【React源码 - Diff算法】
介绍
在React学习中,Diff算法(协调算法),想必我们并不陌生,简单来说就是一个对比新老节点寻找差异,然后找出最小的一个变化集,最后对这个最小变化集进行最小的DOM操作,本文将从源码来分析在React(17.0.2)中是如何来通过这个算法来进行对比并让Renderer知道如果操作DOM的。
在reconcileChildFibers中,主要是通过newChild的类型以及type来判断执行那个函数来更新fiber,其中主要类型分为非空对象、字符串/数字、数组、可迭代类型。
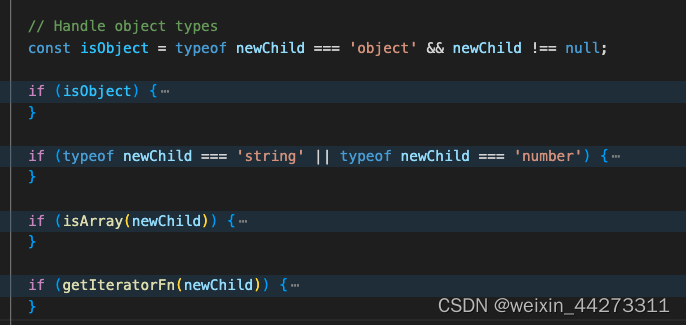
其中我们主要对非空对象的React Element(reconcileSingleElement函数)以及数组(reconcileChildrenArray函数,可迭代reconcileChildrenIterator和该函数核心逻辑大致一样)的处理来分析DIff算法:
if (isObject) {
switch (newChild.$$typeof) {
case REACT_ELEMENT_TYPE:
return placeSingleChild(
reconcileSingleElement(
returnFiber,
currentFirstChild,
newChild,
lanes,
),
);
case REACT_PORTAL_TYPE:
return placeSingleChild(
reconcileSinglePortal(
returnFiber,
currentFirstChild,
newChild,
lanes,
),
);
case REACT_LAZY_TYPE:
if (enableLazyElements) {
const payload = newChild._payload;
const init = newChild._init;
// TODO: This function is supposed to be non-recursive.
return reconcileChildFibers(
returnFiber,
currentFirstChild,
init(payload),
lanes,
);
}
}
}
if (isArray(newChild)) {
return reconcileChildrenArray(
returnFiber,
currentFirstChild,
newChild,
lanes,
);
}
DIff算法可以分为两种:
- 单节点对比(reconcileSingleElement)
- 多节点对比(reconcileChildrenArray)
单节点对比
我们从reconcileSingleElement函数来分析,当虚拟DOM为一个非空对象时,React是如何进行单节点对比的:
function reconcileSingleElement(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
element: ReactElement
): Fiber {
const key = element.key;
let child = currentFirstChild;
// 首先判断是否存在对应DOM节点
while (child !== null) {
// 上一次更新存在DOM节点,接下来判断是否可复用
// 首先比较key是否相同
if (child.key === key) {
// key相同,接下来比较type是否相同
switch (child.tag) {
// ...省略case
default: {
if (child.elementType === element.type) {
// 将该fiber及其兄弟fiber标记为删除
deleteRemainingChildren(returnFiber, child.sibling);
