XTuner 大模型单卡低成本微调实战
仅作为自己学习的笔记记录。
教程
XTuner 大模型单卡低成本微调实战 文档
XTuner 大模型单卡低成本微调实战 B站视频


指令微调,也叫指令微调,intruct 大模型。
左边这种海量的预训练得到的模型,在没有经过指令微调,可能无法意识到你的问题的预期回答模式。想要模型的回答更符合你的指令,就可以进行指令微调。

增量预训练和指令跟随微调这两种方式是如何实现的呢?(数据预处理)
指令微调
指令跟随微调时候需要对训练数据进行角色指定。数据是由一问一答两个部分构成的。
问题部分需要指定给user 角色,把回答指定给 assistant 角色。system 部分就按照自己微调的目标领域来写。
完成三个角色的数据,就完成了对话模板的构建。

对话模板的话在不同系统中也不尽相同。
部署的模型,也就是预测阶段,用户输入的内容是默认放在 user 角色下的, system 部分是由模板添加的,至于具体使用什么模板,在启动预测的时候,是可以自定义的。
指令微调需要用对话来做。

只对答案部分进行损失的计算。

增量预训练
不需要使用问答数据。增量部分不需要问句,只需要回答。
system, user 内容留空,架构增量预训练的内容放到 assistant 角色中。仍然计算 assistant 部分的损失。

微调原理
在 SD 中,换一个 lora 就相当于换一个风格, 而不需要调整基座模型。
新增一个旁路分支,也就是 Adapter 文件,参数量远远小于原来的模型。lora 相当于
QLoRA? 类似螺丝刀?

全参数微调时,整个模型都要加载进显存中的,然后所有的参数的优化器也都要加载到显存中。
Lora 微调的时候,整个模型也是要加载到显存中的,但是对于参数优化器,只需要保存 lora 部分的参数优化器,这就已经大大减少显存占用。
而对于 QLoRA, 首先加载模型的时候,就使用 4bit 量化的方式加载,也就相当于不那么精确的加载,但是可以节省显存开销。然后优化器还可以在 CPU 和 GPU 之间调度,如果显存慢了,就自动去内存上跑。
XTuner 对CPU的调度做了整合。

XTuner


快速上手

跑完训练后,要将得到的 PTH 模型转换为 HuggingFace 模型,生成 Adapter 文件夹。
可以简单理解:LoRA 模型文件 = Adapter
将 HuggingFace adapter 合并到大语言模型:
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
#xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf
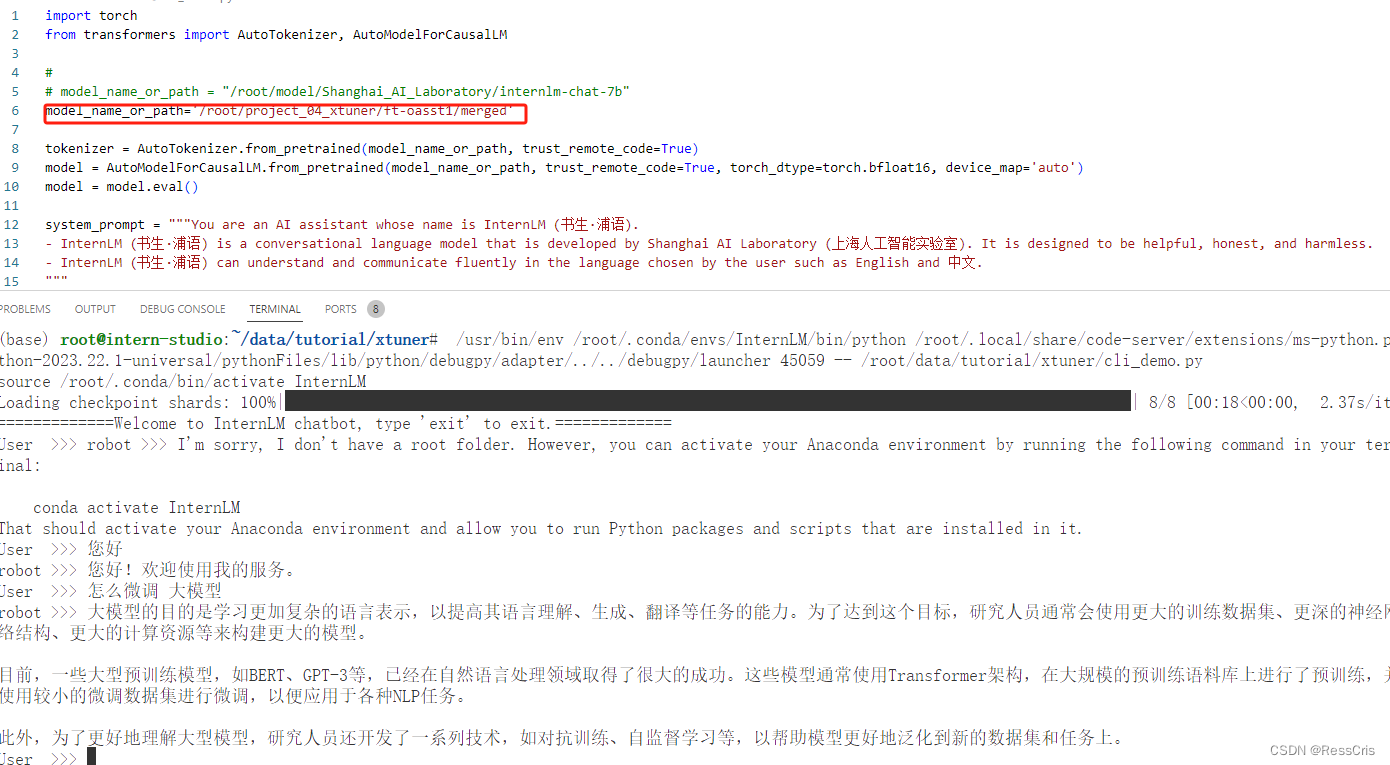
与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
#4 bit 量化加载
xtuner chat ./merged --bits 4 --prompt-template internlm_chat

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!