Python 的多进程与多线程编程(进阶)
参考内容:https://www.bilibili.com/video/BV1Ev411G7i3?p=3&vd_source=9c227976fc64451bd98c5af8637d55e0
1. GIL锁
在上一篇文章“Python 的多进程与多线程编程(简单入门)”中提到线程和进程的优势分别在于:
| 进程 | 线程 | |
|---|---|---|
| 优势 | 可以实现多核CPU并行 | 资源耗费少 |
| 劣势 | 资源耗费大 | 仅能实现单核CPU并发 |
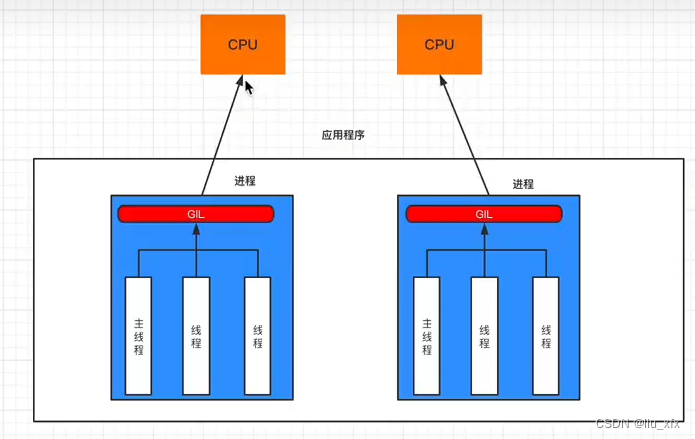
那么为什么线程仅能使用单核CPU呢?这与GIL锁(全局解释器锁,Global Interpreter Lock, GIL)有关,GIL锁是CPython解释器特有一个玩意,让一个进程中同一个时刻只能有一个线程可以被CPU调用。去关系如图所示。
那么很自然存在一个问题,什么时候使用多线程,什么时候使用多进程?
- 计算密集型,用多进程,例如:大量的数据计算
- IO密集型,用多线程,例如: 文件读写、网络数据传输
2. 多线程
2.1 多线程执行顺序
2.1.1 守护主线程
在上一篇文章“Python 的多进程与多线程编程(简单入门)”中提到可以通过以下两种方法设置守护主线程:即主线程结束后自动销毁子线程;
def task():
pass
# 设置守护主线程方法1:实例化对象时设置参数 daemon = True
thread1 = threading.Thread(target=task, daemon = True)
# 设置守护主线程方法2:在运行多线程之前设置参数 对象名.SetDaemon = True
thread1.SetDaemon = True
2.1.2 通过 join() 等待实现顺序控制
但很多时候,我们希望主线程(由进程自动创建,用于逐行执行代码)能够等待子线程的执行完毕才继续执行,从而避免代码计算紊乱的问题。可以通过多线程对象的成员函数:join() 来实现,具体可以看以下例子:
import threading
import time
# 定义全局变量,用于存储 求和结果
sumval = 0
def task_add():
# 线程任务为:计算 1+2+...+1e7
global sumval
for i in range(int(1e7)):
sumval += i
def task_sub():
# 线程任务为:计算 -1-2-...-1e7
global sumval
for i in range(int(1e7)):
sumval -= i
if __name__ == '__main__':
# 创建 2 个子线程
subthread1 = threading.Thread(target=task_add)
subthread2 = threading.Thread(target=task_sub)
subthread1.start()
subthread1.join()
subthread2.start()
subthread2.join()
print('Sumval is: ', sumval)
'''
没有添加 join() 函数的输出(运行三次):每次结果都不一样,即计算混乱;
Sumval is: 257516095655
Sumval is: 185387711992
Sumval is: 258007091260
添加 join() 函数的输出(运行三次):每次结果都一样;
Sumval is: 0
Sumval is: 0
Sumval is: 0
'''
2.1.3 通过线程递归锁加锁 threading.Rlock() 实现顺序控制
加锁操作主要包括:创建锁 、 申请锁 和 释放锁 三种操作。笔者认为加锁操作可以简单通俗理解为:一把锁只有一根钥匙,但是这把锁可以锁住多个门,第一个先到的人可以直接领取钥匙,直到其归还钥匙其他人才能用该钥匙打开其他的门。
import threading
import time
# 定义全局变量,用于存储 求和结果
sumval = 0
# 1. 创建锁
lock = threading.RLock()
def task_add():
# 线程任务为:计算 1+2+...+1e7
global sumval
# 2. 加锁
lock.acquire()
for i in range(int(1e7)):
sumval += i
# 3. 释放锁
lock.release()
def task_sub():
# 线程任务为:计算 -1-2-...-1e7
global sumval
# 2. 加锁
lock.acquire()
for i in range(int(1e7)):
sumval -= i
# 3. 释放锁
lock.release()
if __name__ == '__main__':
