双端队列和优先级队列
前言
今天要介绍比较特殊的结构,双端队列。
还有一个适配器,优先级队列。
deque
栈的默认容器用了一个deque的东西,这个东西是啥?
deque虽然是队列,但它不是正队列,它是双端队列。
为什么叫双端队列,因为它最适合头插头删,尾插尾删。
deque对标的是vector+list.
它的结构和前面没有什么差别。

这些功能只有我们之前讲的list能做到。
最牛逼的是还有这个

看,它既支持vector的功能又支持list的功能。
但是这个东西真的这么牛吗?
要回答这个问题,我们得看一下deque的底层设计。
deque底层设计
我们先来分析一下顺序表和链表的区别。
顺序表:
它最大的优点就是空间连续随机访问,但是也带来了,头插,中间插入删除的困难。

其实顺序表还有一个优点就是高速缓存效率高,但是这里学习的时候不作为重点。
链表:

能不能把list和vector的优点合起来呢?
有人用了一个折中的思路。
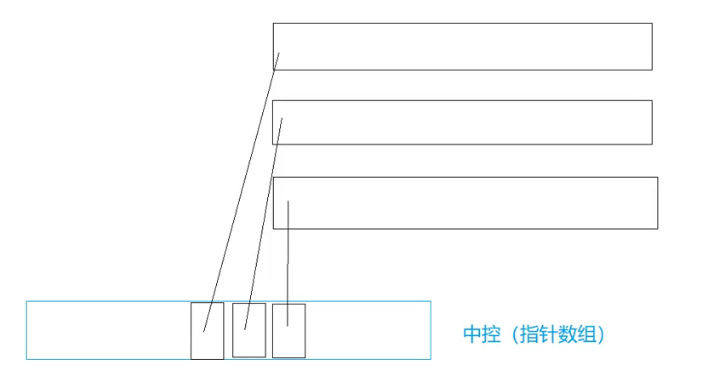
折中的思路,一次开一个的小数组,满了以后在开一段空间,不扩容。
怎样管理多端小数组?中控(指针数组)
假设我要头插或者尾插
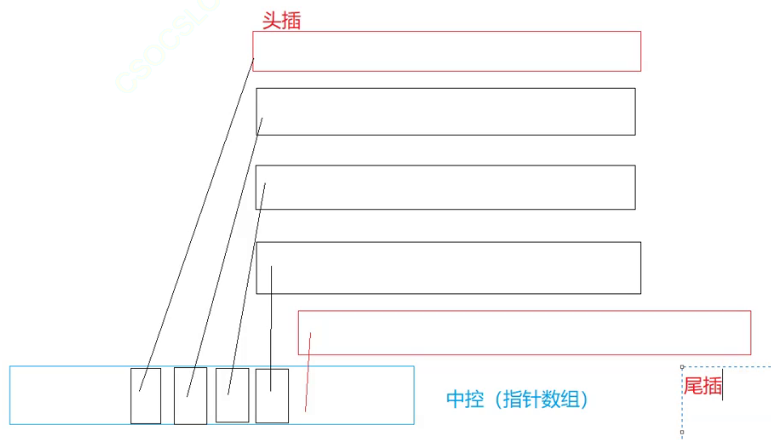
大家看这个结构什么时候需要扩容?
中控满了就需要扩容。但是扩容的代价低。因为中控扩容中只拷贝指针。
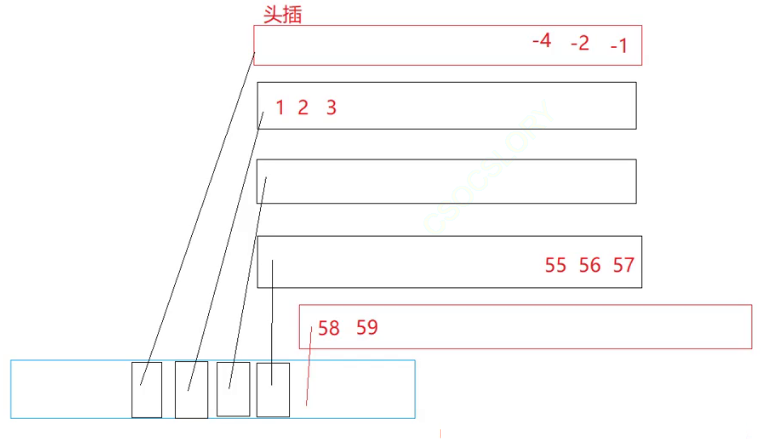
假设我要访问第25个数据,怎么访问?

