【Python深度学习系列】十几行代码教你使用CTGAN模拟生成表格数据
发布时间:2023年12月21日
一、问题
? ? 在机器学习中,我们经常会遇到数据集数量不足的情况。CTGAN是一个生成对抗网络(GAN)的实现,它可以学习原始数据的分布并生成具有相似特征的合成数据。生成的数据将尽量保持与原始数据的统计特性一致。
二、实现过程
2.1 安装CTGAN库
pip install ctgan使用命令在终端或命令提示符中安装CTGAN库
2.2?导入CTGAN类
from ctgan import CTGAN在Python代码中导入CTGAN类
2.3 准备原始数据
hci_data=pd.read_csv(r'HCI_Datasheet.csv')
hci_data=hci_data.drop(columns=['S. No','Decision Date','Application Date'])
hci_data['University_Program']=hci_data.University+' '+hci_data.Programme
hci_data.University=hci_data.University_Program
hci_data=hci_data.drop(columns=['Programme','University_Program','Year of Entry'])
#Label Encoding
le = preprocessing.LabelEncoder()
hci_data['Decision'] = le.fit_transform(hci_data['Decision']) ### 0-Accepted, 1-Rejected
hci_data['Research Experience'] = le.fit_transform(hci_data['Research Experience']) ###1-Yes, 0-No
hci_data['Submitted Portfolio'] = le.fit_transform(hci_data['Submitted Portfolio']) ###1-Yes, 0-No
hci_data['Student Status'] = le.fit_transform(hci_data['Student Status']) ### 0-Domestic, 1-International, 2-Undergrad domestic
hci_data['GRE']=hci_data['GRE'].fillna(330)