// type相同则表示可以复用
const existing = useFiber(child, element.props);
// 更新复用节点的ref
existing.ref = coerceRef(returnFiber, child, element);
existing.return = returnFiber;
// 返回复用的fiber
return existing;
}
// type不同则跳出switch
break;
}
}
// 代码执行到这里代表:key相同但是type不同
// 将该fiber及其兄弟fiber标记为删除
deleteRemainingChildren(returnFiber, child);
break;
} else {
// key不同,将该fiber标记为删除
deleteChild(returnFiber, child);
}
child = child.sibling;
}
// 创建新Fiber,并返回 ...省略
}
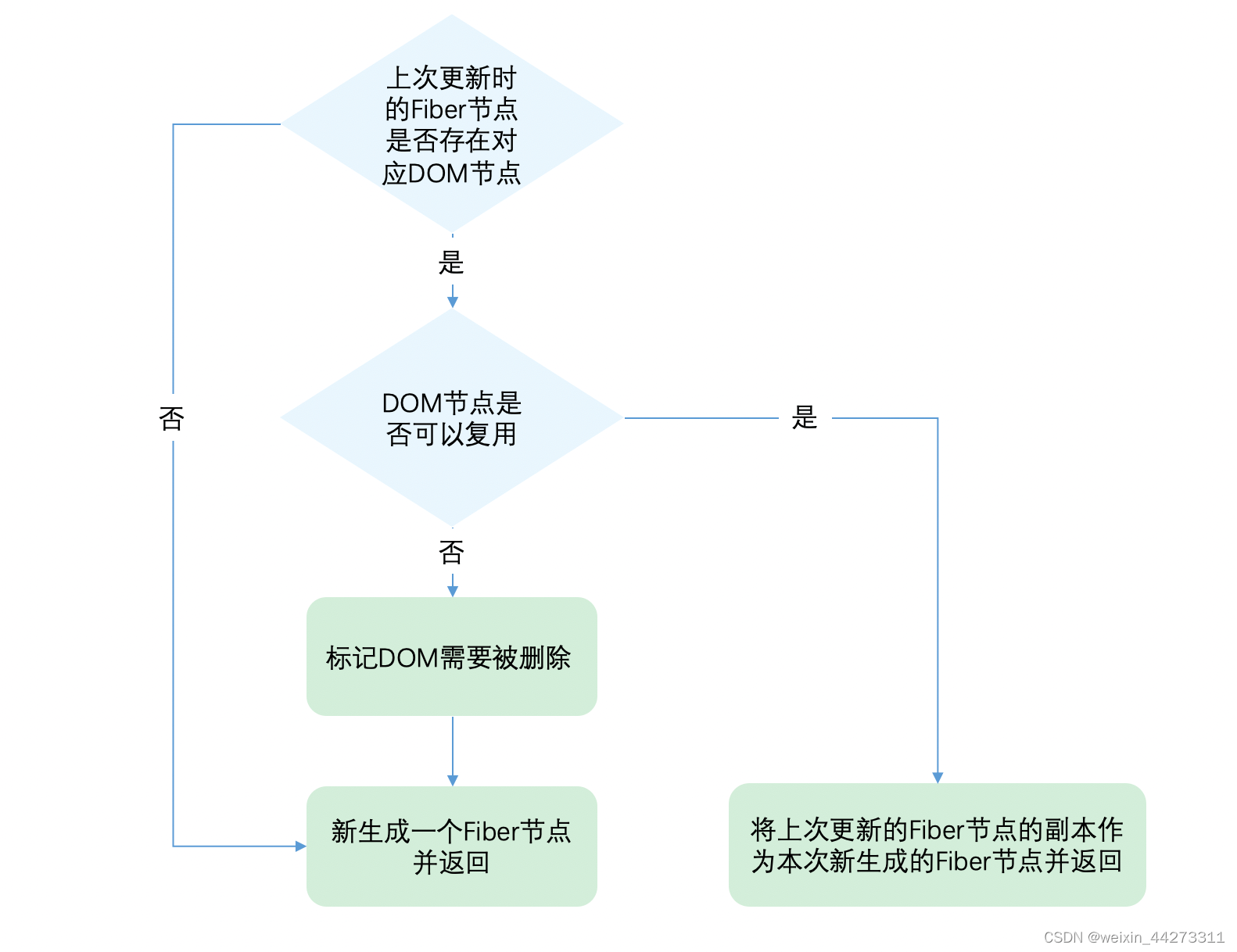
从代码中能看出,先判断当前fiber是否有对应的dom节点,如果是新增节点(child === null), 直接新建 fiber, 没有多余的逻辑。如果是对比更新,如果key不一样则给当前fiber打上delete的标记,继续遍历兄弟节点,key一样type不一样则给当前fiber和其兄弟节点都打上delete标记,key和type都相同(即: ReactElement.key === Fiber.key 且 Fiber.elementType === ReactElement.type), 则复用useFiber,并更新ref,否则新建。
注意: 复用过程是调用useFiber(child, element.props)创建新的fiber对象, 这个新fiber对象.stateNode = currentFirstChild.stateNode, 即stateNode属性得到了复用, 故 DOM 节点得到了复用.因为stateNode保存的就是DOM节点信息.所以常说的复用节点可以简单粗暴的理解为复用stateNode属性
当key相同且type不同时,代表我们已经根据key找到本次更新组件,但是组件发生了更新,不能复用。既key的唯一可能性已经不能复用,则剩下的fiber都没有继续查找的必要,所以都需要标记删除。
当key不同时只代表遍历到的该fiber不能被复用,后面还有兄弟fiber还没有遍历到。所以仅仅标记该fiber删除。
代码流程可以简述为:
多节点对比
这里我们通过reconcileChildrenArray来分析React中对于多节点是如何进行对比复用的。
// reconcileChildFibers函数中
if (isArray(newChild)) {
return reconcileChildrenArray(
returnFiber,
currentFirstChild,
newChild,
lanes,
);
}
通过isArray判断是否是数组,如果是则进行多节点Diff对比,会进行两次遍历,
function reconcileChildrenArray(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChildren: Array<*>,
lanes: Lanes,
): Fiber | null {
let resultingFirstChild: Fiber | null = null;
let previousNewFiber: Fiber | null = null;
let oldFiber = currentFirstChild;
let lastPlacedIndex = 0;
let newIdx = 0;
let nextOldFiber = null;