小数组要不要扩容,这是很灵活的,得你自己去看
为什么它的扩容代价低?
相比vector而言,只需要拷贝指针,代价低了很多。
但相比list而言,还是比不过list,list没有扩容的概念,增加一个数据它就开一次空间。

注意,deque的随机访问比vector低,但是比list还是高很多。

deque适合干嘛?
头插头删多,尾插尾删多可以用。
大家可以去测试一下deque和vector和list sort的效率
其实效率都不如拷贝到vector,进行排序然后拷贝回去。
迭代器设计
它的迭代器设计是我们目前为止接触到最复杂的迭代器。
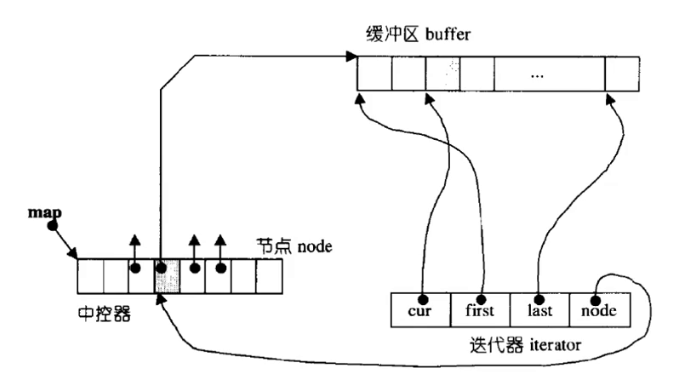
它有四个指针,看它们分别干嘛的?
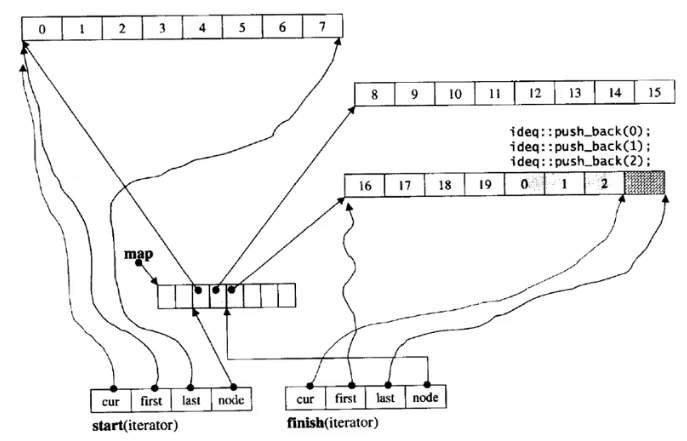
cur:当前指向数据的位置
first和last:buff数组开始和结束
node:反向指向中控数组

好像也没有那么难理解。
这里就不模拟实现了,deque在现实生活中用的其实不多,除了用来做头插头删,做deque的默认容器以外,
实际当中用的还是vector和list.
如果对deque有兴趣可以去看一下源码,但其实没必要,有些东西我们需要深入学习,但deque我们只需要
了解它的框架就可以了。
priority
这个东西还是挺适用的,很多地方都要用。

默认容器是vector,当然你也可以传deque,但是这里deque不如vector.
它有个要求,就是随机访问的迭代器。
它是优先级队列,看一下接口就知道了。

它的接口跟我们的堆很想。
它这里需不需要符合先进先出?
不需要,它是要求优先级高的先出。
它也不支持遍历,容器适配器都不支持遍历。
还是出一个走一个。
void test_priority_queue()
{
//默认是大堆,大的优先级高
priority_queue<int> pq;
pq.push(1);
pq.push(0);
pq.push(5);
pq.push(2);
pq.push(1);
pq.push(7);
while (!pq.empty())
{
cout << pq.top() << " ";
pq.pop();
}
cout << endl;
}
它默认认为什么的优先级高?
大的优先级高。
它的底层是一个vector,vector的底层实际是一个堆,也就是一个完全二叉树。
默认是大堆。
那我现在有一个问题,以后要用topk的时候,还需要自己写一个堆出来吗?
不需要。
如果要变成小堆,怎么办?
用了一个仿函数。