# 创建 2 个子线程
subthread1 = threading.Thread(target=task_add)
subthread2 = threading.Thread(target=task_sub)
subthread1.start()
subthread2.start()
subthread1.join() # 注意:相对上一个案例 两个 join() 函数都放在 start() 后面
subthread2.join()
print('Sumval is: ', sumval)
'''
没有添加 lock.acquire() 加锁函数的输出(运行三次):每次结果都不一样,即计算混乱;
Sumval is: -11829240444414
Sumval is: 20009353273876
Sumval is: -8127810892288
添加 lock.acquire() 加锁函数的输出(运行三次):每次结果都一样;
Sumval is: 0
Sumval is: 0
Sumval is: 0
'''
2.2 死锁
除了上述提到的递归锁 threading.RLock 还有 同步锁 threading.Lock,两者都能实现线程加锁的功能,但是 递归锁 RLock 的缺点在于,其速度较慢,而 同步锁 Lock 的缺点在于其不支持锁的嵌套,一旦出现嵌套,就会出现代码停滞的现象,称为死锁。
除了 同步锁 Lock 的锁嵌套会导致死锁外,逻辑自掐也会导致死锁(递归锁 RLock 和 同步锁 Lock 都会死锁),如下描述的情况2,lock1和lock2分别被task1和task2拿走了没有释放,代码后续task1和task2又想去拿对方的锁,这样就会导致task1和task2都在等对方释放锁,最后大家都无法释放,导致死锁。
以下代码解释死锁的两种情况。
import threading
import time
lock = threading.Lock()
# 死锁情况1:
def task():
lock.acquire()
if True:
lock.acquire()
# 同步锁不支持嵌套,会导致死锁
lock.release()
lock.release()
# 死锁情况2:
lock1 = threading.RLock()
lock2 = threading.RLock()
def task1():
print('开始 task1:')
lock1.acquire()
time.sleep(1)
lock2.acquire()
time.sleep(1)
lock2.release()
lock1.release()
print('结束 task1:')
def task2():
print('开始 task2:')
lock2.acquire()
time.sleep(1)
lock1.acquire()
time.sleep(1)
lock1.release()
lock2.release()
print('结束 task2:')
subthread1 = threading.Thread(target=task1)
subthread2 = threading.Thread(target=task2)
subthread1.start()
subthread2.start()
2.3 线程池
首先由一个问题引入为什么我们需要线程池:根据之前的例子,对于每一个任务,我们会创建一个对应的线程来处理该任务。但是随着任务数目增多,我们需要创建的线程数目也急剧增加,从而导致速度变慢。
因此我们需要设置合适数目的线程,类比于合适数目的流水线工人张全蛋,假设由300个零件(任务)需要质检,只有30个张全蛋(线程),为了防止哪一个张全蛋偷懒,因此需要设置一个监工张铁柱,这个张铁柱的任务就是给30个流水线工人张全蛋分配任务,防止其偷懒。那么这个监工张铁柱的作用就是 线程池 的作用。
线程池的使用步骤主要包括以下五步:
- 引入线程池头相关文件: from concurrent.futures import ThreadPoolExecutor, Future
- 创建特定尺寸的线程池: pool = ThreadPoolExecutor( 线程数目 )
- 把任务提交给线程池:feature = pool.submit( 任务函数名,参数 )
- 通过回调函数把线程计算结果放入下游任务:feature.add_done_callback(下游任务函数名)
- 控制主线程执行顺序(类似于join()):pool.shutdown(True)
以下通过一个简单的案例来展示线程池的使用方法:
# 步骤1: 引入线程池头相关文件
from concurrent.futures import ThreadPoolExecutor, Future
import time
# 多线程执行的任务是:对每一个任务在加一个后缀
def task(name):
time.sleep(1)
return name + '_is_your_son!'
