代码随想录算法训练营第十三天 |二叉树递归遍历、非递归遍历、统一非递归
引用说明
文档讲解:代码随想录
?二叉树递归遍历
思路:
这次我们要好好谈一谈递归,为什么很多同学看递归算法都是“一看就会,一写就废”。
主要是对递归不成体系,没有方法论,每次写递归算法 ,都是靠玄学来写代码,代码能不能编过都靠运气。
本篇将介绍前后中序的递归写法,一些同学可能会感觉很简单,其实不然,我们要通过简单题目把方法论确定下来,有了方法论,后面才能应付复杂的递归。
这里帮助大家确定下来递归算法的三个要素。每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
确定递归函数的参数和返回值:?确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
确定终止条件:?写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
确定单层递归的逻辑:?确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
好了,我们确认了递归的三要素,接下来就来练练手:
以下以前序遍历为例:
- 确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值,除了这一点就不需要再处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
void traversal(TreeNode* cur, vector<int>& vec)
- 确定终止条件:在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return,代码如下:
if (cur == NULL) return;
- 确定单层递归的逻辑:前序遍历是中左右的循序,所以在单层递归的逻辑,是要先取中节点的数值,代码如下:
vec.push_back(cur->val); // 中 traversal(cur->left, vec); // 左 traversal(cur->right, vec); // 右单层递归的逻辑就是按照中左右的顺序来处理的,这样二叉树的前序遍历,基本就写完了,再看一下完整代码:
前序遍历:
class Solution { public: void traversal(TreeNode* cur, vector<int>& vec) { if (cur == NULL) return; vec.push_back(cur->val); // 中 traversal(cur->left, vec); // 左 traversal(cur->right, vec); // 右 } vector<int> preorderTraversal(TreeNode* root) { vector<int> result; traversal(root, result); return result; } };那么前序遍历写出来之后,中序和后序遍历就不难理解了,代码如下:
中序遍历:
void traversal(TreeNode* cur, vector<int>& vec) { if (cur == NULL) return; traversal(cur->left, vec); // 左 vec.push_back(cur->val); // 中 traversal(cur->right, vec); // 右 }后序遍历:
void traversal(TreeNode* cur, vector<int>& vec) { if (cur == NULL) return; traversal(cur->left, vec); // 左 traversal(cur->right, vec); // 右 vec.push_back(cur->val); // 中 }
?非递归遍历
思路:
为什么可以用迭代法(非递归的方式)来实现二叉树的前后中序遍历呢?
我们在栈与队列:匹配问题都是栈的强项?(opens new window)中提到了,递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
此时大家应该知道我们用栈也可以是实现二叉树的前后中序遍历了。
#前序遍历(迭代法)
我们先看一下前序遍历。
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
动画如下:
不难写出如下代码: (注意代码中空节点不入栈)
class Solution { public: vector<int> preorderTraversal(TreeNode* root) { stack<TreeNode*> st; vector<int> result; if (root == NULL) return result; st.push(root); while (!st.empty()) { TreeNode* node = st.top(); // 中 st.pop(); result.push_back(node->val); if (node->right) st.push(node->right); // 右(空节点不入栈) if (node->left) st.push(node->left); // 左(空节点不入栈) } return result; } };此时会发现貌似使用迭代法写出前序遍历并不难,确实不难。
此时是不是想改一点前序遍历代码顺序就把中序遍历搞出来了?
其实还真不行!
但接下来,再用迭代法写中序遍历的时候,会发现套路又不一样了,目前的前序遍历的逻辑无法直接应用到中序遍历上。
#中序遍历(迭代法)
为了解释清楚,我说明一下 刚刚在迭代的过程中,其实我们有两个操作:
- 处理:将元素放进result数组中
- 访问:遍历节点
分析一下为什么刚刚写的前序遍历的代码,不能和中序遍历通用呢,因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
动画如下:
中序遍历,可以写出如下代码:
class Solution { public: vector<int> inorderTraversal(TreeNode* root) { vector<int> result; stack<TreeNode*> st; TreeNode* cur = root; while (cur != NULL || !st.empty()) { if (cur != NULL) { // 指针来访问节点,访问到最底层 st.push(cur); // 将访问的节点放进栈 cur = cur->left; // 左 } else { cur = st.top(); // 从栈里弹出的数据,就是要处理的数据(放进result数组里的数据) st.pop(); result.push_back(cur->val); // 中 cur = cur->right; // 右 } } return result; } };#后序遍历(迭代法)
再来看后序遍历,先序遍历是中左右,后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了,如下图:
所以后序遍历只需要前序遍历的代码稍作修改就可以了,代码如下:
class Solution { public: vector<int> postorderTraversal(TreeNode* root) { stack<TreeNode*> st; vector<int> result; if (root == NULL) return result; st.push(root); while (!st.empty()) { TreeNode* node = st.top(); st.pop(); result.push_back(node->val); if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈) if (node->right) st.push(node->right); // 空节点不入栈 } reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了 return result; } };


?统一非递归?