这里用了一个less,默认是大堆。
// 小堆 -- 小的优先级高
priority_queue<int, vector<int>, greater<int>> pq;
包一下这个文件
#include <functional>
仿函数
假设我需要写一个大于或小于的仿函数,怎么写呢?
其实很简单, 仿函数都有一个特点,重载一个()的运算符。
这个()就是函数参数的括号的运算符。
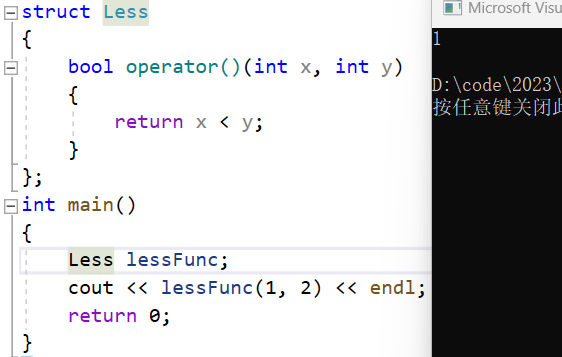
如果但看这一行,你会觉得lessFunc是什么?
cout << lessFunc(1, 2) << endl;
函数名或者函数指针,但它其实是一个对象。
这个类叫做仿函数。表示它的对象可以像函数一样去使用。但它的本质是调用operator(), 是运算符重载。
仿函数有什么好处?
它的好处是能更好的去做类型。模拟实现优先级队列的时候能更好理解。
它的对象可以像函数一样调用,我们就可以控制很多行为。
C++搞出这个东西是由于函数指针太复杂了。具体是函数指针的类型太复杂了。有些地方是要去做回调。
C的qsort

C++的sort

把上面的仿函数更改为针对任意类型。
#include <functional>
template<class T>
struct Less
{
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
int main()
{
Less<int> lessFunc;
cout << lessFunc(1, 2) << endl;
return 0;
}
下面我们用优先级队列来做一个题目
数组中的第k个最大元素


返回第k个最大元素,好不好找?
排序就搞定了。
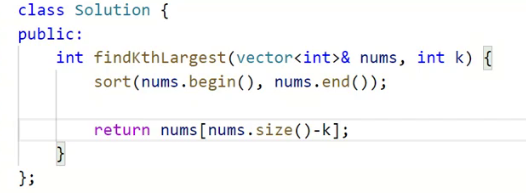
但是时间复杂度不满足
这道题最好的方式肯定还是快排的思想,我们这里不考虑这个,我们把堆用起来。
如果这道题优先级队列来解决,怎么解决?
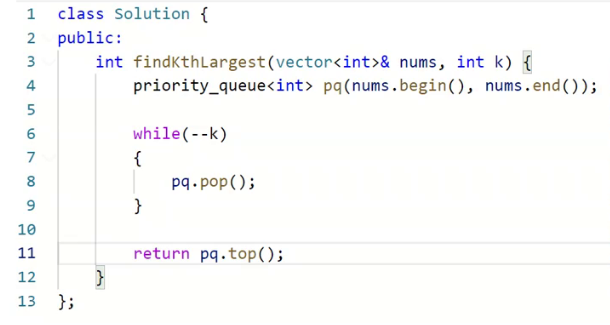
pop k次,堆顶的元素就是我们要找的元素。
这样写,时间复杂度是多少?
第四行的时间复杂度是多少?N
我们知道向下建堆可以O(N).
pop的时间复杂是多少?
K*logN
所以合计的时间复杂度。
O(KlogN+N)
这里如果k==N,那就麻烦了,时间复杂度是NlogN
假设N远大于k,且N很大,有什么优化方式?
我们要找最大的前k个,除了全部建大堆,还有没有其他方式?
我们还可以建k个元素的堆。
那我们建大堆还是小堆?
Top k最大的前k个,我们是要建小堆。
看代码
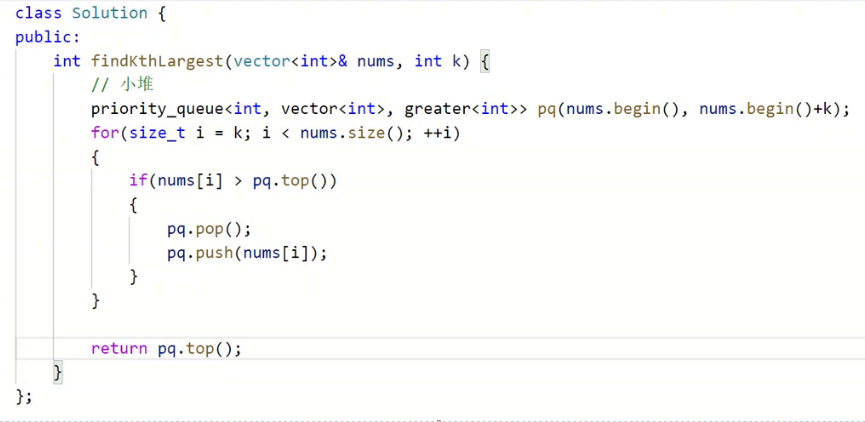
这样解决时间复杂度是多少?
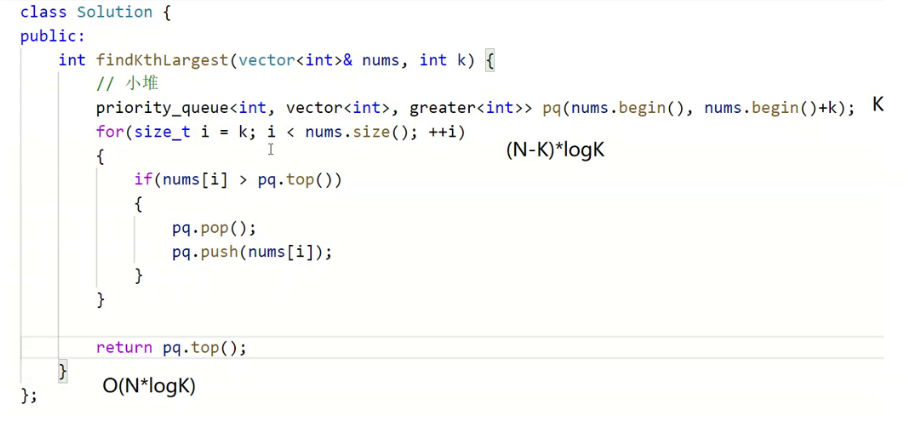
它最大的特点是消耗空间很小。
我们学会了优先级队列,根本不需要去手搓一个堆
优先级队列模拟实现
首先,底层要存数据还是用vector这样的东西来存.
接着我们在把要写的接口给写出来,这跟栈还是很像的。