def callback(response):
print(response.result())
if __name__ == '__main__':
names = ['小明','小红','小白','小黑','小黄','小绿','小编']
# 步骤2: 创建特定尺寸的线程池
pool = ThreadPoolExecutor(2)
for name in names:
# 步骤3: 把任务交给线程池
futrue = pool.submit(task, name)
# 步骤4:通过回调函数把线程计算结果放入下游任务
futrue.add_done_callback(callback)
# 步骤5:控制主线程执行顺序(类似于join())
pool.shutdown(True)
print('GameOver!')
'''
输出结果:可以看出两个线程间的先后关系并不固定
小红_is_your_son!
小明_is_your_son!
小白_is_your_son!
小黑_is_your_son!
小绿_is_your_son!
小黄_is_your_son!
小编_is_your_son!
GameOver!
'''
3. 进程
3.1 进程的模式
在上一篇文章“Python 的多进程与多线程编程(简单入门)”中讲解的多进程的基本使用方法:
- 步骤1: 引入 multiprocessing 多进程库文件
- 步骤2: 利用 multiprocessing.Process 多进程库创建多进程子对象,对象的初始化包括以下三个参数:
target:参数为需要进行多进程处理的函数名;
args:需要进行多进程处理的函数参数,以元组的形式;
kwargs:需要进行多进程处理的函数参数,以字典的形式; - 步骤3:利用类对象的 start 成员函数执行多进程
其实多进程包括三种模式,”fork“, “spawn”, “forkserver”,在windows时仅能采用 "spawn"模式,在该模式下,传参只能通过 上述加粗的 args 和 kwargs 变量。而在 ”fork“ 模式下,主进程的所有变量/函数和类都会拷贝一份到子进程中,即不需要手动传输。多进程的模式可以通过以下函数设置:
import multiprocessing
multiprocessing.set_start_method("fork") # fork, spawn, forkserver
| 模式 | 主进程资源/变量 | 传参类型 | 支持运行系统 | 主进程开始位置 | 速度 |
|---|---|---|---|---|---|
| ”fork“ | 拷贝几乎所有资源 | 支持文件对象、线程锁作为参数 | unix | 任意位置 | 快 |
| “spawn” | 需要手动传参 | 不支持文件对象、线程锁作为参数 | unix、win | mian函数 | 慢 |
| “forkserver” | 需要手动传参 | 不支持文件对象、线程锁作为参数 | 部分unix | mian函数 |
3.2 进程的常见成员方法
import threading
import multiprocessing
# 1. 设置进程模式
multiprocessing.set_start_method("fork") # fork, spawn, forkserver
# 2. 创建进程对象
p = multiprocessing.Process(target=task, args=(param1,param2,...))
# 3. 设置守护主进程
p.deamon = True
# 4. 启动进程
p.start()
# 5. 等待子进程
p.join()
# 6. 设计进程名称
p.name = 'Jackey'
# 7. 查看CPU个数(进程数可与CPU个数保持一致)
multiprocessing.cpu_count()
3.3 进程间数据共享
首先由两个问题:
- 为什么需要进程间数据共享?