思路:
此时我们在二叉树:一入递归深似海,从此offer是路人?(opens new window)中用递归的方式,实现了二叉树前中后序的遍历。
在二叉树:听说递归能做的,栈也能做!?(opens new window)中用栈实现了二叉树前后中序的迭代遍历(非递归)。
之后我们发现迭代法实现的先中后序,其实风格也不是那么统一,除了先序和后序,有关联,中序完全就是另一个风格了,一会用栈遍历,一会又用指针来遍历。
实践过的同学,也会发现使用迭代法实现先中后序遍历,很难写出统一的代码,不像是递归法,实现了其中的一种遍历方式,其他两种只要稍稍改一下节点顺序就可以了。
其实针对三种遍历方式,使用迭代法是可以写出统一风格的代码!
重头戏来了,接下来介绍一下统一写法。
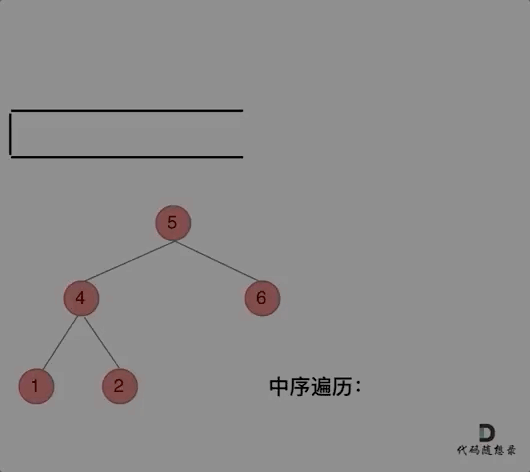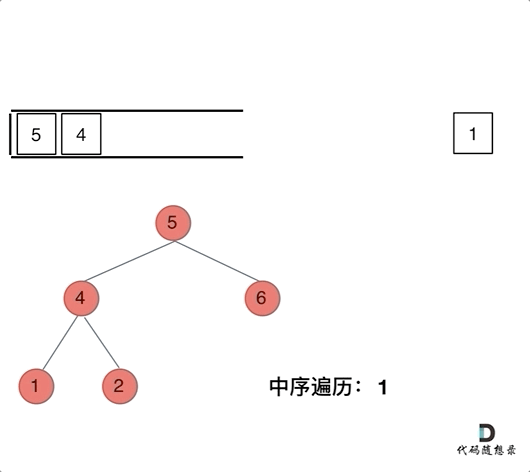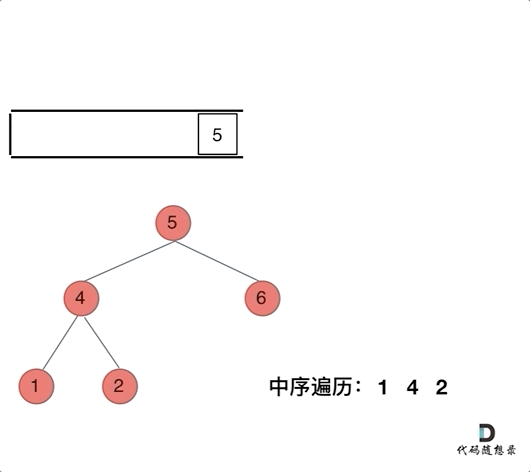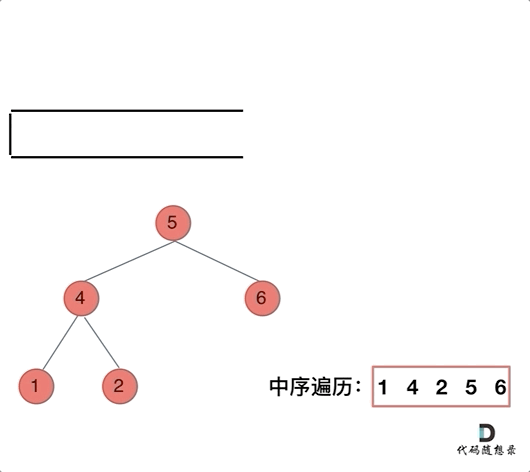
我们以中序遍历为例,在二叉树:听说递归能做的,栈也能做!?(opens new window)中提到说使用栈的话,无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况。
那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
如何标记呢,就是要处理的节点放入栈之后,紧接着放入一个空指针作为标记。?这种方法也可以叫做标记法。
#迭代法中序遍历
中序遍历代码如下:(详细注释)
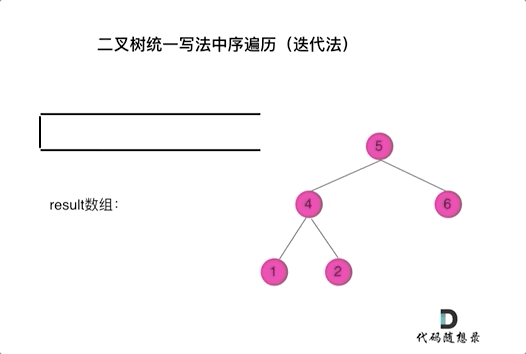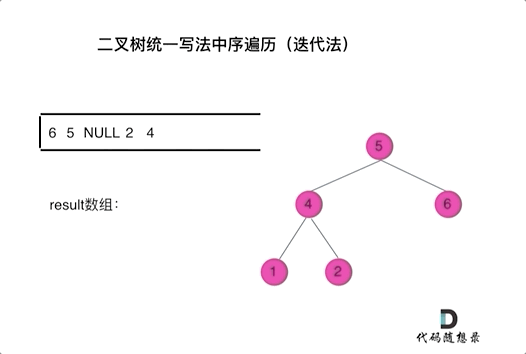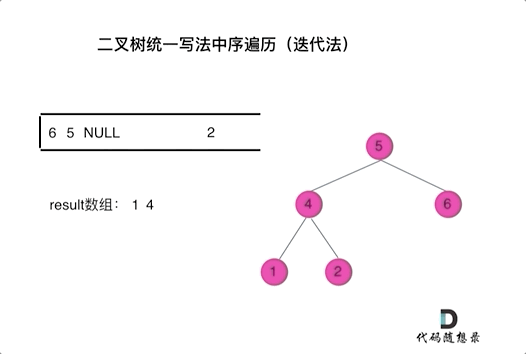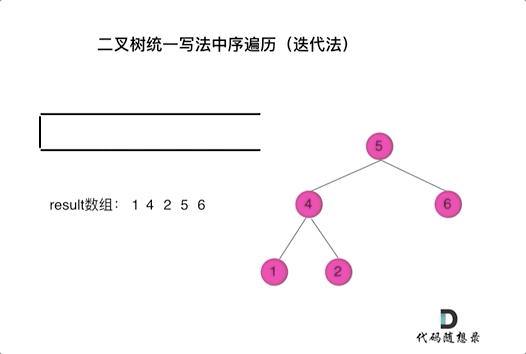
class Solution { public: vector<int> inorderTraversal(TreeNode* root) { vector<int> result; stack<TreeNode*> st; if (root != NULL) st.push(root); while (!st.empty()) { TreeNode* node = st.top(); if (node != NULL) { st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中 if (node->right) st.push(node->right); // 添加右节点(空节点不入栈) st.push(node); // 添加中节点 st.push(NULL); // 中节点访问过,但是还没有处理,加入空节点做为标记。 if (node->left) st.push(node->left); // 添加左节点(空节点不入栈) } else { // 只有遇到空节点的时候,才将下一个节点放进结果集 st.pop(); // 将空节点弹出 node = st.top(); // 重新取出栈中元素 st.pop(); result.push_back(node->val); // 加入到结果集 } } return result; } };看代码有点抽象我们来看一下动画(中序遍历):