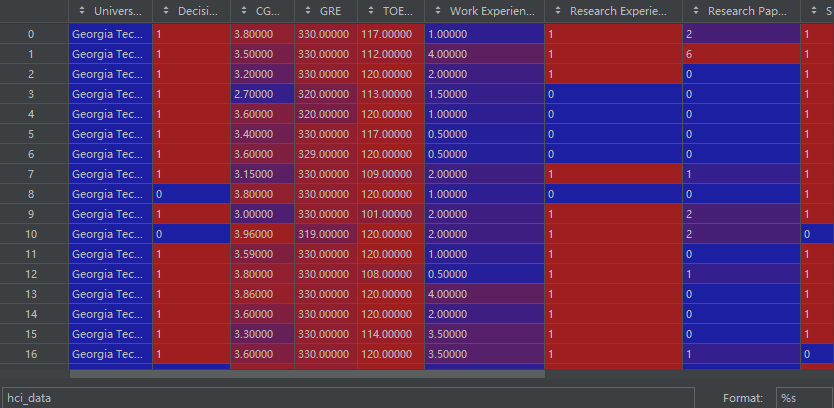
hci_data['TOEFL']=hci_data['TOEFL'].fillna(120)原始数据准备为一个Pandas DataFrame对象,数据中包含连续型和离散型特征,以及一个标签列(如果适用)。实例数据如下:
2.4 创建CTGAN对象并拟合数据
columns=list(hci_data.columns)
ctgan = CTGAN(epochs=100)
ctgan.fit(hci_data, columns)使用CTGAN类创建一个对象,并使用原始数据拟合模型
2.5 生成模拟数据
synthetic_data = ctgan.sample(len(data))
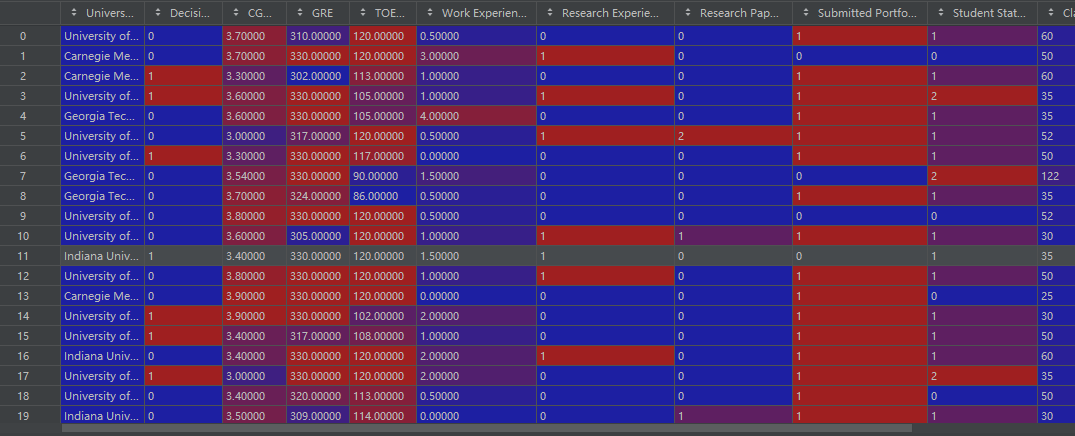
print(synthetic_data)使用拟合好的模型生成模拟数据,模拟数据效果如下:
2.6 效果评价
table_evaluator = TableEvaluator(hci_data, synthetic_data)
try:
table_evaluator.visual_evaluation()
except:
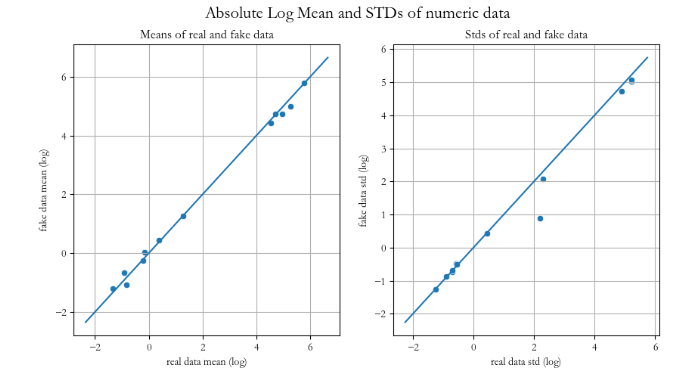
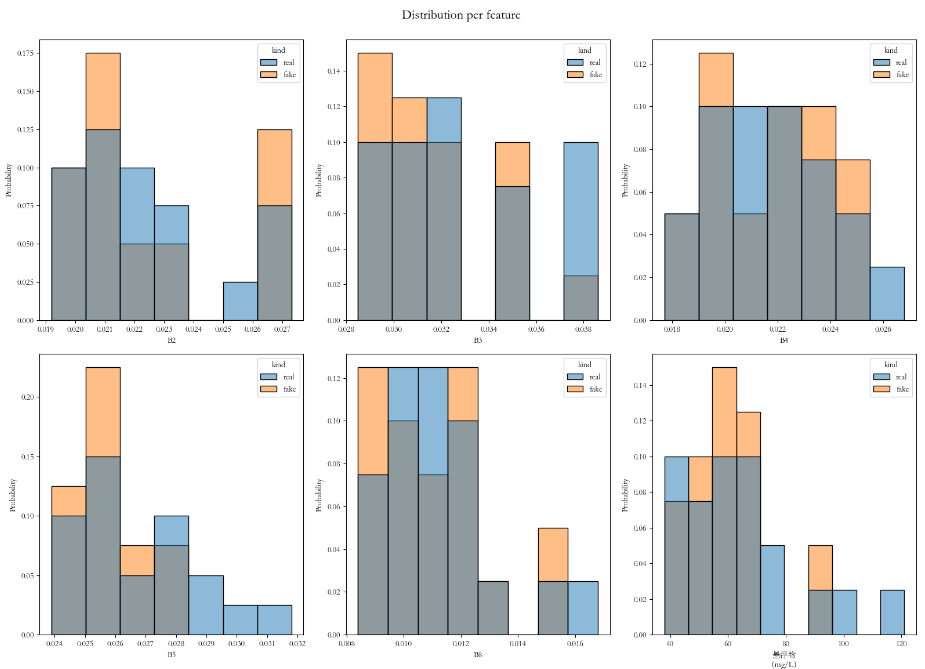
print()效果如下:
好了,本篇内容就总结分享到这里,需要源码的小伙伴可以关注底部公众号添加作者微信!
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
文章来源:https://blog.csdn.net/sinat_41858359/article/details/135128549
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据库】使用远程管理工具链接Mysql数据库
- AI教我学编程之C#关键字
- 现代C++的多线程开发
- uniapp框架——vue3+uniFilePicker+fastapi实现文件上传(搭建ai项目第二步)
- UE5 C++ 学习笔记 UBT UHT 和 一些头文件
- py判断telnet端口是否通
- c语言中的static静态(1)static修饰局部变量
- TS学习笔记八:命名空间
- 《中学课程辅导》期刊投稿邮箱
- Node.js安装