工作中redis相关知识总结

这里写目录标题
一、Redis数据持久化概念
持久化在Redis中的工作原理就是将你存储在缓存中的数据异步的保存在你的磁盘中实现持久存储。
当电脑或者服务器发生宕机时,我们的内存会被清空,但是存储在磁盘中的数据不会丢失,
当我们再次打开Redis时,磁盘中的数据集就会再次同步到我们的Redis中,也就是从磁盘中再次回到内存中。
二、redis数据类型
String
Hash
List
Set
ZSet
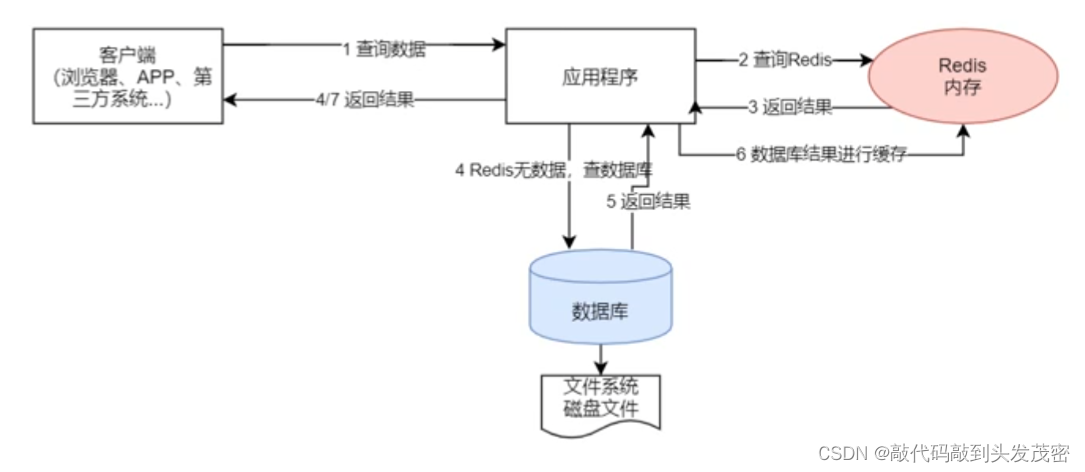
三、redis缓存的应用流程
四、什么样的数据适合存放到redis中?
读的频率非常高、更新频率较少的数据
应用程序从redis中微秒获取数据
1、什么情况下,redis中会没有数据?
a、第一次查询,数据需要从数据库查询再缓存起来
b、redis数据过期。数据查询不到了
c、redis挂了。整个服务都访问不了了,只能从数据库里面查询。
2、redis缓存项目在测试中的注意事项
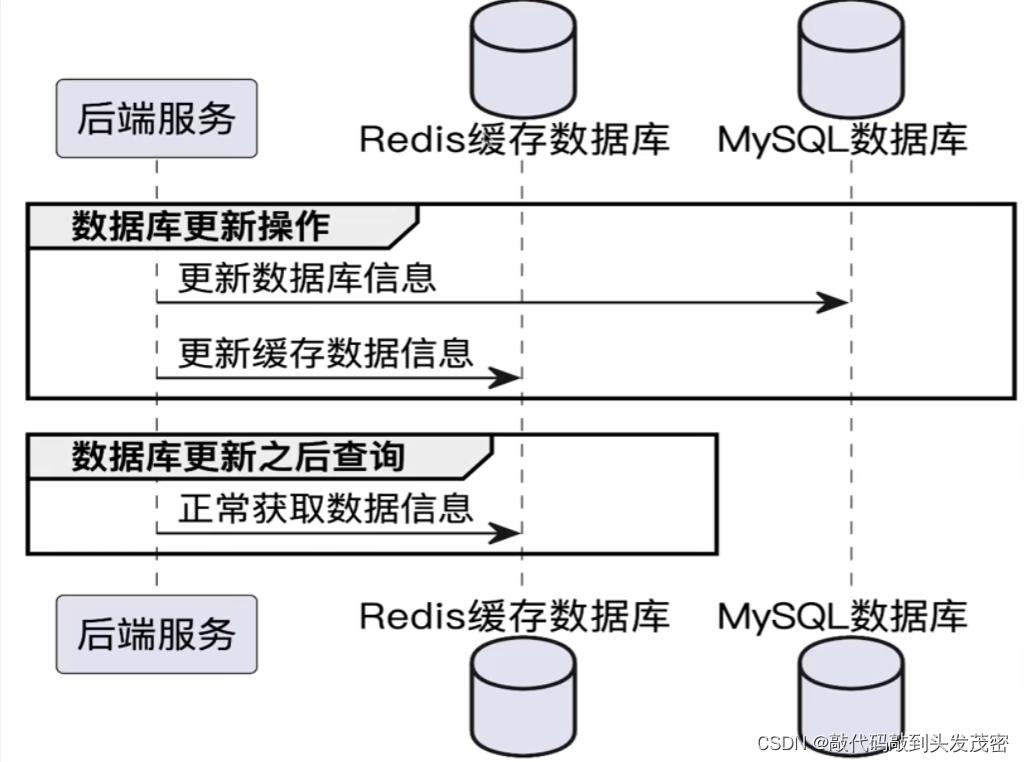
a、更新缓存
缓存操作流程-写(更新缓存)
优点: 基本不会出现cache miss的情况。
缺点: 每次更新数据库都更新缓存,比较影响性能。
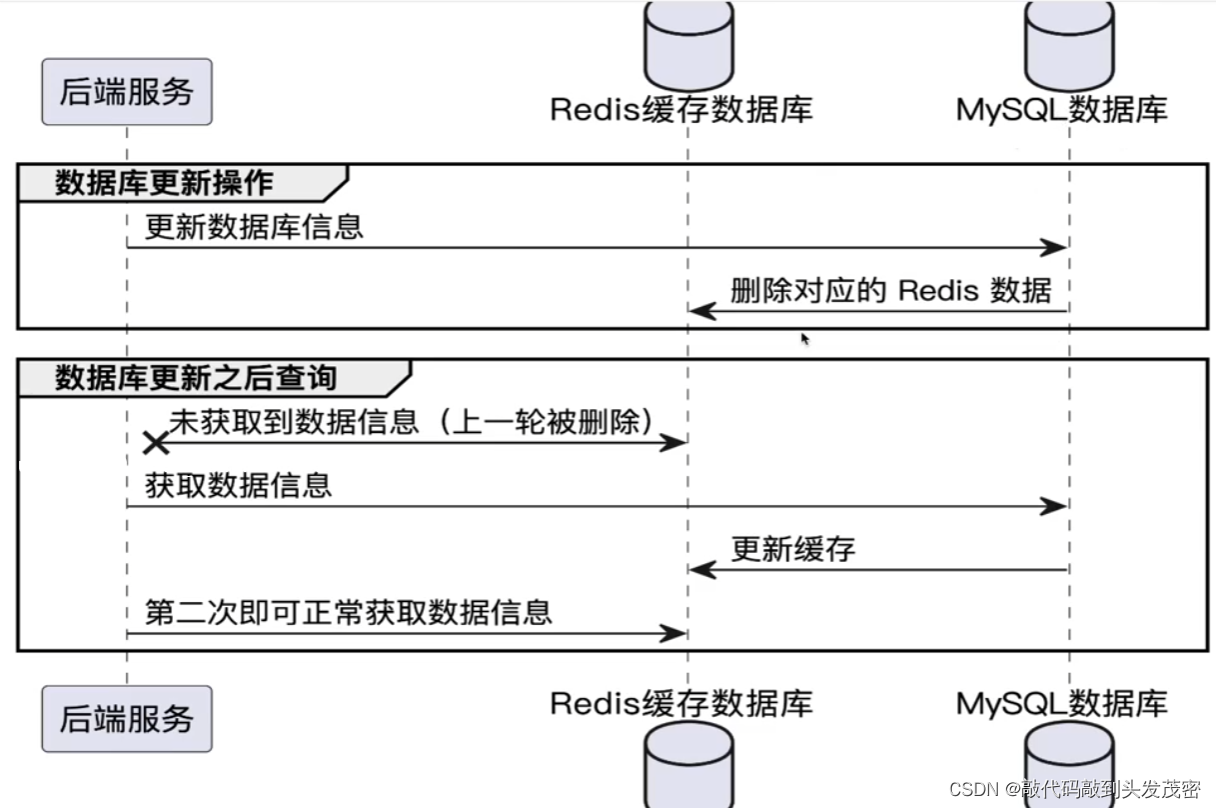
b、淘汰缓存
优点: 操作简单,性能比较好。
缺点:至少会出现一个 cache miss。(当大量的请求访问数据库时,数据库压力很很大)
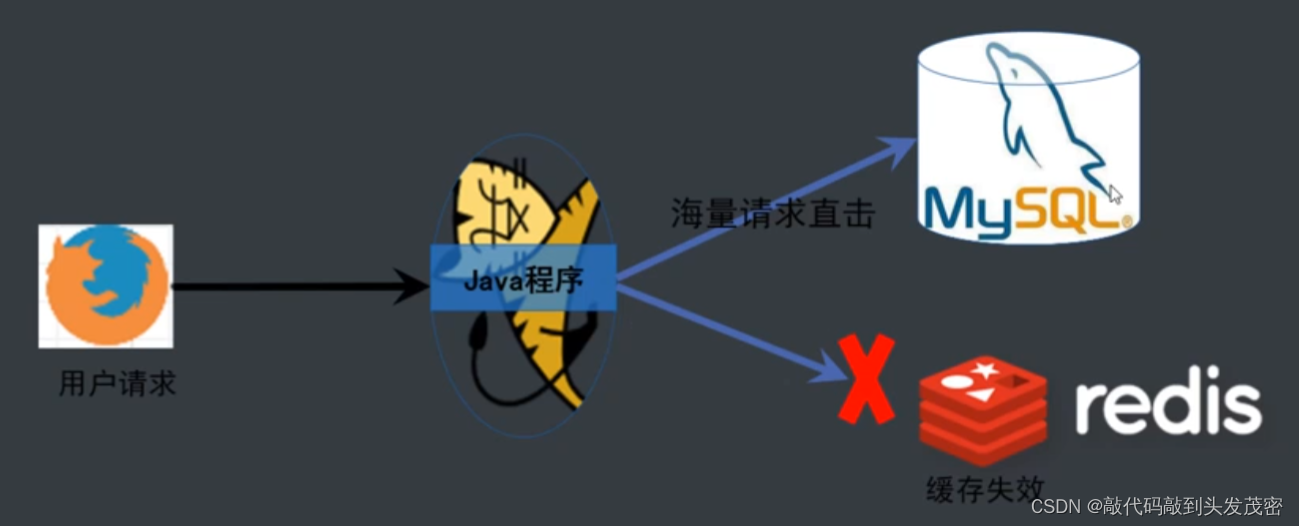
五、什么是缓存击穿
在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据,造成瞬间数据库请求量大、压力剧增,甚至可能打垮数据库。
1、缓存失效的两种情况
- a、高峰期大面积缓存key失效。(所有请求全部访问后端数据库)