// 1. 第一次循环: 遍历最长公共序列(key相同), 公共序列的节点都视为可复用
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
// 后文分析
}
if (newIdx === newChildren.length) {
// 如果newChildren序列被遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记)
deleteRemainingChildren(returnFiber, oldFiber);
return resultingFirstChild;
}
if (oldFiber === null) {
// 如果oldFiber序列被遍历完, 那么newChildren序列中剩余节点都视为新增(打上Placement标记)
for (; newIdx < newChildren.length; newIdx++) {
// 后文分析
}
return resultingFirstChild;
}
// ==================分割线==================
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// 2. 第二次循环: 遍历剩余非公共序列, 优先复用oldFiber序列中的节点
for (; newIdx < newChildren.length; newIdx++) {}
if (shouldTrackSideEffects) {
// newChildren已经遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记)
existingChildren.forEach((child) => deleteChild(returnFiber, child));
}
return resultingFirstChild;
}
所谓的新老节点对比,在这里就是currentFirstChild和newChildren两个序列的对比:
- currentFirstChild: 是一个fiber节点, 通过fiber.sibling可以将兄弟节点全部遍历出来. 所以可以将currentFirstChild理解为链表头部, 它代表一个序列, 源码中被记为oldFiber.
- newChildren: 是一个数组, 其中包含了若干个ReactElement对象. 所以newChildren也代表一个序列.
所以reconcileChildrenArray实际就是 2 个序列之间的比较(链表oldFiber和数组newChildren), 最后返回合理的fiber序列.
上述代码中, 以注释分割线为界限, 整个核心逻辑分为 2 步骤:
- 第一次循环: 遍历最长公共序列(key 相同), 公共序列的节点都视为可复用
如果newChildren序列被遍历完, 那么oldFiber序列中剩余节点都视为删除(打上Deletion标记)
如果oldFiber序列被遍历完, 那么newChildren序列中剩余节点都视为新增(打上Placement标记) - 第二次循环: 遍历剩余非公共序列, 优先复用 oldFiber 序列中的节点,以[key, oldFiber]的形式Map结构存储,方便快速查找复用节点
在对比更新阶段(非初次创建fiber, 此时shouldTrackSideEffects被设置为 true). 第二次循环遍历完成之后, oldFiber序列中没有匹配上的节点都视为删除(打上Deletion标记)
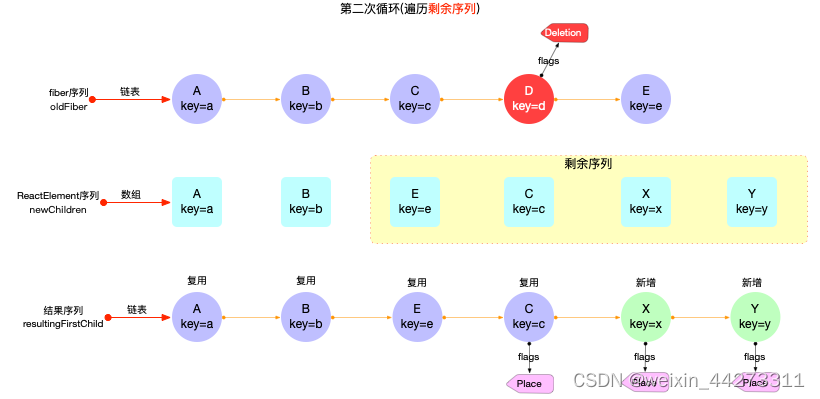
假设有如下图所示 2 个初始化序列:
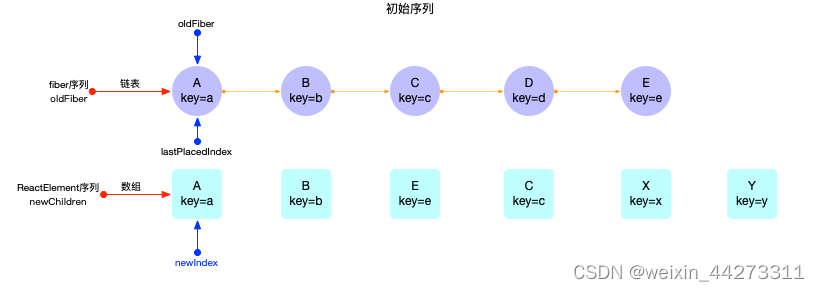
接下来第一次循环, 会遍历公共序列A,B, 生成的 fiber 节点fiber(A), fiber(B)可以复用.
