Langchain-Chatchat在LLM RAG的落地实践浅谈
发布时间:2024年01月11日
RAG的WHAT、WHY、HOW



Langchain-Chatchat实现原理
Langchain-Chatchat实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的?top k个 -> 匹配出的文本作为上下文和问题一起添加到?prompt中 -> 提交给?LLM生成回答。
Langchain-Chatchat组成模块
文档解析器


文本分割器



Embedding模型
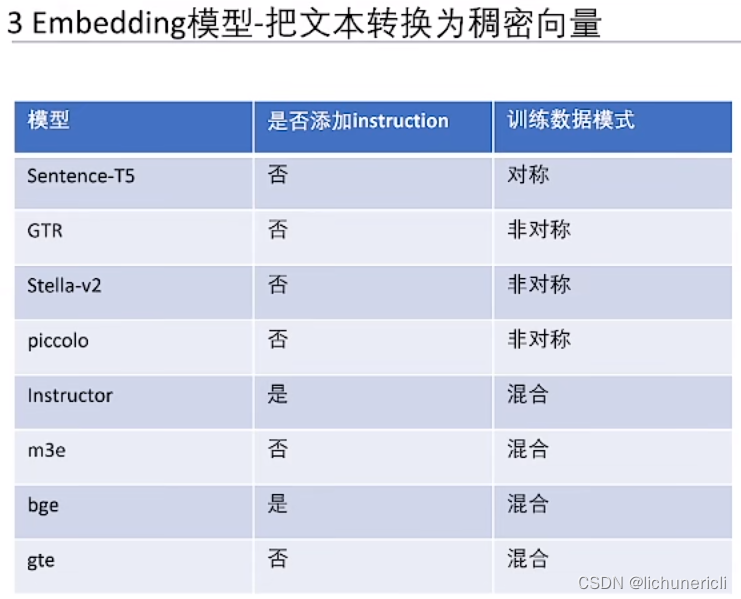

对称与非对称嵌入
在自然语言处理中,嵌入(Embedding)是将词语或文本转换为向量表示的过程。这些向量被设计为在计算机中容易处理和比较的形式,以便用于机器学习和深度学习任务。
对称嵌入(Symmetric Embedding)是指在嵌入空间中,具有相似含义的词语或文本具有类似的向量表示。这意味着它们在嵌入空间中的距离或相似度是对称的,如果词语 A 与词语 B 的嵌入向量非常接近,则词语 B 与词语 A 的嵌入向量也应该非常接近。对称嵌入的一个常见例子是 Word2Vec 模型中的词向量表示。
非对称嵌入(Asymmetric Embedding)则是指在嵌入空间中,具有相似含义的词语或文本可能具有不同的向量表示。这意味着它们在嵌入空间中的距离或相似度可能是非对称的,即词语 A 与词语 B 的嵌入向量与词语 B 与词语 A 的嵌入向量可能不完全相似。非对称嵌入可以通过使用不同的嵌入方法或模型来实现,例如使用预训练的语言模型(如BERT)。
对称嵌入和非对称嵌入在不同的任务和应用中具有不同的优势和用途。对称嵌入通常适用于一些基本的语义相似度任务,而非对称嵌入则可以更好地捕捉词语或文本之间的细微差异和语境信息。选择使用哪种类型的嵌入取决于具体的应用场景和任务需求。
向量数据库


HNSW算法?


