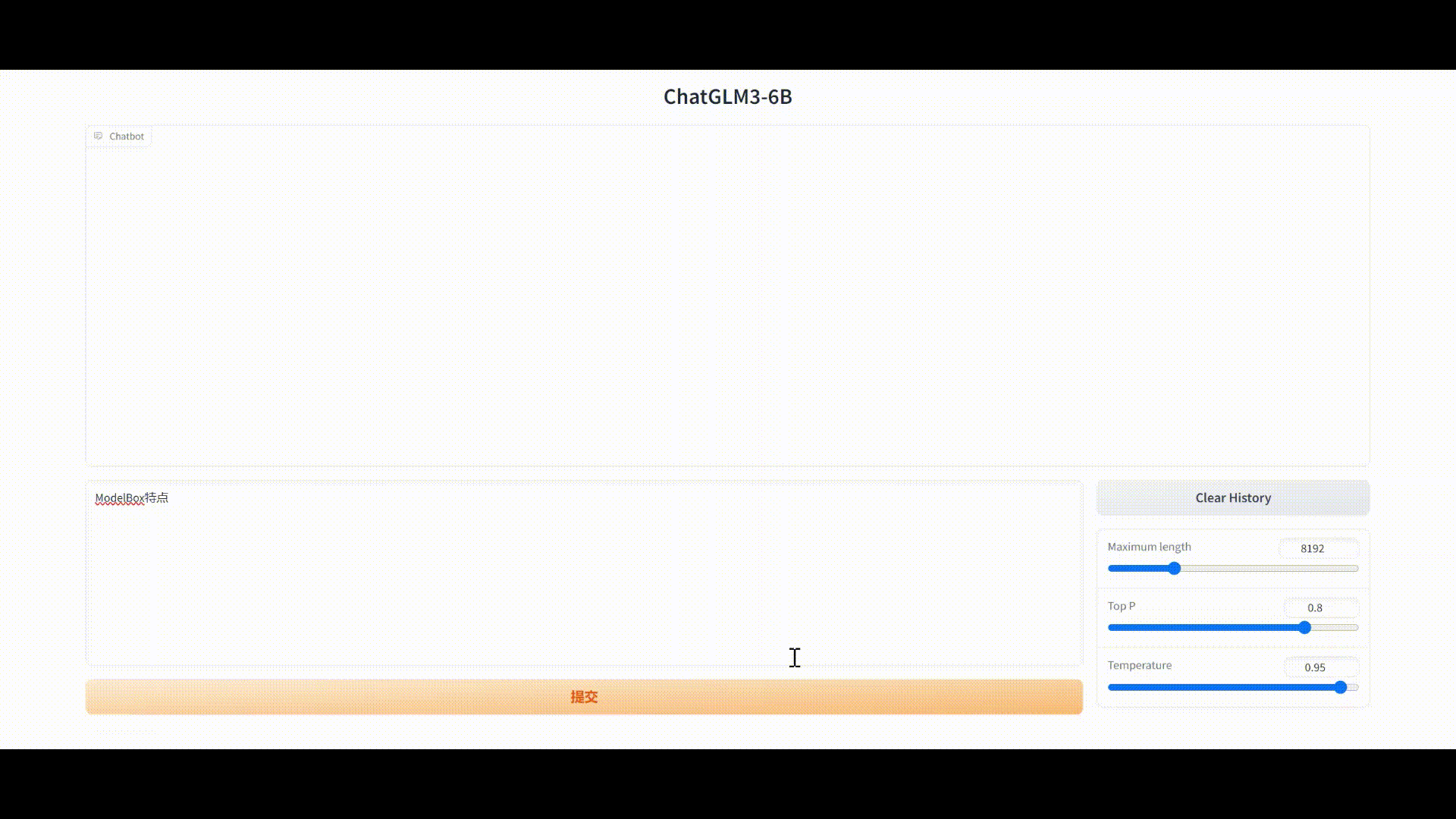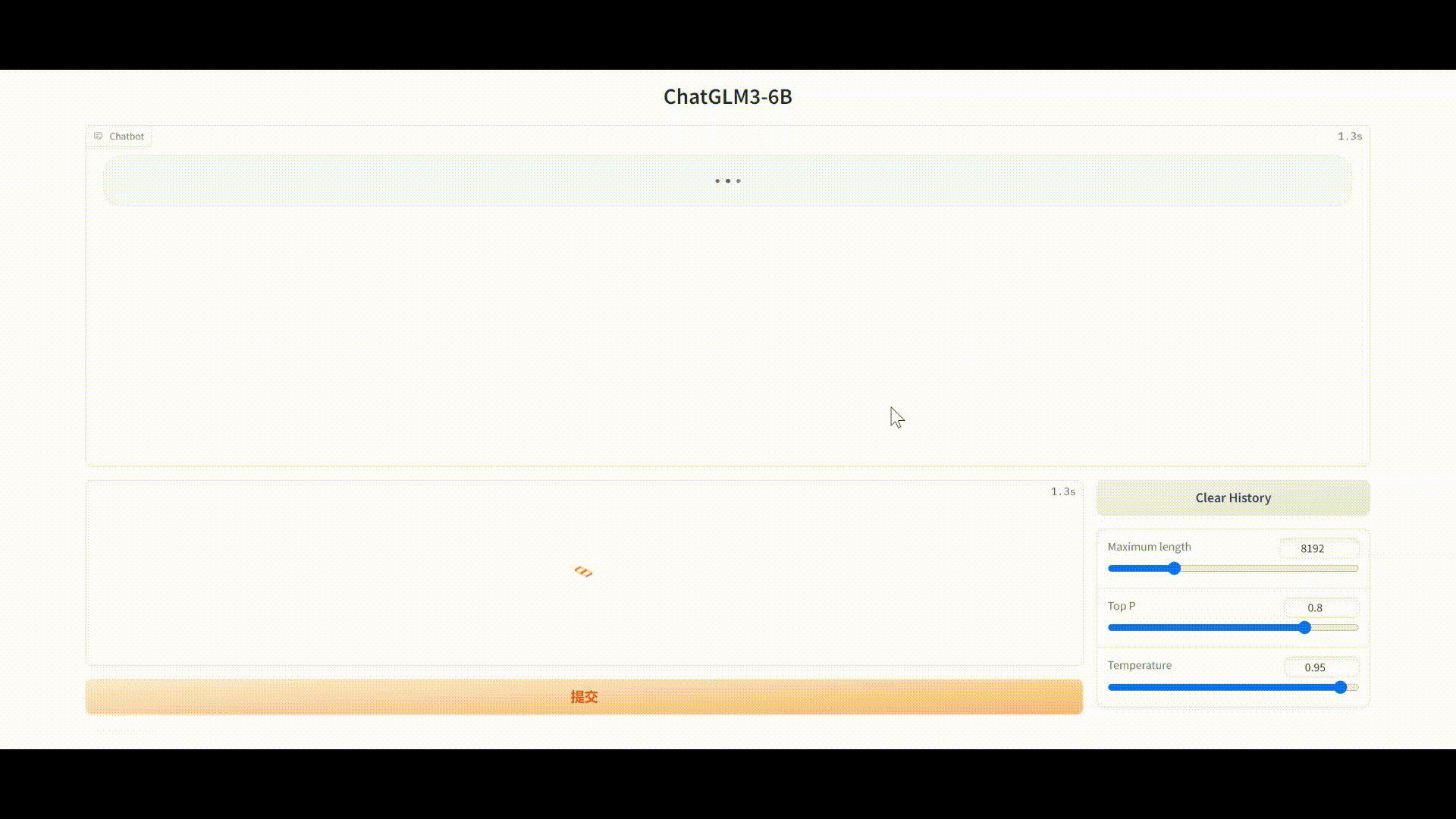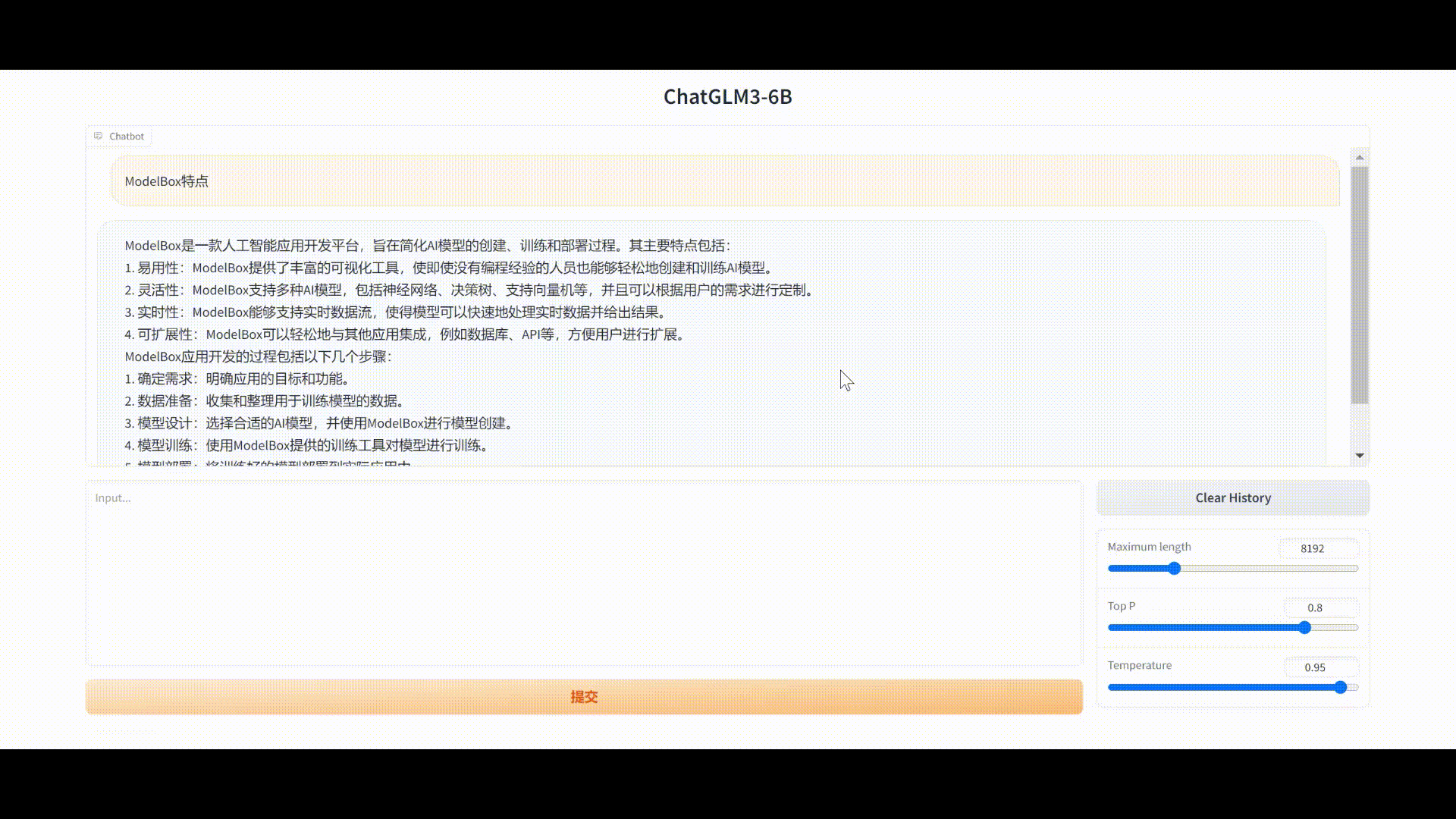