- b、局部高峰期,热点缓存key失效(导致海量的请求直接击穿数据库)
2、缓存数据有效期到来的那一瞬间举例
- 1、突发重要热点事件
- 2、春节发红包
- 3、电商降价、抢购、促销活动
六、什么是缓存穿透
访问一个redis缓存和数据库都不存在的key,此时会直接打到数据库上,并且查不到数据,没法写到redis缓存,所以下一次同样会打到数据库上。
缓存起不到作用,流量大时数据库可能会被打挂,此时缓存就好像被穿透了一样,起不到任何作用。
1、如何测试验证?
使用Jmeter等压测工具进行模拟测试
七、缓存雪崩
缓存雪崩是指缓存失效后导致服务大面积崩溃的后果
1、缓存雪崩的原因
缓冲击穿、缓存穿透、缓存服务不可用
2、缓存雪崩风险
因为缓存服务器挂掉或者热点缓存失效,从而导致海量请求去查询数据库,导致数据库连接不够用或者数据库处理不过来,从而导致整个系统不可用。
数据库服务器压力大,依赖数据库的其他系统就会面临崩溃风险。
3、解决方案
缓存击穿
- 过期事件打散:高峰期大面积的key不要全部一起失效;或者直接不失效。
- 热点数据不过期:针对单个热点数据。
- 互斥锁:万一实在是拿不到缓存了,并发控制。
- 缓存降级:redis服务器挂了,缓存备份,数据兜底。
缓存穿透
- 业务规则校验:日期范围、业务规则校验不符合直接返回。
- 数据格式校验:ID(特意设计)、前16位表示事件,中间3位表示业务分类代码,后面3位表示随机数
- 布隆过滤器:把大批量的请求参数的真实值,压缩放到过滤器里,每次请求的时候,通过过滤器进行验证。
- IP黑名单限流:禁止访问。
八、redis 在你们项目中具体的作用,还有哪些常用的功能
1、权限的数据的特点
需要去数据库中频繁的读和写,为了项目提高运行效率,可以把用户的权限在每次登录的时候都缓存到redis中。这样的话,权限判断的中间件就可以方便的从redis中得到当前用户的所有权限,从而判断。