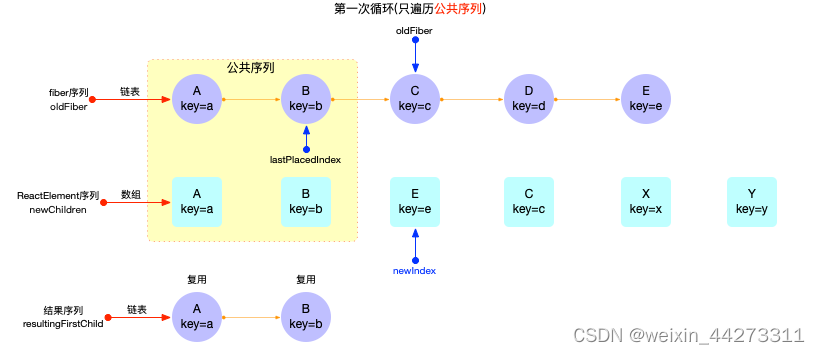
最后第二次循环, 会遍历剩余序列E,C,X,Y:
- 生成的 fiber 节点fiber(E), fiber?可以复用. 其中fiber?节点发生了位移(打上Placement标记).
- fiber(X), fiber(Y)是新增(打上Placement标记).
- 同时oldFiber序列中的fiber(D)节点确定被删除(打上Deletion标记).
整个主干逻辑就介绍完了, 接下来贴上完整源码
第一次循环:
// 1. 第一次循环: 遍历最长公共序列(key相同), 公共序列的节点都视为可复用
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
if (oldFiber.index > newIdx) {
nextOldFiber = oldFiber;
oldFiber = null;
} else {
nextOldFiber = oldFiber.sibling;
}
// new槽位和old槽位进行比较, 如果key不同, 返回null
// key相同, 比较type是否一致. type一致则执行useFiber(update逻辑), type不一致则运行createXXX(insert逻辑)
const newFiber = updateSlot(
returnFiber,
oldFiber,
newChildren[newIdx],
lanes,
);
if (newFiber === null) {
// 如果返回null, 表明key不同. 无法满足公共序列条件, 退出循环
if (oldFiber === null) {
oldFiber = nextOldFiber;
}
break;
}
if (shouldTrackSideEffects) {
// 若是新增节点, 则给老节点打上Deletion标记
if (oldFiber && newFiber.alternate === null) {
deleteChild(returnFiber, oldFiber);
}
}
// lastPlacedIndex 记录被移动的节点索引
// 如果当前节点可复用, 则要判断位置是否移动.