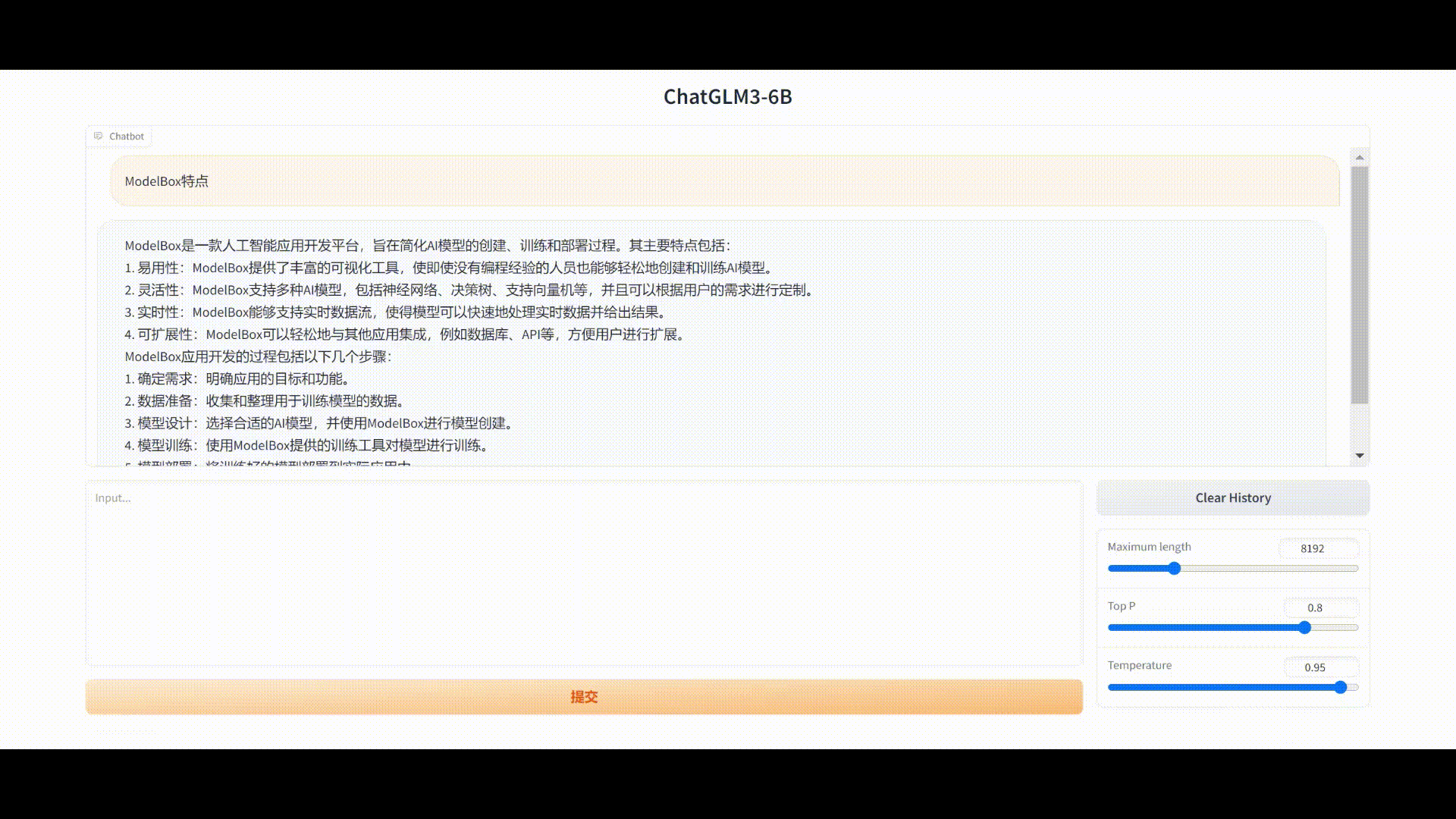
流聊天方式生成文本
4、将导入的文档向量化并存入数据库,以及基于词向量的相似文本检索
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL比较运算符详解
- QT第3天
- JS 作用域和预解析
- 主浏览器优化之路2——Edge浏览器的卸载与旧版本的重新安装
- 用CHAT分析高校体育智慧教学体系构建与探索研究现状
- GCP Scanner:一款针对Google Cloud Platform(GCP)的凭证安全审计工具
- APP广告变现技术——广告分层(瀑布流)
- Node.js中fs模块
- 基于visual studio的verilog环境搭建
- 【论文笔记合集】TimesNet之TimesBlock详解