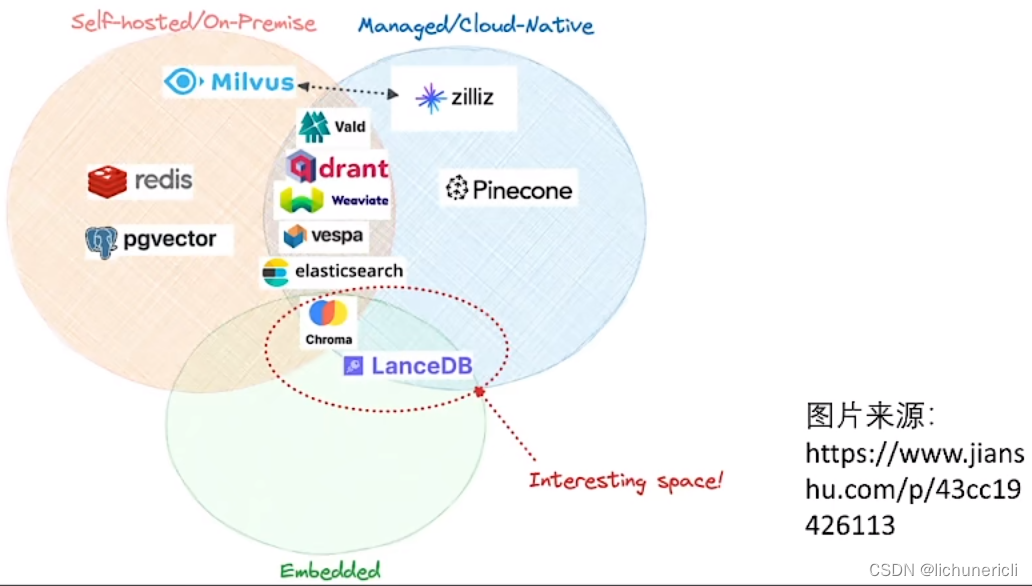
向量数据库选择

检索




RAG增强








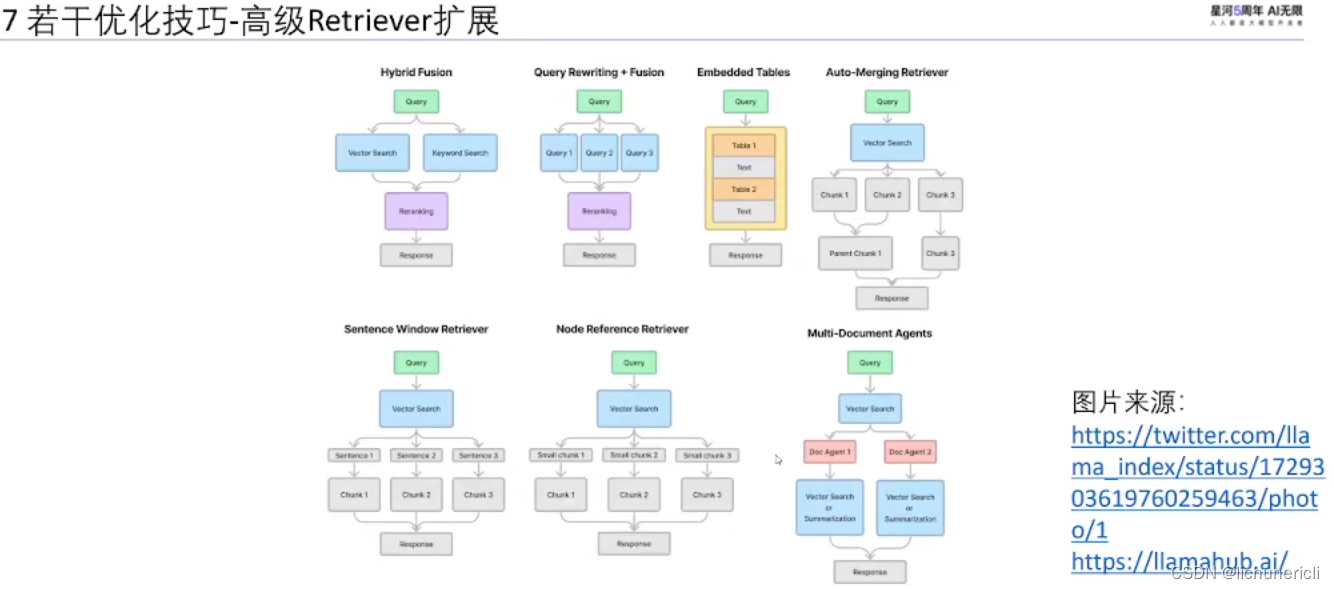
若干优化技巧?


文章来源:https://blog.csdn.net/lichunericli/article/details/135501899
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!