push
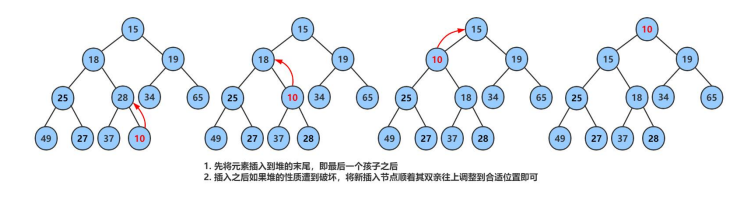
想一想堆是怎么push数据的?
堆的底层是一个数组的结构。我们插入数据的时候向上调整。

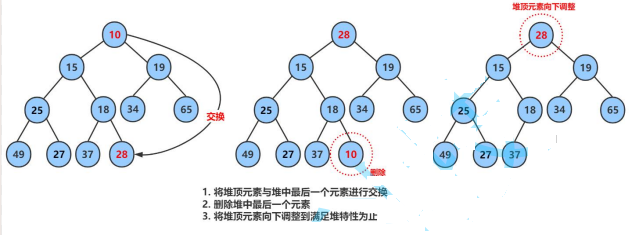
pop
堆的数据删除怎么删?
堆的删除直接删,不然堆就挪乱了。效率极低。
堆删除数据是删除第一个数据,将第一个数据和最后一个数据交换,然后删除最后一个数据,然后从根开始向下调整。