动画中,result数组就是最终结果集。
可以看出我们将访问的节点直接加入到栈中,但如果是处理的节点则后面放入一个空节点, 这样只有空节点弹出的时候,才将下一个节点放进结果集。
此时我们再来看前序遍历代码。
#迭代法前序遍历
迭代法前序遍历代码如下: (注意此时我们和中序遍历相比仅仅改变了两行代码的顺序)
class Solution { public: vector<int> preorderTraversal(TreeNode* root) { vector<int> result; stack<TreeNode*> st; if (root != NULL) st.push(root); while (!st.empty()) { TreeNode* node = st.top(); if (node != NULL) { st.pop(); if (node->right) st.push(node->right); // 右 if (node->left) st.push(node->left); // 左 st.push(node); // 中 st.push(NULL); } else { st.pop(); node = st.top(); st.pop(); result.push_back(node->val); } } return result; } };#迭代法后序遍历
后续遍历代码如下: (注意此时我们和中序遍历相比仅仅改变了两行代码的顺序)
class Solution { public: vector<int> postorderTraversal(TreeNode* root) { vector<int> result; stack<TreeNode*> st; if (root != NULL) st.push(root); while (!st.empty()) { TreeNode* node = st.top(); if (node != NULL) { st.pop(); st.push(node); // 中 st.push(NULL); if (node->right) st.push(node->right); // 右 if (node->left) st.push(node->left); // 左 } else { st.pop(); node = st.top(); st.pop(); result.push_back(node->val); } } return result; } };
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- pandas笔记:找出在一个dataframe但不在另一个中的index
- Power BI案例-医院数据集的仪表盘制作
- 产教融合经验 | 赛宁与高校多年磨合出的育人之道
- OpenHarmony AI框架开发指导
- javacv和opencv对图文视频编辑-按指定间隔从视频抽取缩略图
- 分布式技术之分布式非集中式结构
- MySQL的聚簇索引和非聚簇索引的区别以及示例
- APS排产相关的leetcode
- 处理机调度与死锁
- DDIA 第十章:批处理