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 更新resultingFirstChild结果序列
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
oldFiber = nextOldFiber;
}
第二次循环:
// 1. 将第一次循环后, oldFiber剩余序列加入到一个map中. 目的是为了第二次循环能顺利的找到可复用节点
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// 2. 第二次循环: 遍历剩余非公共序列, 优先复用oldFiber序列中的节点
for (; newIdx < newChildren.length; newIdx++) {
// [key, oldFiber]形式存储在Map结构中,方便快速查找
const newFiber = updateFromMap(
existingChildren,
returnFiber,
newIdx,
newChildren[newIdx],
lanes,
);
if (newFiber !== null) {
if (shouldTrackSideEffects) {
if (newFiber.alternate !== null) {
// 如果newFiber是通过复用创建的, 则清理map中对应的老节点
existingChildren.delete(newFiber.key === null ? newIdx : newFiber.key);
}
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// 更新resultingFirstChild结果序列
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
}
// 3. 善后工作, 第二次循环完成之后, existingChildren中剩余的fiber节点就是将要被删除的节点, 打上Deletion标记
if (shouldTrackSideEffects) {
existingChildren.forEach((child) => deleteChild(returnFiber, child));
}
所以无论是单节点还是多节点、可迭代节点的比较, 最终的目的都是生成下级子节点. 并在reconcileChildren过程中, 给一些有副作用的节点(新增, 删除, 移动位置等)打上副作用标记, 等待 commit 阶段(Renderer)的处理.
时间复杂度
Diff 算法并非 React 独创,React 只是在传统 Diff 算法做了优化,将 diff 算法的时间复杂度一下子从 传统递归O(n^3)降到 两次循环O(n),其中n是树中元素数量。为了降低算法复杂度,React中对Diff算法做了以下优化:
1、同级对比
只对同级元素进行Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他,即对相同层级的 虚拟DOM 节点进行比较,同一个父节点下的所有子节点。当发现节点已经不存在时,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。
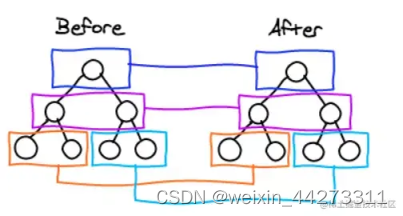
如果DOM节点前后更新跨越了层级,React则不会复用,直接新建节点并删除原来节点:

2、类型比较
当比较两个节点时,首先检查它们的类型。如果类型不同,React 会销毁旧节点,并建立新节点。这种类型检查适用于不同的HTML标签或不同的组件类型。
3、Key标识
在处理动态子元素列表时,React 使用 keys 来识别每个元素的唯一性。这有助于确定哪些元素在重新渲染时保持不变,哪些元素需要更改。合理使用 keys 可以极大地提高性能,尤其是在列表和动态内容中。
4、避免不必要的 DOM 操作
通过比较新旧虚拟DOM树,React 可以确定实际需要进行的最小 DOM 更新,从而避免不必要的操作。一个虚拟DOM的Key和Type一样就认为该节点可以复用。
5、批量更新与异步渲染
React 会将多个 setState/useState 调用合并成一个批量更新,以减少渲染次数。React 17 及以后版本中,引入了新的并发模式,允许更灵活的异步渲染。
优化策略
基于React对于传递Diff的优化总结,我们可以通过以下方式来进行优化,简化对比:
- Keys:在列表中使用唯一的key可以帮助React识别哪些元素改变了,哪些没有。这样React可以只重新渲染那些改变了的元素,而不是整个列表。
- 组件级别的比较:React在比较组件时,如果组件类型相同,则会比较其props和state;如果组件类型不同,则会销毁旧组件并创建新组件。
- 避免不必要的重新渲染:使用shouldComponentUpdate、React.memo或PureComponent来避免不必要的渲染。
- 虚拟DOM树的结构优化:合理的组织组件结构,避免过深的虚拟DOM树,可以减少diff算法需要比较的节点数,从而提高性能。
- 使用不可变数据:这可以帮助快速比较props和state的变化,因为不可变数据在发生变化时会产生一个新的对象。
- 懒加载组件:对于大型应用中的一些不常用组件,可以使用懒加载技术,只有当这些组件需要被展示时,才加载它们。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ubuntu pycharm 死机,如何重启
- 京东年度数据报告-2023全年度笔记本十大热门品牌销量(销额)榜单
- JS eval函数实现把字符串当脚本执行
- 主流进销存系统有哪些?企业该如何选择进销存系统?
- 信创之国产浪潮电脑+统信UOS Linux操作系统体验10:visual studio code中调试C++程序
- uni-app中代理的两种配置方式
- vue3中使用markdown编辑器
- 哈希-力扣350. 两个数组的交集Ⅱ
- 【JavaWeb学习笔记】15 - jQuery
- 洛谷P1055 [NOIP2008 普及组] ISBN 号码(C语言)