调整
怎呢向上调整?
跟父结点比,挨着挨着往上走就可以了。
先搞大堆。

template<class T, class Container = vector<T>>
class priority_queue
{
public:
void adjust_up(int child)
{
Comapre com;
int parent = (child - 1) / 2;
while (child > 0)
{
if (_con[parent] < _con[child])
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void adjust_down(int parent)
{
size_t child = parent * 2 + 1;
while (child < _con.size())
{
Comapre com;
if (child + 1 < _con.size()
&& _con[child] < _con[child + 1])
{
++child;
}
if (_con[parent] < _con[child])
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
adjust_up(_con.size()-1);
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
adjust_down(0);
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
快速写了一个优先级队列,测试一下,自己写的代码。
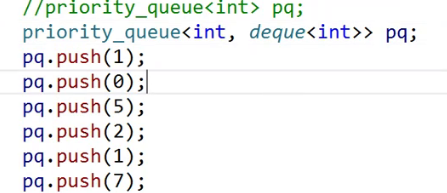
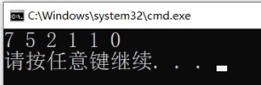
它的适配器默认是vector,这里用deque,但是它照样能跑。
也就是说这里你只需要符合它的需求,满足上面的接口,这个程序都可以正常运行。
它们的底层已经天差地别了,一个是vector,一个是双端队列,但是对这个上层的优先级队列完全没有影响。这就是容器适配器,只要你那个东西满足我的需求,我就可以转换成我想要的东西。
仿函数
上面写的是大堆的代码,那我要变成小堆呢?
要变成小堆,就要控制上面调整的比较方式。

总不能纯手搓吧。我们肯定是先把大堆写出来,加东西,然后顺便改一下就变成小堆了。
那这一定是外部可以传一个东西去控制,它这里是通过模板参数去控制的。
怎么通过模板参数来控制呢?
先写两个可以比较的仿函数。
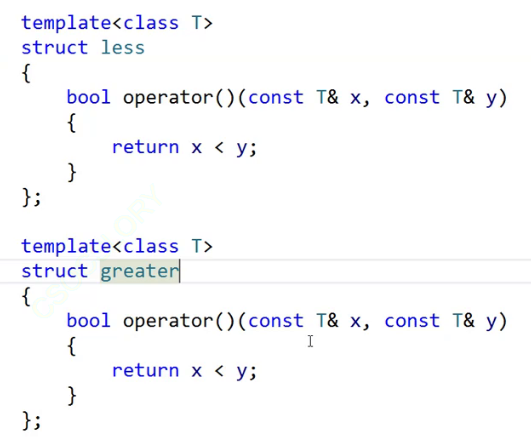
那就可以用这个类型的对象去比较。
//跟库里面保持一致,大堆用一个小于。
template<class T, class Container = vector<T>, class Compare = less<T>>
神奇的事情发生了。
大堆和小堆就可以随意更换了。
void adjust_up(int child)
{
Comapre com;
int parent = (child - 1) / 2;
while (child > 0)
{
//if (_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
//if (Comapre()(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void adjust_down(int parent)
{
size_t child = parent * 2 + 1;
while (child < _con.size())
{
Comapre com;
//if (child + 1 < _con.size()
// && _con[child] < _con[child + 1])
if (child + 1 < _con.size()
&& com(_con[child],_con[child + 1]))
{
++child;
}
//if (_con[parent] < _con[child])
if (com(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
template<class T, class Container = vector<T>, class Compare =less<T>>
以前用的泛型是控制数据类型,不知道具体的数据类型是什么,你传什么就是什么。
现在控制的不是类型,控制的是比较方式。默认它是less,那com就是less对象,less对象去调用operator(),那它就是小于比较方式。

它能够通过模板参数传类型,类型里面实例化对象控制比较的方式。
跟函数指针的比较
模板传的是类型,仿函数是一个类。类型就可以在模板参数传,模板参数传有什么好处?
我整个类都可以用。
仿函数还有其他功能,我们在后面会C++的学习中会慢慢感受到
存储自定义类型
假设我们优先级数列存储的数据不再是内置类型。自定义类型,能不能用优先级队列。
也可以。
大堆:
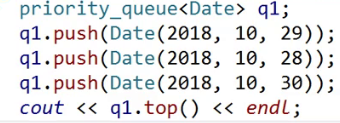