- 为什么线程不需要数据共享?
简单地回答就是进程间不共享资源,而线程间共享同一个进程的资源。可以通过以下例子来解释:我想通过子进程修改 ls 为:“Jackey Chen 666!”,但是最后的输出结果时 ”Jackey Chen“,这反映了在子进程 myls 并不能改变主线程的内容,因此我们需要进程间的通信。
import multiprocessing
def ChangeInSubprocess(myls):
myls +=' 666!'
if __name__ == '__main__':
ls = 'Jackey Chen'
p = multiprocessing.Process(target=ChangeInSubprocess, args=(ls,))
p.start()
p.join()
print(ls) # 输出: Jackey Chen
接下来,要解决的问题就是:如何进行进程间的通信?
Python 环境中提供了4中方法,笔者认为概况来说是2种方法,分别是:借助全局变量和利用进程间通信。其中方法2和方法3使用频率最高。
3.3.1 利用 Value 或 Array 数据类型
from multiprocessing import Process, Value, Array
def ChangeInSubprocess(n, nums):
n.value = 99
nums[0] = 0
nums[2] = 0
if __name__ == '__main__':
num = Value('i', 66)
arr = Array('i', [1, 1, 1])
p = Process(target=ChangeInSubprocess, args=(num, arr))
p.start()
p.join()
print('num is: ', num.value, ', array is: ', arr[:])
# 输出: num is: 99 , array is: [0, 1, 0]
注意,代码中的小写字母代表以下数据类型,源于C/C++;

3.3.2 利用 Manager 携带的特殊数据类型
from multiprocessing import Process, Manager
def ChangeInSubprocess(d, ls):
d['JackeyChen'] = 666
ls[0] = 0
ls[2] = 0
if __name__ == '__main__':
with Manager() as manager:
num = manager.dict()
arr = manager.list([1, 1, 1])
p = Process(target=ChangeInSubprocess, args=(num, arr))
p.start()
p.join()
print('num is: ', num, ', array is: ', arr)
# 输出: num is: {'JackeyChen': 666} , array is: [0, 1, 0]
3.3.3 利用 Queues 进行进程间通信
所谓队列,最显著的特征就是先进先出,单向行驶,如图。其通信的示例如下所示:

from multiprocessing import Process, Queue
def ChangeInSubprocess(queue):
# 2. 子进程向主进程传递参数
queue.put('Jackey')
queue.put('Chen')
queue.put('666')
queue.put('!')
if __name__ == '__main__':
# 1. 创建一个通信队列,并作为子进程的参数
queue = Queue()
p = Process(target=ChangeInSubprocess, args=(queue,))
p.start()
p.join()
# 3. 主进程向子进程提取传递参数
print('1: ', queue.get())
print('2: ', queue.get())
print('3: ', queue.get())
print('4: ', queue.get())
'''
输出:
1: Jackey
2: Chen
3: 666
4: !
'''
3.3.4 利用 Pipes 进行进程间通信
相比于 Queue ,Pipes是双向传递的机制,如图:

from multiprocessing import Process, Pipe
import time
def ChangeInSubprocess(child_conn):
# 2. 子进程向主进程传递参数
time.sleep(1)
child_conn.send(['Jackey'])
# 5. 子进程从主进程提取传递参数
data = child_conn.recv() # 主线程阻塞接收
print("Father2Child: ", data)
# 6. 子进程向主进程传递参数
time.sleep(1)
child_conn.send(['666 !'])
if __name__ == '__main__':
# 1. 创建一个通信管道,并设置管道的两端,把父端给主进程,子端给子进程
father_conn, child_conn = Pipe()
p = Process(target=ChangeInSubprocess, args=(child_conn,))
p.start()
# 3. 主进程向子进程提取传递参数
data = father_conn.recv() # 主线程阻塞接收
print("Child2Father: ", data)
# 4. 主进程向子进程传递参数
father_conn.send(['Chen'])
# 7. 主进程向子进程提取传递参数
data = father_conn.recv() # 主线程阻塞接收
print("Child2Father: ", data)
'''
输出:
Child2Father: ['Jackey']
Father2Child: ['Chen']
Child2Father: ['666 !']