对于那些数据量大,并且需要频繁的读写,一定需要做缓存的
详细的实现过程请查看博客:https://blog.csdn.net/YZL40514131/article/details/128599386
2、django自动化测试平台以及python开发的平台,需要异步执行任务或者定时执行任务
1、选择一个broker
使用celery首先需要选择一个消息队列。安装任意你熟悉的前面提到的celery支持的消息队列。
2、安装redis容器
因为redis默认没有密码,使用云服务器部署redis容器时需要设置密码。新建配置文件/root/redis.conf编写如下配置:
requirepass pythonvip
然后运行如下命令创建容器:
sudo docker run -d -p 9000:6379 -v /home/ubuntu/redis.conf:/usr/local/etc/redis/redis.conf --name myredis redis:alpine redis-server /usr/local/etc/redis/redis.conf
redis的连接url格式如下
redis://:password@hostname:port/db_number
详细的实现过程请查看博客:https://blog.csdn.net/YZL40514131/article/details/132245242
九、涉及redis相关的内容怎么测试?
1、故障注入
- redis故障降级测试
- 将redis中的数据清空。
- 获取某个数据,看能否击穿redis去数据中获取到数据。
- 检测获取到数据是否又保存到数据库中了。
- 启动redis,恢复数据了,测试能否从redis中获取到正确的数据
- redis崩溃了,能佛从数据库中获取到数据

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!