小堆:
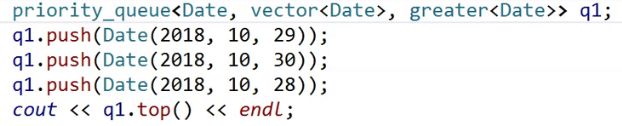
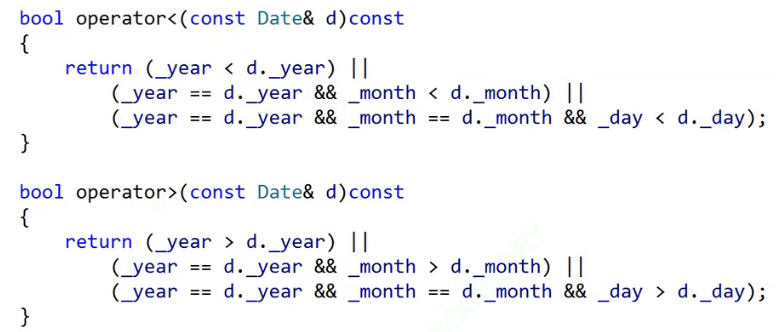
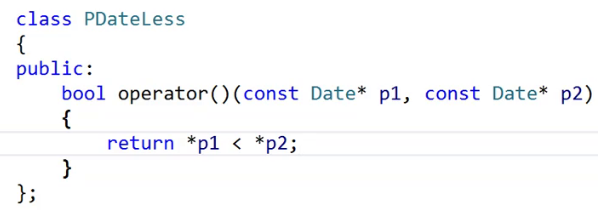
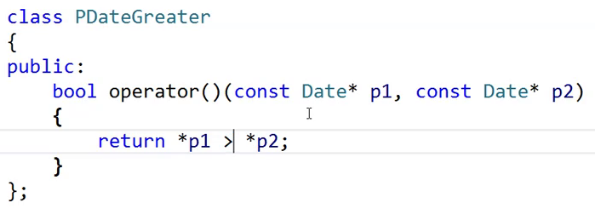
日期类需要重载大于,小于才行。
如果没有重载就需要写仿函数才能搞定。
给大家看一下更牛逼的东西。
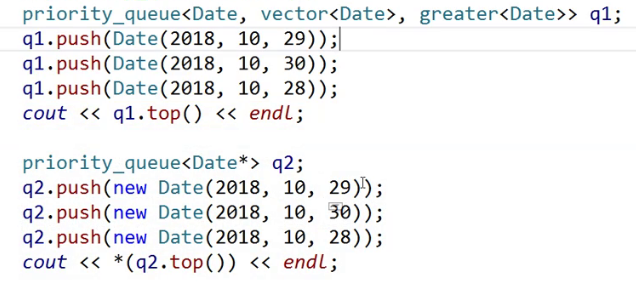
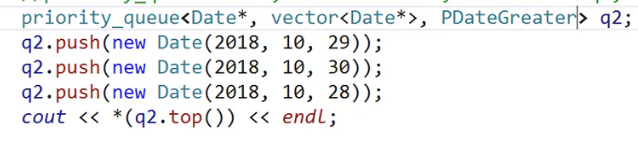
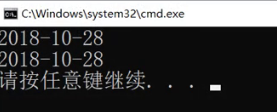
结果每次都不一样
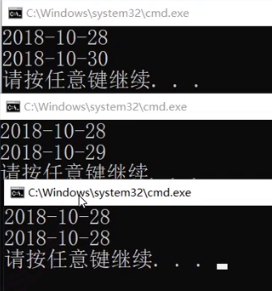
怎么回事呢?
现在存进去的T是Date*,不是Date.
Date* 可以进行比较,但这不是我想要的。
Date* 是new出来的,new是堆上申请的空间,那个地址可能先大先小,完全没有规律。
template<class T, class Container = vector<T>, class Compare =less<T>>
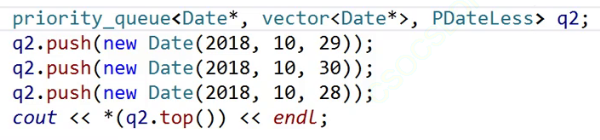
如果我非要这样比较呢?
我们的骚操作又要上场了。
默认是大堆。
再怎么运行他都不会变。
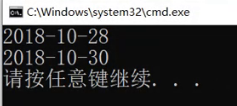
小堆:
再写一个仿函数
这是不是给了一个非常大的空间
它真正的优势在于,我就是个compare对象,有个默认比较方式,但是你想要其他的比较方式,全部都可以交给你控制。你想怎么比就怎么比。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- OpenHarmony开发之WebGL开发指导与介绍
- 揭开 JavaScript 作用域的神秘面纱(下)
- RobotMaster+KUKA——实际工作遇到问题及其解决方案
- innovus:insert Power Switch失败,报告not covered by a row问题解析
- Deepin使用记录-deepin安装docker
- 终于有人把接口测试讲明白了!
- 使用nginx搭建网页
- 探寻未来卫生新境界:互联网公厕是什么意思
- B端产品经理学习-版本规划管理
- Linux 在CUDA11.1上安装pytorch