'''
3.4 进程锁
回顾以下线程锁,线程锁的目的在于由于线程间共享同一个进程的资源,因此可能会出现数据紊乱的情况,因此需要加入线程锁来控制代码执行的顺序。
那么进程需要进程锁吗?原则上是不需要的,因为进程间的资源是不共享的,无法造成数据紊乱。但是由于 3.3 节 进程间数据共享 的全局变量的加入和一些本地的IO操作,使得进程间也会出现数据紊乱的现象,因此进程锁也是需要的。
以下使用一个本地IO的例子来讲述进程锁的使用:
import multiprocessing
import time
# 0. 创建一个任务为:模拟淘宝抢票,原有10件商品(存在.txt文件中),每个子进程访问一次,商品个数减1
def task(lock):
lock.acquire()
print('开始抢购啦!!')
with open('f.txt', 'r') as f:
# 读取目前商品个数
current_num = int(f.read())
print('排队抢购中...')
time.sleep(1)
current_num -= 1
with open('f.txt', 'w') as f:
# 读取目前商品个数
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
# 1. 在主进程中创建了一把进程锁
lock = multiprocessing.RLock()
# 2. 创建10个子进程
for i in range(10):
# 3. 传递进程锁作为参数
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
'''
不添加进程锁,f.txt文件的结果为:9
添加进程锁,f.txt文件的结果为:0
'''
3.4 进程池
多进程的优势在于利用多核CPU的优势,对于一台电脑,电脑的核心个数是一定的,如8/16核。
那么,当任务超过CPU核心个数时,创建过多的进程数目是没有意义的,反而会导致速度降低。因此,类似于线程池,我们也可以通过创建进程池来管理进程的分配。
进程池的使用方法与线程池完全一致,主要包括以下常用函数:
# 1. 进程池的库文件
from concurrent.futures import ProcessPoolExecutor
# 2. 创建进程池
pool = ProcessPoolExecutor( 进程数目 )
# 3. 提交任务到进程池中
future = pool.submit(任务函数名,参数)
# 4. 调用回调函数处理进程输出结果,值得一提的是,线程池的回调函数由子线程负责,而进程池的回调函数由主进程负责
future.add_done_callback( 回调函数名称 )
# 5. 阻塞主进程等待子进程执行结束
pool.shutdown(True)
# 6. 设置进程锁,不能使用 multiprocessing.RLock(), Lock()同理
manager = multiprocessing.Manager()
lock = manager.RLock()
4. 总结
终于写完了这部分的所有内容,完结撒花!!!原视频讲的很好:视频链接。建议看一看!
总的来说,本文主要讲解了多线程和多进程的常用方法或者利用进程池、线程池来实现自动管理,也着重讨论了进程间数据共享以及其会导致的数据紊乱的问题,进而我们介绍 进程锁、线程锁、死锁、 等概念来解决这个问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 「从ES到CK 07」kibana自定义插件跳转clickvisual
- UDP Ping程序实现--第5关:客户端向服务器发送消息并接收消息
- LLM大模型和数据标注
- 米贸搜|Facebook为什么ROAS被看得这么重要?建议的标准是什么?
- YOLOv8 + openVINO 多线程数据读写顺序处理
- c语言版:数据结构(时间复杂度,空间复杂度,练习)
- Keil调试STM32卡死在文件startup_stm32f10x_hd.s的B处
- RK3568平台开发系列讲解(Linux系统篇)设备树中 GPIO 相关属性
- 2023最新版JavaSE教程——第2天:变量与运算符
- 【C++】智能指针